系统设计面试
在线阅读
《系统设计面试:内幕指南(中文翻译)》
原名:《System Design Interview: An Insider’s Guide》
作者:Alex Xu
译者:精灵王 @Admol
目录
- 第 1 章:从零到数百万用户的规模
- 第 2 章:粗略估算
- 第 3 章:系统设计面试框架
- 第 4 章:设计一个分布式限流器
- 第 5 章:一致性哈希设计
- 第 6 章:设计一个 key-value 存储系统
- 第 7 章:设计一个分布式系统唯一ID生成器
- 第 8 章:设计一个短网址系统
- 第 9 章:设计一个网络爬虫系统
- 第 10章:设计一个通知系统
- 第 11章:设计一个新闻提要系统
- 第 12章:设计一个聊天系统
- 第 13章:设计一个搜索自动完成系统
- 第 14章:设计 YouTube
- 第 15章:设计 Google Drive
《系统设计面试:内幕指南(第二卷)》
原名:《System Design Interview An Insider's Guide Volume 2》
作者:Alex Xu &Sahn Lam
译者:精灵王 @Admol
目录
- 第1章 邻近服务
- 第2章 附近的好友
- 第3章 谷歌地图
- 第4章 分布式消息队列
- 第5章 指标监控与告警系统
- 第6章 广告点击事件聚合
- 第7章 酒店预订系统
- 第8章 分布式邮件服务
- 第9章 类S3对象存储
- 第10章:实时游戏排行榜
- 第11章 支付系统
- 第12章 数字钱包
- 第13章 股票交易所
声明
译者纯粹出于 学习目的 与 个人兴趣 翻译本书,不追求任何经济利益。
译者保留对此版本译文的署名权,其他权利以原作者和出版社的主张为准。
本译文只供学习研究参考之用,不得公开传播发行或用于商业用途。
有能力阅读英文书籍者请至亚马逊购买正版支持。
第01章:从0到百万用户
设计一个支持数百万用户的系统具有挑战性,是一个需要持续完善和不断改进的过程。在这一章中,我们构建一个支持单个用户的系统,并逐渐扩展以服务数百万用户。阅读完这一章后,你将掌握一些技巧,有助于你解决系统设计面试问题。
单服务器设置
千里之行始于足下,构建一个复杂的系统亦是如此。为了从简单的地方开始,我们把所有东西都运行在一个单独的服务器上。图1-1展示了单服务器设置的示意图,其中所有内容都在一个服务器上运行:Web应用程序、数据库、缓存等。
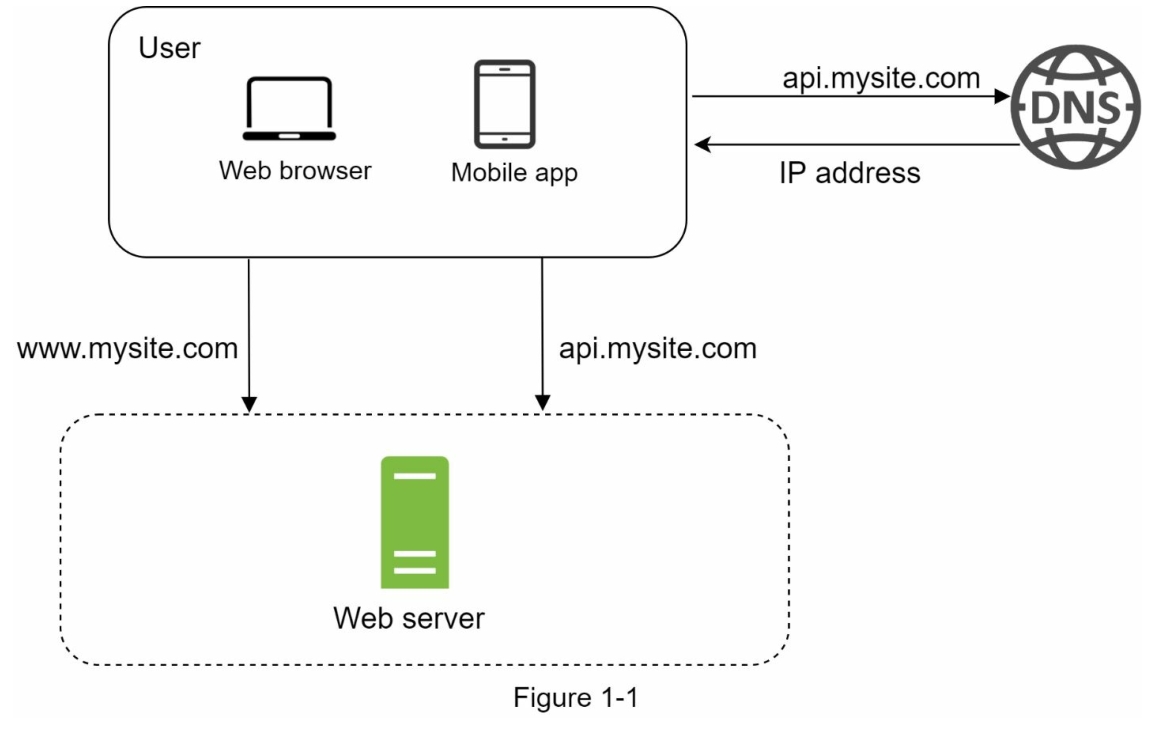
为了理解这个设置,调查请求流程和流量来源是有帮助的。首先,让我们看一下请求流程(图1-2)。
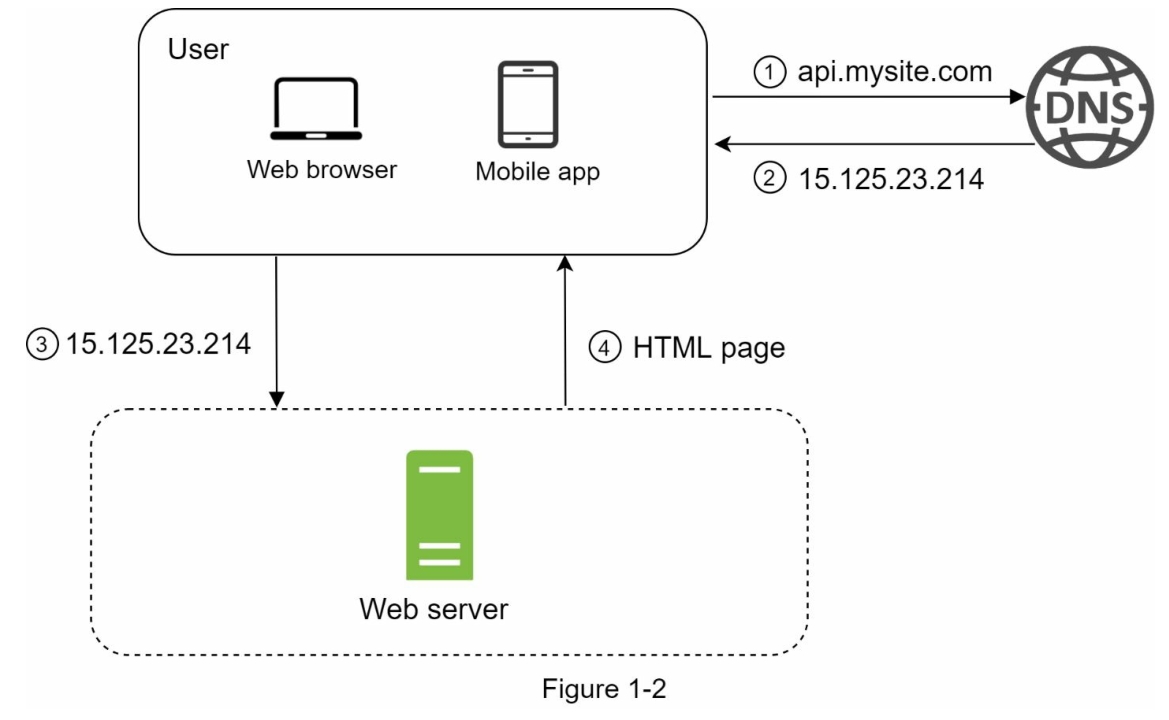
- 用户通过域名访问网站,例如api.mysite.com。通常,域名系统(DNS)是由第三方提供的付费服务,而不是由我们的服务器托管。
- Internet Protocol(IP)地址被返回给浏览器或移动应用程序。在这个例子中,返回的IP地址是15.125.23.214。
- 一旦获得了IP地址,就会直接向您的Web服务器发送超文本传输协议(HTTP)[1]请求。
- Web服务器返回用于渲染的HTML页面或JSON响应。
接下来,让我们检查流量来源。对你的Web服务器的流量来自两个来源:Web应用程序和移动应用程序。
-
Web应用程序:它使用一组服务器端语言(Java、Python等)来处理业务逻辑、存储等,以及客户端语言(HTML和JavaScript)进行呈现。
-
移动应用程序:HTTP协议是移动应用程序和Web服务器之间的通信协议。由于其简单性,JavaScript Object Notation(JSON)是常用的API响应格式用于数据传输。以下是JSON格式的API响应示例:
``` GET /users/12 – Retrieve user object for id = 12 { "id": 12, "firstName": "John", "lastName": "Smith", "address": { "streetAddress": "21 2nd Street", "city": "New York", "state": "NY", "postalCode":10021 }, "phoneNumbers": [ "212 555-1234", "646 555-4567" ] } ```
数据库
随着用户基数的增长,单个服务器已经不够,我们需要多个服务器:一个用于处理Web/移动流量,另一个用于数据库(图1-3)。将Web/移动流量(Web层)和数据库(数据层)服务器分开允许它们独立扩展。 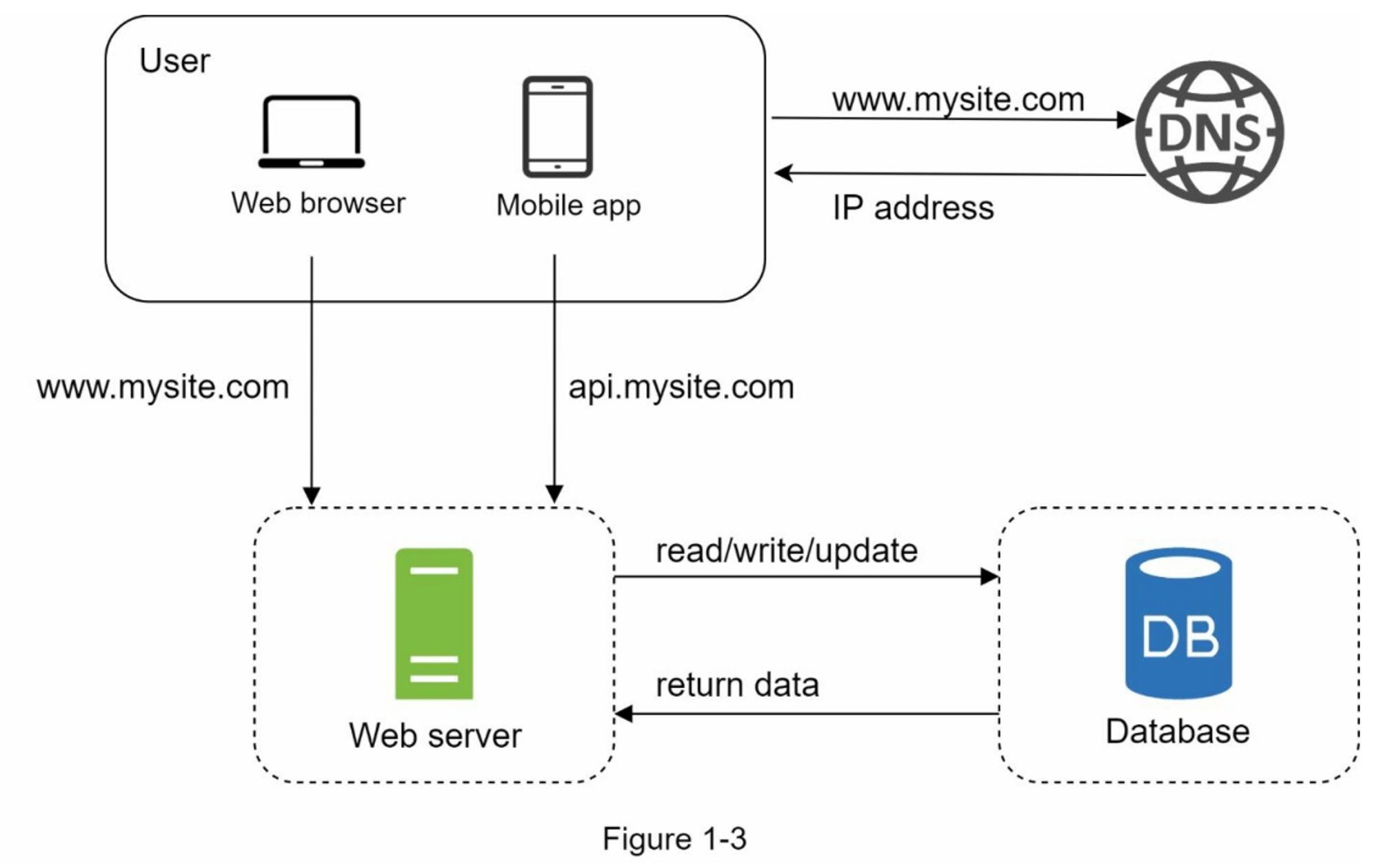
-
使用什么数据库?
你可以在传统关系型数据库和非关系型数据库之间进行选择。让我们来看看它们的区别。
关系型数据库也称为关系数据库管理系统(RDBMS)或SQL数据库。其中最流行的包括MySQL、Oracle数据库、PostgreSQL等。关系型数据库使用表格和行来表示和存储数据。你可以使用SQL在不同的数据库表之间执行连接操作。
非关系型数据库也称为NoSQL数据库。其中一些流行的包括CouchDB、Neo4j、Cassandra、HBase、Amazon DynamoDB等[2]。这些数据库分为四类:键值存储、图存储、列存储和文档存储。非关系型数据库通常不支持连接操作。
对于大多数开发者来说,关系型数据库是最佳选择,因为它们已经存在了40多年,历史上一直表现良好。然而,如果关系型数据库不适用于你特定的用例,那么探索超越关系型数据库是至关重要的。
在以下情况,非关系型数据库可能是正确的选择:
- 你的应用程序需要超低延迟
- 你的数据是非结构化的,或者你没有任何关系型数据。
- 你只需要序列化和反序列化数据(JSON、XML、YAML等)。
- 你需要存储大量的数据
垂直扩展vs水平扩展
垂直扩展,又称为“纵向扩展”,指的是通过增加单个服务器的计算能力(CPU、RAM等)来提升其性能。
水平扩展,又称为“横向扩展”,允许通过向资源池中添加更多服务器来进行扩展。
当流量较低时,垂直扩展是一个很好的选择,而垂直扩展的主要优势在于其简单性。不幸的是,它也带有一些严重的限制。
- 垂直扩展有一个硬性限制,不可能为单个服务器无限制的添加CPU和内存
- 垂直扩展没有故障转移和冗余,如果一台服务出现宕机,网站和应用程序都会彻底宕机。
由于垂直扩展的局限性,对于大规模应用程序来说,水平扩展更为理想。
在以前的设计中,用户直接连接到web服务器,如果服务器下线,用户将不能访问网站。在另一种情况下,如果许多用户同时访问web服务器,并且它达到了web服务器的限制,则用户通常会遇到响应较慢或者无法连接到服务器的情况。
负载均衡是解决这些问题的最佳技术方案。
负载均衡
负载均衡器均匀地分配传入的流量到在负载均衡集中定义的Web服务器,图1-4展示了负载均衡器的工作原理。 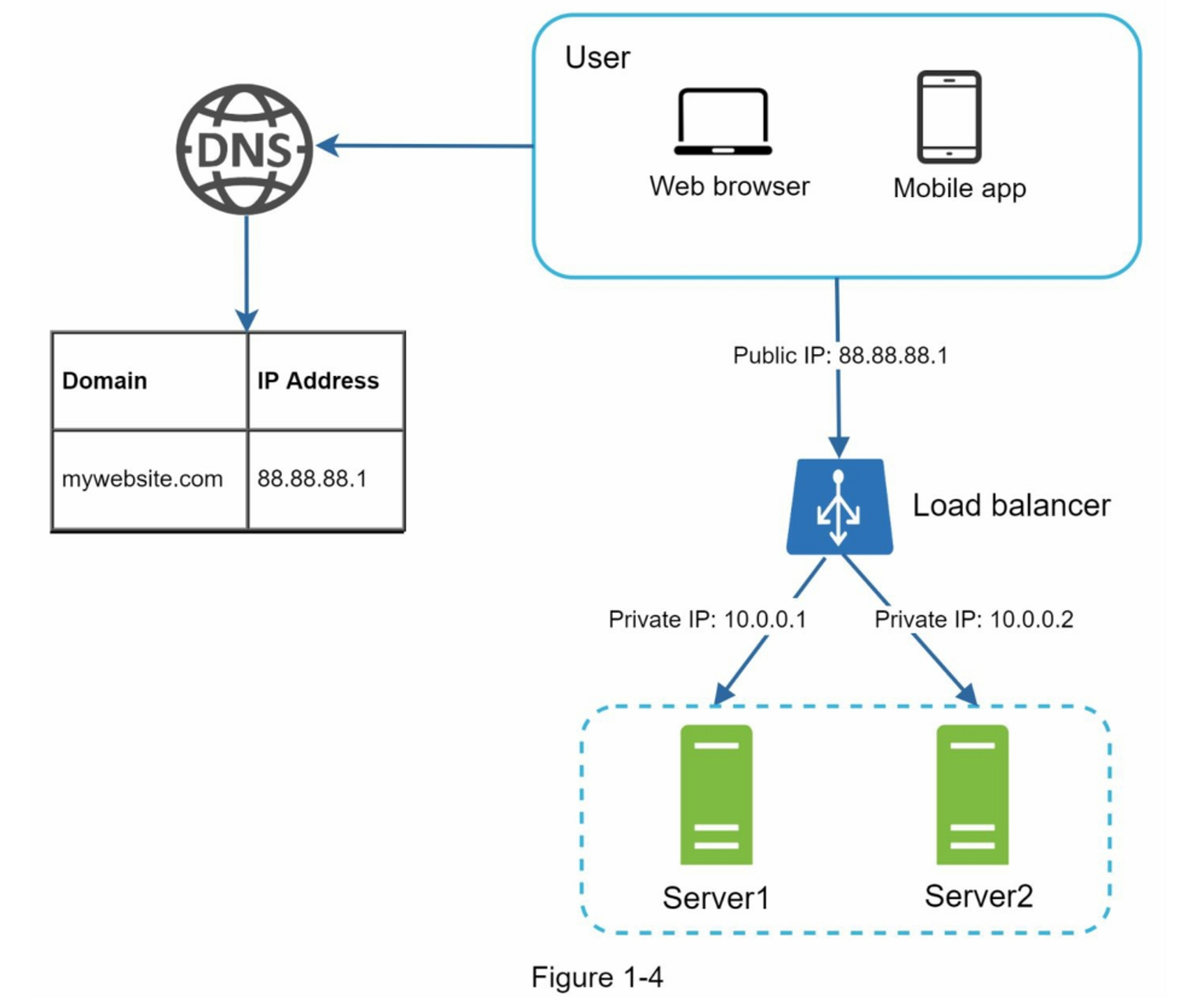
如图1-4显示,用户直接连接负载均衡的公网IP。通过此配置,客户端不再直接访问web服务器,为了提高安全性,服务器之间的通信使用私有IP。私有IP是仅在同一网络中的服务器之间可达的IP地址。然而,它在互联网上是不可访问的。负载均衡器通过私有IP与Web服务器通信。
在图1-4中,在添加了一个负载均衡和第二个web服务器后,我们成功解决了故障切换问题,并提高了Web层的可用性。
详细解释如下:
- 如果服务器1下线,所有流量将被路由到服务器2。这可以防止网站离线,我们还将在服务器池中添加一个新的健康Web服务器来平衡负载。
- 如果网站流量迅速增长,并且两台服务器不足以处理流量,那么负载均衡可以很好的处理这个问题,你只需要向web服务器池中添加更多的服务器,负载均衡会自动发送请求给他们。
现在Web层看起来很好,那数据层呢?当前设计只有一个数据库,因此不支持故障切换和冗余。数据库复制是解决这些问题的常见技术,让我们来看看吧。
数据库复制
引用自维基百科:“数据库复制可适用于许多数据库管理系统,通常在原始数据库(master)与副本数据库(slaves)之间建立主/从关系”。
主数据库通常仅支持写的操作。从数据库从主数据库中复制数据并且仅支持读操作。所有修改数据的命令,如:insert,delete,update 都必须发送到主数据库。
大多数应用程序对读写比的要求较高,因此,系统中从库的数量通常大于主库的数量。
图1-5展示了一个主数据库和多个从数据库的情况。
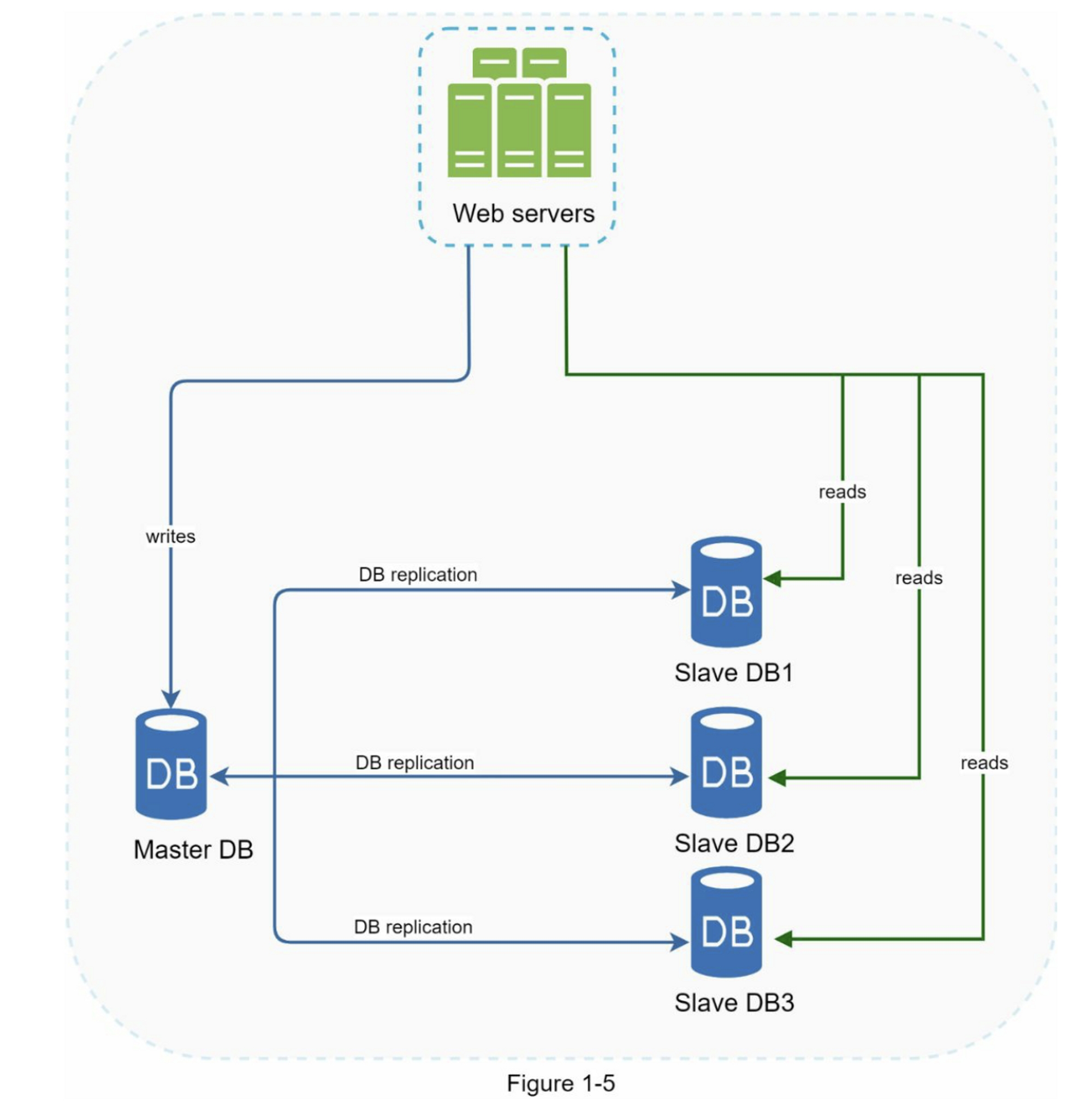
数据库复制的优势包括:
- 更好的性能:在这个主/从模型中,所有的写入和更新都发生在主节点,而所有的读操作分布在从节点。这种模型提高了性能,因为它允许并行处理更多的查询。
- 可靠性:如果你的其中一台数据库被台风、地震等自然灾害破坏,数据仍然会被保留。你无需担心数据丢失,因为数据被复制到多个位置。
- 高可用性:通过在不同位置复制数据,即使一台数据库离线,你的网站仍然可以运行,因为你可以访问存储在另一个数据库服务器中的数据。
在前面的部分,我们讨论了负载均衡器如何帮助提高系统的可用性。在这里我们提出相同的问题:如果其中一个数据库离线怎么办?图1-5中讨论的架构设计可以处理这种情况:
- 如果只有一个从数据库可用且它离线,读操作将临时指向主数据库。一旦发现问题,一个新的从库将会替换掉旧的从库,如果有多个从数据库是可用的,读操作会被转发到其他健康的从数据库,
- 如果主数据库离线,一个从库会被提升为新的主库,所有的数据库操作都会临时在新的主库上执行。一个新的从库将会立即替换旧的从库进行数据复制。在生产系统中,提升一个新的主数据库更为复杂,因为从库中的数据可能不是最新的,丢失的数据需要通过运行数据恢复脚本来更新。尽管一些其他的复制方法,如多主复制和循环复制,可能有所帮助,但他们的配置更加复杂;这些讨论将超出本书的讨论范围,有兴趣的读者可以参考列出的参考资料[4][5]。
图1-6展示了在添加负载均衡器和数据库复制后的系统设计。
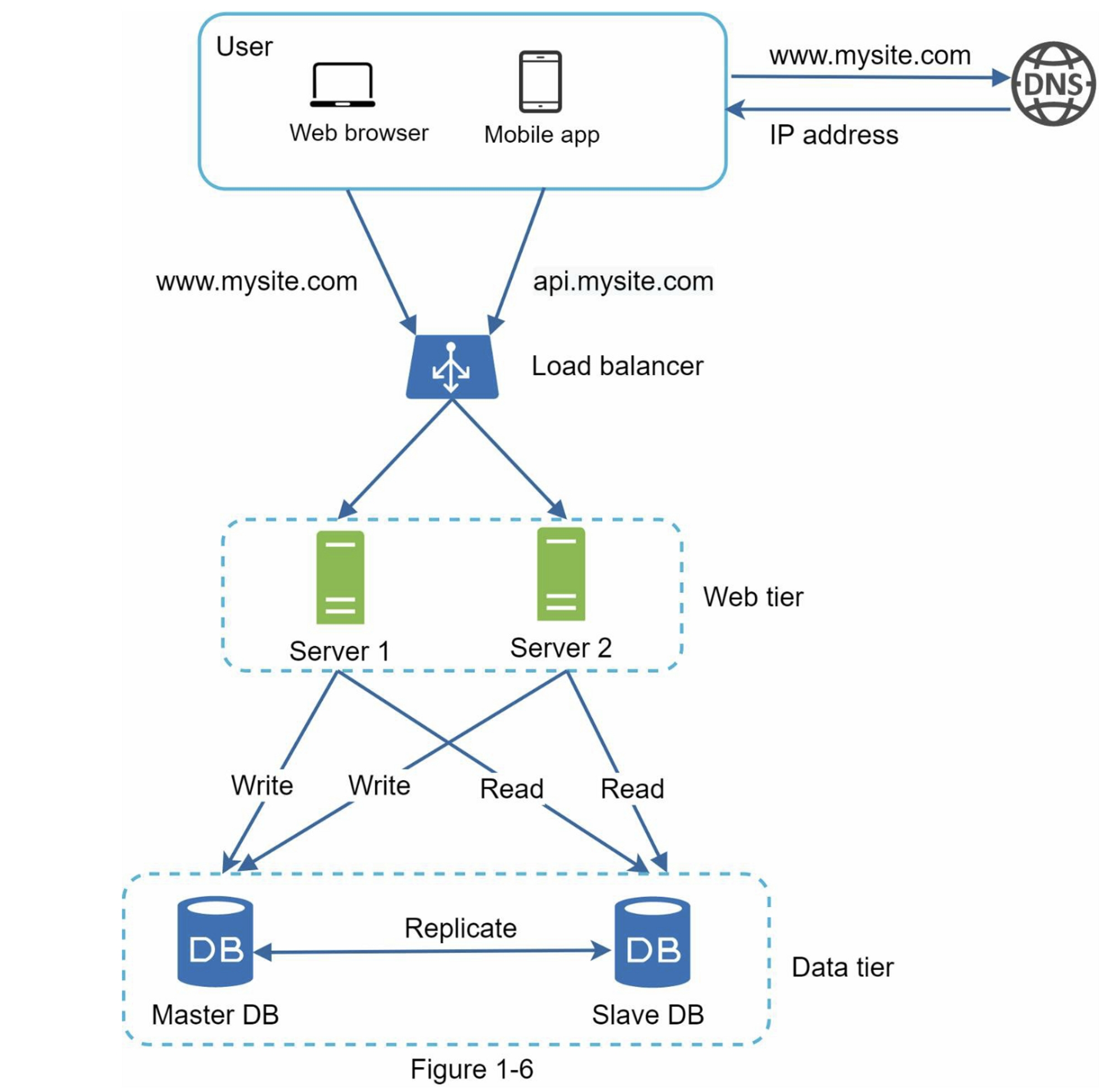
让我们来看一下这个设计:
- 用户从DNS获取负载均衡器的IP地址
- 用户使用这个IP地址连接到负载均衡器
- HTTP请求被路由到Server 1或Server 2。
- Web服务器从从数据库读取用户数据
- Web服务器将任何修改数据的操作路由到主数据库,这包括写入,更新和删除操作。
现在,你已经对web层和数据库层已经有了一个深刻的理解,是时候提升负载/响应时间了。这可以通过添加缓存层并将静态内容(JavaScript/CSS/图像/视频文件)移至内容分发网络(CDN)来完成。
缓存
缓存是一个临时存储区域,用于将昂贵的响应结果或频繁的访问数据存储在内存中,以便之后的请求能被更快的处理。如图1-6所示,每当加载新的网页时,会执行一个或多个数据库调用来获取数据。通过重复调用数据库,应用程序的性能会受到很大影响。缓存可以缓解这个问题。
缓存层
缓存层是一个临时的数据存储层,比数据库更快。拥有独立的缓存层的好处包括更好的系统性能、减轻数据库负载的能力以及能够独立扩展缓存层。图1-7展示了一个可能的缓存服务器设置:

在接收到请求后,Web服务器首先检查缓存是否有可用的响应。如果有,它将数据发送回客户端。如果没有,它会查询数据库,保存响应结果到缓存中,并将其发送回客户端。这种缓存策略称为读取穿透缓存。根据数据类型、大小和访问模式,还有其他可用的缓存策略。之前的一项研究解释了不同缓存策略的工作原理[6]。
与缓存服务器的交互很简单,因为大多数缓存服务器提供了常见编程语言的API。以下代码显示了典型的Memcached API:

使用缓存的注意事项
这里有一些使用缓存系统的注意事项:
-
决定何时使用缓存:当数据频繁读取但不经常修改时,请考虑使用缓存。由于缓存数据存储在易失的内存中,所以缓存服务器不适合持久化数据。例如,如果缓存服务器重启了,内存中所有的数据都会丢失,因此,重要的数据应该保存在持久数据存储中。
-
过期策略:实施过期策略是个好习惯,一旦缓存数据过期,它就会从缓存中删除。当没有过期策略时,缓存数据将被永久的保存在内存中。建议不要将过期时间设置的太短,因为这会导致系统过于频繁地从数据库重新加载数据。于此同时,建议不要将过期时间设置的太长,因为数据可能会过时。
-
一致性:这涉及保持数据存储和缓存同步。一致性问题可能会发生,因为对数据存储和缓存的修改操作不在一个事务中。在跨多个区域扩展时,保持数据存储和缓存之间的一致性具有挑战性。有关更多信息,请参阅Facebook发布的“Scaling Memcache at Facebook”论文[7]。
-
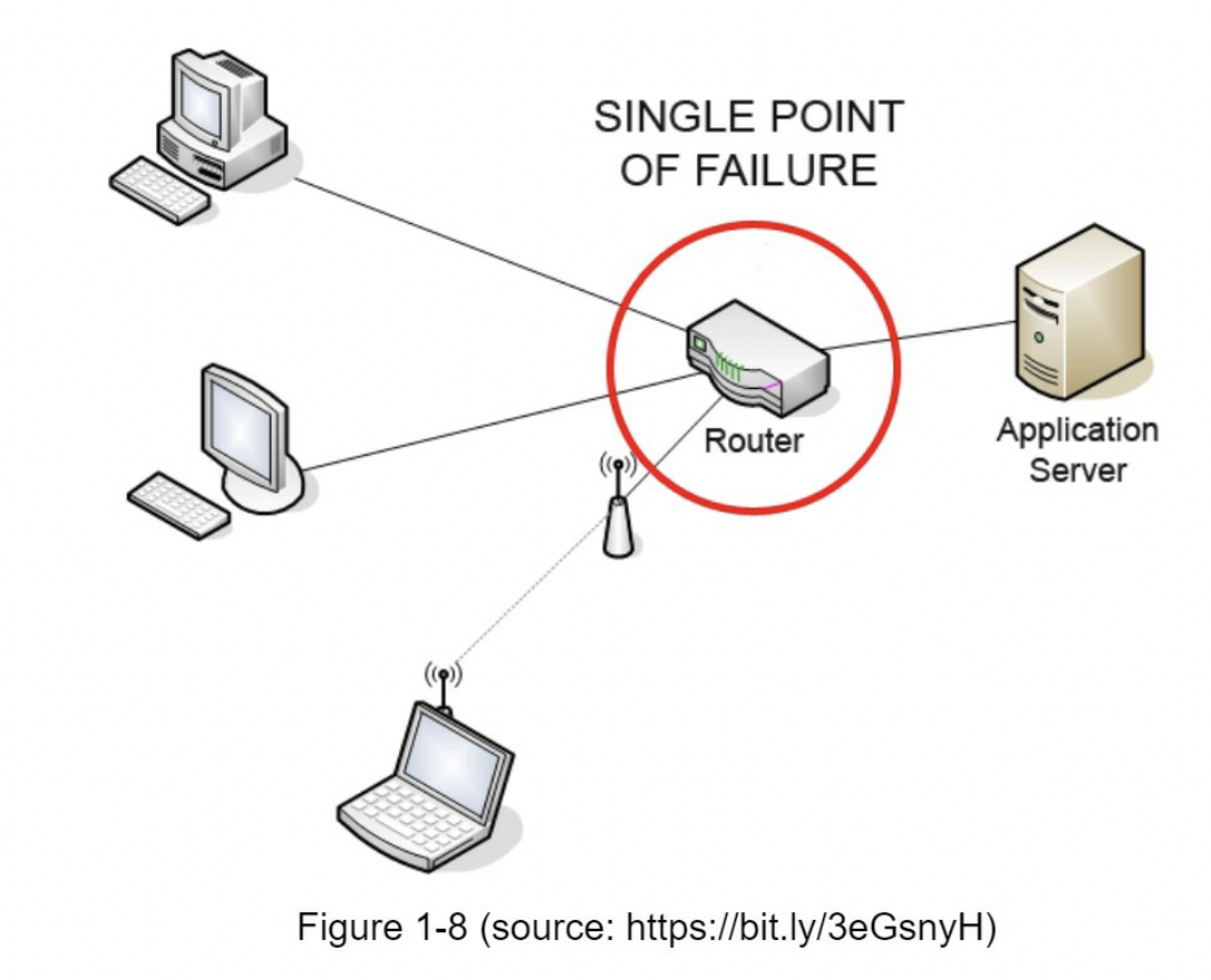
减少故障:单个缓存服务器代表了潜在的单点故障(SPOF),在维基百科中定义如下:“单点故障(SPOF)是系统的一部分,如果它发生故障,将使整个系统停止工作。”[8]。因此,建议在不同数据中心使用多个缓存服务器,以避免单点故障(SPOF)。另一种推荐的方法是通过配置比所需的大小还多一定百分比的内存。这在内存使用量上升的时候起到一个缓冲的效果。
-
驱逐策略:一旦缓存满了,任何尝试向缓存中添加内容的请求都可能导致现有项被移除,这称为缓存驱逐。最近最少使用(LRU)是最流行的缓存驱逐策略。可以使用其他逐出策略,例如:最不常用(LFU)或先进先出(FIFO),以满足不同的使用场景。
CDN
CDN(内容分发网络)是一个由地理上分散的服务器组成的网络,用于提供静态内容。CDN服务器缓存静态内容,如:图片、视频、CSS、JavaScript文件等。
动态内容缓存是一个相对较新的概念,超出了本书的范围。它支持缓存基于请求路径、查询字符串、Cookie和请求头缓存HTML页面。有关更多信息,请参阅参考资料[9]中提到的文章,本书重点介绍如何使用CDN缓存静态内容。
在高层次上,CDN的工作原理如下:当用户访问一个网站时,距离用户最近的CDN服务器将提供静态内容。直观的说,用户距离CDN服务器越远,网站加载速度就越慢。例如,如果CDN服务器位于旧金山,那么洛杉矶的用户将比欧洲的用户更快的获取内容。图1-9是一个很好的例子,展示了CDN如何缩减加载时间。
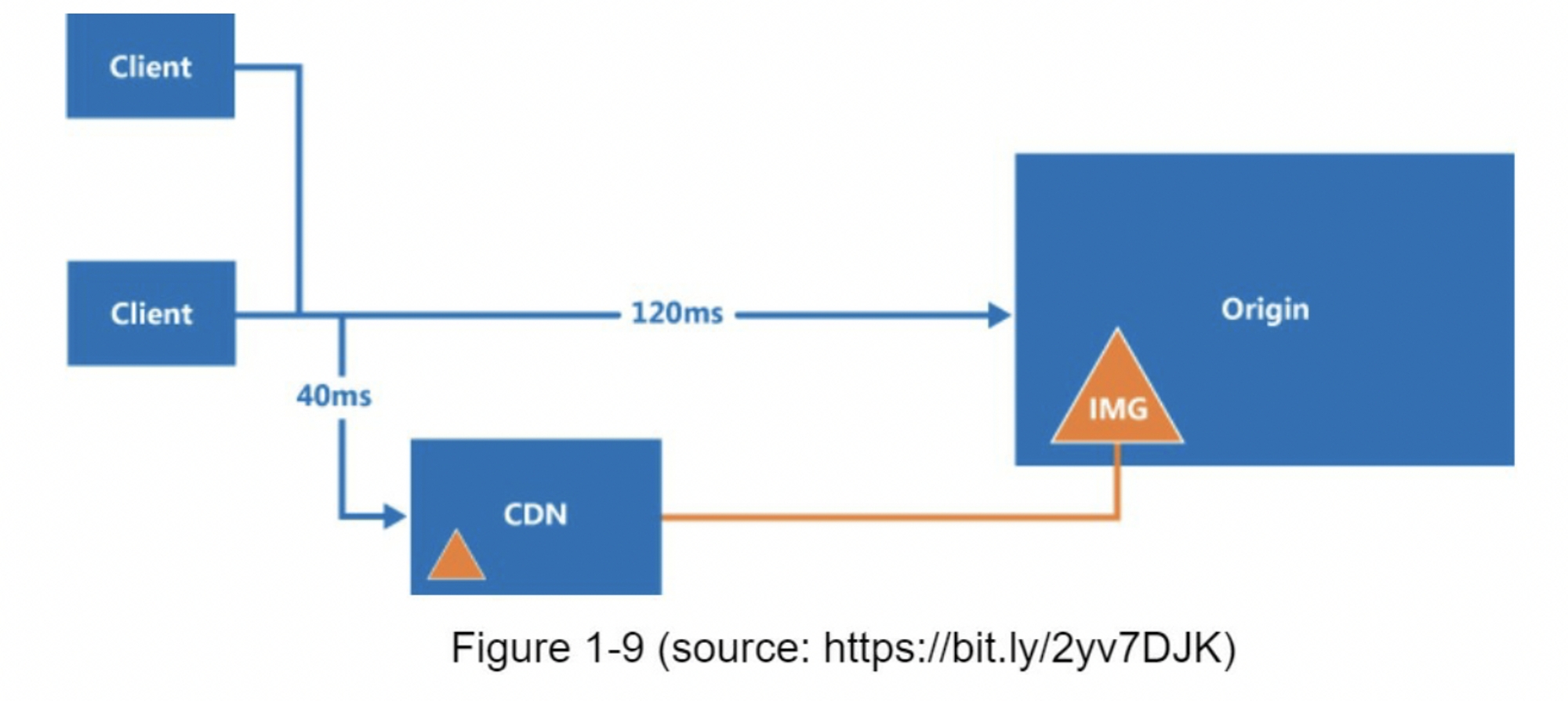
图1-10演示了CDN工作流程
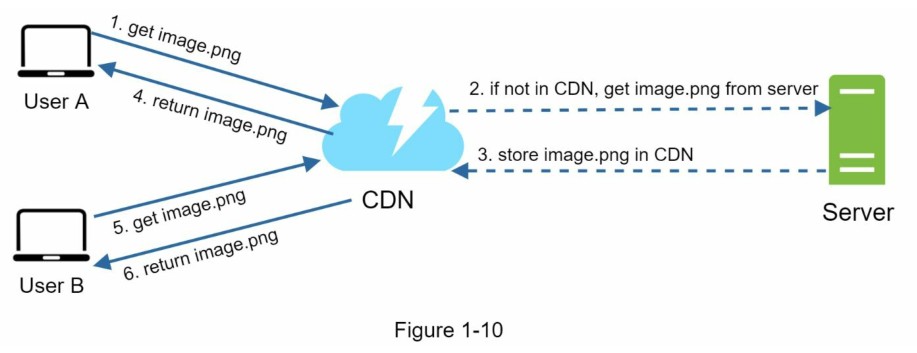
- 用户A尝试通过图片URL获取image.png。这个URL的域名是由CDN提供商提供,以下两个图像URL是用于演示URL在Amazon和Akamai CDN上的示例:
- https://mysite.cloudfront.net/logo.jpg
- https://mysite.akamai.com/image-manager/img/logo.jpg
- 如果CDN服务器缓存中没有这个图片image.png,CDN服务器会从源(可以是Web服务器或在线存储,如Amazon S3)请求文件。
- 源返回image.png给CDN服务器,并包含可选的HTTP头部Time-to-Live(TTL),它表示图像被缓存的时间有多长。
- CDN缓存图像并将其返回给用户A。在TTL过期之前,图像一直被缓存在CDN中。
- 用户B发送一个请求获取相同的图片
- 只要TTL尚未过期,图像就会从缓存中返回。
使用CDN时需要考虑的因素
- 成本:CDN由第三方提供商运行,你需要为进出CDN的数据传输付费,对于很少使用的缓存资源,提供不了显著的好处,因此您应该考虑将它们移出CDN。
- 设置适当的缓存过期时间:对于时间敏感的内容,设置缓存过期时间是很重要的,缓存过期时间既不应该太长,也不应该太短。如果时间太长,内容可能不再新鲜,如果时间太短,可能导致反复从源服务器重新加载内容到CDN。
- CDN回源:你应该考虑你的网站/应用程序如何处理CDN故障,如果出现临时CDN中断,客户端应该能够检测问题并从源请求资源。
- 使文件无效:在缓存过期之前,您可以通过执行以下操作之一从CDN中删除文件:
- 通过CDN服务商提供的API使CDN对象失效
- 使用对象版本控制来提供不同版本的对象。对对象进行版本控制,可以向URL中添加参数例如版本号,例如:在查询字符串中添加版本号2:image.png?v=2。
添加CDN和缓存后的设计如图1-11 所示
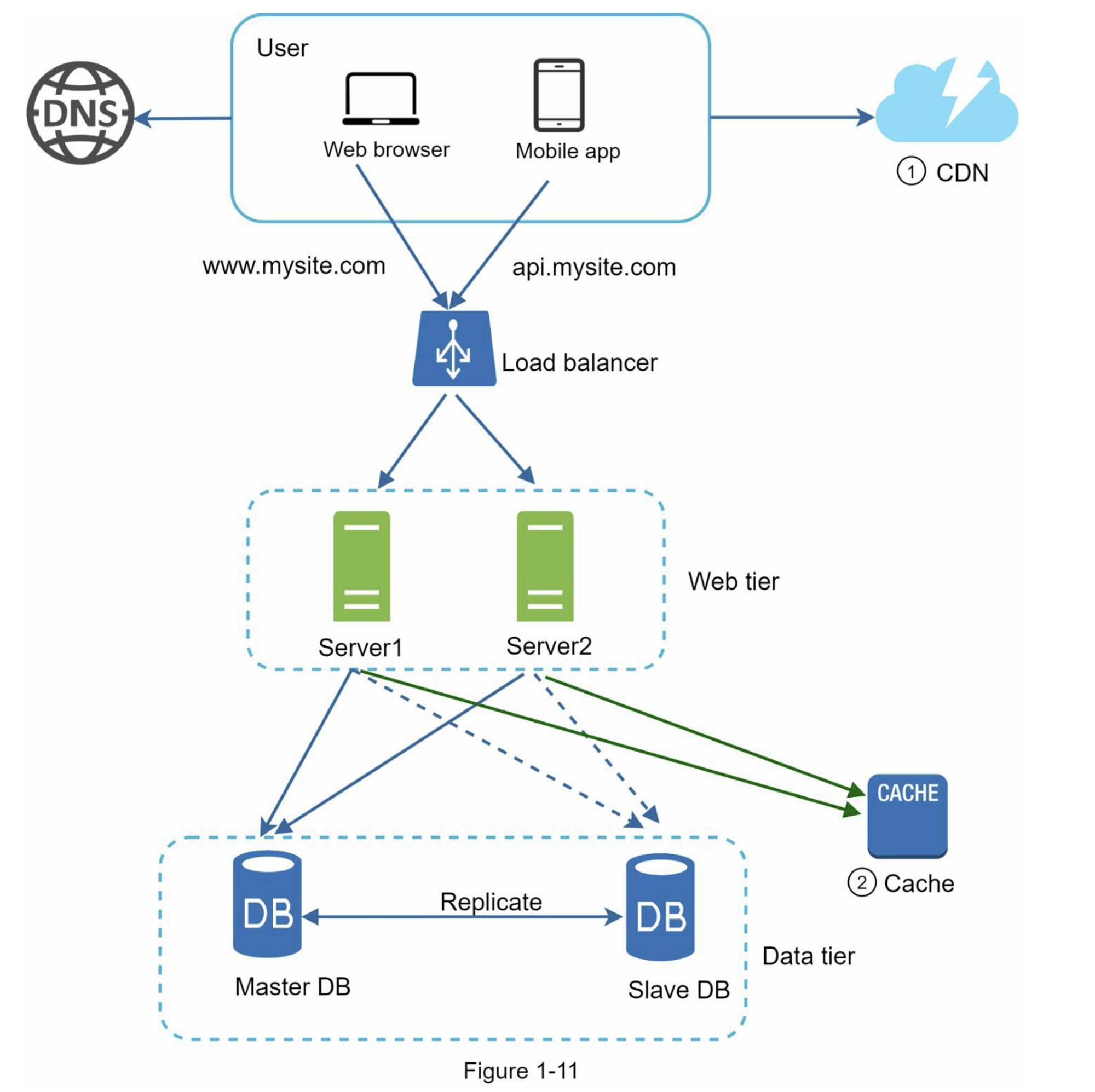
- Web服务器不再提供静态资产(JS、CSS、图像等),它们从CDN获取以获得更好的性能。
- 通过缓存数据,减轻了数据库的负载。
无状态的Web层
现在是时候考虑水平扩展Web层了,为此,我们需要将状态(例如用户会话数据)移出Web层。一个好的做法是将会话数据存储在持久性存储中,比如关系型数据库或NoSQL。集群中的每个Web服务器都可以从数据库中访问状态数据,这被称为无状态的Web层。
有状态架构
有状态服务和无状态服务有一些关键区别。有状态服务器会在一个请求到下一个请求时记住客户端数据(状态)。无状态服务不会保留任何状态信息。
图1-12展示了一个有状态架构的示例。
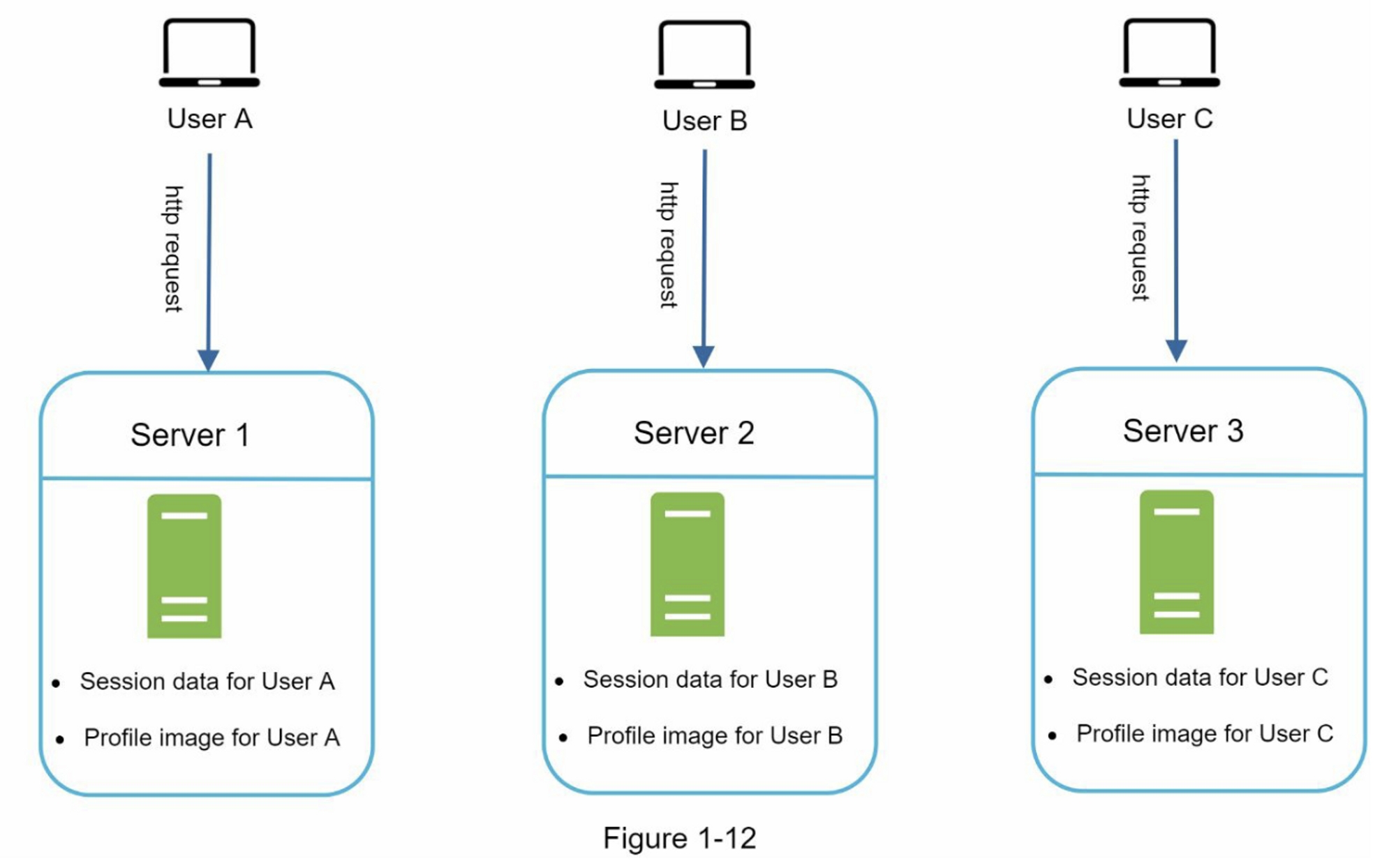
在图1-12 中,用户A的会话数据和头像数据存储在Server 1中,要对用户A进行身份验证,必须将HTTP请求路由到Server 1,如果将请求发送到其他服务器,比如Server 2,身份验证将失败,因为Server 2不包含用户A的会话数据。同样,用户B的所有Http请求都必须路由到Server 2,所有来自用户C的请求必须发送到Server 3。
问题在于,来自同一客户端的每个请求必须路由到同一台服务器。在大多数负载均衡器中,可以使用粘性会话(sticky sessions)来实现这一点[10];然而,这会增加开销,使用这种方法更难添加或删除服务器,处理服务器故障也是一个挑战。
无状态的架构
无状态架构如图1-13所示
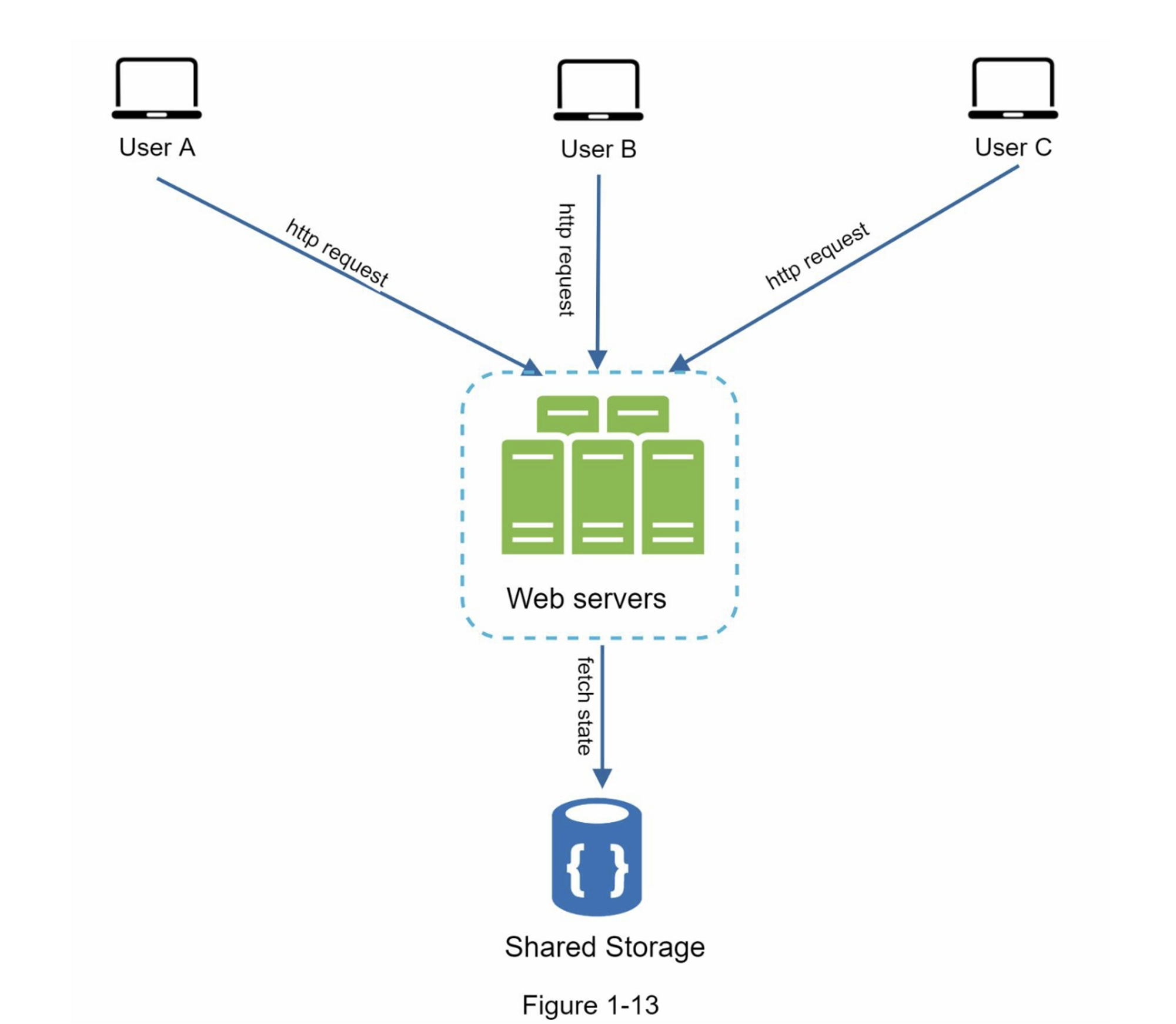
在这个无状态架构中,来自用户的HTTP请求可以被发送到任何Web服务器,并从共享的数据存储中获取状态数据。状态数据存储在共享的数据存储中,并且不存储在Web服务器中,一个无状态的系统更简单、更健壮且可扩展。
图1-14展示了带有无状态Web层的更新设计
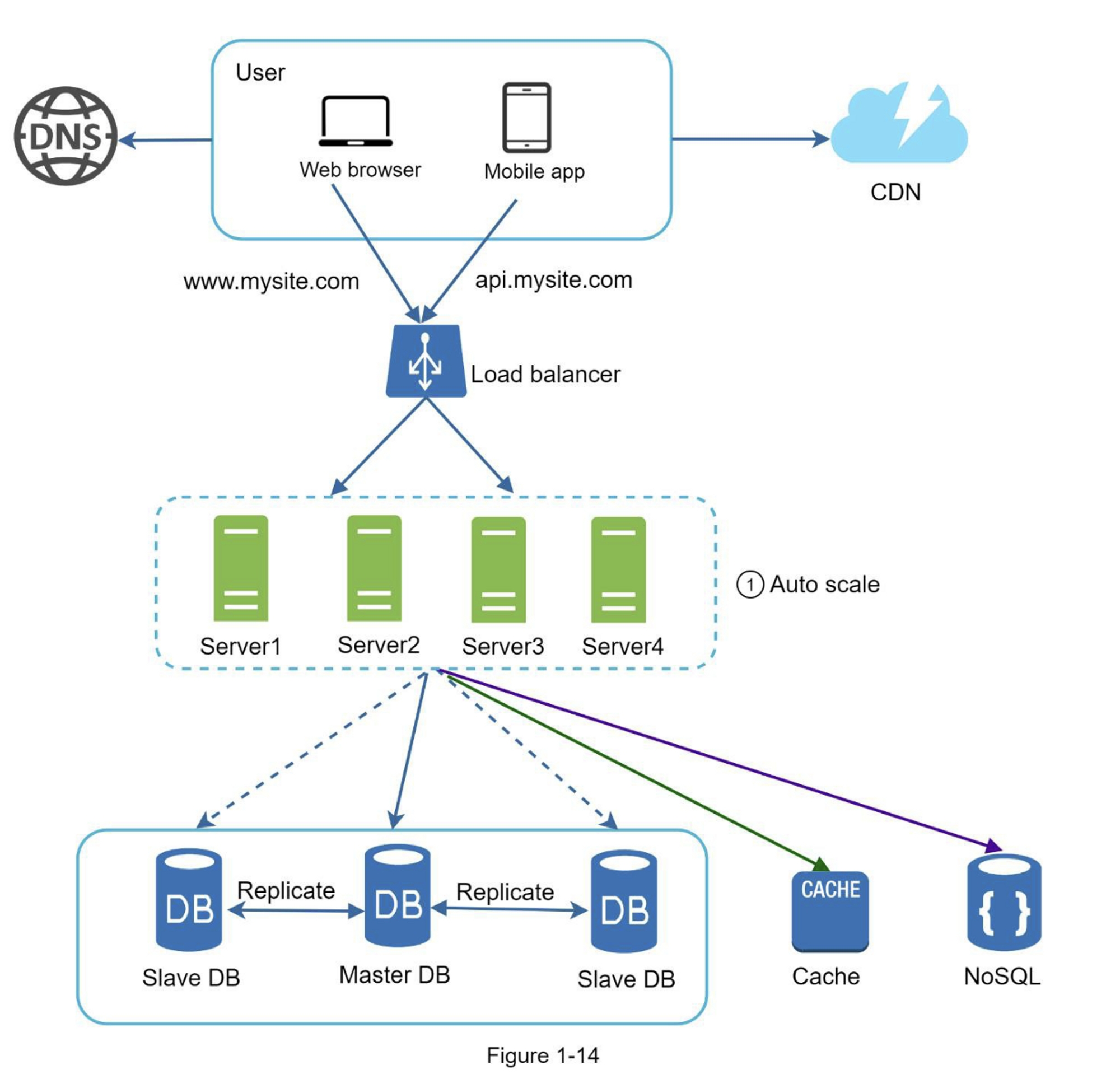
在图1-14中,我们将会话数据从Web层移出,并将其存储在持久数据存储中。共享的数据存储可以是关系型数据库,Memcached/Redis, NoSQL等。选择NoSQL数据存储是因为它易于扩展。自动扩展意味着根据流量负载自动添加或删除Web服务器。在将状态数据移出Web服务器后,可以根据流量负载添加或删除服务器,从而轻松实现Web层的自动扩展。
你的网站发展迅速,并吸引了大量国际用户,为了提高可用性并在更广泛的地理区域提供更好的用户体验,支持多个数据中心至关重要。
数据中心
图1-15显示了具有两个数据中心的示例设置。在正常运行时,用户通过geoDNS路由(也称为地理路由)到最近的数据中心,美国东部的流量为x%,美国西部的流量为(100-x)%。geoDNS是一种DNS服务,允许根据用户的位置将域名解析为IP地址。
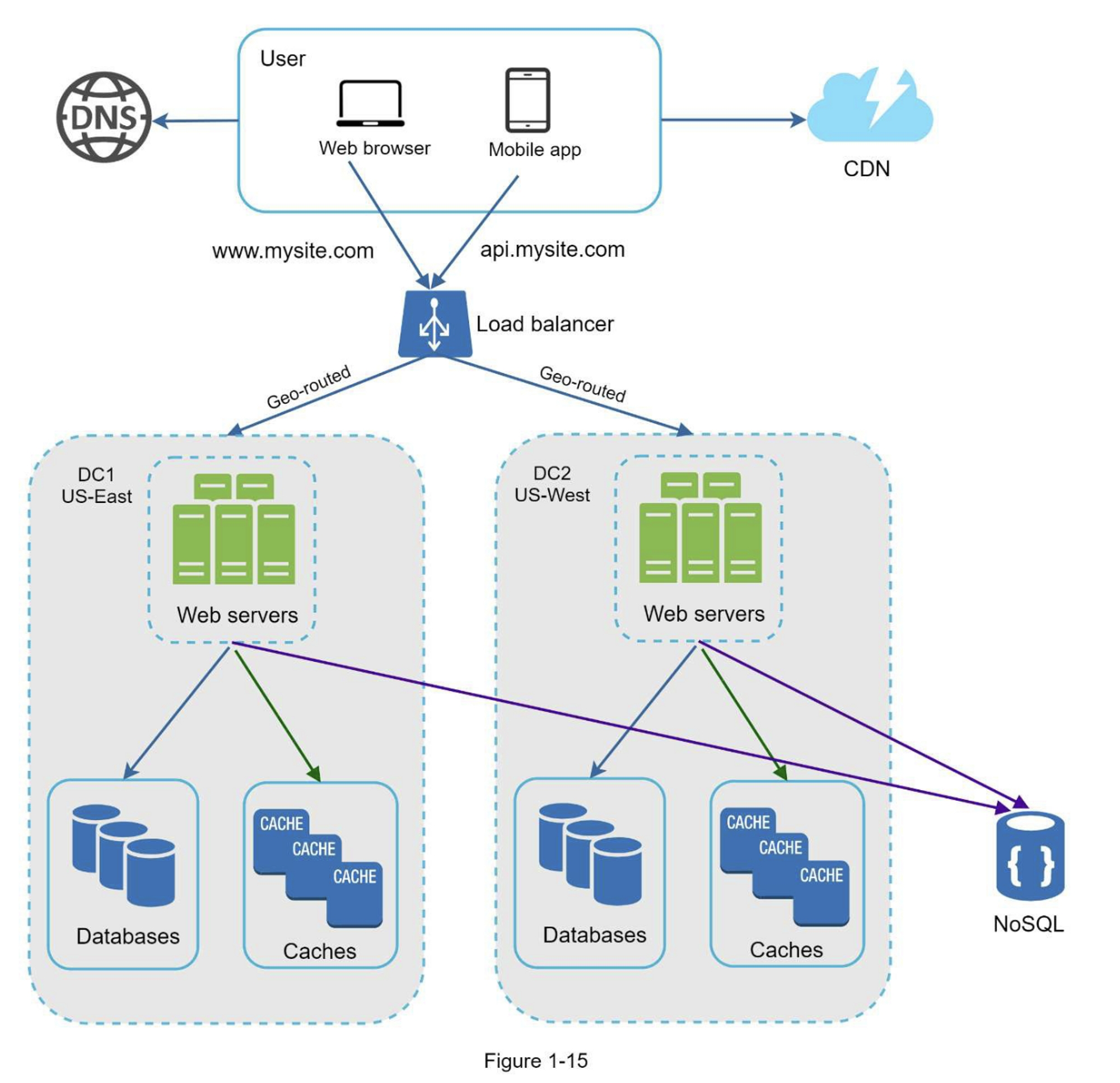
在发生任何重大数据中心中断的情况下,我们将所有流量引导到一个健康的数据中心。图1-16中,数据中心2(美西)处于离线状态,100%的流量路由到数据中心1(美东) 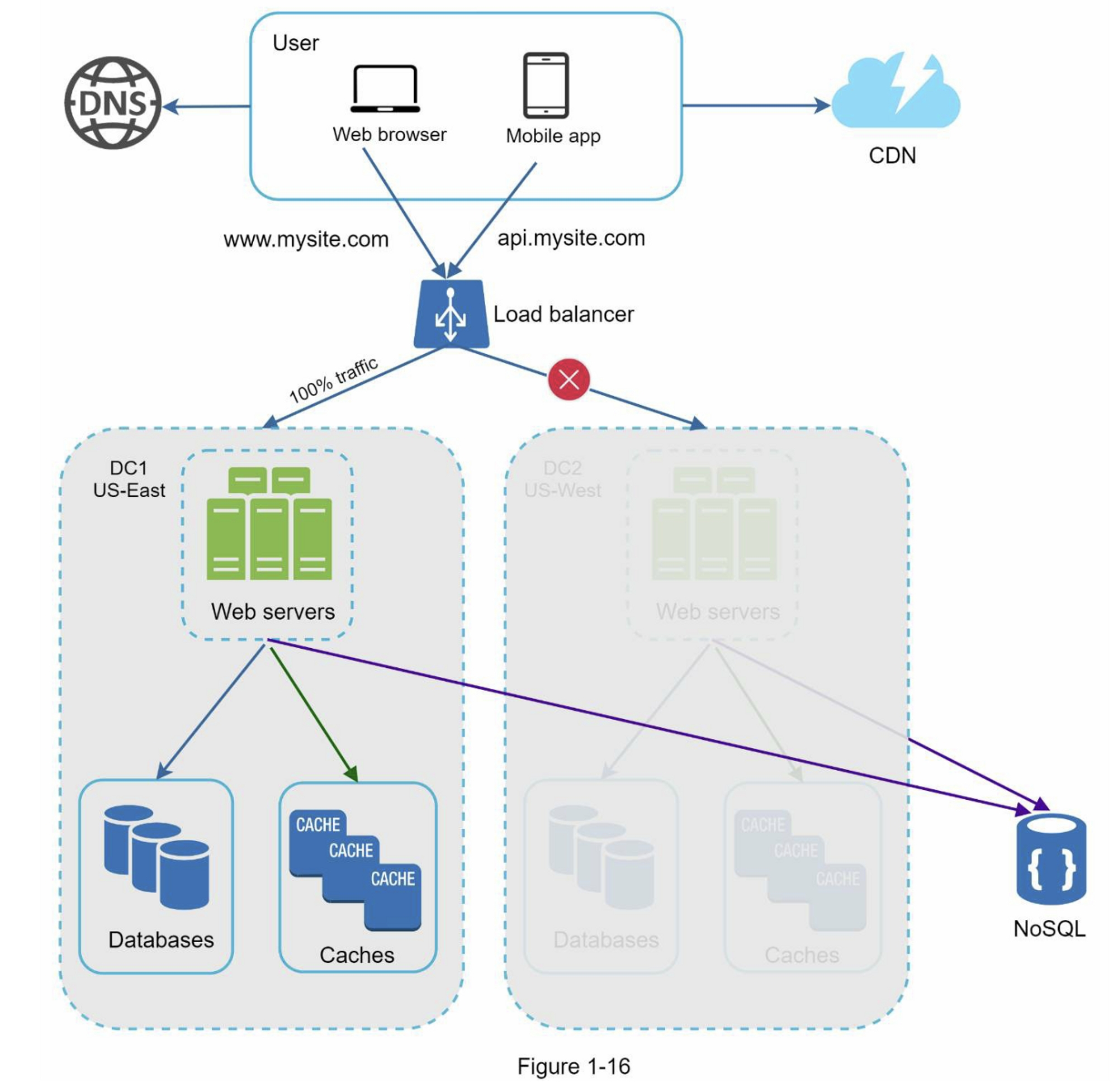
要实现多数据中心配置,必须要解决几个技术难题:
- 流量重定向:需要有效的工具将流量重定向到正确的数据中心。geoDNS可以根据用户位置将流量引导至用户最近的数据中心。
- 数据同步:来自不同地区的用户可以使用不同的本地数据库或缓存,在故障转移的情况下,流量可能被路由到不可用的数据中心。一种常见的策略是跨多个数据中心复制数据。之前的研究展示了Netflix如何实现异步多数据中心复制[11]
- 测试和部署:对于多数据中心设置,在不同位置测试网站/应用程序非常重要,自动化部署工具对于保持所有数据中心的服务一致性至关重要 [11]。
为了更进一步扩展我们的系统,我们需要解耦系统的不同组件,使它们可以独立扩展。消息队列是许多实际分布式系统采用的关键策略,用于解决这个问题。
消息队列
消息队列是一个持久性组件,存储在内存中,支持异步通信,它充当缓冲区并分发异步请求。消息队列的基础架构非常简单,输入服务,被称为生产者/发布者,创建消息,并将它们发送到消息队列中。其他服务或服务器,称为消费者/订阅者,连接到队列,并执行消息定义的动作。
模型如图1-17所示
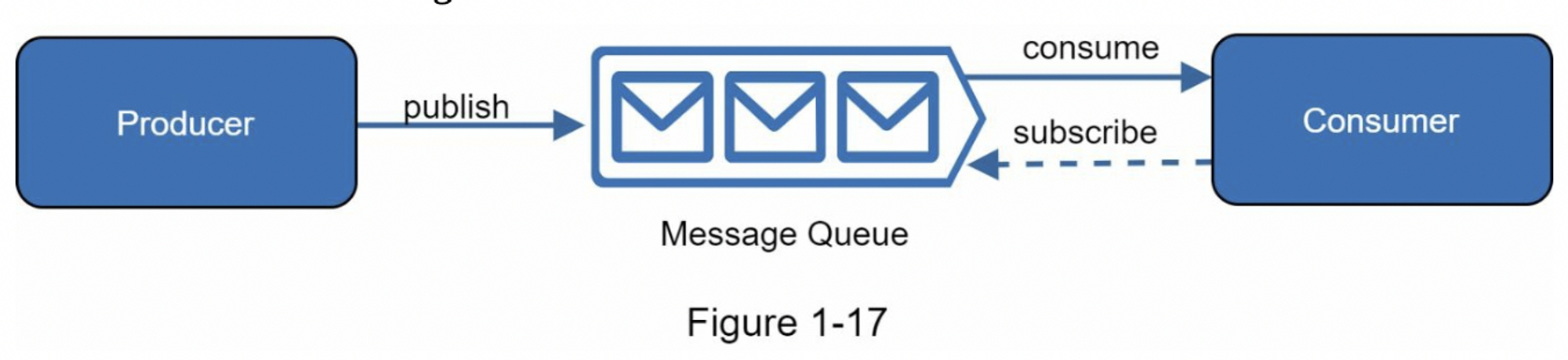
解耦使消息队列成为构建可伸缩且可靠的应用程序的首选架构。使用消息队列,生产者可以在消费者无法处理消息时将消息发布到队列中。即使生产者不可用,消费者也可以从队列中获取数据。
考虑下面的用例:你的应用程序支持照片自定义,包括剪裁、锐化、模糊等。这些定制任务需要一些时间才能完成。在图1-18中,Web服务器将照片处理作业发布到消息队列。照片处理工作者从消息队列中获取作业并异步执行照片定制任务。生产者和消费者可以独立扩展,当队列的大小变得很大时,添加更多的工作者以减少处理时间。但是,如果队列大部分时间为空,则可以减少工作者的数量。 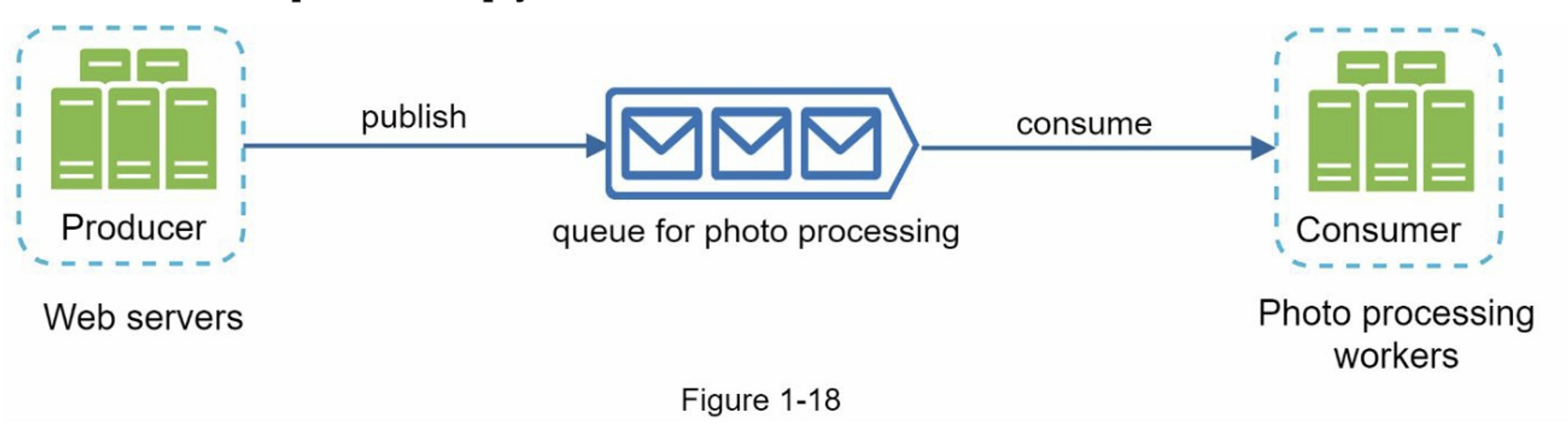
日志记录、指标、自动化
当处理运行在少量服务器上的小型网站时,日志记录、指标、和自动化支持是很好的选择,但并不是必须的。但是,现在你的网站已经发展成为一个大型业务,那么投资这些工具是必不可少的。
日志记录:监控错误日志是重要的,因为它有助于识别系统中的错误和问题。您可以在每个服务器级别监视错误日志,或使用工具将它们汇总到一个集中的服务中,以便于搜索和查看。
指标:收集不同类型的指标有助于我们获得业务洞察能力和了解系统的健康状态。以下一些指标是有用的:
- 主机级别的指标:CPU、内存、磁盘I/O等
- 聚合级别的指标:例如,整个数据库层、缓存层的性能
- 关键业务指标:每日活跃用户、留存数、收入等
自动化:当系统变得庞大而复杂时,我们需要构建或利用自动化工具来提高生产力。持续集成是一种很好的做法,其中每次代码提交都通过自动化进行验证,使团队能够及时发现问题。此外,将你的构建、测试、部署过程等自动化,可以显著提高开发人员的生产力。
添加消息队列和不同的工具
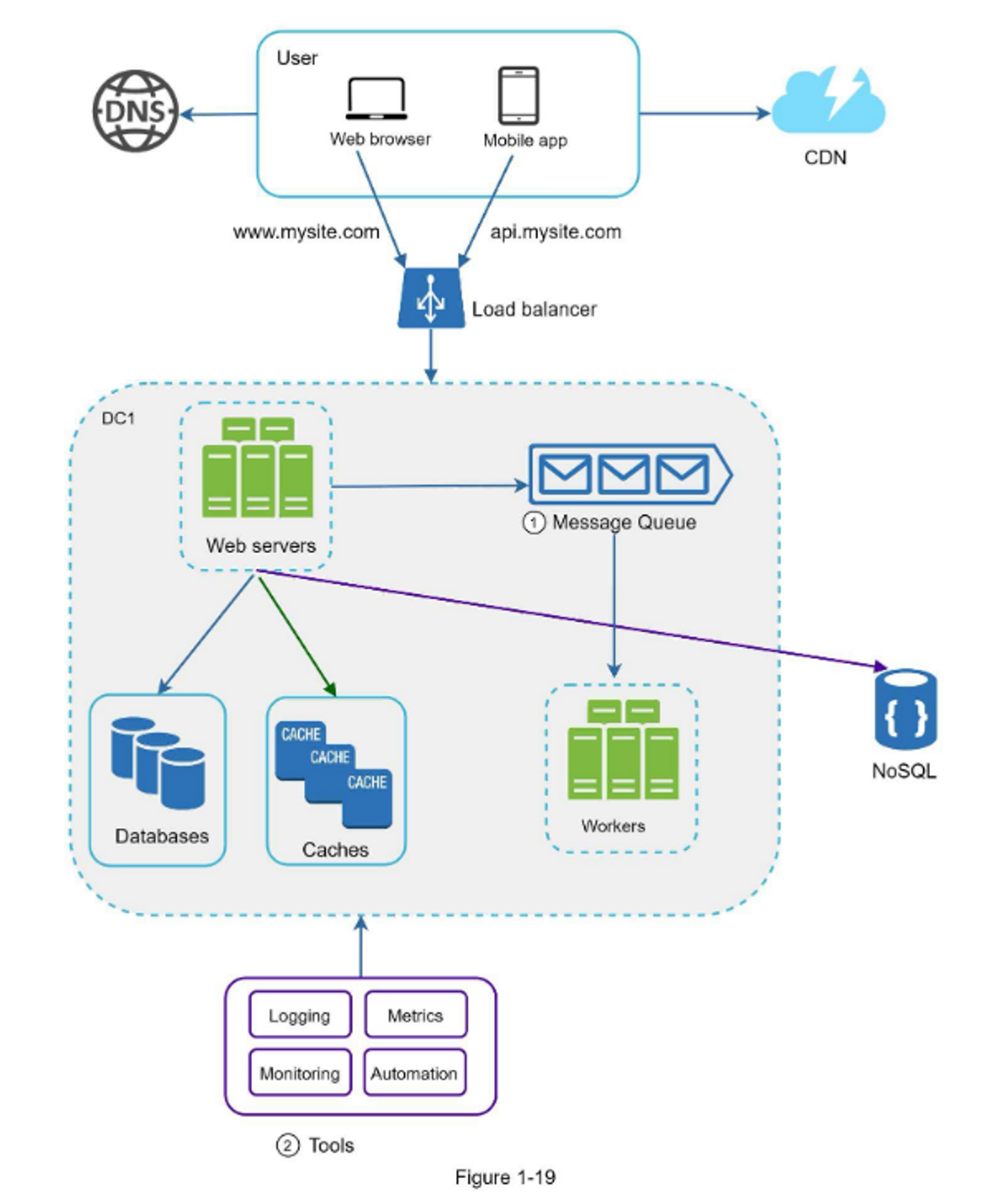
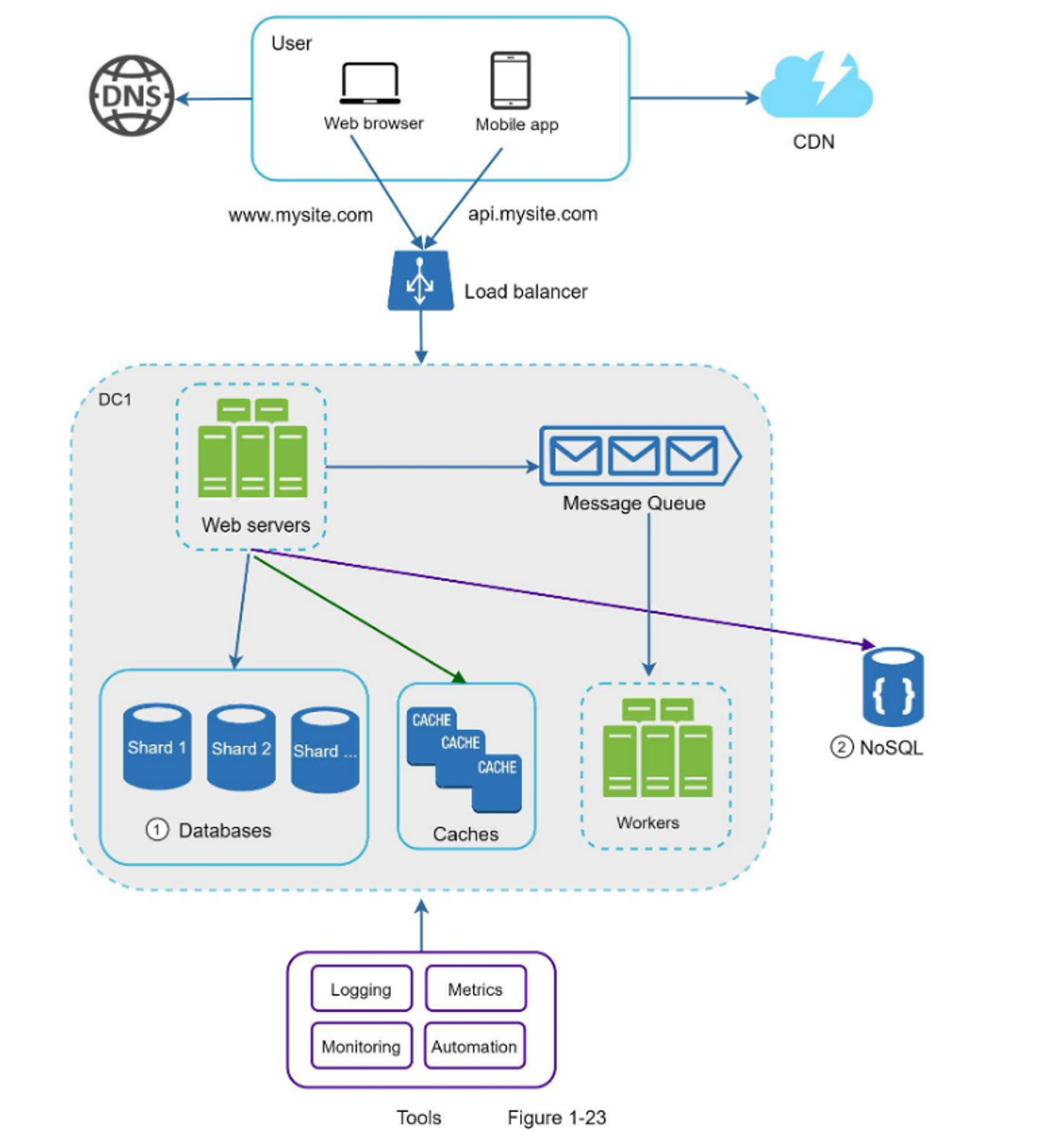
图1-19展示了更新后的设计,限于篇幅有限,图中仅显示了一个数据中心。
- 该设计包含一个消息队列,有助于使系统更松耦合和故障恢复能力。
- 日志记录、监控、指标、自动化工具也包括其中。
随着数据每天的增长,你的数据库负载越来越重,是时候扩展数据层了。
数据库扩展
这里有两种广泛的数据库扩展方法:垂直扩展和水平扩展
垂直扩展
垂直扩展,也被称为向上扩展,是通过向现有机器添加更多资源(如CPU、内存、磁盘等)来进行扩展的。
有一些强大的数据库服务器。根据亚马逊关系数据库服务(RDS)[12],你可以得到一个 24TB 内存的数据库服务器。这种强大的数据库服务器可以存储和处理大量的数据。例如,stackoverflow.com在2013年有超过1000万的每月独立访客,但它只有1个主数据库[13]。
然而,垂直扩展也有一些严重的缺点:
- 你可以向你的服务器中添加更多的CPU、内存等,但是是有硬件限制的。如果你有一个庞大的用户群,一台服务是不够的。
- 单点故障的风险更大
- 垂直扩展的总体成本更高,强大的服务器要贵得多。
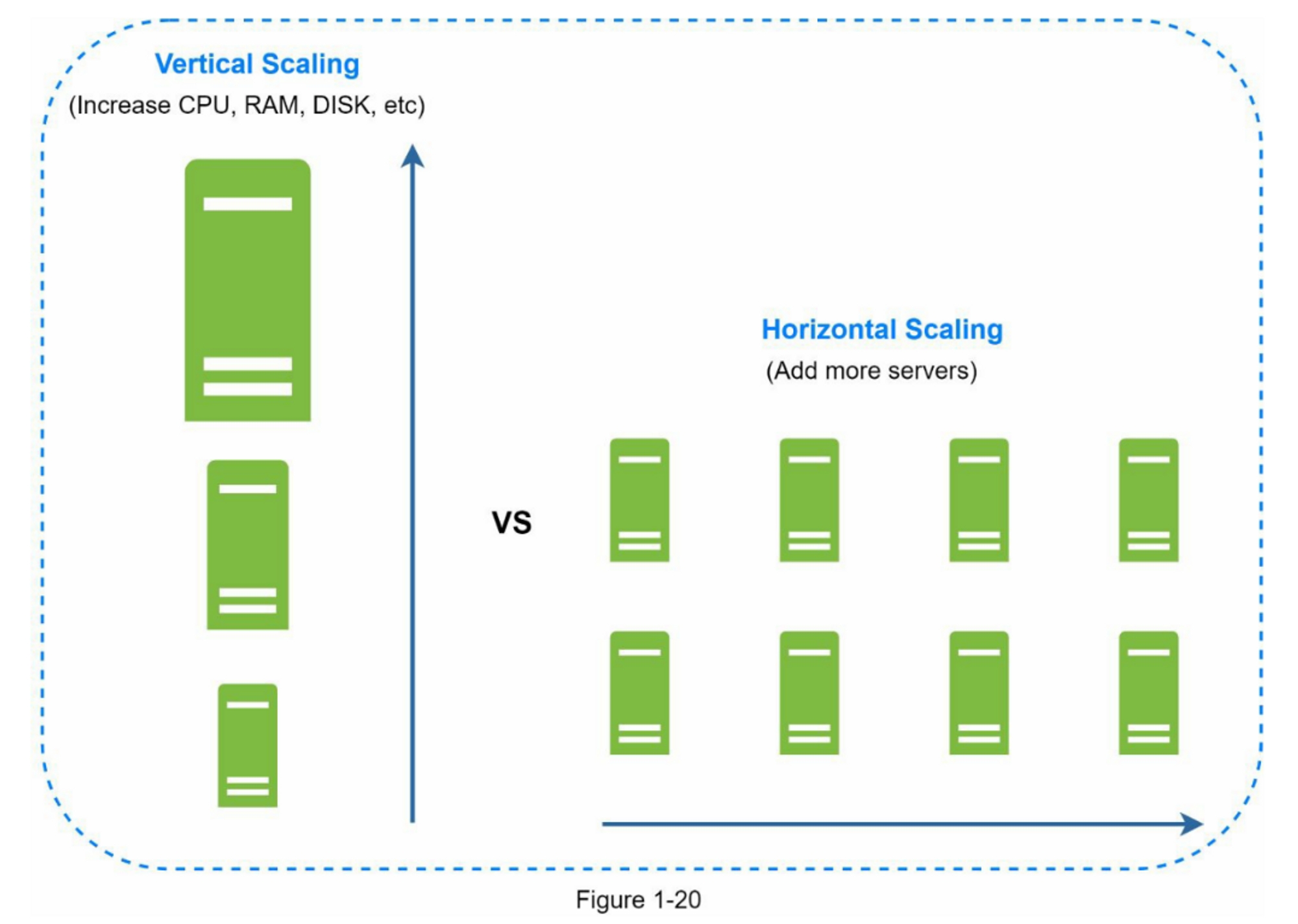
水平扩展
水平扩展,也称为分片,是添加更多服务器的做法。图1-20比较了垂直扩展和水平扩展。
分片将大型数据库分成更小、更易于管理的部分,称为分片。每个分片共享相同的模式,尽管每个分片上的实际数据对该分片来说是独一无二的。
图1-21展示了一个分片数据库的示例。用户数据根据用户ID分配到数据库服务器。每次访问数据时,都会使用哈希函数来找到相应的分片。在我们的示例中,user_id % 4 被用作hash函数。如果结果为0,则使用分片0来存储和提取数据。如果结果为1,则使用分片1。其他分片采用相同的逻辑。
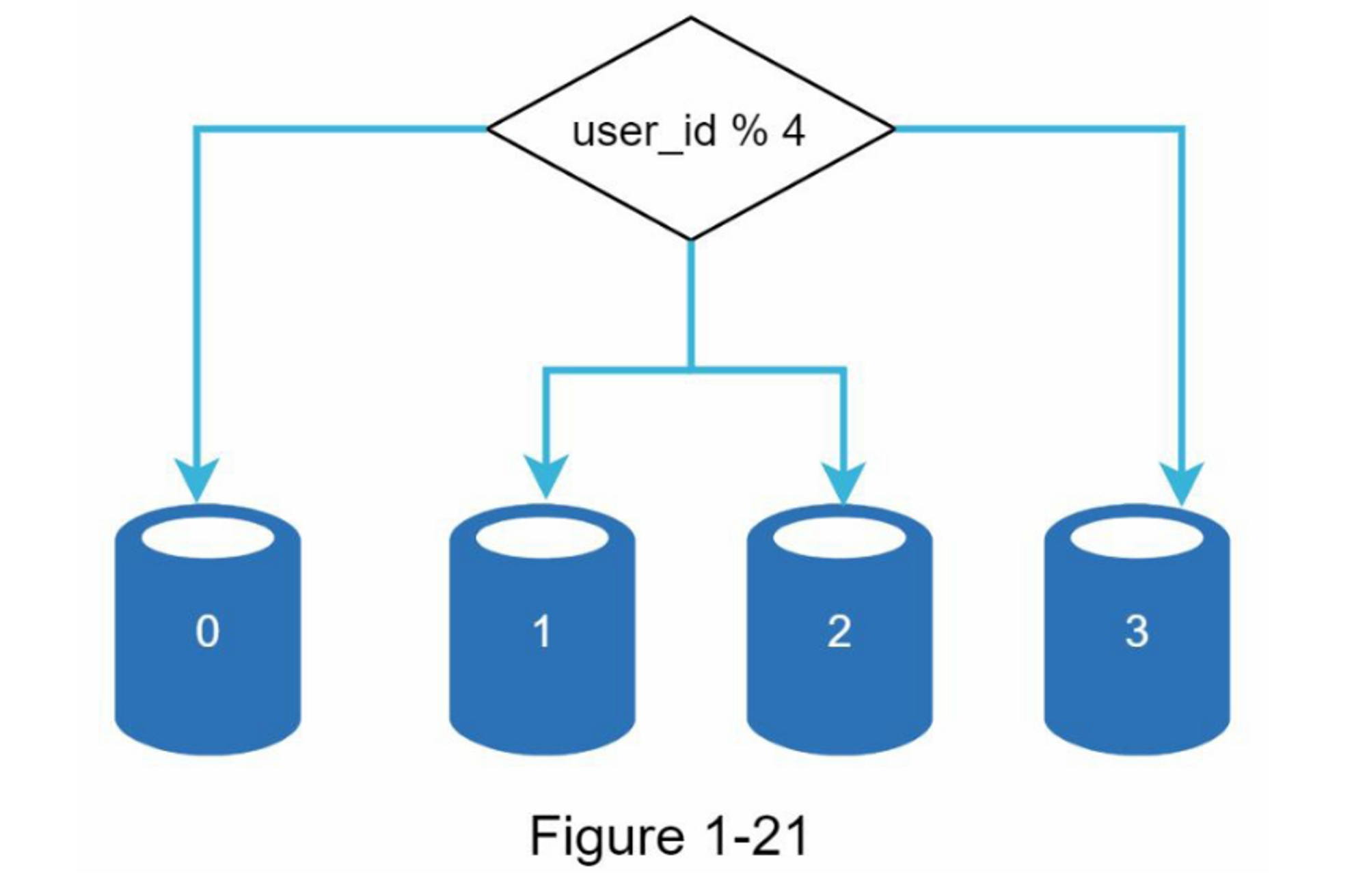
图1-22 显示了在分片数据库中的用户表
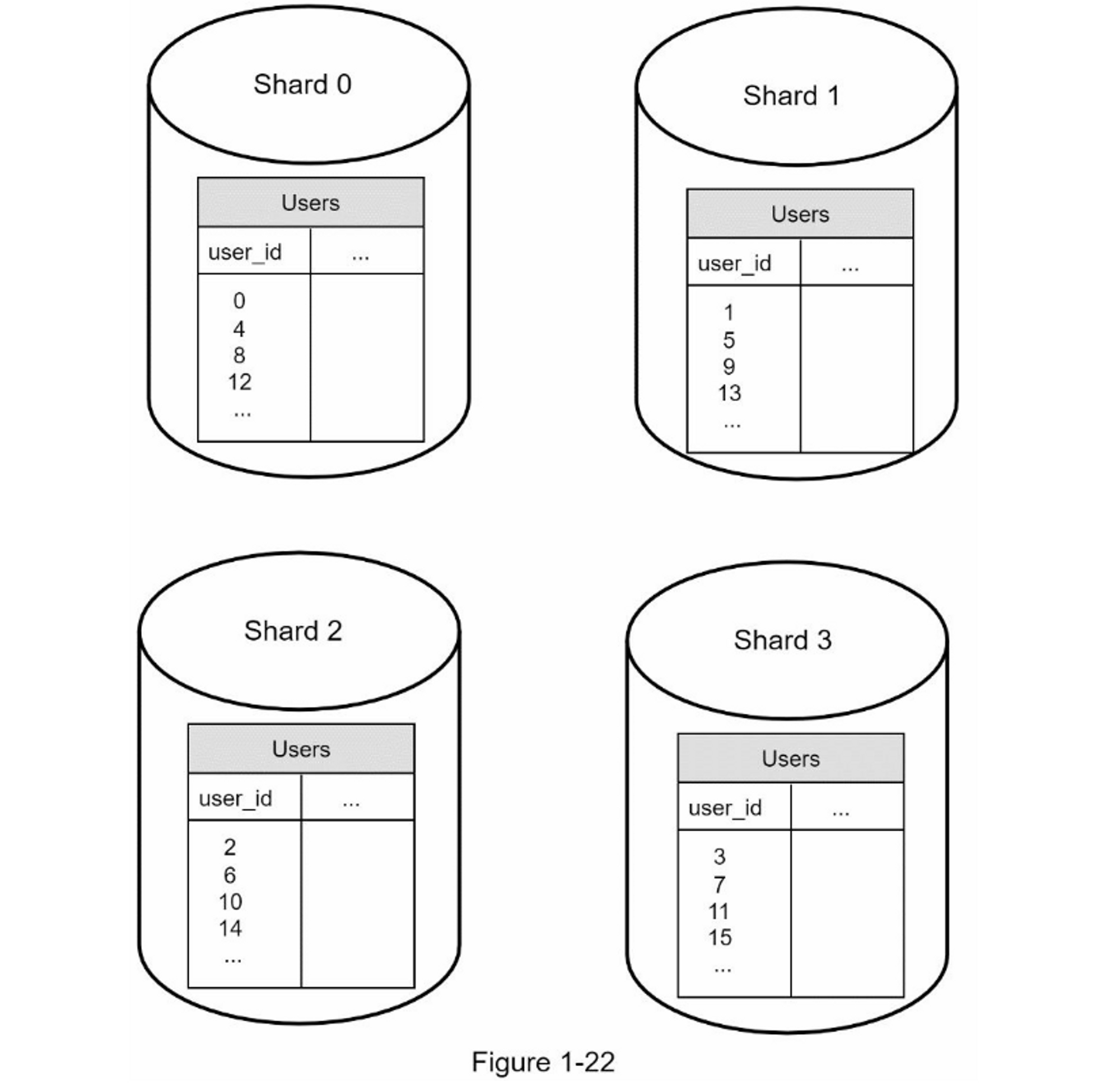
分片键的选择是实施分片策略时要考虑的重要因素。分片键(也称为分区键)由一个或多个列组成,决定数据的分布方式。如图1-22所示,“user_id”是分片键,分片键允许你将数据库查询路由到正确的数据库来高效地检索和修改数据。在选择分片键时,最重要的一个指标是选择一个可以均匀分布数据的键。
分片是扩展数据库的一项伟大技术,但它远不是一个完美的解决方案。它为系统引入了复杂性和新的挑战:
- 重新分片数据:在以下情况,需要从新分片数据。
- 由于快速增长,单个分片无法再容纳更多数据
- 由于数据分布不均匀,某些分片可能比其他分片更快被耗尽,当分片耗尽时,需要更新分片功能并移动数据。一致性哈希,将在第5章中讨论,是解决此问题的常用技术。
- 名人问题:这也被称为热点键问题。对一个特定分片的过度访问可能会导致服务器过载。想象一下 Katy Perry、Justin Bieber 和 Lady Gaga 的数据最终都在同一个分片上,对于社交应用来说,这个分片将会被读操作淹没。为了解决这个问题,我们可能需要为每一个名人分配一个分片,每个分片甚至可能需要进一步分区。
- 连接和去范式化:一旦数据库跨多个服务分片,就很难跨数据库分片执行连接操作。常见的解决方法是对数据库进行去范式化,以便可以在单个表中执行查询。
在图1-23中,我们对数据库进行分片,以支持快速增长的数据流量。同时,一些非关系型功能被移动到NoSQL数据存储中,以减轻数据库负载。这里有一篇文章介绍了很多NoSQL的使用案例[14]。
百万用户及以上
扩展系统是一个持续迭代的过程。重复我们在本章中学到的知识可以使我们走的更远。为了超越百万用户,需要更多的微调和新的策略。例如,你可能需要优化你的系统,将系统解耦为更小的服务。本章所学的知识为应对新的挑战提供了一个良好的应对基础。在本章最后,我们提供了一个关于我们如何扩展我们系统以支持数百万用户的总结:
- 保持Web层无状态
- 在每一层建立冗余
- 尽可能缓存数据
- 支持多个数据中心
- 在CDN中托管静态数据
- 通过分片扩展数据层
- 将层拆分为单独的服务
- 监控你的系统并使用自动化工具
祝贺您走到这一步!现在给自己一个鼓励,干得漂亮!
参考资料
[1] Hypertext Transfer Protocol: https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol
[2] Should you go Beyond Relational Databases?: https://blog.teamtreehouse.com/should-you-go-beyond-relational-databases
[3] Replication: https://en.wikipedia.org/wiki/Replication_(computing)
[4] Multi-master replication: https://en.wikipedia.org/wiki/Multi-master_replication
[5] NDB Cluster Replication: Multi-Master and Circular Replication: https://dev.mysql.com/doc/refman/5.7/en/mysql-cluster-replication-multi-master.html
[6] Caching Strategies and How to Choose the Right One: https://codeahoy.com/2017/08/11/caching-strategies-and-how-to-choose-the-right-one/
[7] R. Nishtala, "Facebook, Scaling Memcache at," 10th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’13).
[8] Single point of failure: https://en.wikipedia.org/wiki/Single_point_of_failure
[9] Amazon CloudFront Dynamic Content Delivery: https://aws.amazon.com/cloudfront/dynamic-content/
[10] Configure Sticky Sessions for Your Classic Load Balancer: https://docs.aws.amazon.com/elasticloadbalancing/latest/classic/elb-sticky-sessions.html
[11] Active-Active for Multi-Regional Resiliency: https://netflixtechblog.com/active-active-for-multi-regional-resiliency-c47719f6685b
[12] Amazon EC2 High Memory Instances: https://aws.amazon.com/ec2/instance-types/high-memory/
[13] What it takes to run Stack Overflow: http://nickcraver.com/blog/2013/11/22/what-it-takes-to-run-stack-overflow
[14] What The Heck Are You Actually Using NoSQL For: http://highscalability.com/blog/2010/12/6/what-the-heck-are-you-actually-using-nosql-for
第02章:粗略估算
在系统设计面试中,有时会要求你使用粗略估算来估计系统的容量或性能需求。根据谷歌高级研究员杰夫·迪恩(Jeff Dean)的说法,“粗略估算是使用一系列思维实验和常见性能数据的组合进行估算,以便对哪种设计能够满足你的要求有一个良好的了解” [1]。
要有效地进行粗略估算,你需要对可扩展性基础知识有很好的了解。以下概念应该被深入理解:二的幂 [2]、每个程序员都应该知道的延迟数字和可用性数字。
2的幂次方
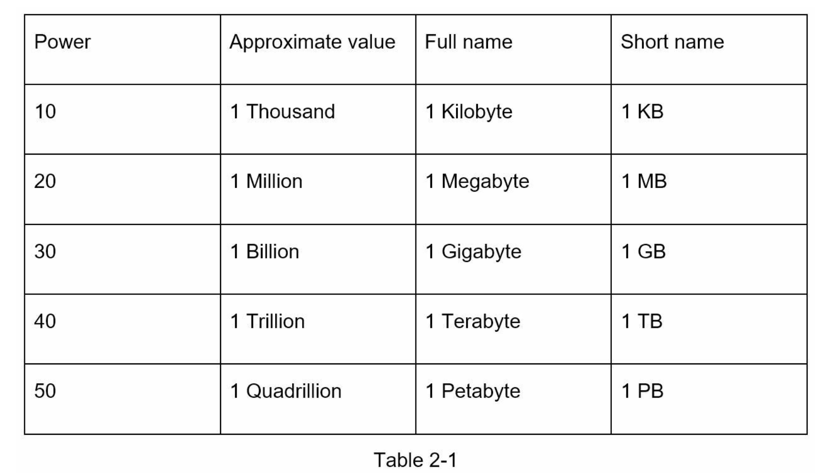
尽管在处理分布式系统时数据量可能变得非常庞大,但所有计算归结为基础知识。为了获得正确的计算结果,了解使用二的幂的数据量单位至关重要。一个字节是8个位的序列。一个 ASCII 字符使用一个字节的内存(8位)。下面是解释数据量单位的表格(表2-1)。
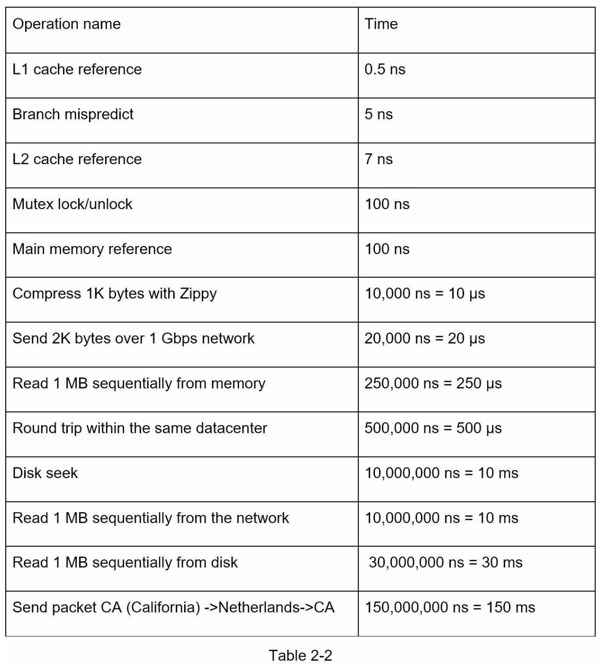
每个程序员都应该了解的延迟数据
Google的Dean博士在2010年透露了典型计算机操作的时间[1]。 随着计算机变得更快更强大,一些数字已经过时。然而,这些数字仍然应该能够让我们了解不同计算机操作的速度和慢速。
注意事项
ns = 纳秒, μs = 微秒, ms = 毫秒
$$1 \space ns = 10^{-9} \space 秒$$
$$1 \space \mu s= 10^{-6} \space 秒 = 1,000 \space ns$$
$$1 \space ms = 10^{-3} \space 秒 = 1,000 \space \mu s = 1,000,000 \space ns$$
一位谷歌软件工程师构建了一个工具来可视化Dean博士的数据。该工具还考虑了时间因素。 图2-1显示了截至2020年的可视化延迟数字(图源:参考资料[3])。

通过分析图2-1中的数字,我们得出以下结论:
- 内存速度快,但磁盘速度慢。
- 如果可能的话,应避免磁盘寻道。
- 简单的压缩算法速度快。
- 在发送数据到互联网之前,尽可能对数据进行压缩。
- 数据中心通常位于不同的区域,发送数据之间需要一定的时间。
可用性数据
高可用性是系统持续运行的能力,期望能够长时间保持操作。 高可用性通常以百分比表示,100%意味着服务没有任何停机时间。大多数服务的可用性介于99%到100%之间。
服务水平协议(SLA)是服务提供商常用的术语。这是你(服务提供商)与你的客户之间的协议,该协议正式定义了你的服务将提供的运行时间水平。 云服务提供商Amazon、Google和Microsoft将它们的SLA设置在99.9%或更高。系统的运行时间传统上以数字的形式进行测量。 数字越多,表示系统的运行时间越长。 如表2-3所示,数字数量与预期系统停机时间相关。 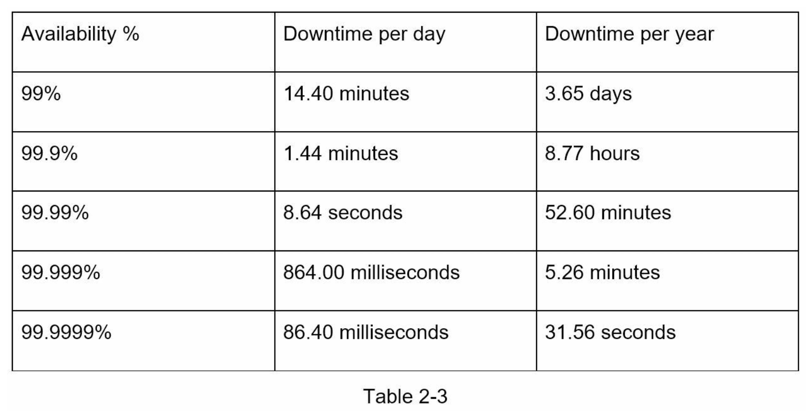
示例:估算Twitter的查询量和存储需求
请注意,以下数字仅用于本练习,不是 Twitter 的真实数据。
假设:
- 每月活跃用户为3亿。
- 50%的用户每天使用 Twitter。
- 用户平均每天发布2条推文。
- 10%的推文包含媒体。
- 数据存储时间为5年。
估算: 查询每秒次数(QPS)估计:
- 每日活跃用户(DAU)= 3亿 * 50% = 1.5亿
- 推文 QPS = 1.5亿 * 2推文 / 24小时 / 3600秒 = 约 3500
- 峰值QPS = 2 * QPS = 约 7000
(译者注:这里更准确地说应该估算的 TPS,而不是QPS。仅个人观点,原文翻译还是保持原作者意思为 QPS。)
我们这里只会估算媒体存储。
- 平均推文大小:
- 推文ID 64 bytes(字节)
- 文本 140 bytes(字节)
- 媒体 1MB
- 媒体存储:1.5亿 * 2 * 10% * 1MB = 每天30TB
- 5年媒体存储:30TB * 365 * 5 = 约 55PB
小贴士
粗略估计更注重过程而非结果。 解决问题比得到准确结果更为重要。 面试官可能会测试你的解决问题的能力。 以下是一些建议:
- 四舍五入和近似值。在面试中进行复杂的数学运算是困难的。例如,“99987 / 9.1”的结果是多少?没有必要花费宝贵的时间来解决复杂的数学问题。精确度并不是必需的。使用整数和近似值来简化问题。例如,“100,000 / 10”。
- 记下你的假设。写下你的假设是个好主意,以便以后参考。
- 标记你的单位。当你写下“5”时,它是指5 KB还是5 MB?这可能会让你感到困惑。写下单位,因为“5 MB”有助于消除歧义。
- 常见的粗略估计问题包括:QPS、峰值QPS、存储、缓存、服务器数量等。在准备面试时,你可以练习这些计算。熟能生巧。
祝贺你已经走到这一步!现在,给自己一个鼓励。干得漂亮!
参考资料
[1] J. Dean. Google专业提示:使用粗略估计来选择最佳设计: http://highscalability.com/blog/2011/1/26/google-pro-tip-use-back-of-the-envelope-calculations-to-choo.html
[2] 系统设计入门指南:https://github.com/donnemartin/system-design-primer
[3] 每个程序员都应该知道的延迟数据:https://colin-scott.github.io/personal_website/research/interactive_latency.html
[4] 亚马逊计算服务等级协议:https://aws.amazon.com/compute/sla/
[5] 计算引擎服务等级协议(SLA):https://cloud.google.com/compute/sla
[6] Azure服务的SLA摘要:https://azure.microsoft.com/en-us/support/legal/sla/summary/
第03章:系统设计面试框架
你刚刚获得了梦寐以求的现场面试机会。招聘协调员给你发送了当天的日程安排。看完整个日程安排后,你觉得一切都挺好,直到你看到了这个面试环节 - 系统设计面试。
系统设计面试往往令人生畏,它可能像“设计一个知名的产品X?”那样的模糊不清。这些问题模棱两可,似乎过于宽泛。 你的担心是可以理解的。 毕竟,在一个小时内设计一个已经由数百甚至数千名工程师构建的流行产品,这似乎是不可能的?
好消息是,没有人期望你这样做。现实世界的系统设计是非常复杂的。例如,谷歌搜索看起来简单;然而,支持这种简单性背后的技术数量真的令人惊讶。 如果没有人期望你在一小时内设计出一个真实世界的系统,那么系统设计面试的好处是什么?
系统设计面试模拟了现实生活中的问题解决过程,两个同事合作解决一个模糊的问题,并提出一个符合他们目标的解决方案。这个问题是开放式的,没有完美的答案。 与你在设计过程中付出的努力相比,最终的设计并不那么重要。这使你能够展示你的设计技能,捍卫你的设计选择,并以有建设性的方式回应反馈。
让我们换个角度思考,考虑一下当面试官走进会议室与你见面时,她的脑子里在想什么。面试官的首要目标是准确评估你的能力。 她最不希望的是,因为会议进行得不顺利,没有足够的信息,而给出一个没有结果的评价。面试官想通过系统设计面试获得什么?
许多人认为,系统设计面试只涉及一个人的技术设计能力。事实并非如此。 有效的系统设计面试更多地体现了一个人的合作能力、在压力下工作的能力以及以建设性方式解决模糊问题的能力。提出好问题的能力也是一项重要的技能,许多面试官特别看重这项技能。
一个好的面试官也会寻找危险信号,过度设计是许多工程师的真正问题,因为他们喜欢设计的纯粹性而忽视了权衡。他们往往没有意识到过度设计系统的复合成本,许多公司为这种无知付出了高昂的代价。 你当然不希望在系统设计面试中表现出这种倾向。其他危险信号包括狭隘的思想,固执,等等。
在本章中,我们将介绍一些有用的技巧,并介绍一个简单而有效的框架来解决系统设计面试问题。
有效系统设计面试的 4 步流程
每个系统设计面试都是不同的。 出色的系统设计面试是开放式的,没有万能的解决方案。 然而,在每个系统设计面试中都有一些步骤和共同点需要涵盖。
第1步 :了解问题并确定设计范围
"老虎为什么咆哮?"
班级后面有一只手拍了起来。
"是的,吉米?",老师回答。
"因为他很饿"。
"非常好,吉米"。
在整个童年时期,吉米一直是班上第一个回答问题的人。每当老师提出问题时,教室里总有一个孩子喜欢回答这个问题,不管他是否知道答案。这就是吉米。
吉米是个优等生,他以很快就知道所有答案而自豪。在考试中,他通常是第一个完成问题的人。在任何学术竞赛中,他都是教师的首选。
别像吉米那样。
在系统设计面试中,不加思索地迅速给出答案不会给你加分。在没有彻底理解需求的情况下回答问题是一个危险的信号,因为面试不是一个小游戏比赛。这往往没有正确的答案。
作为一名工程师,我们喜欢解决棘手的问题,并投身于最终设计;然而,这种方法很可能会导致你设计出错误的系统。 作为一名工程师,最重要的技能之一是提出正确的问题,做出适当的假设,并收集建立一个系统所需的所有信息。因此,不要害怕问问题。
当你提出问题时,面试官要么直接回答你的问题,要么要求你做出你的假设。如果是后者,请在白板或纸上写下你的假设。你以后可能会用到它们。
要问什么问题?提出问题以了解确切的要求。 以下是一个问题清单,以帮助你开始工作:
- 我们要开发哪些特定功能?
- 这个产品有多少用户?
- 公司预计扩大规模的速度如何?3个月、6个月和1年后的预期规模是多少?
- 公司的技术栈是?可以利用哪些现有的服务来简化设计?
例子
如果你被要求设计一个新闻订阅系统,你希望问一些问题来帮助理解需求。你和面试官之间的对话可能是这样的:
候选人:这是一个移动应用吗?还是一个网页应用?还是两者兼有?
面试官:两者都有。
候选人:对于产品来说,最重要的功能是什么??
面试官:能够发布帖子并查看朋友的新闻动态。
候选人:新闻动态是按照时间顺序排列,还是按照特定顺序? 所谓的特定顺序意味着每篇帖子都有不同的权重。 例如,来自亲密朋友的帖子比来自一个群组的帖子更重要。
面试官:为了简单起见,我们假设动态是按照时间顺序排列的。
候选人:一个用户最多可以有多少个朋友?
面试官:5000个。
候选人:流量有多大?
面试官:每日活跃用户数为1000万(DAU)。
候选人:动态可以包含图像、视频,还是只有文字?
面试官:它可以包含媒体文件,包括图像和视频。
以上是一些你可以问面试官的示例问题。 理解需求并澄清不明确的地方是很重要的。
第2步:提出高层次的设计方案并获得认同
在这一步中,我们的目标是制定一个高层次的设计,并与面试官就设计达成一致。在这个过程中,与面试官合作是个好主意。
- 想出一个初步的设计蓝图。征求反馈意见。把你的面试官当作队友,一起工作。许多优秀的面试官喜欢交谈和参与。
- 在白板或纸上画出关键组件的框图。这可能包括客户端(移动/网络)、API、网络服务器、数据存储、缓存、CDN、消息队列,等等。
- 做一些粗略计算,以评估你的蓝图是否符合规模限制。边想边说。在深入研究之前,如果进行粗略计算是必要的,请与你的面试官进行沟通交流。
如果可能的话,通过一些具体的用例。这将帮助你确定高层设计的框架。用例也有可能帮助你发现你还没有考虑到的边缘情况。
我们应该在这里包括API端点和数据库架构吗?这取决于当前问题。对于像“设计Google搜索引擎”这样的大型设计问题,这有点过于底层。 对于像为一个多人扑克游戏设计后端这样的问题,这是合理的。
与你的面试官沟通。
例子
让我们以“设计一个新闻订阅系统”为例,来演示如何进行高层设计。这里不要求你了解系统的实际工作情况。所有的细节将在第11章解释。
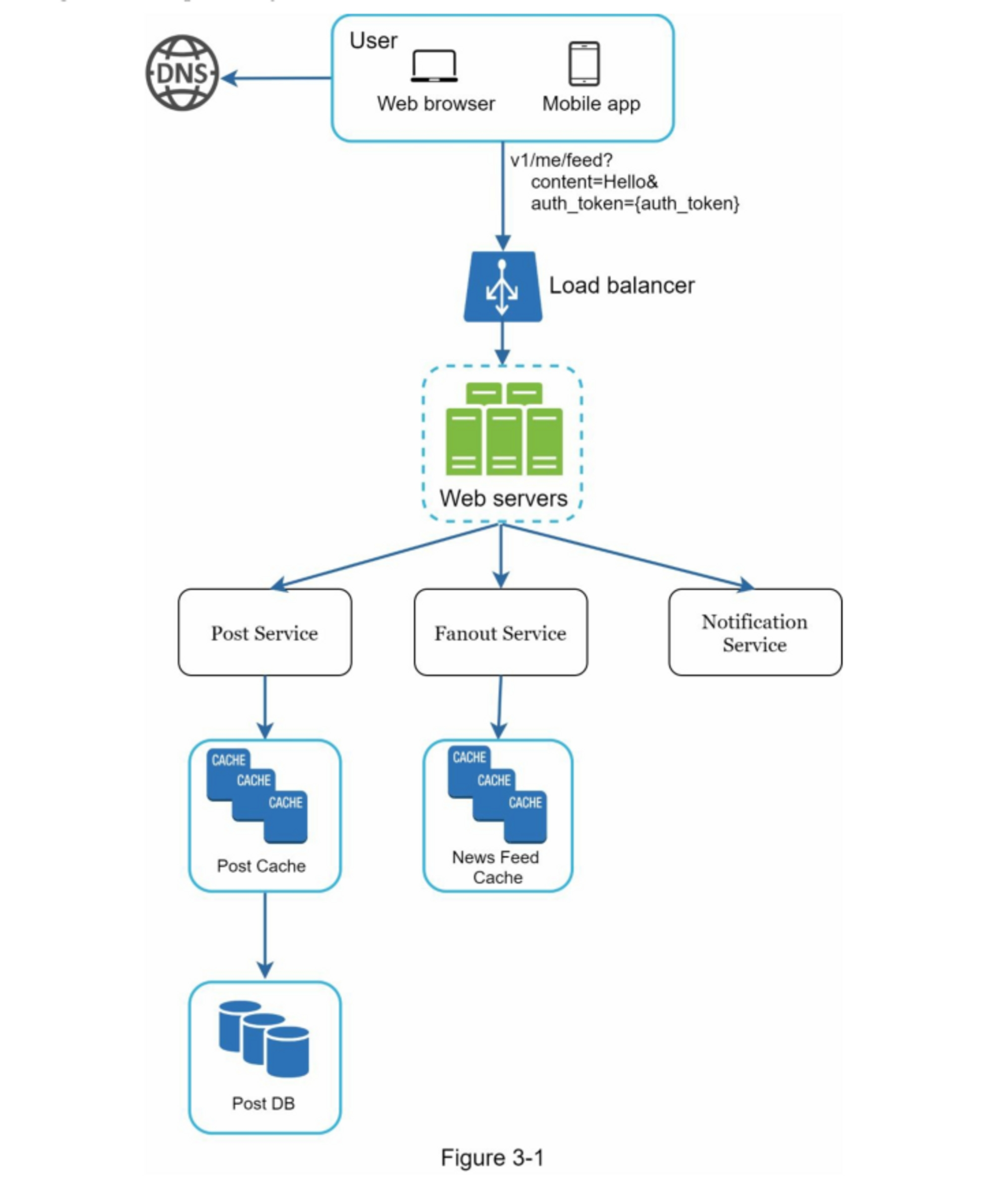
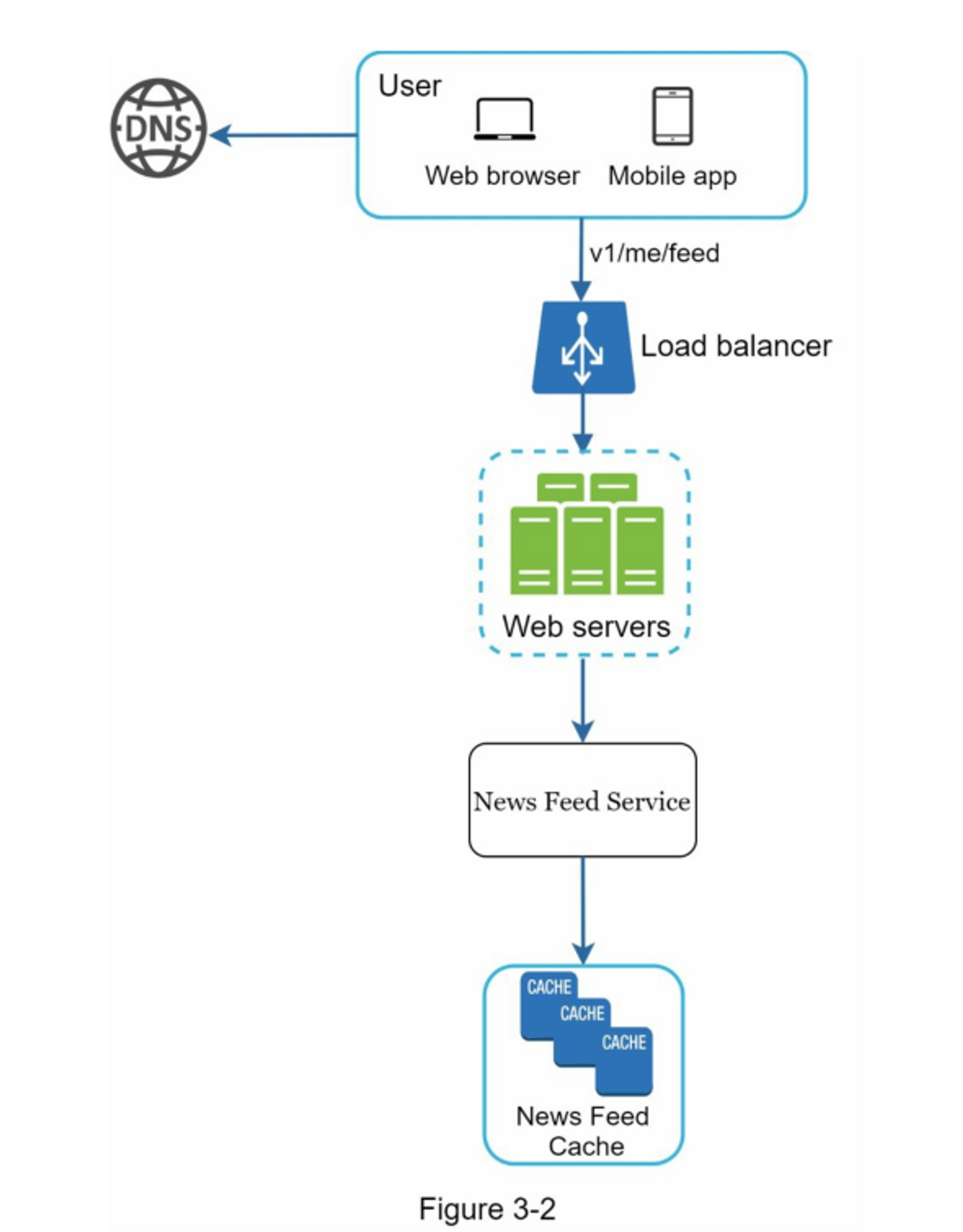
在高层次上,设计分为两个流程:订阅发布和新闻订阅构建。
- 订阅发布:当用户发布帖子时,相应的数据会被写入缓存/数据库,并且该帖子将出现在好友的新闻订阅中。
- 新闻订阅构建:新闻订阅通过按时间倒序聚合好友的帖子来构建。
图3-1和图3-2分别展示了订阅发布和新闻订阅构建流程的高层设计。
第3步:深入设计
在这一步,你和你的面试官应该已经实现了以下目标:
- 就总体目标和功能范围达成一致
- 为整体设计草拟了一个高层次的蓝图
- 从面试官那里获得了对高层设计的反馈
- 根据她的反馈,对深入设计的重点区域有了一些初步想法
你应该与面试官合作,确定并优先考虑架构中的组件。值得强调的是,每次面试都是不同的。有时,面试官可能会暗示她喜欢专注于高层设计。 有时,对于资深候选人的面试,讨论可能会涉及系统性能特性,主要关注瓶颈和资源估算。在大多数情况下,面试官可能希望你深入了解某些系统组件的细节。 对于 URL 缩短器,深入探讨将长 URL 转换为短 URL 的哈希函数设计是一个有趣的话题。对于一个聊天系统来说,如何减少延迟以及如何支持在线/离线状态是两个有趣的话题。
时间管理是至关重要的,因为你很容易被一些细枝末节所迷惑,而这些细节并不能体现你的能力。你必须准备好一些信号来展示给面试官。尽量不要陷入不必要的细节中。 例如,在系统设计面试中,详细谈论Facebook feed排名的EdgeRank算法并不理想,因为这需要很多宝贵的时间,而且并不能证明你在设计可扩展系统方面的能力。
例子
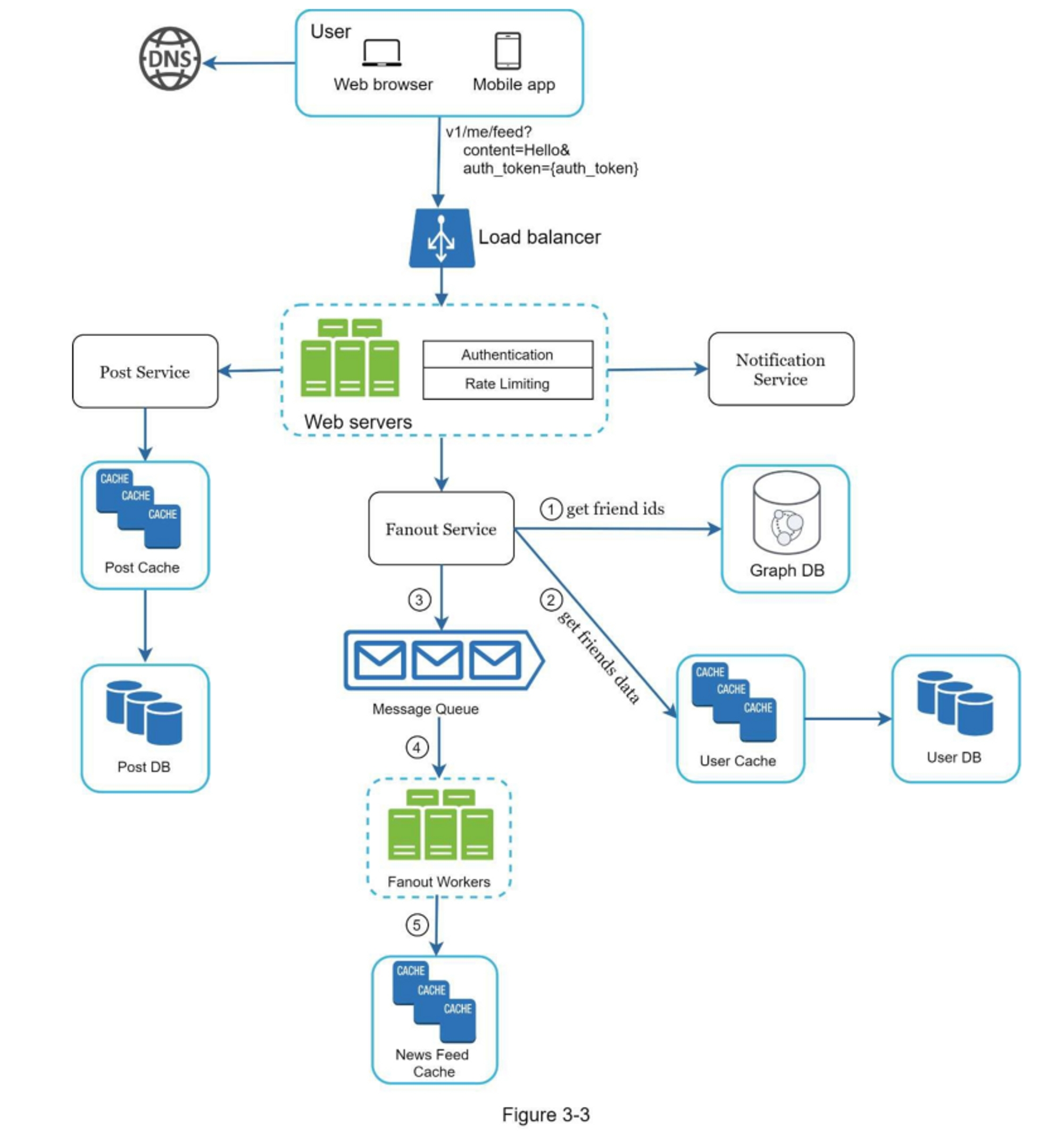
在这一点上,我们已经讨论了新闻订阅系统的高级设计,面试官对您的提议感到满意。接下来,我们将调查两个最重要的使用案例:
- 新闻订阅发布
- 新闻订阅检索
图3-3和图3-4显示了两个用例的详细设计,这将在第11章中详细说明
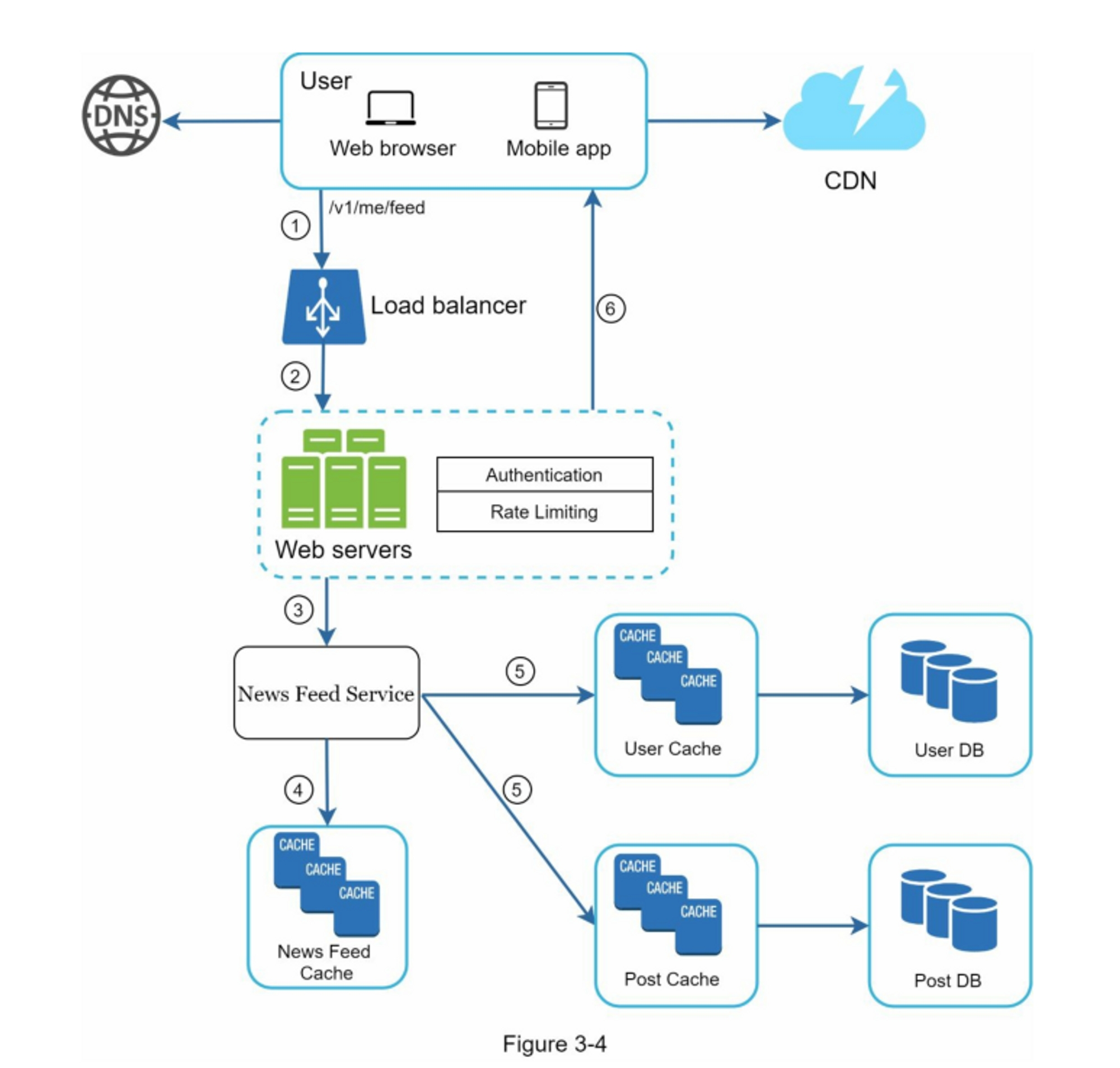
第4步:总结
在这最后一步,面试官可能会问你一些后续问题,或者让你自由讨论其他的附加要点。 以下是一些跟进方向:
- 面试官可能希望你找出系统的瓶颈,并讨论潜在的改进。千万不要说你的设计是完美的,没有什么可以改进的。总有一些东西是可以改进的。这是一个展示你的批判性思维的好机会,并留下一个好的最终印象。
- 给面试官回顾一下你的设计可能是有用的。如果你提出了几种解决方案,这一点就特别重要。在长时间的会话后,提醒面试官可能会有所帮助。
- 错误情况(服务器故障、网络丢失等)值得讨论。
- 运营问题也值得一提。如何监控指标和错误日志?系统如何推广?
- 如何处理下一个规模曲线也是一个有趣的话题。例如,如果你目前的设计支持100万用户,你需要做什么改变来支持1000万用户?
- 如果你有更多的时间,可以提出其他改进建议。
最后,我们总结了一份 "该做" 和 "不该做" 的清单。
-
该做
- 要问清楚。不要认为你的假设是正确的。
- 了解问题的要求。
- 既没有正确的答案,也没有最好的答案。为解决年轻创业公司的问题而设计的解决方案与拥有数百万用户的老牌公司的解决方案不同。确保你理解了要求。
- 让面试官知道你在想什么。与你的面试官沟通。
- 如果可能的话,提出多种方法。
- 一旦你与你的面试官就蓝图达成一致,就对每个组件进行详细说明。先设计最关键的部分。
- 向面试官反映想法。一个好的面试官会把你当作一个团队伙伴和你一起合作。
- 永不言弃。
-
不该做
- 不要对典型的面试问题没有任何准备。
- 在没有弄清需求和假设的情况下,不要贸然提出解决方案。
- 在开始的时候,不要对一个单一的组件进行太多细节的研究。首先给出高层次的设计,然后再深入探讨。
- 如果你被卡住了,不要犹豫,请求提示。
- 再次强调,要进行沟通。不要默默思考。
- 不要认为一旦你给出设计方案,你的面试就结束了。直到你的面试官说你完成了,你才算完成。尽早并经常要求反馈。
-
每个步骤的时间分配
系统设计的面试问题通常非常广泛,45分钟或一个小时不足以涵盖整个设计。时间管理至关重要。在每个步骤上应该花费多少时间? 以下是一个非常粗略的指南,指导你在45分钟的面试会议中的时间分配。请记住,这只是一个粗略的估计,实际时间分配取决于问题的范围和面试官的要求。
- 第1步 理解问题并确定设计范围:3-10分钟
- 第2步 提出高层次的设计并获得认同:10-15分钟
- 第3步 深入设计:10-25分钟
- 第4步 总结:3-5分钟
第04章:设计一个限流器
在网络系统中,限流器被用于控制客户端或服务端发送流量的速率。在HTTP世界中,限流器限制在指定时间内允许发送客户端请求数。 如果API请求次数超过了限流器设置的阈值,则所有超出的调用都会被阻止。 以下是一些示例:
- 单个用户每秒最多可以发布2个帖子
- 每天同一IP地址最多可以创建10个帐户。
- 同一设备每周最多可以领取5次奖励。
在本章中,您需要设计一个限流器。在开始设计之前,我们先看看使用 API 限流器的好处:
- 防止拒绝服务 (DoS) 攻击造成的资源匮乏 [1]。 几乎大型科技公司发布的所有 API 都强制执行某种形式的速率限制。 例如,Twitter将每3小时的推文数量限制为300条[2]。 Google docs APIs有如下默认限制:每个用户每60秒读取请求为300次[3]。 限流器通过阻止多余的调用来防止DoS攻击,无论是有意还是无意的。
- 降低成本。限制过多的请求意味着减少服务器数量,将更多资源分配给高优先级的API。 速率限制对于使用付费第三方API的公司来说极为重要。 例如,你对以下外部API的调用是按次数收费的:检查信用、付款、检索健康记录等。限制调用次数对减少成本至关重要。
- 防止服务器过载。为了减少服务器的负荷,使用限流器来过滤由机器人或用户的不当行为造成的过量请求。
第1步:了解问题并确定设计范围
速率限制可以通过不同的算法来实现,每一种算法都有其优点和缺点。 面试官和候选人之间的互动有助于阐明我们试图建立的限流器的类型。
候选人:我们要设计什么样的限流器?是客户端的限流器还是服务器端的API限流器?
面试官:好问题,我们专注于服务器端的API限流器。
候选人:限流器是否根据IP、用户ID或其他属性来限制API请求?
面试官:限流器应该足够灵活,能够支持不同的限流规则集。
候选人:该系统的规模是多少?它是为初创企业还是拥有庞大用户群的大公司建立的?
面试官:该系统必须能够处理大量的请求。
候选人:系统会在分布式环境下工作吗?
面试官:是的。
候选人:限流器是一个单独的服务还是应该在应用程序代码中实现?
面试官:这是一个由你决定的设计问题。
候选人:是否需要通知被限流的用户?
面试官:是的。
要求
以下是对系统要求的概述
- 准确地限制过多的请求
- 低延迟:限流器不能降低Http响应时间。
- 尽可能的占用更少的内存。
- 分布式速率限制,要求可以在多个服务器或进程之间共享。
- 异常处理,当用户的请求受到限制时,向用户显示明确的异常信息。
- 高容错性。如果限流器出现任何问题(例如,一个缓存服务器离线),它不会影响整个系统。
第2步:提出高层次的设计方案并获得认同
让我们保持简单,并使用基本的客户端和服务器模型进行通信。
限流器放在哪里
直觉上,你可以在客户端或服务器端实现限流器。
-
客户端实现。 一般来说,客户端是执行速率限制的不可靠场所,因为客户端请求很容易被恶意用户伪造。 此外,我们可能无法控制客户端的实现。
-
服务端实现。图4-1显示了一个放在服务器端的限流器。
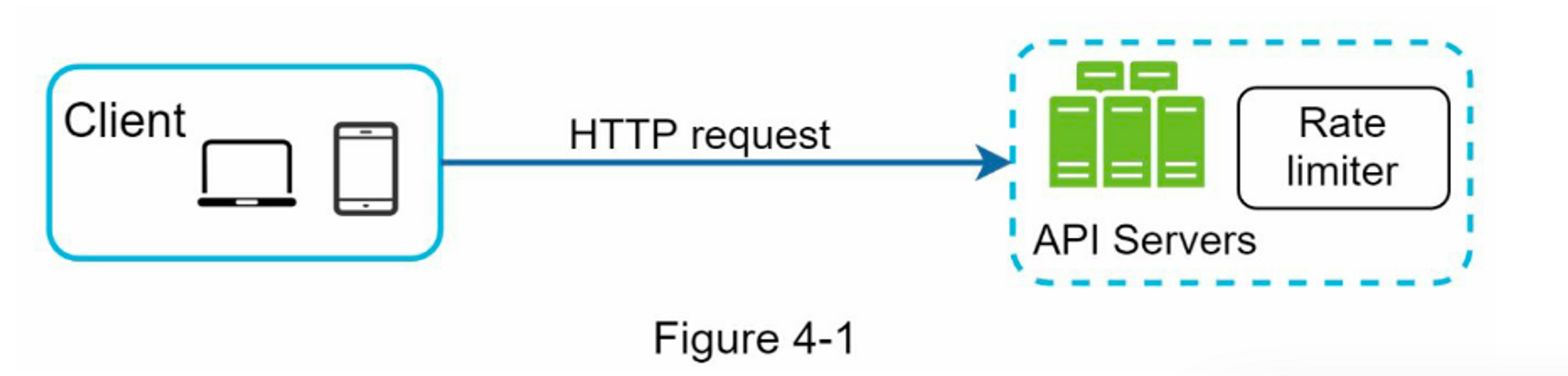 除了客户端和服务器端的实现方式之外,还有另一种方法。 我们可以不将限流器放在API服务器上,而是创建一个限流器中间件,用于对API的请求进行限制,如图 4-2 所示:
除了客户端和服务器端的实现方式之外,还有另一种方法。 我们可以不将限流器放在API服务器上,而是创建一个限流器中间件,用于对API的请求进行限制,如图 4-2 所示:
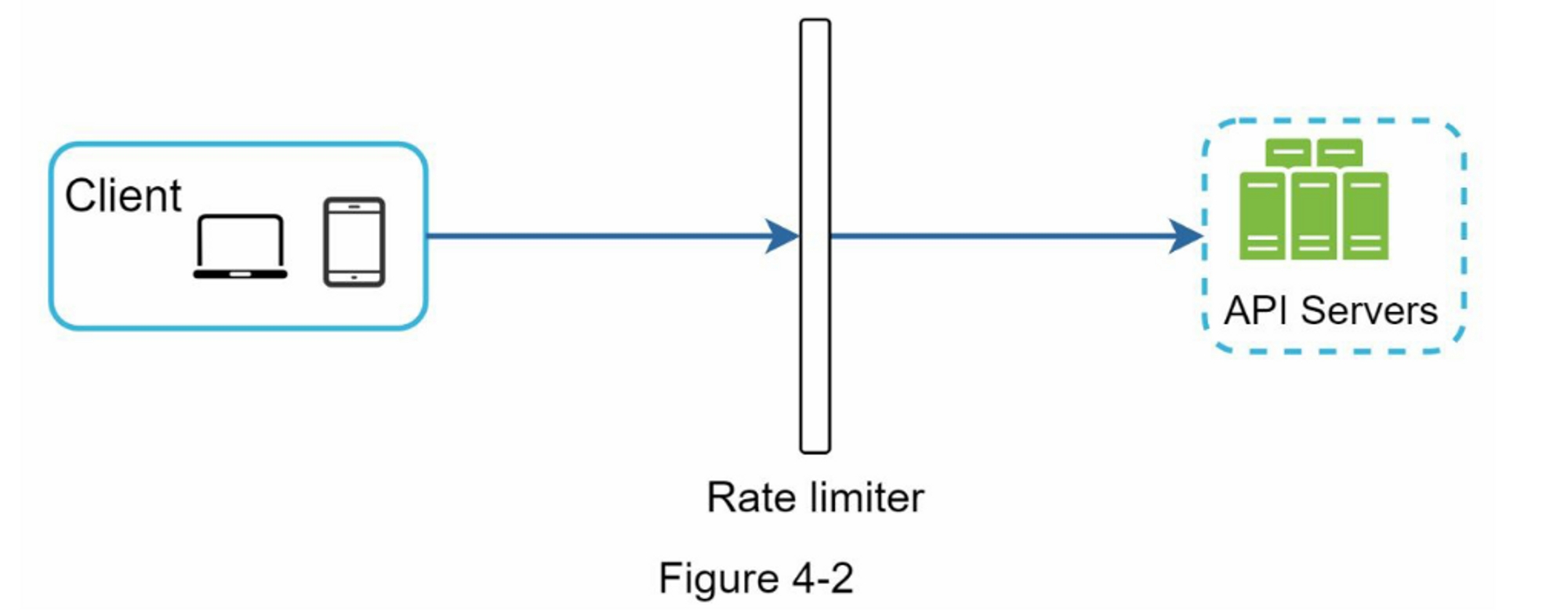
让我们使用图 4-3 中的示例来说明这种设计中的限流器是如何工作的。 假设我们的 API 允许每秒 2 个请求,而客户端在一秒内发送了3个请求到服务器。 前两个请求被路由到 API 服务器。 但是,限流器中间件会限制第三个,请求并返回 HTTP 状态代码 429。 HTTP 429 响应状态代码表示用户发送了过多的请求。
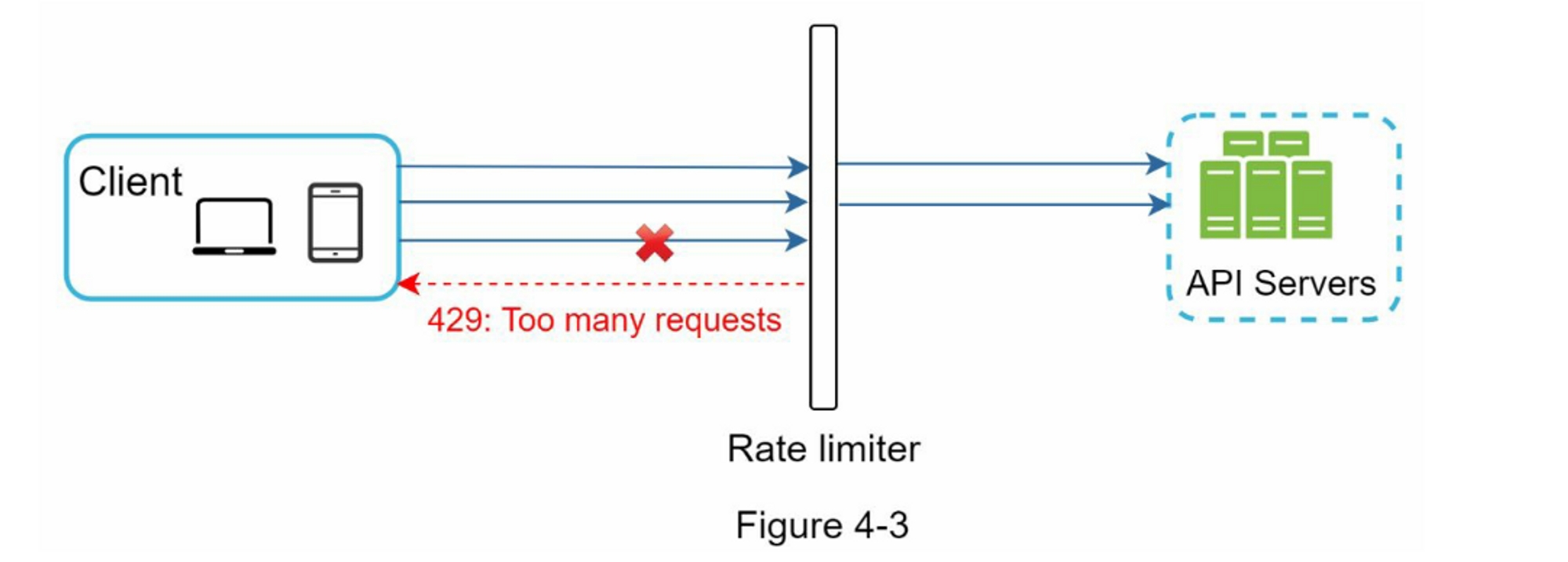
云微服务[4]已经变得非常流行,限流通常在一个叫做API网关的组件中实现。API网关是一个完全托管的服务,支持限速、SSL、认证、IP白名单、服务静态内容等。现在,我们只需要知道API网关是一个支持限流的中间件。
在设计限流器时,要问自己的一个重要问题是:限流器应该在哪里实现,在服务器端还是在网关中?这没有绝对的答案。这取决于你公司目前的技术栈、工程资源、优先级、目标等。这里有一些通用的指南:
- 评估你目前的技术栈,如编程语言、缓存服务等。确保你目前的编程语言能够有效地在服务器端实现速率限制。
- 确定适合你业务需求的速率限制算法。当你在服务器端实施一切时,你可以完全控制算法。然而,如果你使用第三方网关,你的选择可能是有限的。
- 如果你已经使用了微服务架构,并在设计中包含了一个API网关来执行认证、IP白名单等,你可以在API网关上添加一个限流器。
- 建立你自己的速率限制服务需要时间。如果你没有足够的工程资源来实现限流器,商业API网关是一个更好的选择。
限流算法
限流可以使用不同的算法来实现,每种算法都有其独特的优缺点。尽管本章并不关注算法,但在高层次上了解它们有助于选择正确的算法或算法组合来适应我们的使用情况。
下面是一个流行算法的列表:
- 令牌桶(Token bucket)
- 漏桶算法(Leaking bucket)
- 固定窗口计数器(Fixed window counter)
- 滑动窗口日志(Sliding window log)
- 滑动窗口计数器(Sliding window counter)
令牌桶算法
令牌桶(Token bucket)算法广泛用于速率限制。 它简单易懂,常被互联网公司采用。 Amazon [5] 和 Stripe [6] 都使用这个算法来限制他们的 API 请求。
令牌桶算法的工作原理如下:
-
令牌桶是一个具有预定义容量的容器。 令牌会以预定的速率定期放入桶中, 一旦桶满了,就不再添加令牌。 如图4-4所示,令牌桶容量为4,注入装置每秒向桶中放入2个令牌,一旦桶满了,多余的令牌就会溢出。
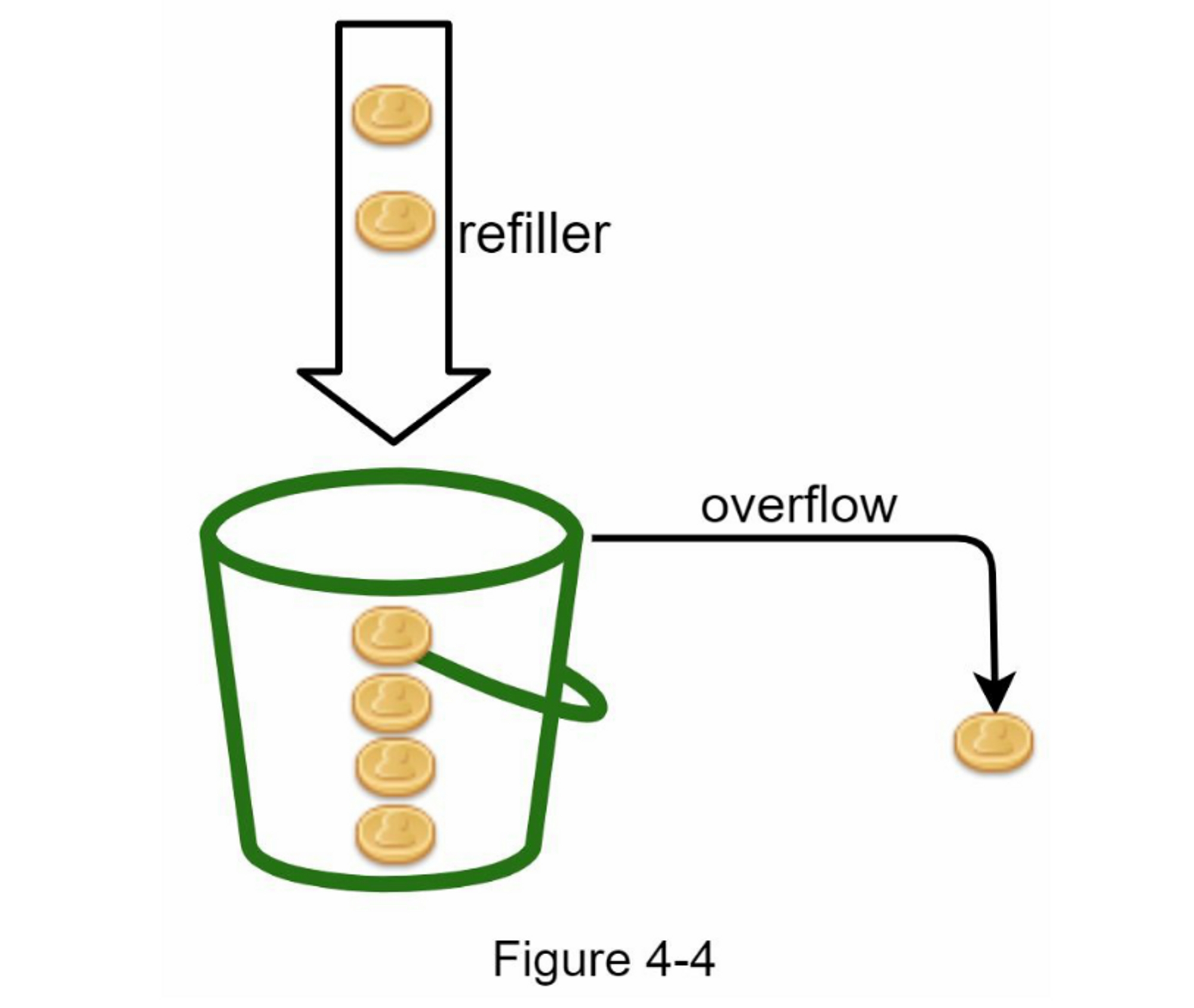
-
每个请求都会消耗一个令牌。当一个请求到达时,我们检查桶中是否有足够的令牌。图4-5解释了它是如何工作的。
- 如果有足够的令牌,我们会为每个请求取出一个令牌,然后请求通过。
- 如果没有足够的令牌,则该请求被丢弃。
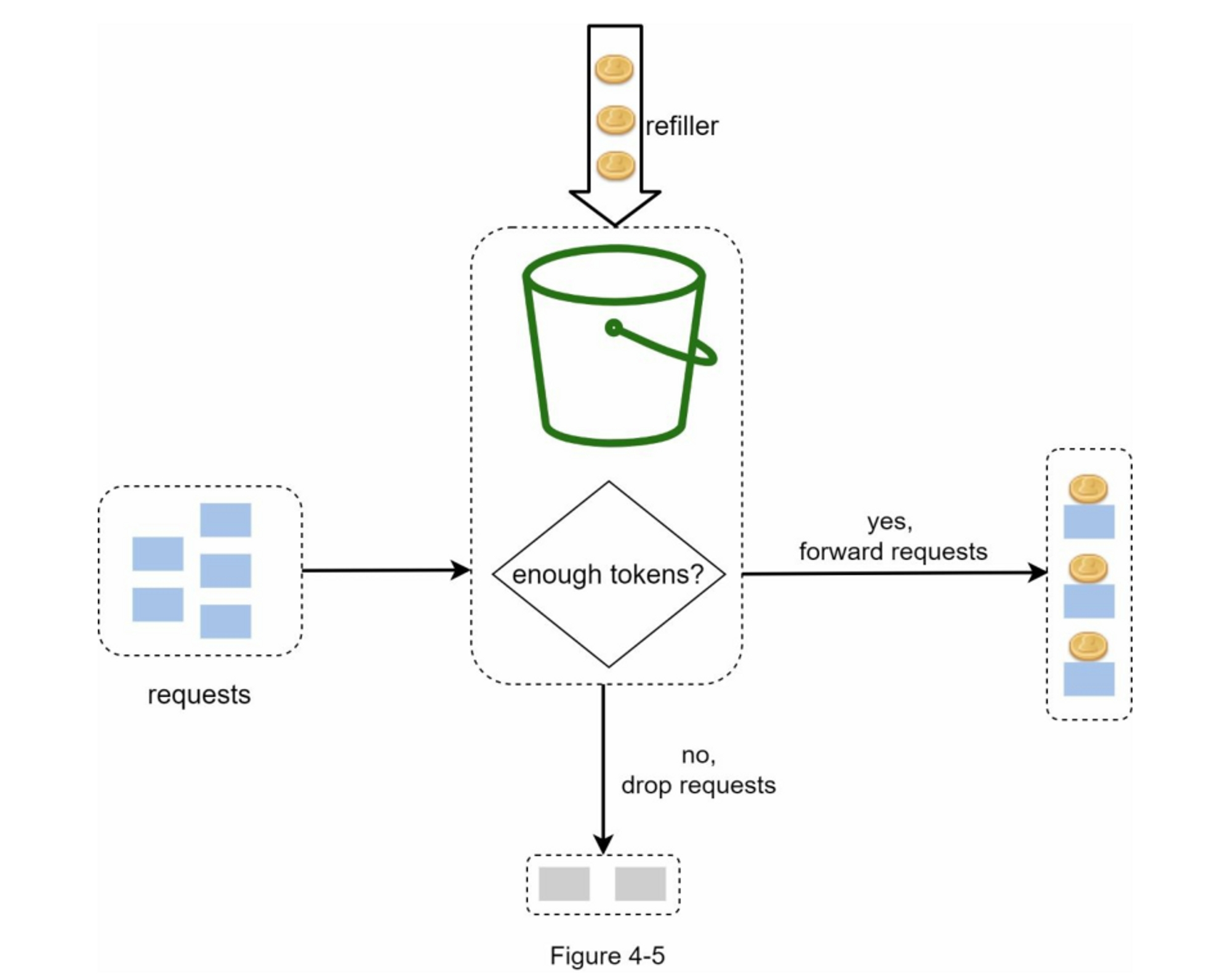
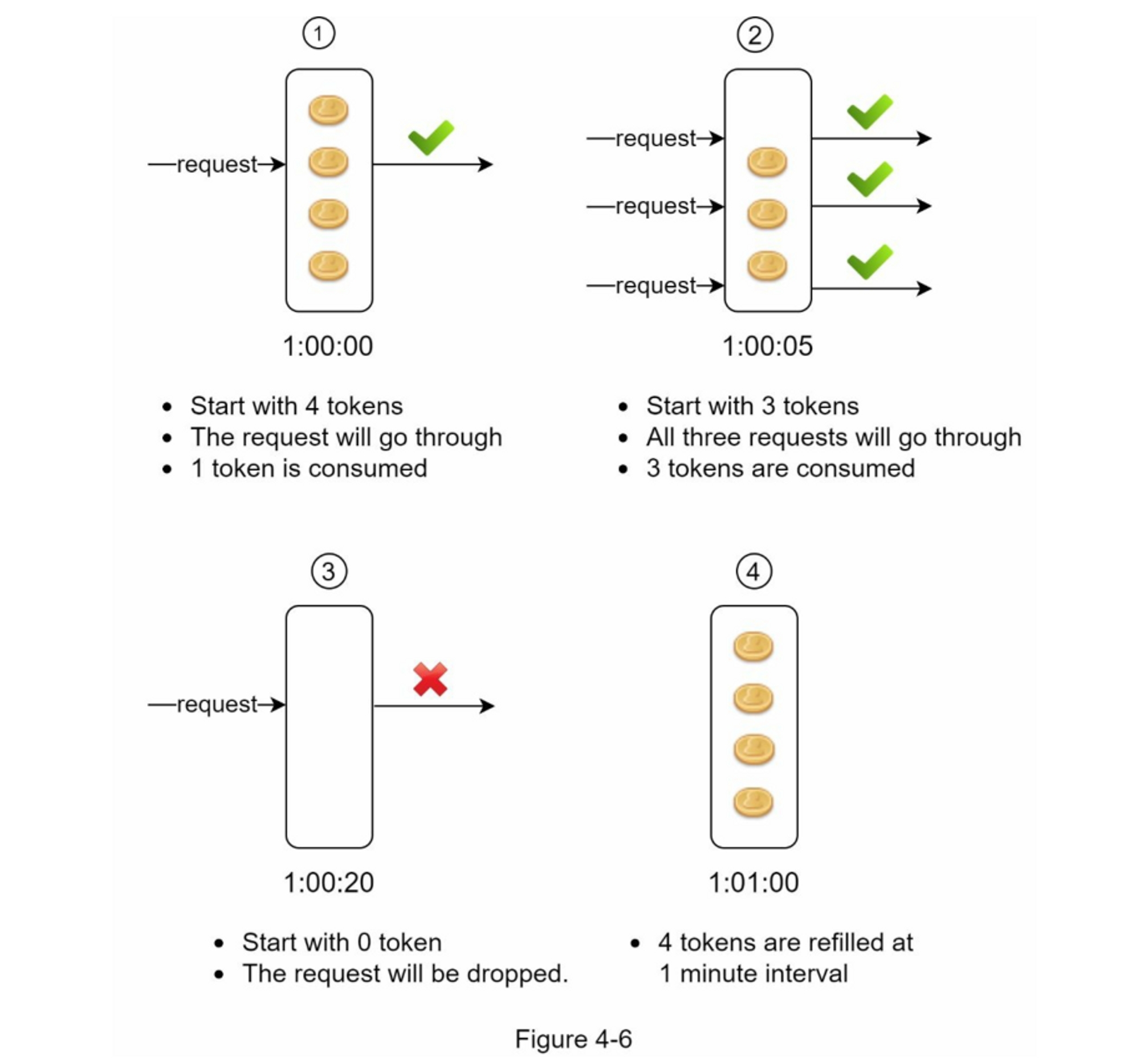
图 4-6 说明了令牌消耗、重新填充和速率限制逻辑的工作原理。 在此示例中,令牌桶大小为 4,重新填充速率为每 1 分钟 4 个。
令牌桶算法需要两个参数:
- 桶大小:桶内允许的最大令牌数。
- 填充速率:每秒放入到桶内的令牌数量。
我们需要多少个桶?这取决于限流规则,并且会有所不同。 以下是几个例子。
- 通常需要为不同的API端点使用不同的桶。例如,如果一个用户被允许每秒发1个帖子,每天添加150个好友,并且每秒钟点赞5个帖子,则每个用户需要3个桶。
- 如果我们需要根据IP地址对请求进行限流,每个IP地址都需要一个桶。
- 如果系统允许每秒最多10,000个请求,则有一个全局桶供所有请求共享是有意义的。
优点
- 算法容易实现
- 占用内存少
- 令牌桶允许在短时间内进行突发流量。只要有剩余的令牌,请求就可以通过。
缺点
- 算法中有两个参数,即桶的大小和令牌的补充速率。然而,正确调整它们可能具有挑战性。
漏桶算法
漏桶(Leaking bucket)算法与令牌桶类似,不同之处在于请求是以固定速率处理的。它通常用先入先出(FIFO)队列来实现。
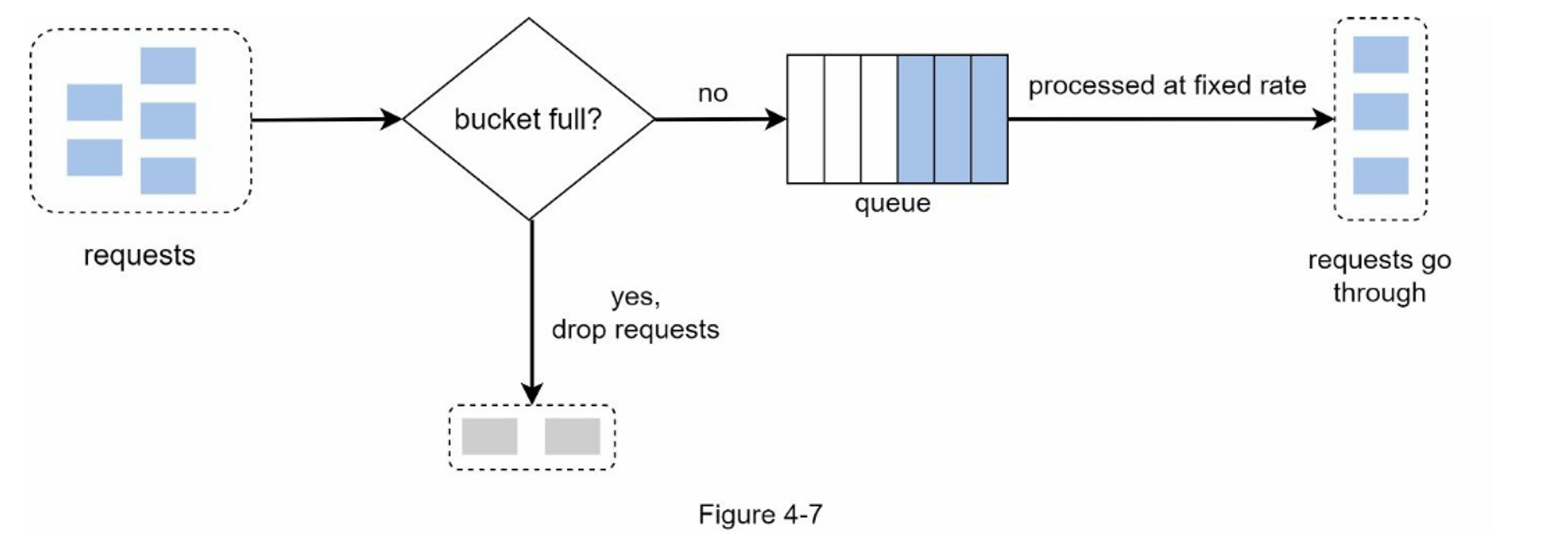
该算法的工作原理如下:
- 当请求到达时,系统会检查队列是否已满。如果队列未满,则将请求添加到队列中。
- 否则,将丢弃该请求。
- 请求会在固定的时间间隔内从队列中取出并进行处理。
图4-7解释了该算法的工作原理:
漏桶算法需要以下两个参数
- 桶的大小:它等于队列的大小。队列容纳了要以固定速度处理的请求。
- 流出率:定义了在固定速率下可以处理多少请求,通常以秒为单位。
Shopify,一家电子商务公司,使用泄漏桶来限制速度[7]。
优点:
- 鉴于队列大小有限,内存效率高。
- 请求以固定的速率处理,因此它适用于需要稳定流出速率的用例。
缺点:
- 突发的流量使队列中充满了旧的请求,如果这些请求没有得到及时处理,最近的请求将受到速率限制。
- 算法中有两个参数,要适当地调整它们可能并不容易。
固定窗口计数器算法
固定窗口计数器(Fixed window counter)算法工作原理如下:
- 该算法将时间轴划分为固定大小的时间窗口,并为每个窗口分配一个计数器。
- 每个请求将计数器增加一。
- 一旦计数器达到预定的阈值,新的请求就会被放弃,直到新的时间窗口开始。
让我们用一个具体的例子来看看它是如何工作的。在图4-8中,时间单位是1秒,系统允许每秒钟最多有3个请求。在每个秒窗口中,如果收到的请求超过3个,额外的请求就会被放弃,如图4-8所示: 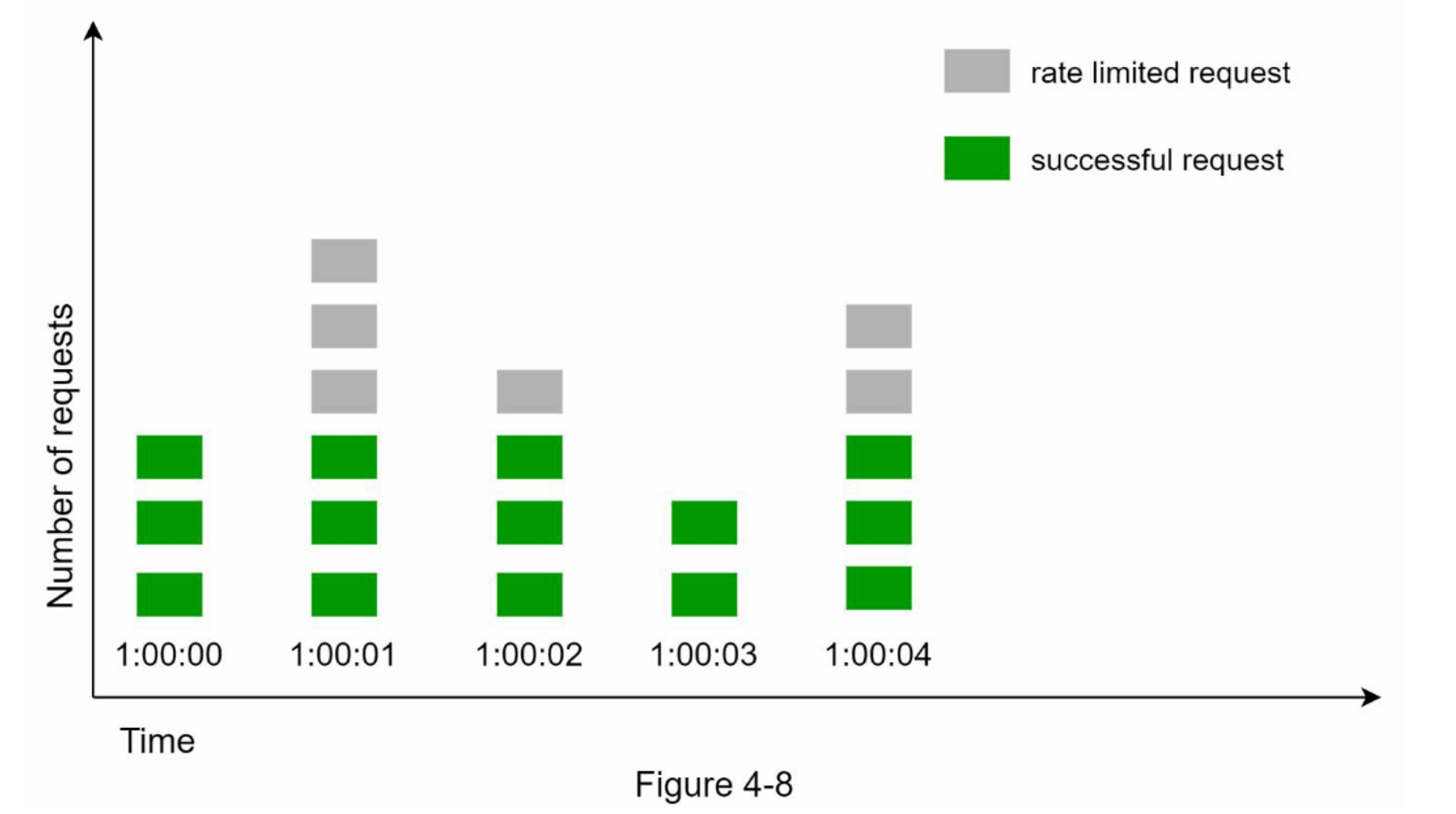
该算法的一个主要问题是,在时间窗口边缘的突发流量可能会导致超过允许配额的请求。考虑以下情况:
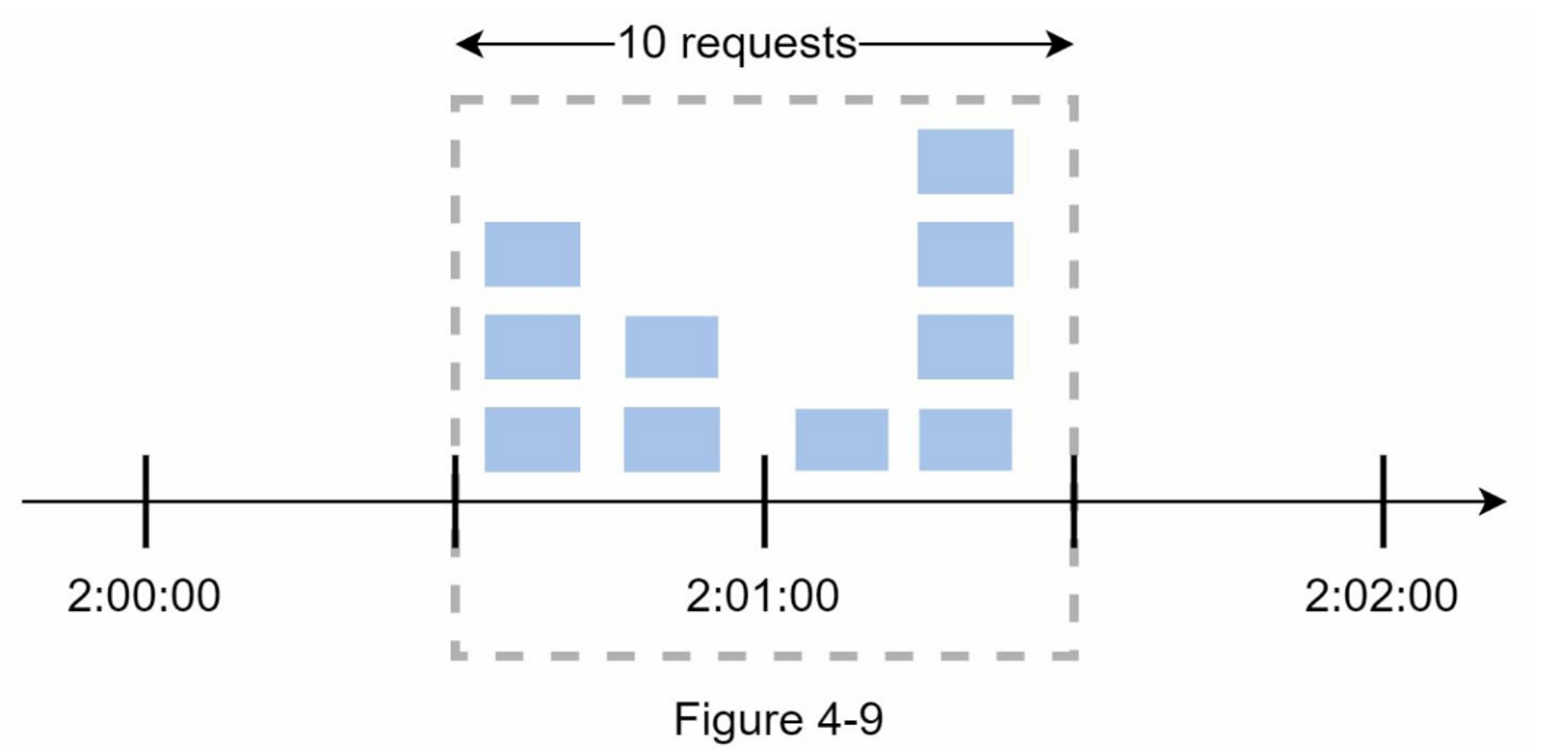
在图4-9中,系统允许每分钟最多有5个请求,可用的配额在整点分钟时重置。如图所示,在 2:00:00 和 2:01:00 之间有5个请求,在 2:01:00 和 2:02:00 之间又有五个请求。 在 2:00:30 和 2:01:30 之间的1分钟窗口,有10个请求通过了。这是允许请求数量的两倍。
优点:
- 内存高效
- 容易理解
- 在单位时间窗口结束时重新设置可用配额,适合某些使用情况
缺点:
- 窗口边缘的流量激增可能导致超过允许配额的请求被通过(有突刺)
滑动窗口日志算法
如前所述,固定窗口计数(Fixed window log)算法有一个主要问题:它允许更多的请求在窗口的边缘通过。滑动窗口日志算法解决了这个问题。 它的工作原理如下:
- 该算法对请求的时间戳进行跟踪。时间戳数据通常保存在缓存中,如Redis的sorted[8] 。
- 当一个新的请求进来时,删除所有过期的时间戳。过时的时间戳被定义为比当前时间窗口的开始时间更早的时间戳。
- 将新请求的时间戳添加到日志中
- 如果日志大小与允许的计数相同或更低,则接受请求。否则,它将被拒绝
我们用图4-10所示的一个例子来解释该算法。
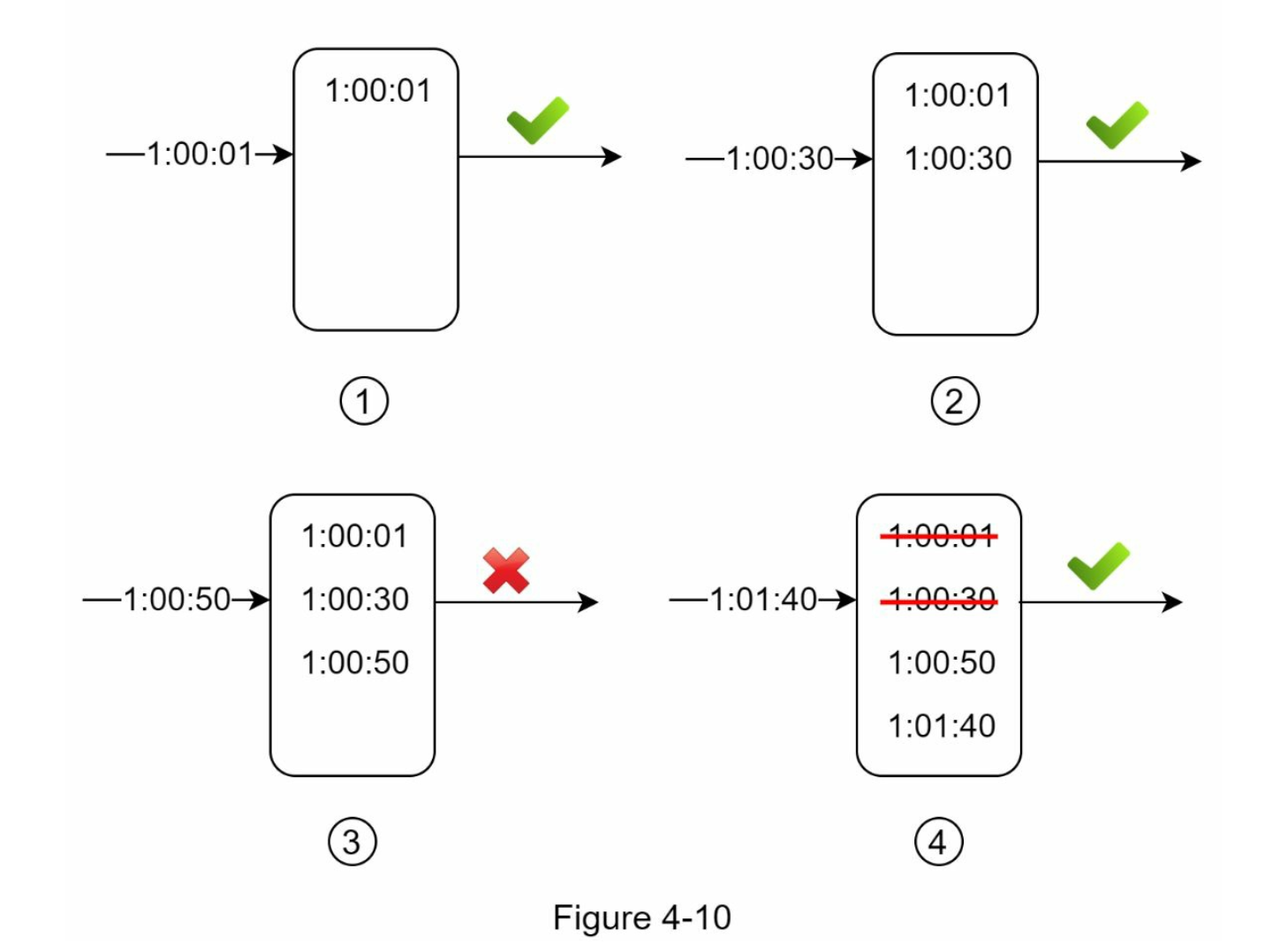
在这个例子中,限流器允许每分钟2个请求。通常情况下,Linux的时间戳会存储在日志中。然而,在我们的例子中,为了提高可读性,使用了人类可读的时间表示法。
- 当一个新的请求在 $$1:00:01$$ 到达时,该日志是空的。因此,该请求被允许。
- 一个新的请求在 $$1:00:30$$ 到达,时间戳 $$1:00:30$$ 被插入到日志中。插入后,日志大小为2,不大于允许的数量,因此,该请求被允许。
- 一个新的请求在 $$1:00:50$$ 到达,时间戳被插入到日志中。插入后,日志大小为3,大于允许的大小2。因此,这个请求被拒绝,尽管时间戳仍然在日志中。
- 一个新的请求在 $$1:01:40$$ 到达。在 $$\left [1:00:40,1:01:40 \right]$$ 范围内的请求是在最新的时间范围内,但在 $$1:00:40$$ 之前发送的请求是过时的。
- 两个过期的时间戳 $$1:00:01$$ 和 $$1:00:30$$ 被从日志中删除。在删除操作之后,日志大小变成了2;因此,请求被接受。
优点:
- 这种算法实现的速率限制是非常准确的。在任何滚动窗口中,请求都不会超过速率限制。
缺点:
- 该算法消耗了大量的内存,因为即使一个请求被拒绝,其时间戳仍可能被存储在内存中
滑动窗口计数器算法
滑动窗口计数器(Sliding window counter)算法是一种混合方法,结合了固定窗口计数器和滑动窗口日志。 该算法可以通过两种不同的方法来实现。我们将在本节中解释一种实现方法,并在本节末尾提供另一种实现方法的参考。
图4-11说明了这种算法的工作原理:
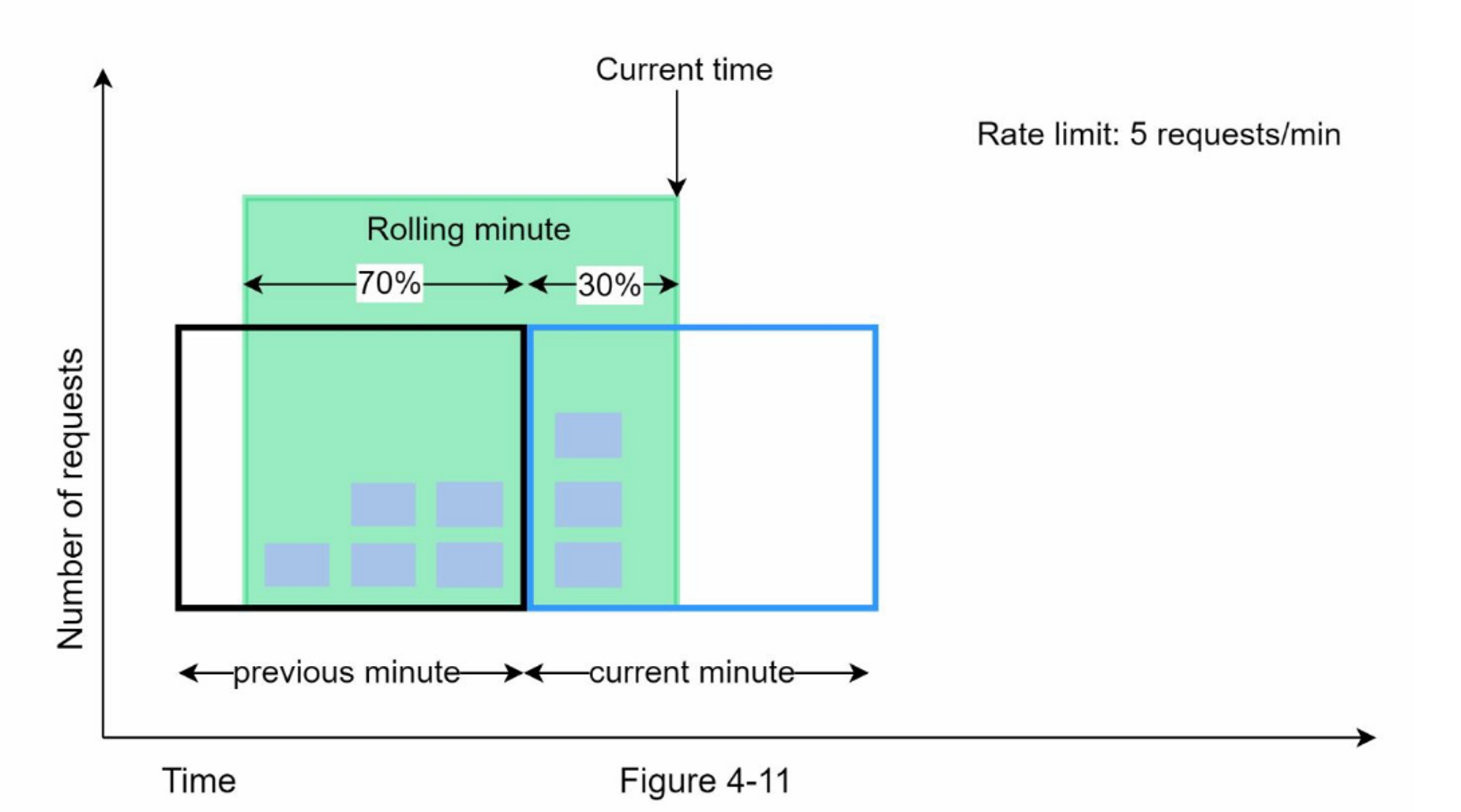
假设限流器允许每分钟最多有7个请求,在上一分钟有5个请求,当前一分钟有3个请求。对于在当前分钟内到达30%位置的新请求,滚动窗口中的请求数用以下公式计算:
- 当前窗口中的请求数量 + 上一个窗口中的请求数量 * 滚动窗口和上一个窗口的重叠百分比
- 使用这个公式,我们得到 $$3 + 5 \times 0.7 % = 6.5$$ 个请求。根据不同的使用情况,这个数字可以向上或向下取整。在我们的例子中,它被向下四舍五入为6。
由于限流器每分钟最多允许7个请求,当前的请求可以通过。然而,再收到一个请求后,就会达到限制。
由于篇幅所限,我们在此不讨论其他的实现。有兴趣的读者可以参考参考资料[9]。这种算法并不完美。它有优点也有缺点。
优点:
- 它平滑了流量的峰值,因为速率是基于前一个窗口的平均速率。
- 内存高效
缺点:
- 它只适用于不太严格的回看窗口。它是实际速率的近似值,因为它假设前一个窗口的请求是均匀分布的。然而,这个问题可能并不像它看起来那么糟糕。 根据Cloudflare[10]所做的实验,在4亿个请求中,只有0.003%的请求被错误地允许或限制速率
高层次的架构
限流算法的基本思想很简单。在高层次上,我们需要一个计数器来跟踪来自同一用户、IP地址等的多少个请求。如果计数器大于限制值,则请求被禁止。
我们应该在哪里存储计数器?由于磁盘访问速度慢,使用数据库并不是一个好主意。选择内存缓存是因为它速度快并且支持基于时间的过期策略。 例如,Redis[11]是实现速率限制的一个流行选择。它是一个内存中的存储,提供两个命令:INCR和EXPIRE
INCR:它使存储的计数器加1。EXPIRE:它为计数器设置一个超时。如果超时过后,计数器会被自动删除。
图4-12显示了速率限制的高层结构,其工作原理如下:
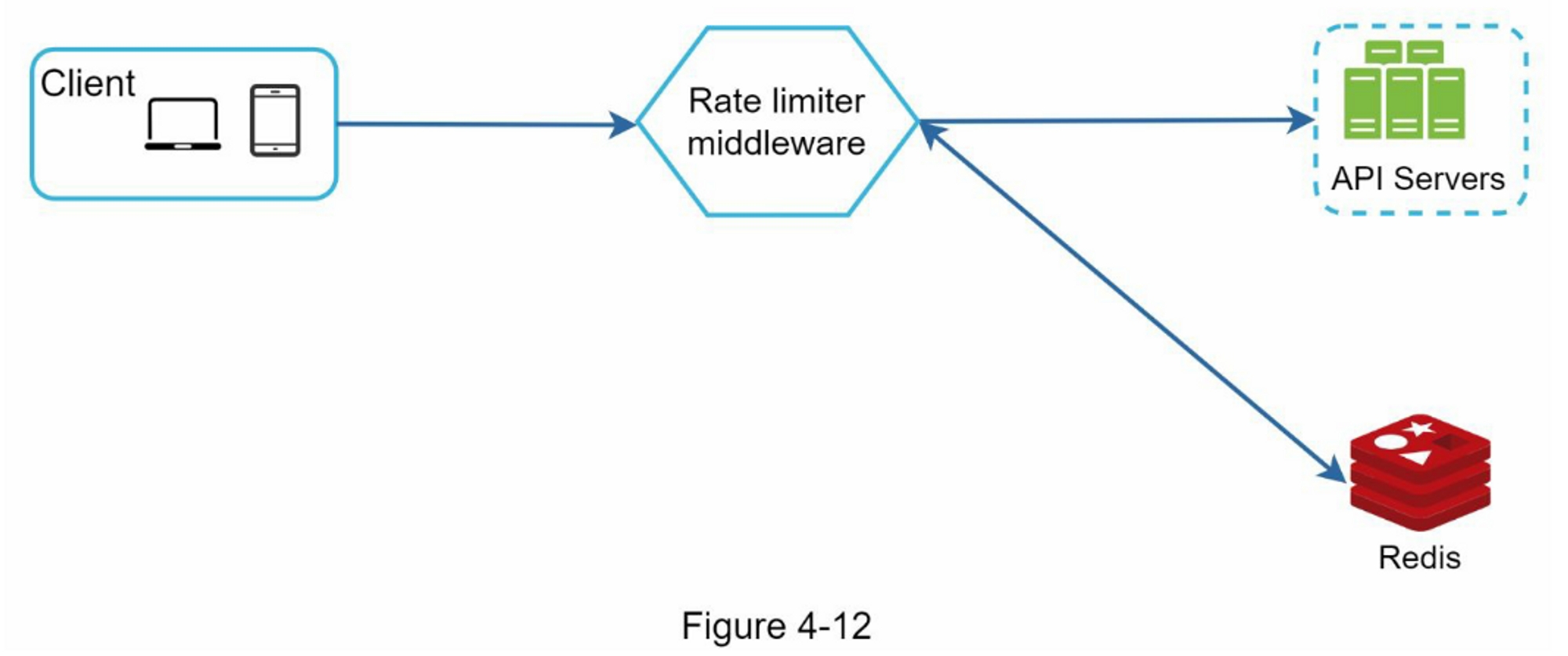
- 客户端向限流中间件发送请求
- 限流中间件从Redis中相应的桶中获取计数器,并检查是否达到限制
- 如果达到限制,则拒绝该请求
- 如果没有达到限制,请求会被发送到API服务器。同时,系统会增加计数器并将其保存回Redis。
第3步:深入设计
图4-12中的高层设计并没有回答以下问题:
- 如何创建速率限制规则?这些规则储存在哪里?
- 如何处理受限的请求?
在这一节中,我们将首先回答关于限流规则的问题,然后介绍处理限流请求的策略。最后,我们将讨论分布式环境中的限流、详细的设计、性能优化和监控。
限流规则
Lyft开源了他们的速率限制组件[12]。我们将窥探该组件的内部情况,并看看一些速率限制规则的例子。
domain: messaging
descriptors:
- key: message_type
Value: marketing
rate_limit:
unit: day
requests_per_unit: 5
在上述例子中,系统被配置为每天最多允许5条营销信息。下面是另一个例子:
domain: auth
descriptors:
- key: auth_type
Value: login
rate_limit:
unit: minute
requests_per_unit: 5
这个规则显示,客户不允许在1分钟内登录超过5次。规则一般写在配置文件中并保存在磁盘上。
超过速率限制
如果一个请求被限制了速率,API会向客户端返回一个HTTP响应代码429(请求太多)。根据不同的使用情况,我们可能会将速率受限的请求排队等候以后处理。 例如,如果一些订单由于系统过载而受到速率限制,我们可以保留这些订单以便以后处理。
限流器请求头
一个客户如何知道它是否被节流?客户端如何知道在被节流之前允许的剩余请求的数量?答案就在HTTP响应头中。限流器向客户端返回以下 HTTP 标头:
- X-Ratelimit-Remaining:窗口内允许请求的剩余数量
- X-Ratelimit-limit:它表示客户端在每个时间窗口可以进行多少次调用
- X-Ratelimit-Retry-After:等待的秒数,直到你可以再次提出请求而不被节流。
当用户发送过多请求时,将向客户端返回 429 too many requests 错误和 X-Ratelimit-Retry-After 标头。
详细设计
图 4-13 给出了系统的详细设计。
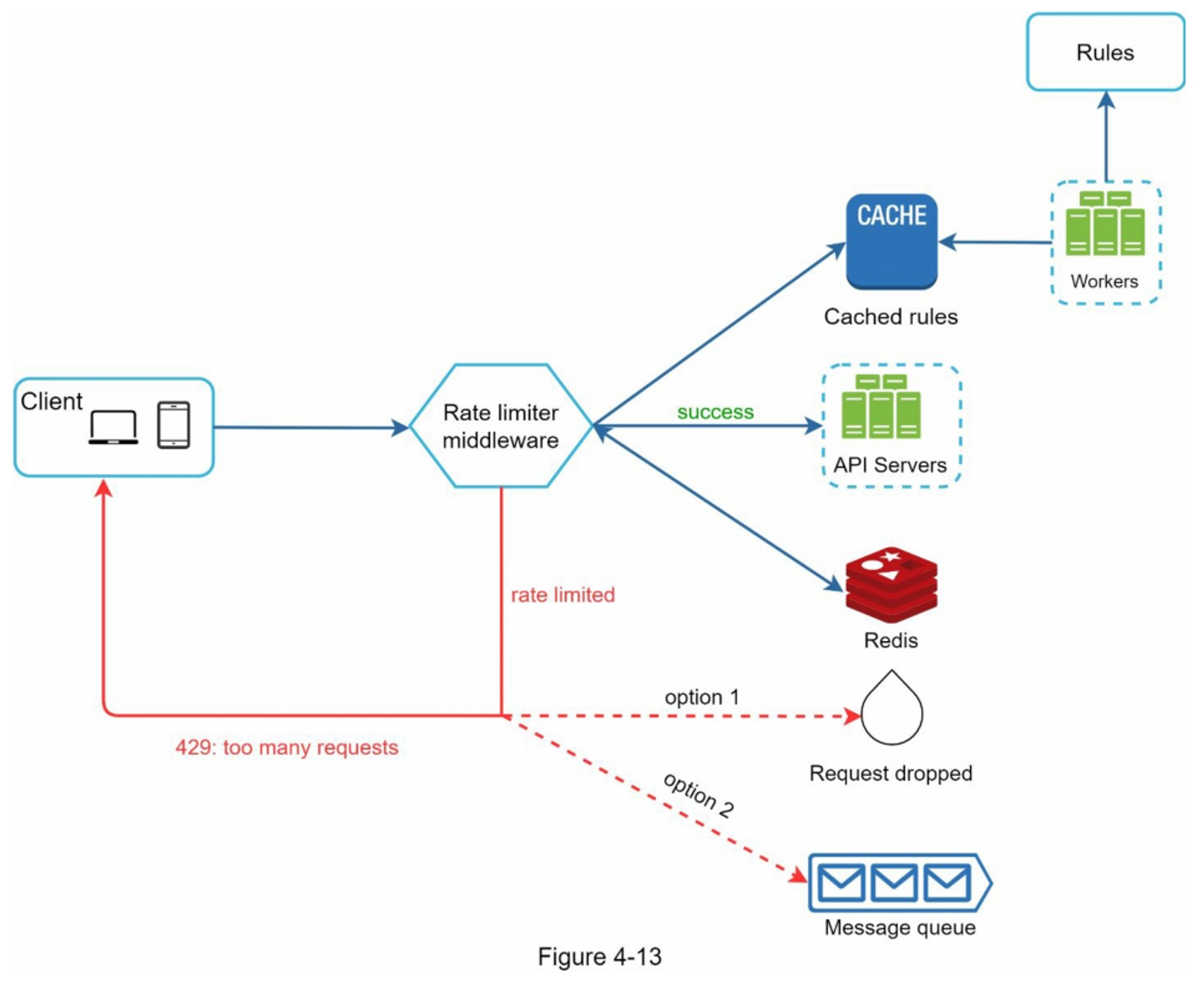
- 规则被存储在磁盘上。工作者经常从磁盘中提取规则,并将其存储在高速缓存中。
- 当客户端向服务器发送请求时,该请求首先被发送到限流中间件。
- 限流中间件从缓存中加载规则。它从Redis缓存中获取计数器和最后一次请求的时间戳。根据响应,限流器决定:
- 如果请求没有速率限制,它将被转发到API服务器。
- 如果请求受到速率限制,限流器会向客户端返回 429 too many requests 错误。 同时,请求被丢弃或转发到队列。
分布式环境下的限流器
构建一个在单个服务器环境下运行的限流器并不困难。然而,将系统扩展到支持多个服务器和并发线程是另一回事。这里有两个挑战:
- 竞争条件
- 同步问题
竞争条件
如前所述,限流器在高层的工作原理如下
- 从Redis读取计数器的值
- 检查 ( 计数器 + 1 ) 是否超过阈值
- 如果不是,则将 Redis 中的计数器值加 1
如图4-14所示,在高度并发的环境中会发生竞争条件。
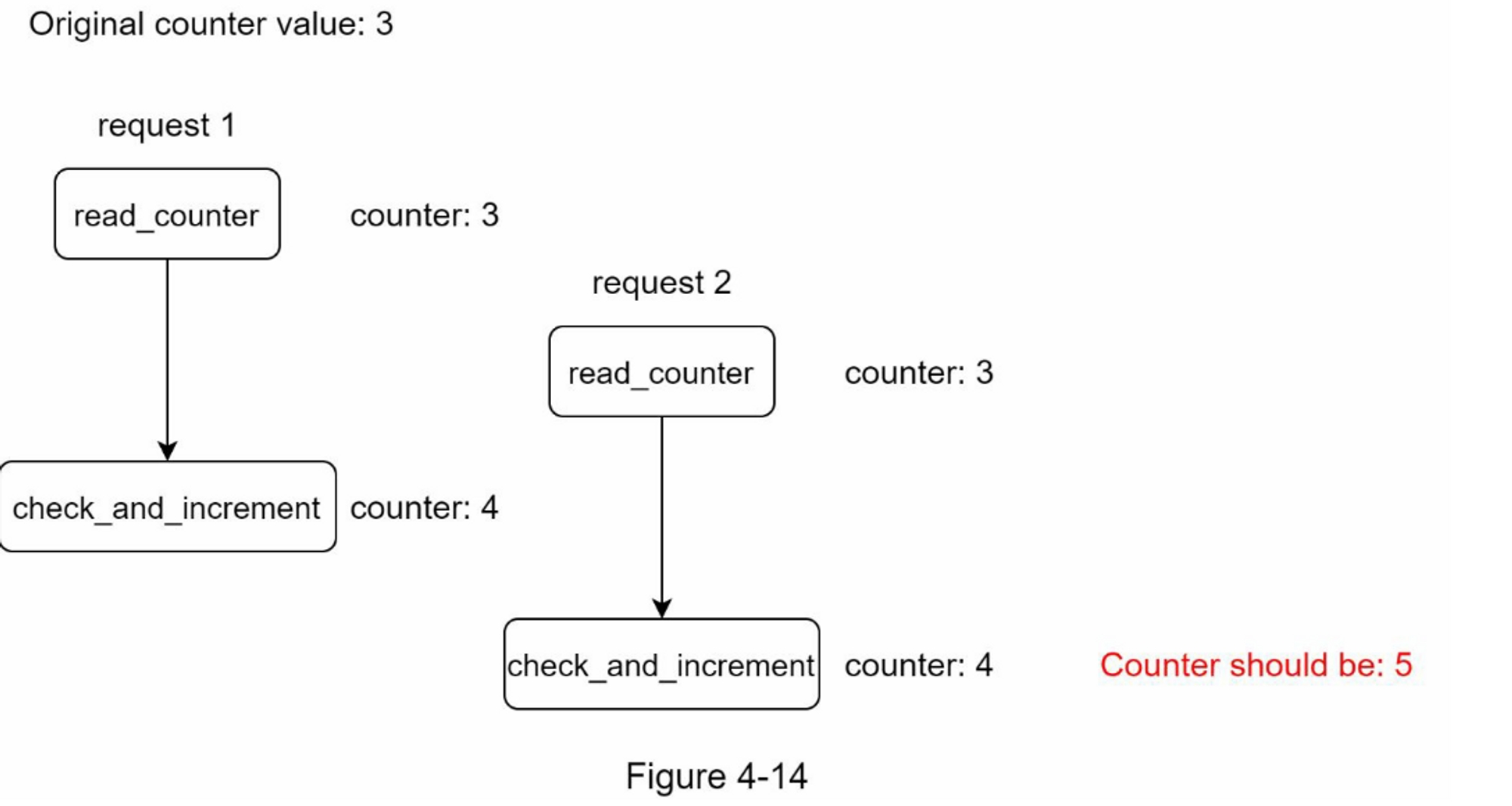
假设 Redis 中的计数器值为 3。如果两个请求在其中一个请求写回值之前同时读取计数器值,则每个请求都会将计数器加 1 并在不检查另一个线程的情况下将其写回。 两个请求(线程)都认为它们具有正确的计数器值 4。但是,正确的计数器值应该是 5
锁是解决竞争条件最明显的解决方案。 但是,锁会显着降低系统速度。 通常使用两种策略来解决这个问题: Lua 脚本 [13] 和 Redis [8] 中的 sorted sets 数据结构。 对这些策略感兴趣的读者可以参考相应的参考资料[8] [13]。
同步问题
同步是分布式环境中要考虑的另一个重要因素。 要支持数百万用户,一个限流器服务器可能不足以处理流量。 当使用多个限流器服务器时,需要同步。 例如,在图 4-15 的左侧,客户端 1 将请求发送到限流器 1,客户端 2 将请求发送到限流器 2。 由于 Web 层是无状态的,客户端可以将请求发送到不同的限流器,如图所示,在图 4-15 的右侧。 如果没有发生同步,限流器 1 不包含有关客户端 2 的任何数据。因此,限流器无法正常工作。 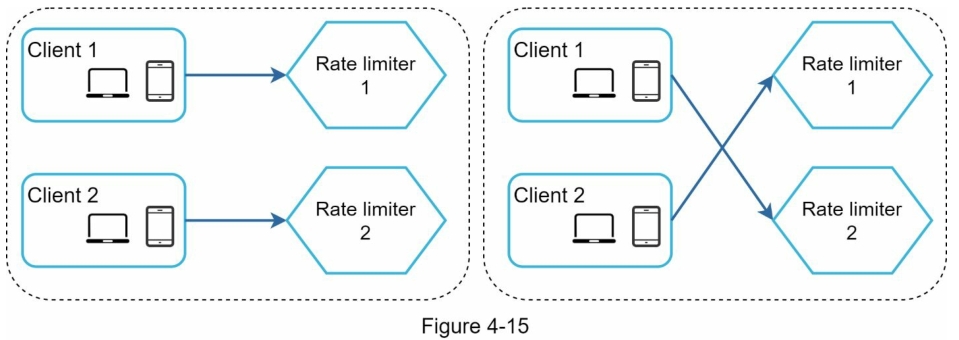
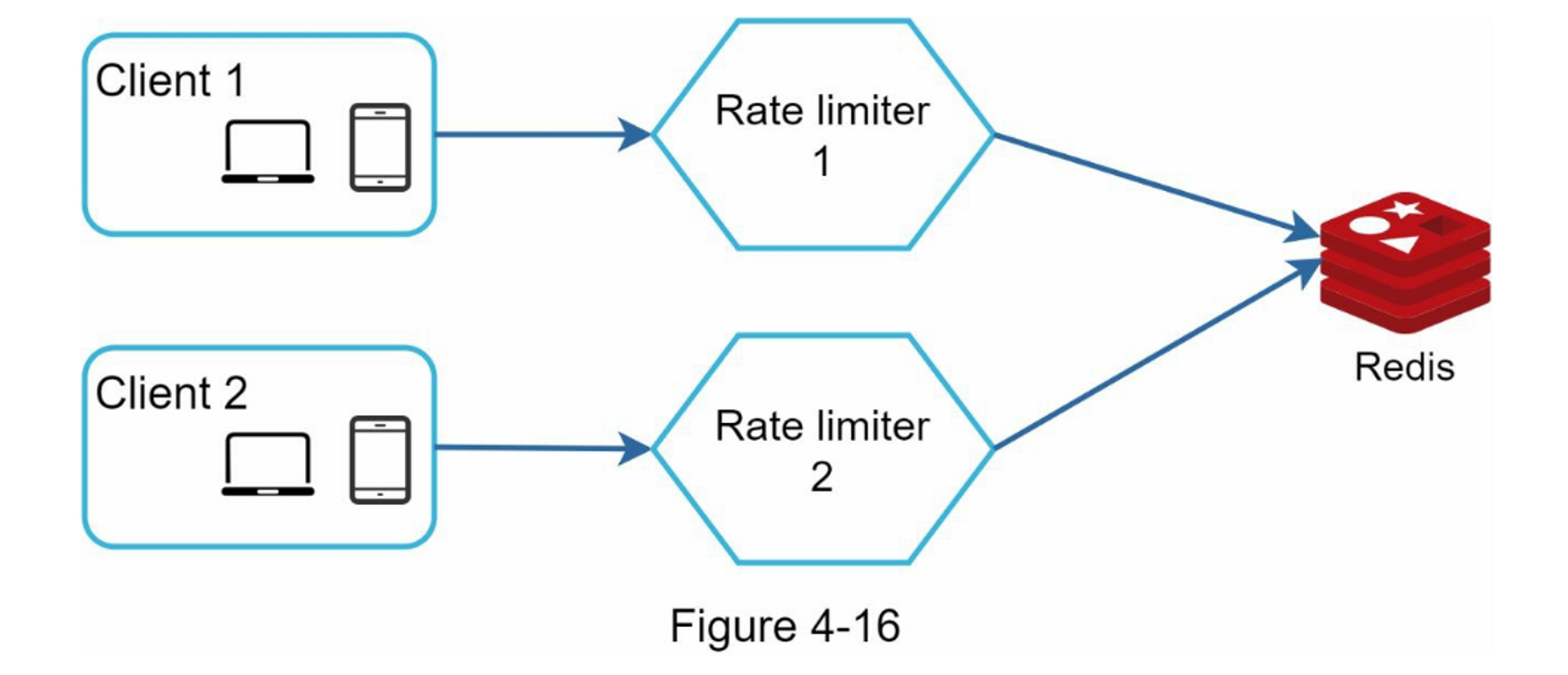
一种可能的解决方案是使用粘性会话,允许客户端将流量发送到相同的限流器。 这个解决方案是不可取的,因为它既不可扩展也不灵活。 更好的方法是使用像 Redis 这样的集中式数据存储。
设计如图 4-16 所示:
性能优化
性能优化是系统设计面试中的一个常见话题。我们将涉及两个方面的改进。
首先,多数据中心的设置对限流器至关重要,因为对于远离数据中心的用户来说,延迟很高。大多数云服务提供商在世界各地建立了许多边缘服务器位置。 例如,截至2020年5月20日,Cloudflare有194个地理上分布的边缘服务器[14]。流量被自动路由到最近的边缘服务器,以减少延时。
第二,用最终的一致性模型来同步数据。如果你不清楚最终的一致性模型,请参考 "第6章:设计一个键值存储 "中的 "一致性 "部分。
监控
限流器到位后,最重要的是要收集分析数据以检查限流器是否有效。
首先,我们要确保:
- 限流算法是有效的
- 限流规则是有效的
例如,如果速率限制规则过于严格,则会丢弃许多有效请求。 在这种情况下,我们想稍微放宽规则。 在另一个示例中,我们注意到当流量突然增加时(如抢购),我们的限流器变得无效。 在这种场景下,我们可能会更换算法来支持突发流量。 令牌桶很适合这种场景。
第4步:总结
在这一章中,我们讨论了速率限制的不同算法和它们的优点和缺点。
讨论的算法包括:
- 令牌桶
- 漏桶
- 固定窗口计数器
- 滑动窗口日志
- 滑动窗口计数器
然后,我们讨论了系统架构、分布式环境中的限流器、性能优化和监控。 与任何系统设计面试问题类似,如果时间允许,您可以提及其他谈话要点:
- 硬件 与 软件限流对比
- 硬件:请求的数量不能超过阈值
- 软件:请求可以在短时间内超过阈值
- 不同级别的限流。在本章中,我们只讨论了应用程序级别(HTTP:第 7 层)的限流,可以在其他层应用限流。例如,你可以使用Iptables[15](IP:第3层)按IP地址应用速率限制。 注意:开放系统互连模型(OSI模型)有7层[16]。第1层:物理层,第2层:数据链路层,第3层:网络层,第4层:传输层,第5层:会话层,第6层:表示层,第7层:应用层。
- 避免被限速,使用最佳实践设计你的客户端:
- 使用客户端缓存,以避免频繁调用API
- 了解限制,不要在短时间内发送太多请求
- 包含捕获异常或错误的代码,以便客户端可以从异常中恢复正常
- 为重试逻辑增加足够的回退时间
恭喜你走到了这一步!现在给自己一个鼓励,干得漂亮!
参考资料
[1] Rate-limiting strategies and techniques: https://cloud.google.com/solutions/rate-limiting-strategies-techniques
[2] Twitter rate limits: https://developer.twitter.com/en/docs/basics/rate-limits
[3] Google docs usage limits: https://developers.google.com/docs/api/limits
[4] IBM microservices: https://www.ibm.com/cloud/learn/microservices
[5] Throttle API requests for better throughput:
https://docs.aws.amazon.com/apigateway/latest/developerguide/api-gateway-request-throttling.html
[6] Stripe rate limiters: https://stripe.com/blog/rate-limiters
[7] Shopify REST Admin API rate limits: https://help.shopify.com/en/api/reference/rest-admin-api-rate-limits
[8] Better Rate Limiting With Redis Sorted Sets: https://engineering.classdojo.com/blog/2015/02/06/rolling-rate-limiter/
[9] System Design — Rate limiter and Data modelling: https://medium.com/@saisandeepmopuri/system-design-rate-limiter-and-data-modelling-9304b0d18250
[10] How we built rate limiting capable of scaling to millions of domains: https://blog.cloudflare.com/counting-things-a-lot-of-different-things/
[11] Redis website: https://redis.io/
[12] Lyft rate limiting: https://github.com/lyft/ratelimit
[13] Scaling your API with rate limiters: https://gist.github.com/ptarjan/e38f45f2dfe601419ca3af937fff574d#request-rate-limiter
[14] What is edge computing: https://www.cloudflare.com/learning/serverless/glossary/what-is-edge-computing/
[15] Rate Limit Requests with Iptables: https://blog.programster.org/rate-limit-requests-with-iptables
[16] OSI model: https://en.wikipedia.org/wiki/OSI_model#Layer_architecture
第05章:一致性hash设计
为了实现水平扩展,在服务器之间高效、均匀地分配请求/数据非常重要。一致哈希是实现这一目标的常用技术。但首先,让我们深入研究一下这个问题。
再哈希问题
如果你有n个缓存服务器,平衡负载的一个常用方法是使用以下哈希方法:
$$serverIndex = hash(key) \bmod N$$,其中N是服务器池的大小
让我们用一个例子来说明它是如何工作的。如表5-1所示,我们有4个服务器和8个字符串键及其哈希值。
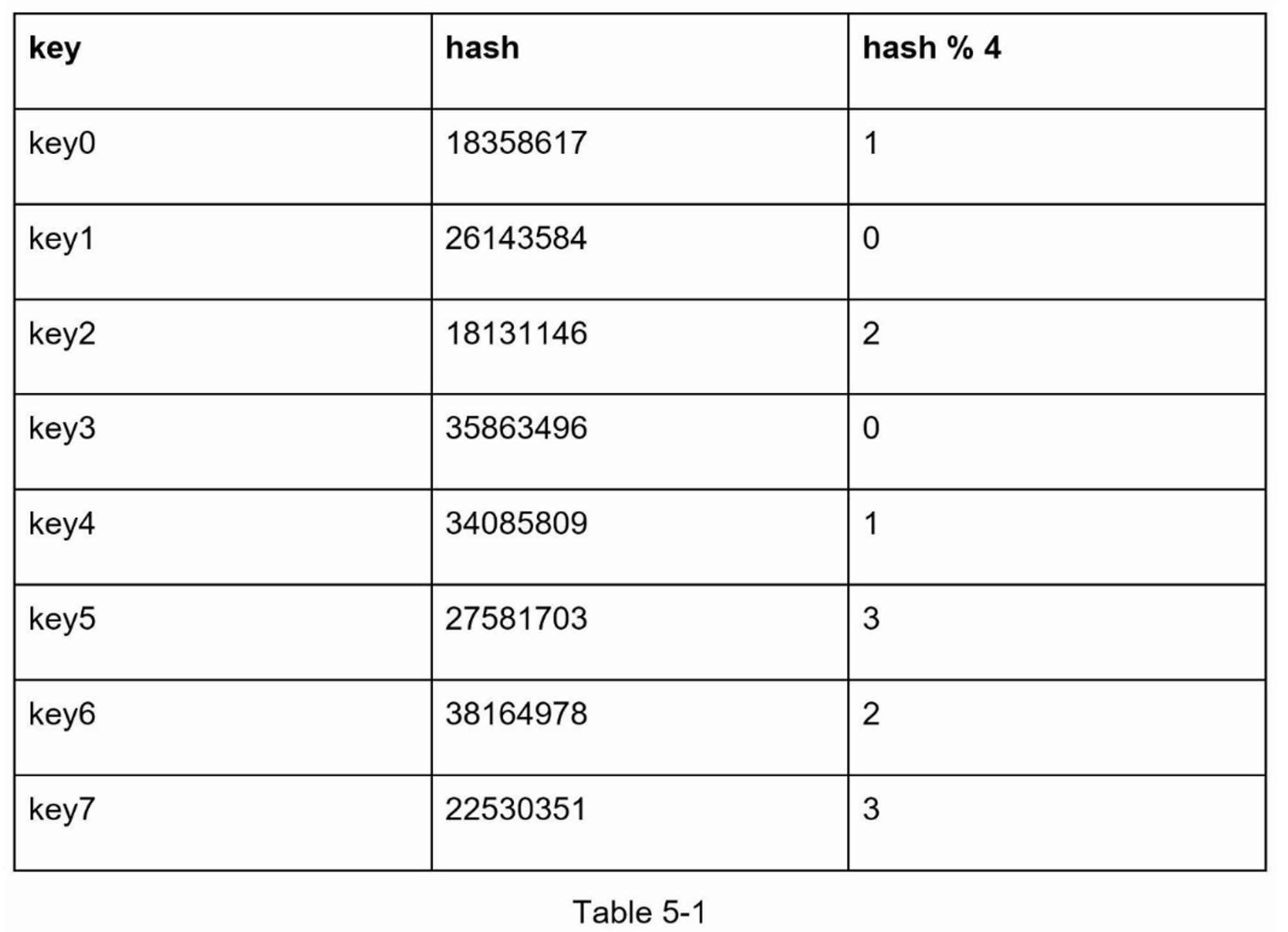
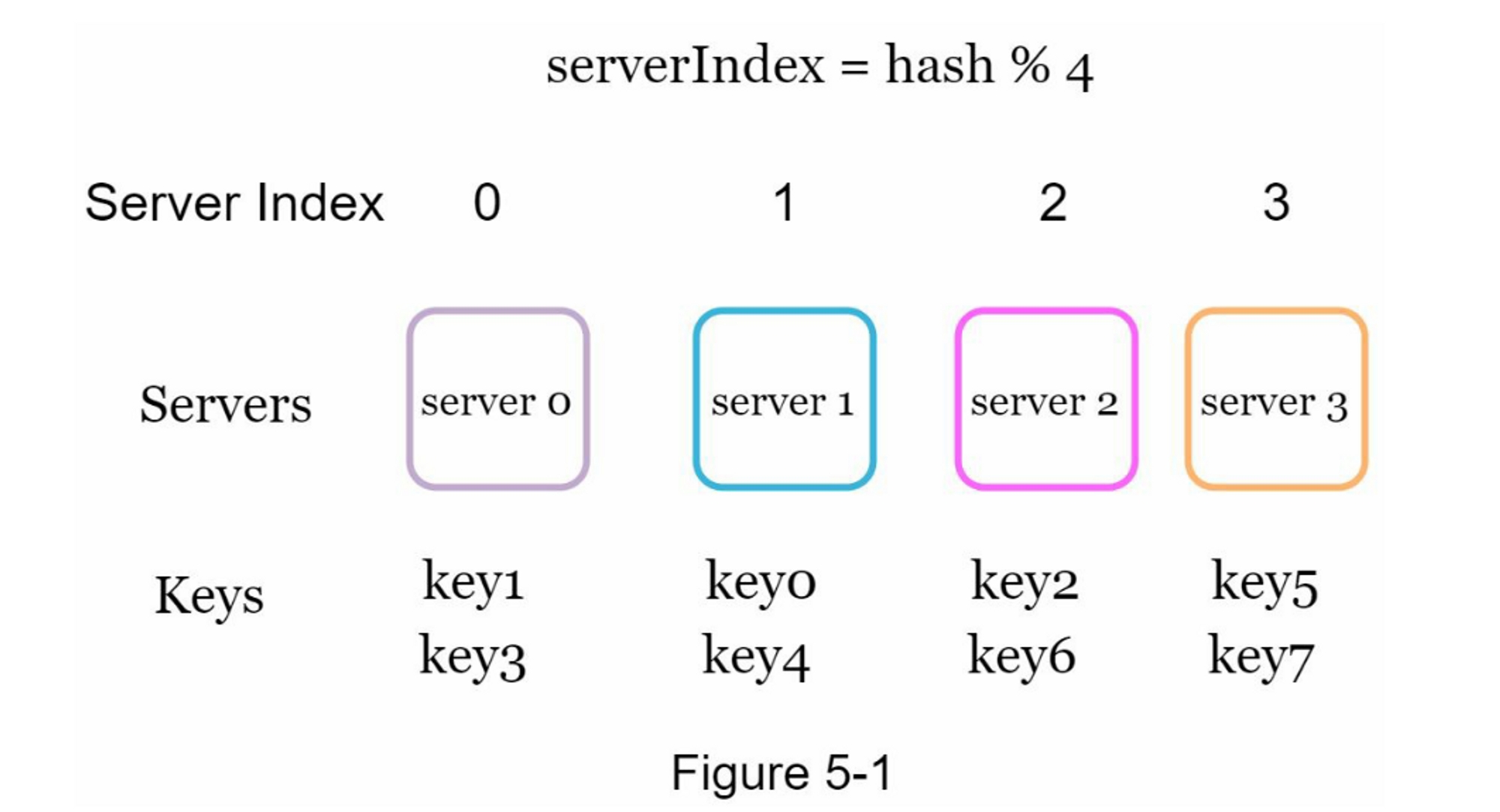
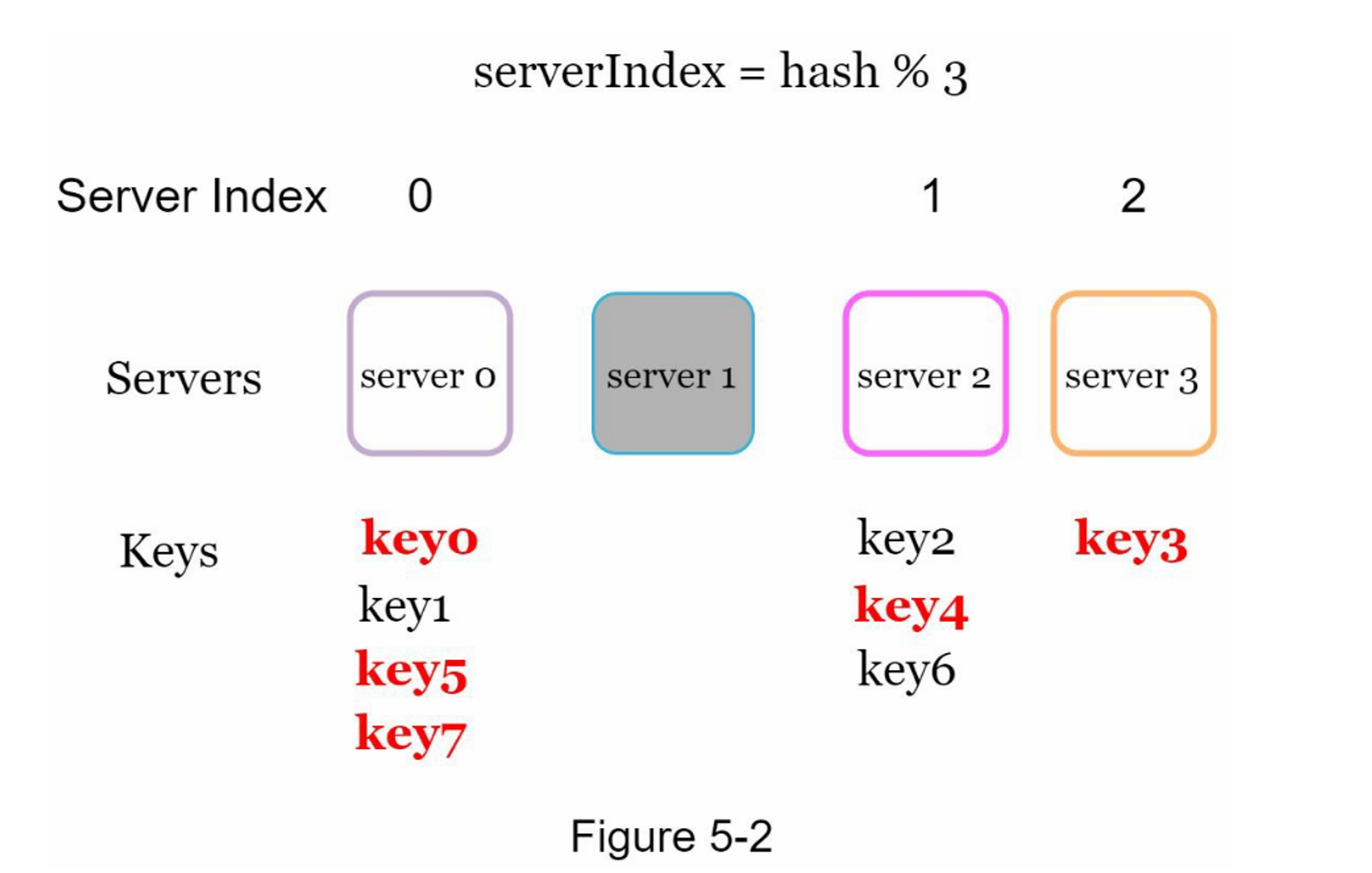
为了获取存储键的服务器,我们进行求余操作 $$f(key) \bmod 4$$。例如, $$hash(key0) \bmod 4 = 1$$ 意味着客户端必须联系服务器1来获取缓存的数据。图5-1显示了基于表5-1的键的分布情况
当服务器池的大小是固定的,而且数据分布均匀时,这种方法效果很好。然而,当增加新的服务器,或删除现有的服务器时,问题就会出现。
例如,如果服务器1下线了,服务器池的大小就变成了 3。使用相同的哈希函数,我们得到的键的哈希值是相同的。 但是应用求余操作,我们会得到不同的服务器索引,因为服务器的数量减少了 1。 通过应用 $$hash \bmod 3$$,我们得到的结果如表5-2所示:
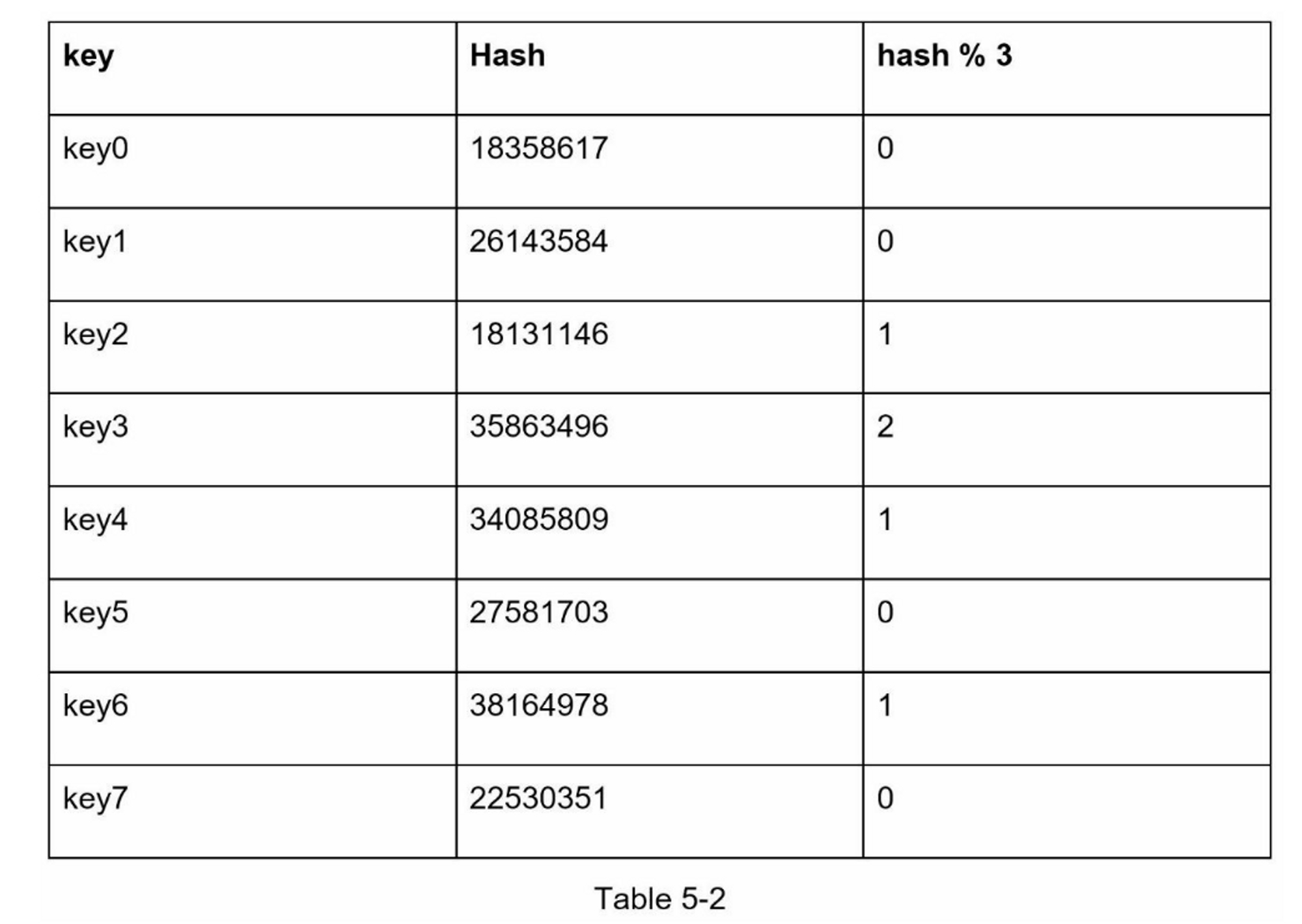
图5-2显示了基于表5-2的新的键分布。
如图5-2所示,大多数键都被重新分配,而不仅仅是最初存储在脱机服务器(服务器1)中的键。 这意味着,当服务器1离线时,大多数缓存客户会连接到错误的服务器来获取数据,这就造成了高速缓存失误的风暴。一致性哈希是一种有效的技术来缓解这个问题。
一致性哈希
引用自维基百科:“一致性哈希是一种特殊的哈希,当重新调整哈希表的大小并使用一致性哈希时,平均只需要重新映射 $$k/n$$ 个键,其中 $$k$$ 是键的数量, $$n$$ 是槽的数量。 相比之下,在大多数传统的哈希表中,数组槽数量的变化导致几乎所有键都被重新映射 [1]”
哈希空间和哈希环
现在我们了解了一致性哈希的定义,让我们看看它是如何工作的。假设使用SHA-1作为哈希函数f,哈希函数的输出范围为: $$x_0,x_1,x_2,x_3,...,x_n$$。 在密码学中,SHA-1 的哈希空间从 $$0$$ 到 $$2^{160} – 1$$。也就是说, $$x_0$$ 对应 $$0$$, $$x_n$$ 对应 $$2^{160} – 1$$,中间的所有其他哈希值都在 $$0$$ 和 $$2^{160} – 1$$ 之间。 图 5-3 显示了哈希空间。

通过收集两端,我们得到一个哈希环,如图5-4所示:
哈希服务器
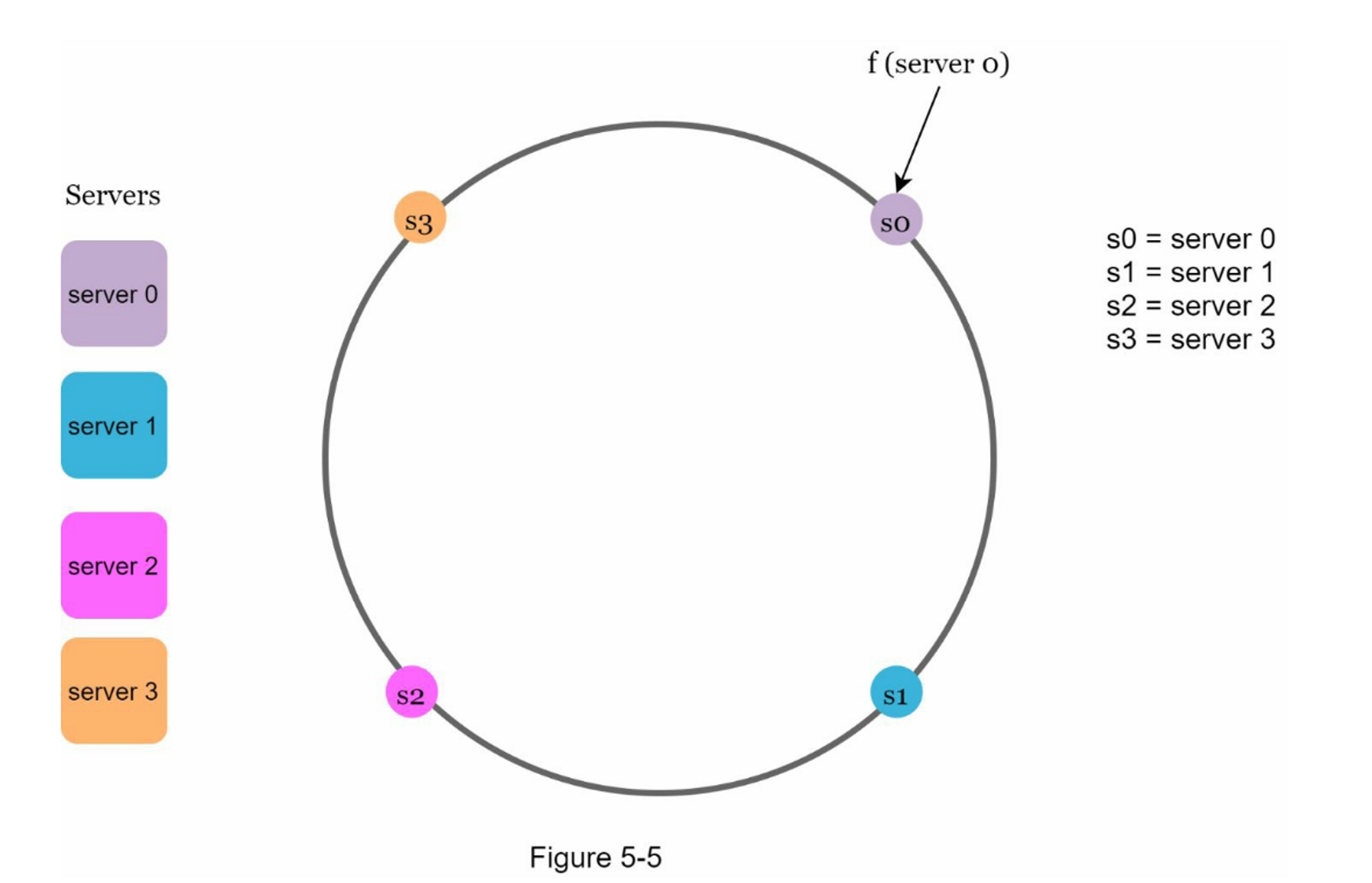
使用相同的哈希函数 f,我们根据服务器的 IP 或名称将服务器映射到环上。 图 5-5 显示哈希环上映射了 4 个服务器
哈希键
值得一提的是,这里使用的哈希函数与“rehashing problem”中的哈希函数不同,没有模运算。 如图5-6所示,4个缓存键(key0、key1、key2、key3)被哈希到哈希环Server lookup。 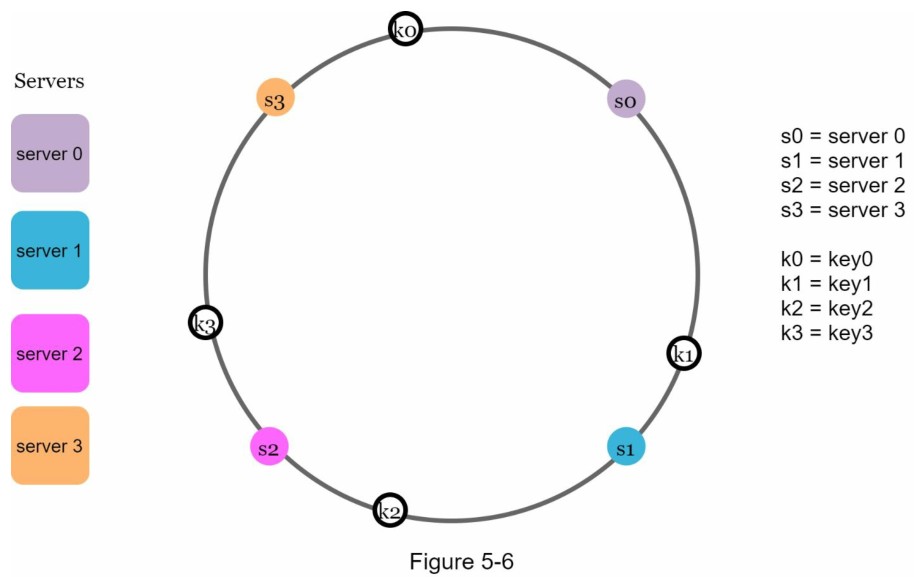
服务器查找
为了确定键存放在哪个服务器上,我们从键在环上的位置顺时针查找,直到找到一个服务器。 图5-7解释了这个过程。顺时针方向查找,key0存储在server0;key1存储在server1;key2存储在server2,key3存储在server3。 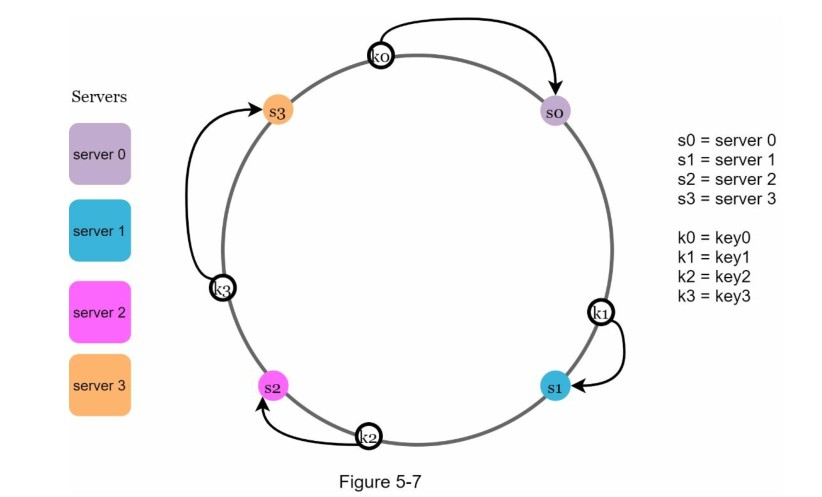
添加一台服务器
使用上述逻辑,增加一台新的服务器将只需要重新分配一部分的键。
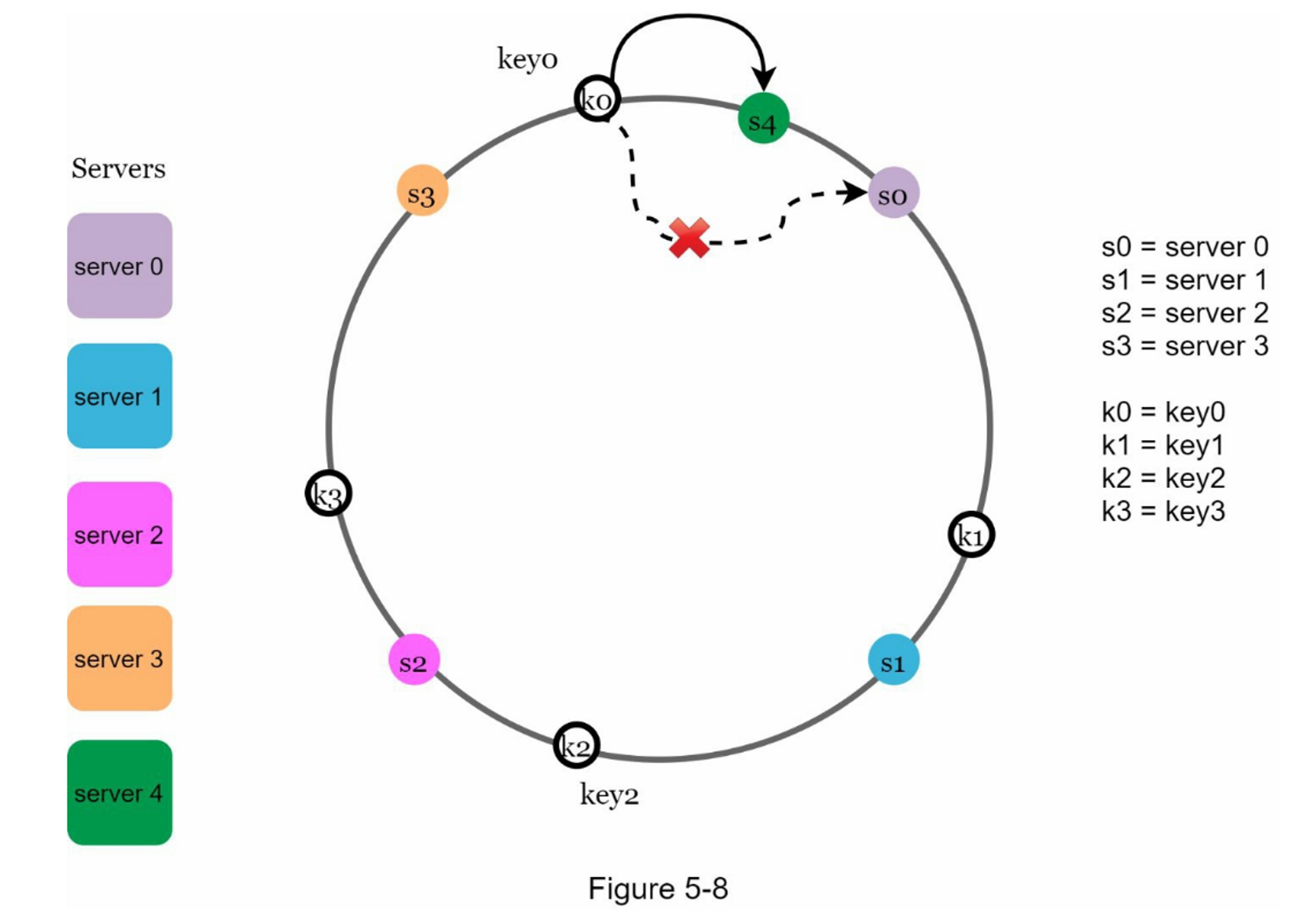
在图5-8中,新增server4后,只需要重新分配key0即可。 k1、k2 和 k3 保留在相同的服务器上。 让我们仔细看看其中的逻辑,在加入server4之前,key0是存放在server0上的。现在key0会存放在server4上,因为server4是从key0在环上顺时针方向第一个遇到的server。 根据一致性哈希算法,其他键不会被重新分配。
移除一台服务器
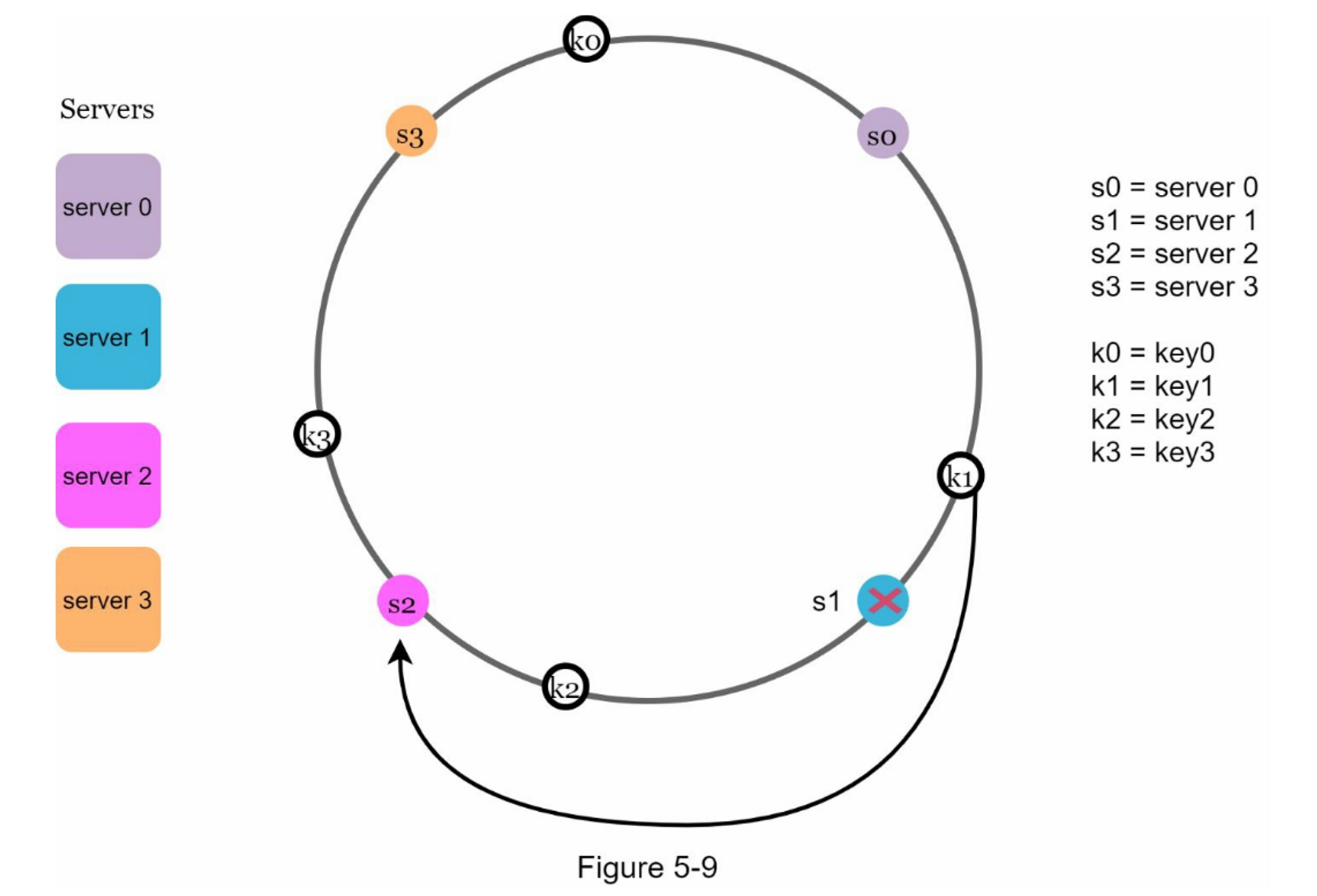
当一台服务器被移除时,只有一小部分的键需要用一致的哈希法进行重新分配。 在图5-9中,当server1被移除时,只有key1必须被重新映射到server2。 其余的键不受影响。
基本方法中的两个问题
一致哈希算法是由麻省理工学院的Karger等人提出的[1]。
基本步骤如下:
- 使用均匀分布的哈希函数将服务器和键映射到环上。
- 要想知道一个键被映射到哪个服务器,从键的位置顺时针查找,直到找到环上的第一个服务器。
这种方法存在两个问题:
-
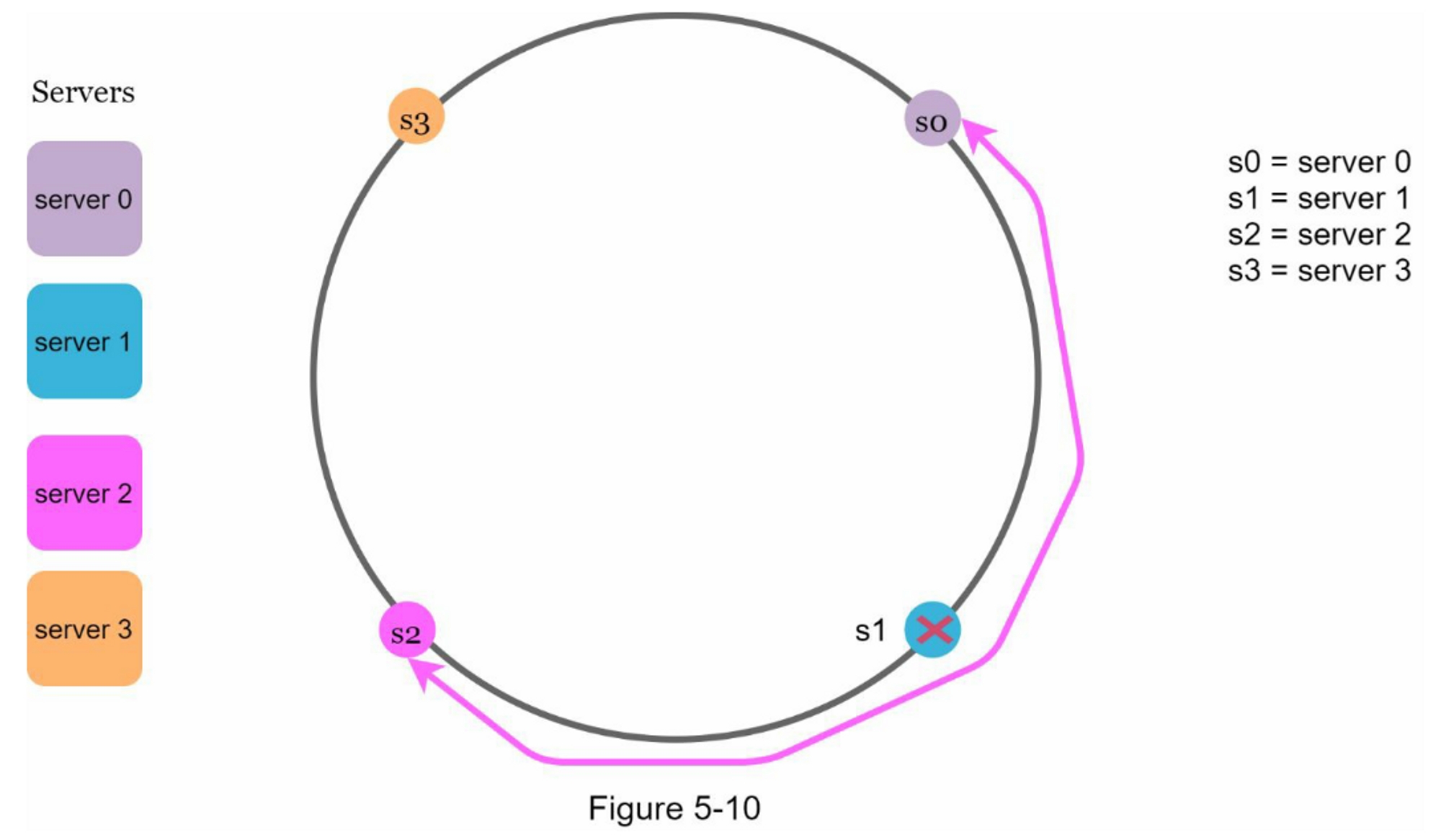
首先,考虑到可以添加或删除服务器,不可能保持环上所有服务器的分区大小相同。 分区是相邻服务器之间的哈希空间。 分配给每个服务器的环上分区的大小可能非常小或相当大。在图5-10中,如果删除s1,s2的分区(用双向箭头突出显示)是s0和s3分区的两倍。
-
第二,在环上有可能出现不均匀的键分布。例如,如果服务器被映射到图5-11中所列的位置,大部分的密钥都存储在
serve2上。然而,server1和serser3没有数据。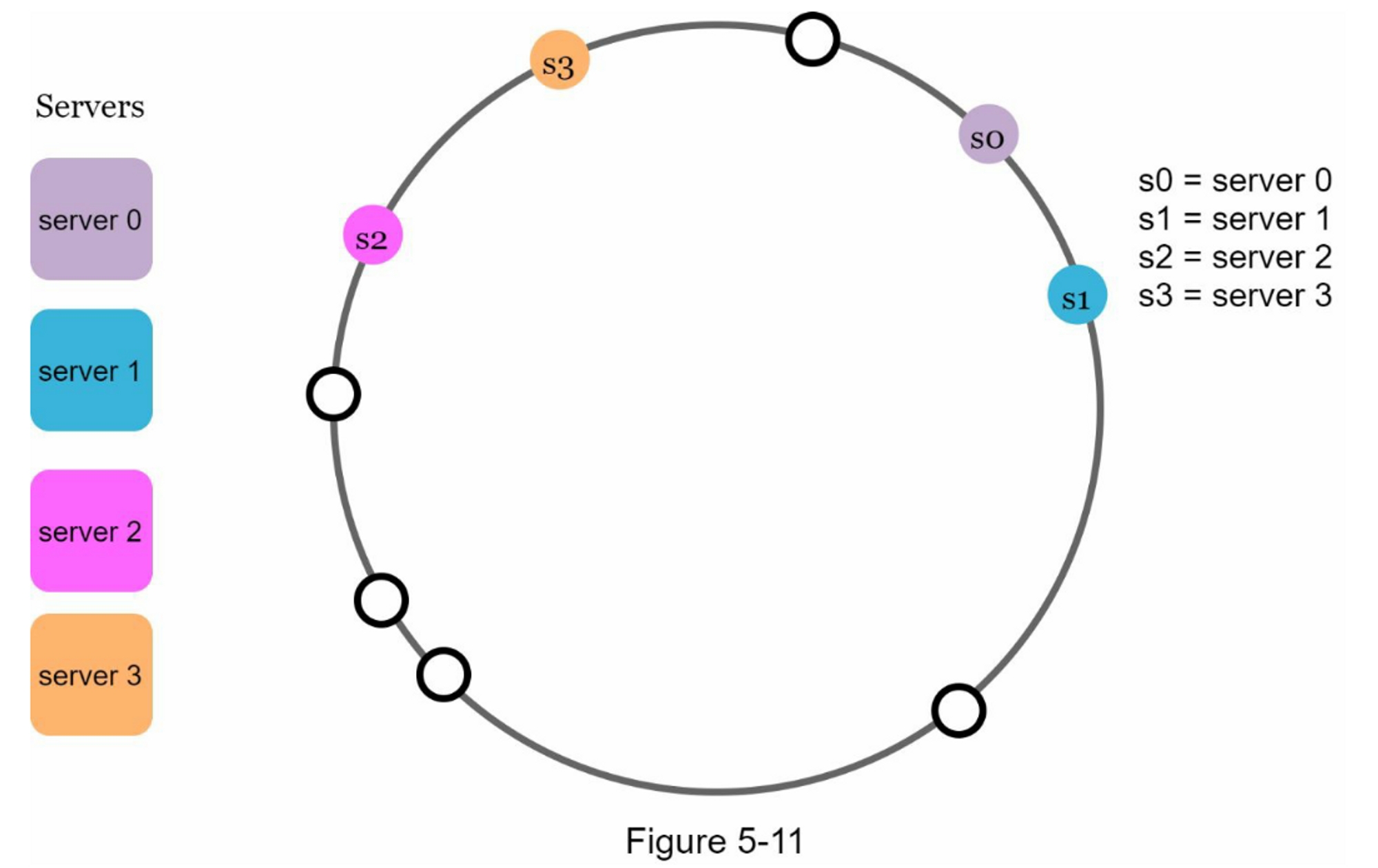
一种叫做虚拟节点或复制的技术被用来解决这些问题
虚拟节点
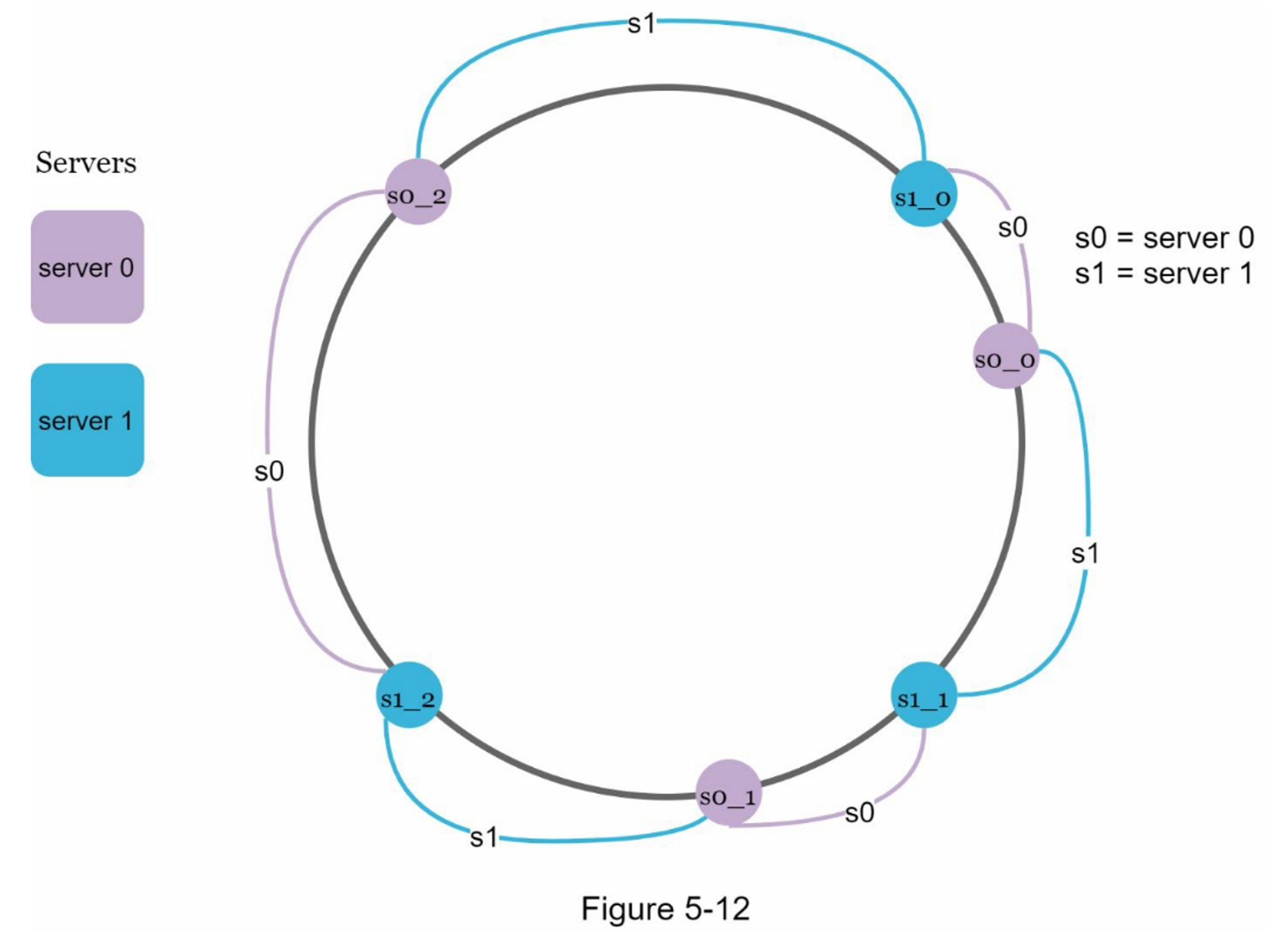
虚拟节点是指真实节点,每个服务器由环上的多个虚拟节点表示。在图5-12中,server0和server1都有3个虚拟节点。 3是任意选择的;而在现实世界的系统中,虚拟节点的数量要大得多。我们不用s0,而是用s0_0、s0_1和s0_2来代表环上的server0。 同样地,s1_0、s1_1和s1_2代表环上的server1。通过虚拟节点,每个服务器负责多个分区。标签为s0的分区(边)由server0管理。 另一方面,标签为s1的分区则由server1管理。
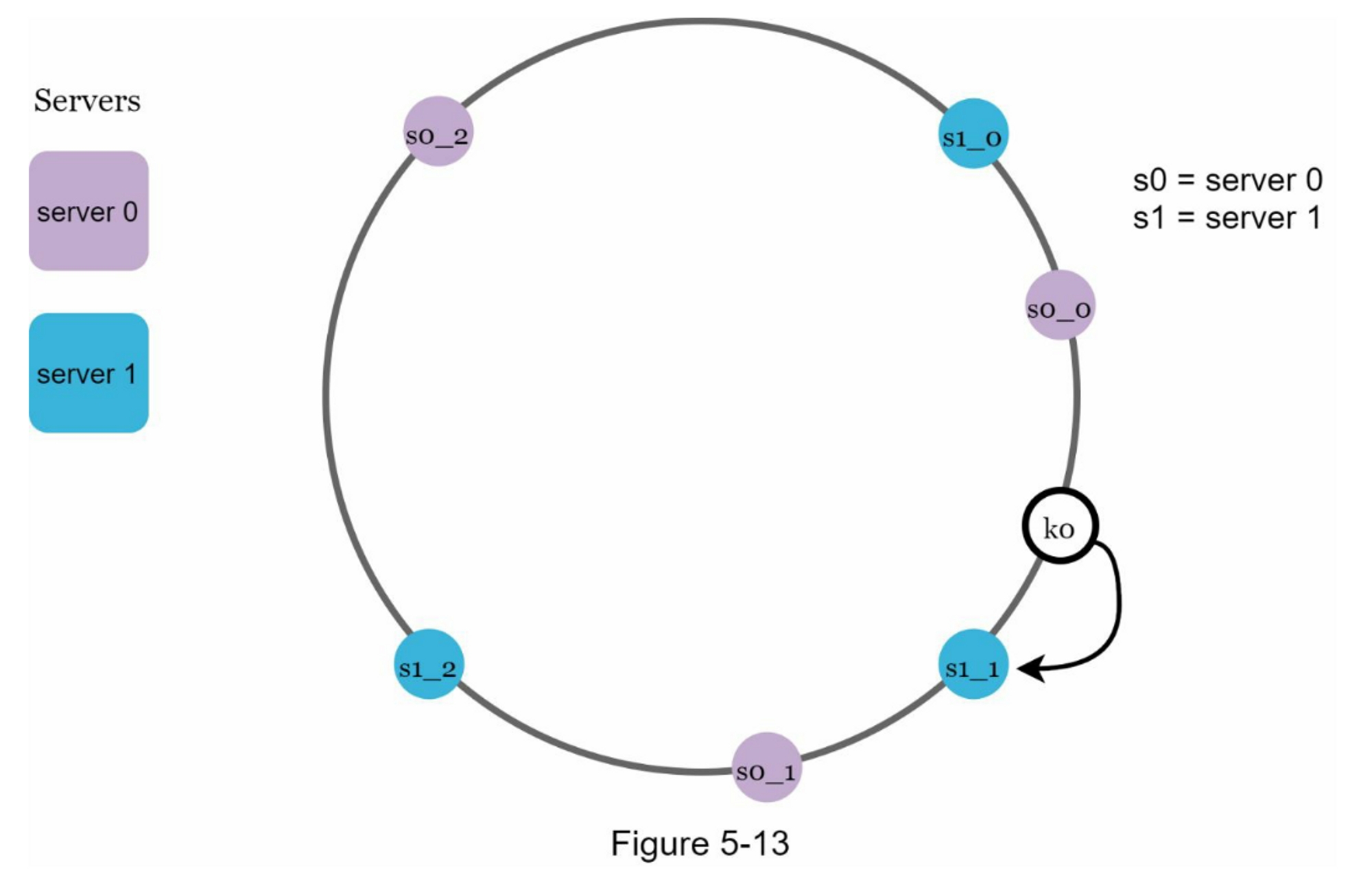
为了找到键存储在哪个服务器上,我们从键的位置顺时针方向找到环上遇到的第一个虚拟节点。 在图5-13中,为了找出k0存储在哪个服务器上,我们从k0的位置顺时针方向找到虚拟节点s1_1,它就是是server1。
随着虚拟节点数量的增加,密钥的分布变得更加均衡。 这是因为随着虚拟节点数量的增加,标准偏差变小,导致数据分布更加均衡。 标准偏差衡量数据的离散程度。 一项在线研究 [2] 的实验结果显示,对于一两百个虚拟节点,标准偏差在均值的 5%(200 个虚拟节点)和 10%(100 个虚拟节点)之间。 当我们增加虚拟节点的数量时,标准偏差会更小。 但是,需要更多空间来存储有关虚拟节点的数据。 这是一个权衡,我们可以调整虚拟节点的数量以满足我们的系统要求。
找出受影响的键
当一个服务器被添加或删除时,有一部分数据需要重新分配。我们怎样才能找到受影响的范围来重新分配?
在图5-14中,Server 4加入环中。 受影响的范围从 s4(新添加的节点)开始并沿环逆时针方向移动,直到找到服务器(s3)。 因此,位于 s3 和 s4 之间的键需要重新分配给 s4。
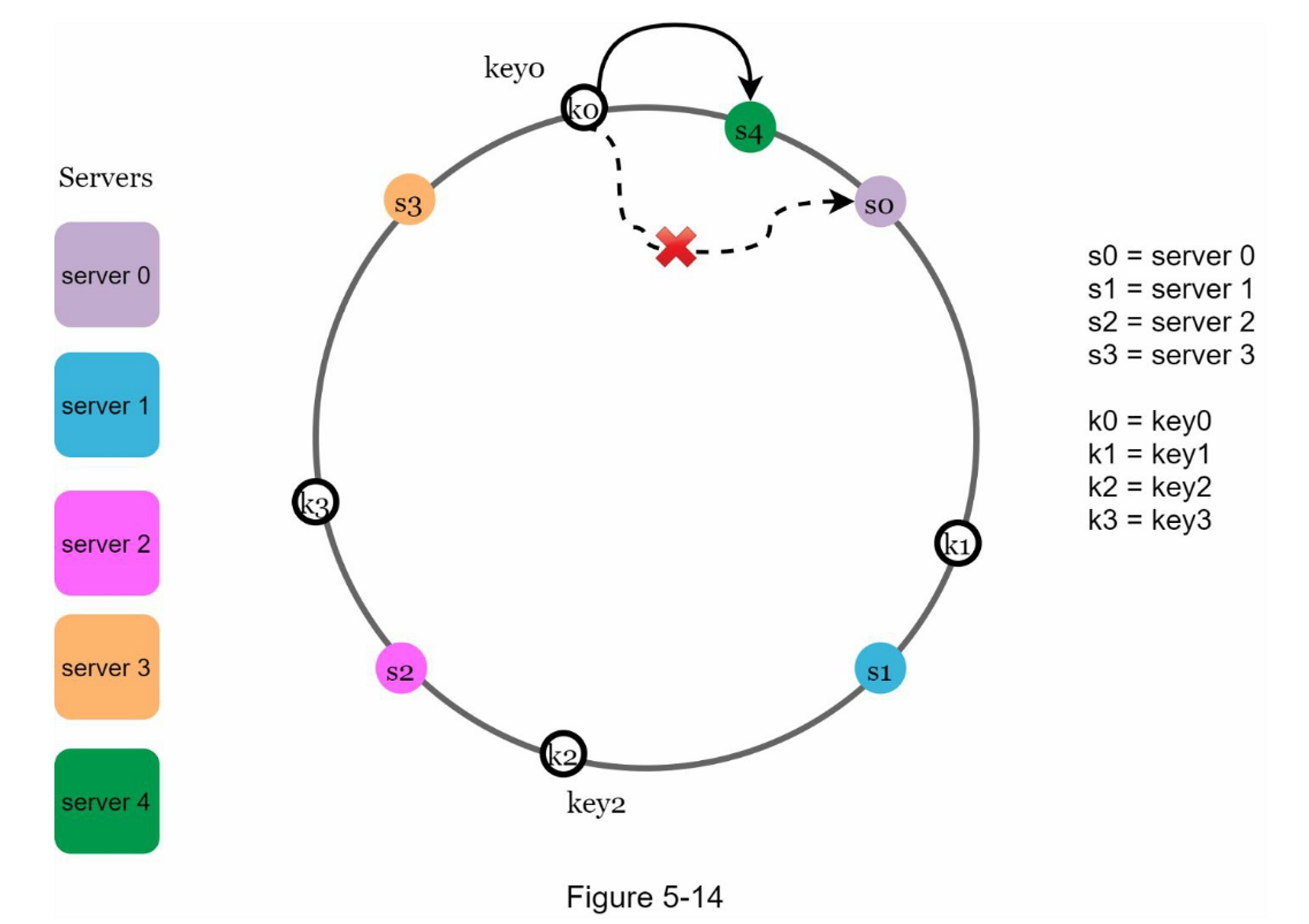
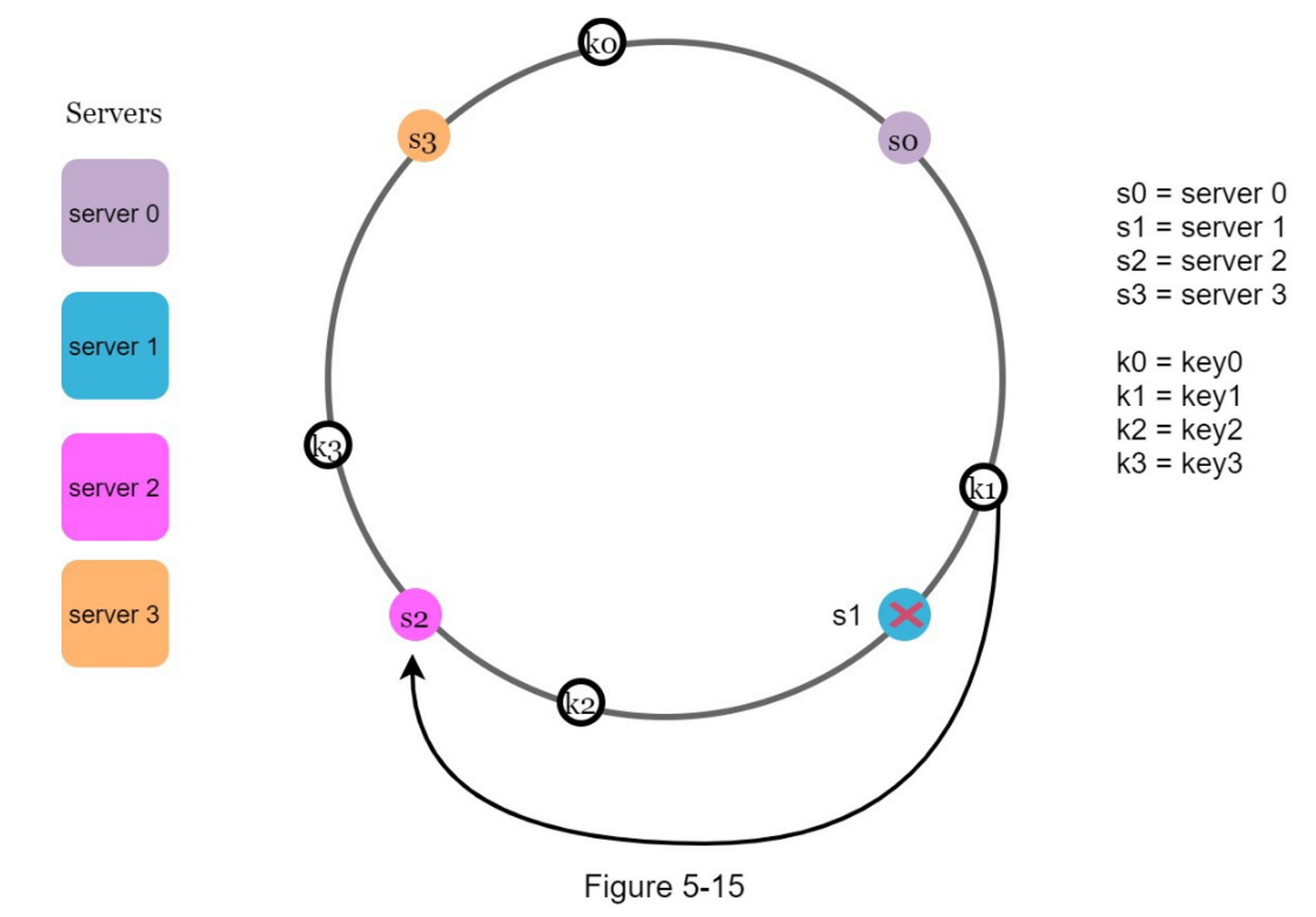
如图 5-15 所示,当一个服务器(s1)被移除时,受影响的范围从 s1(被移除的节点)开始并沿环逆时针方向移动,直到找到一个服务器(s0)。 因此,位于 s0 和 s1 之间的密钥必须重新分配给 s2。
总结
在这一章中,我们深入讨论了一致性哈希,包括为什么需要它以及它是如何工作的。
一致性哈希的好处包括:
- 当服务器被添加或删除时,很小一部分的键被重新分配。
- 容易水平扩展,因为数据分布更加均匀。
- 缓解热点健问题。 对特定分片的过度访问可能会导致服务器过载。 想象一下 Katy Perry、Justin Bieber 和 Lady Gaga 的数据最终都在同一个分片上。 一致性哈希通过更均匀地分配数据来缓解这个问题。
一致性哈希广泛用于现实世界的系统,包括一些著名的系统:
- 亚马逊 Dynamo 数据库的分区组件 [3]
- Apache Cassandra 中跨集群的数据分区 [4]
- Discord 聊天应用 [5]
- Akamai 内容分发网络 [6]
- Maglev 网络负载均衡器 [7]
恭喜你走到了这一步!现在给自己一个鼓励,干得漂亮!
参考资料
[1] Consistent hashing: https://en.wikipedia.org/wiki/Consistent_hashing
[2] Consistent Hashing:
https://tom-e-white.com/2007/11/consistent-hashing.html
[3] Dynamo: Amazon’s Highly Available Key-value Store:
https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
[4] Cassandra - A Decentralized Structured Storage System:
http://www.cs.cornell.edu/Projects/ladis2009/papers/Lakshman-ladis2009.PDF
[5] How Discord Scaled Elixir to 5,000,000 Concurrent Users:
https://blog.discord.com/scaling-elixir-f9b8e1e7c29b
[6] CS168: The Modern Algorithmic Toolbox Lecture #1: Introduction and Consistent Hashing:
http://theory.stanford.edu/~tim/s16/l/l1.pdf
[7] Maglev: A Fast and Reliable Software Network Load Balancer:
https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/44824.pdf
第06章:key-value 存储设计
键值存储,也称为键值数据库,是一种非关系数据库。每个唯一标识符都存储为一个键及其关联值,这种数据配对称为“键值”对。
在键值对中,键必须是唯一的,通过键可以访问与键关联的值。键可以是纯文本或散列值。出于性能原因,短键效果更好。键是什么样子的?
- 纯文本键:“last_logged_in_at”
- 哈希键:253DDEC4
键值对中的值可以是字符串、列表、对象等。在键值存储中,值通常被视为不透明的对象,如Amazon dynamo [1], Memcached [2], Redis [3], 等。
下面是一个键值存储中的数据片段:
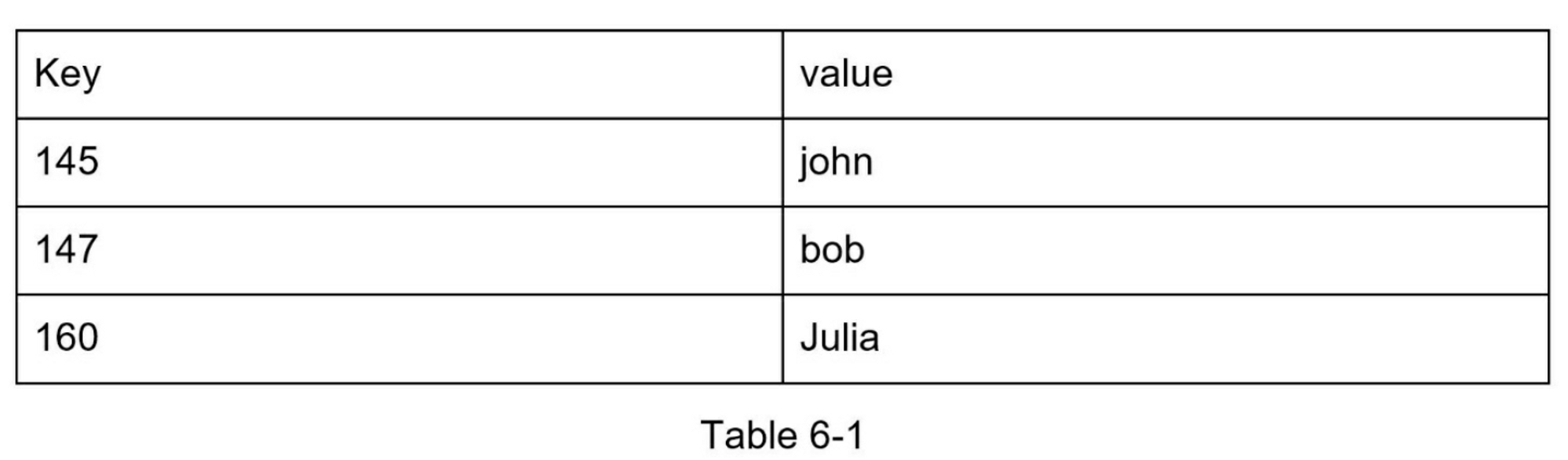
在本章中,你需要设计一个支持以下操作的键值存储:
put(key, value)// 插入与“key”关联的“value”get(key)// 获取与“key”关联的“value”
理解问题并确定设计范围
这里没有完美的设计。每种设计都在读取、写入和内存使用方面取得了特定的权衡。必须在一致性和可用性之间做出另一个权衡。
在本章中,我们设计了一个包含以下特征的键值存储:
- 键值对的大小很小:不到 10 KB。
- 有能力存储大数据。
- 高可用性:系统响应迅速,即使在出现故障时也是如此。
- 高可扩展性:系统可以扩展以支持大数据集。
- 自动缩放:服务器的添加/删除应该根据流量自动进行。
- 可调节的一致性。
- 低延迟。
单一服务器的键值存储
开发一个驻扎在单个服务器中的键值存储很容易,一种直观的方法是将键值对存储在哈希表中,该哈希表将所有内容保存在内存中。
为了在一个服务器中容纳更多的数据,可以做两个优化措施:
- 数据压缩
- 只在内存中存储经常使用的数据,其余的存储在磁盘上
即使进行了这些优化,单个服务器也可以很快达到其容量。需要分布式键值存储来支持大数据
分布式键值存储
分布式键值存储也称为分布式哈希表,它将键值对分布在许多服务器上。在设计分布式系统时,了解 CAP(C一致性、A可用性、P分区容错性)定理很重要。
CAP 定理指出,分布式系统不可能同时提供以下三种保证中的两种以上:一致性、可用性和分区容错性。让我们熟悉一些定义。
一致性:一致性意味着所有客户端无论连接到哪个节点,都在同一时间看到相同的数据。
可用性:可用性意味着即使某些节点已关闭,任何请求数据的客户端都会得到响应。
分区容忍度:分区表示两个节点之间的通信中断,分区容错意味着系统在网络分区的情况下继续运行。
CAP 定理指出,必须牺牲三个属性之一来支持 3 个属性中的 2 个,如图 6-1 所示:
如今,键值存储根据它们支持的两个 CAP 特性进行分类:
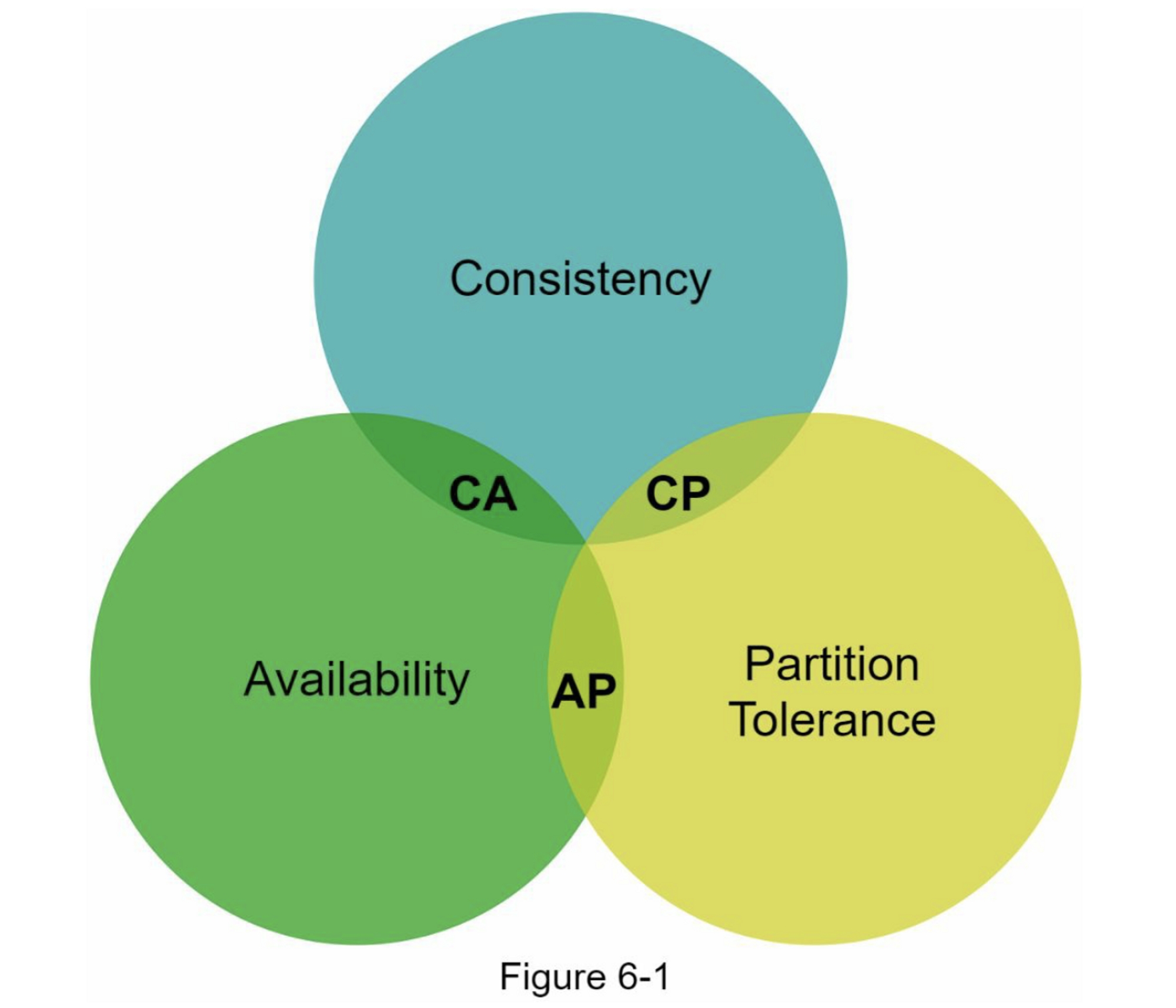
CP(一致性和分区容错)系统:CP 键值存储在牺牲可用性的同时支持一致性和分区容错。
AP(可用性和分区容错)系统:AP 键值存储支持可用性和分区容错,同时牺牲一致性
CA(一致性和可用性)系统:CA 键值存储支持一致性和可用性,同时牺牲分区容错性。由于网络故障是不可避免的,分布式系统必须容忍网络分区。因此,CA 系统不能存在于现实世界的应用程序中。
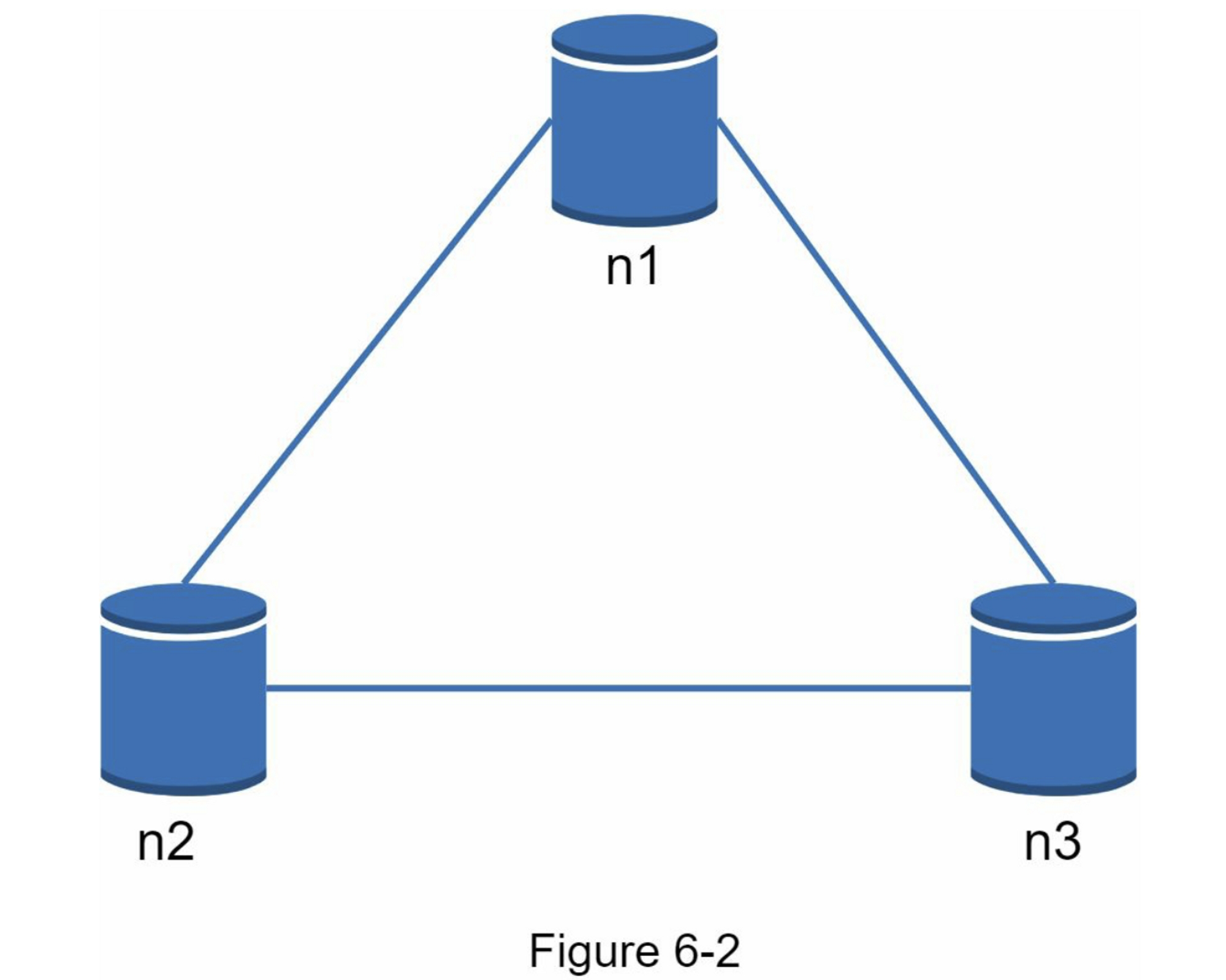
您在上面阅读的内容主要是定义部分。为了更容易理解,让我们看一些具体的例子。在分布式系统中,数据通常会被复制多次。假设数据被复制到三个副本节点n1、n2和n3上,如图6-2所示。
-
理想情况
在理想世界中,网络分区永远不会发生。写入 n1 的数据会自动复制到 n2 和 n3。实现了一致性和可用性。
-
真实世界的分布式系统
在分布式系统中,分区是不可避免的,当出现分区时,我们必须在一致性和可用性之间做出选择。图6-3中,n3宕机,无法与n1、n2通信。如果客户端将数据写入 n1 或 n2,则数据无法传播到 n3。如果数据写入 n3 但尚未传播到 n1 和 n2,则 n1 和 n2 将具有陈旧数据。
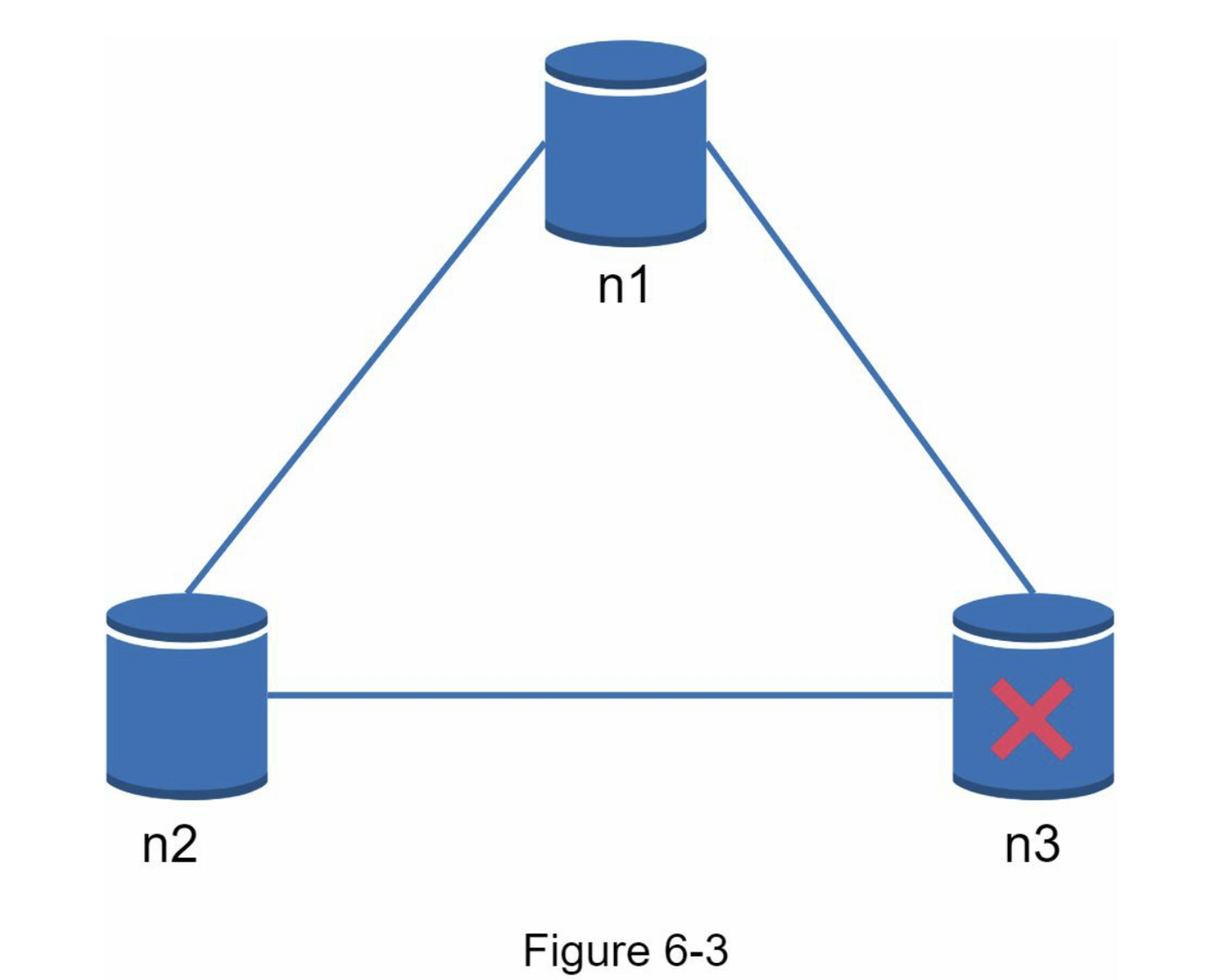
如果我们选择一致性大于可用性(CP系统),我们必须阻止所有对n1和n2的写操作,以避免这三个服务器之间的数据不一致,这使得系统不可用。银行系统通常有极高的一致性要求。例如,对于银行系统来说,显示最新的余额信息是至关重要的。如果由于网络分区而发生不一致,在不一致问题解决之前,银行系统会返回一个错误。
然而,如果我们选择可用性大于一致性(AP系统),系统就会一直接受读取,即使它可能返回陈旧的数据。对于写,n1和n2将继续接受写,当网络分区解决后,数据将被同步到n3。
选择正确的 CAP 以确保适合你的用例是构建分布式键值存储的重要一步。你可以与面试官讨论这个问题并相应地设计系统
系统组件
在本节中,我们将讨论以下用于构建键值存储的核心组件和技术:
- 数据分区
- 数据复制
- 一致性
- 不一致解决方案
- 故障处理
- 系统架构图
- 写入路径
- 读取路径
下面的内容主要基于三个流行的键值存储系统:Dynamo [4]、Cassandra [5] 和 BigTable [6]。
数据分区
对于大型应用程序,将完整的数据集放在单个服务器中是不可行的。实现这一点的最简单方法是将数据拆分为更小的分区并将它们存储在多个服务器中。分区数据时有两个挑战:
- 跨多个服务器平均分配数据。
- 当节点被添加或删除时,尽量减少数据移动。
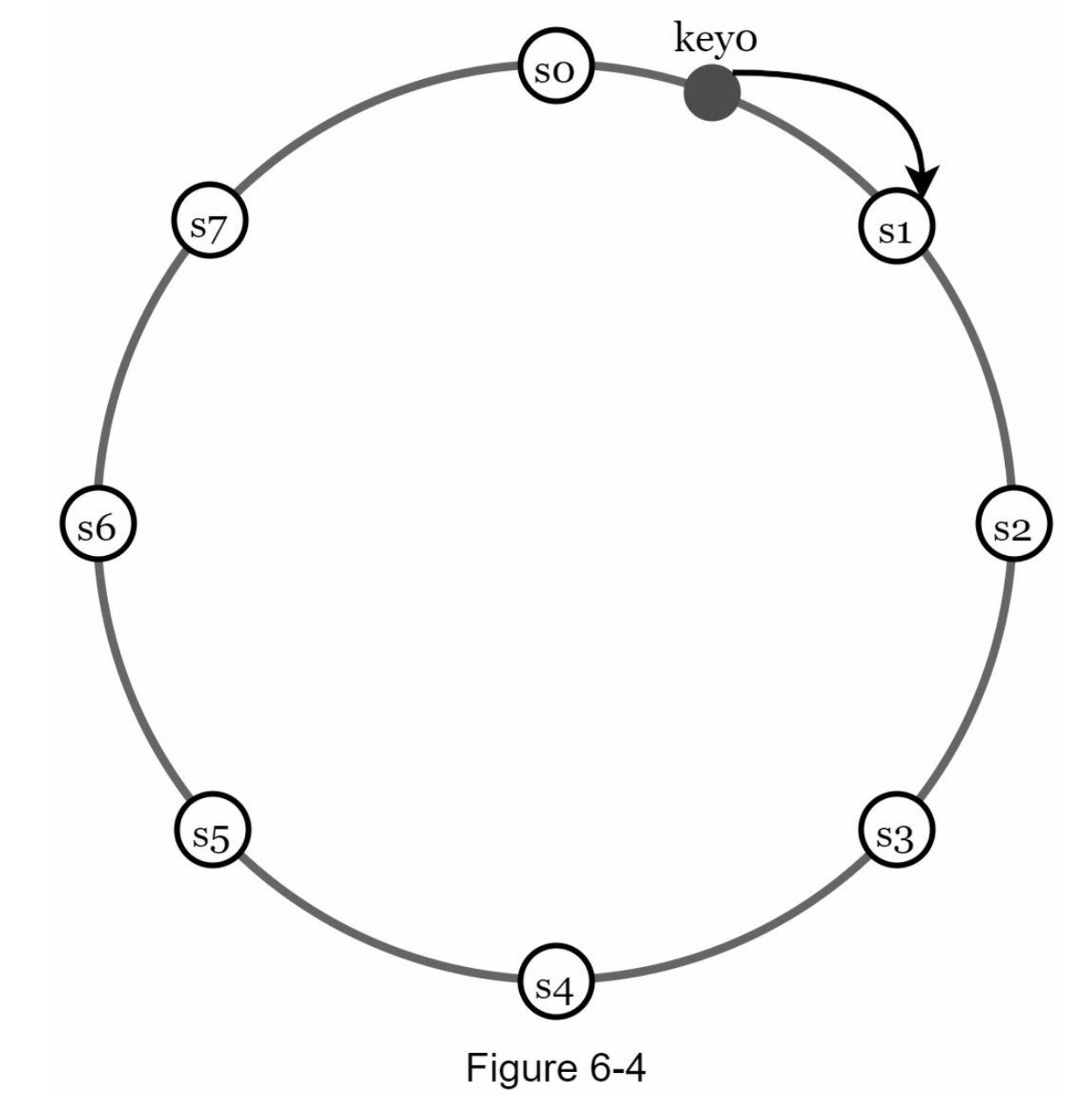
第 5 章中讨论的一致性哈希是解决这些问题的一种很好的技术。让我们重新审视一致性哈希在高层次上的工作原理。
-
首先,服务器被放置在哈希环上。在图 6-4 中,8 个服务器,分别用 s0、s1、...、s7 表示,放在哈希环上。
-
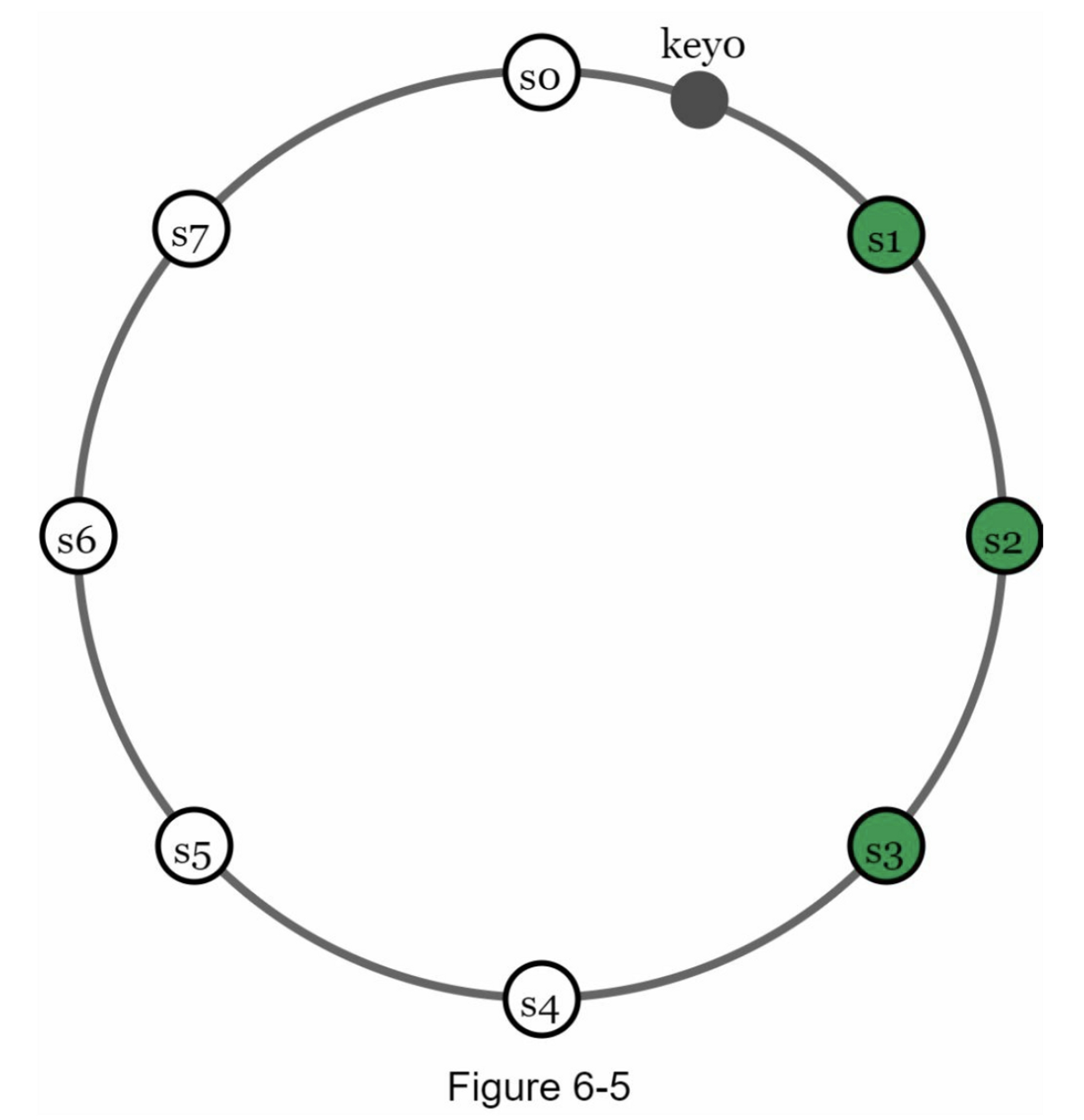
接下来,将一个键散列到同一个环上,并将其存储在顺时针方向移动时遇到的第一个服务器上。例如,key0 使用此逻辑存储在 s1 中。
使用一致性哈希对数据进行分区有以下优点:
- 自动缩放:可以根据负载自动添加和删除服务器
- 异构性:服务器的虚拟节点数与服务器容量成正比。例如,容量越大的服务器分配的虚拟节点越多。
数据复制
为了实现高可用性和可靠性,必须在 N 个服务器上异步复制数据,其中 N 是一个可配置参数。这N台服务器的选择逻辑如下:将key映射到哈希环上的某个位置后,从该位置顺时针走,选择环上的前N台服务器存储数据副本。在图 6-5(N = 3)中,key0 被复制到 s1、s2 和 s3。
对于虚拟节点,环上的前 N 个节点可能由少于 N 个物理服务器拥有。为避免此问题,我们在执行顺时针行走逻辑时仅选择唯一的服务器。
由于停电、网络问题、自然灾害等原因,同一数据中心内的节点经常同时发生故障。为了更好的可靠性,副本被放置在不同的数据中心,数据中心之间通过高速网络连接。
一致性
由于数据在多个节点进行复制,因此必须跨副本同步。Quorum 共识可以保证读写操作的一致性。 让我们先建立几个定义。
N = 副本数
W = 大小为 W 的规定写入。要将写入操作视为成功,必须从 W 个副本确认写入操作。
R = 大小为 R 的读取规定人数。为了使读取操作被认为是成功的,读取操作必须等待至少R个副本的响应。
考虑以下图 6-6 中所示的示例,其中 N = 3。
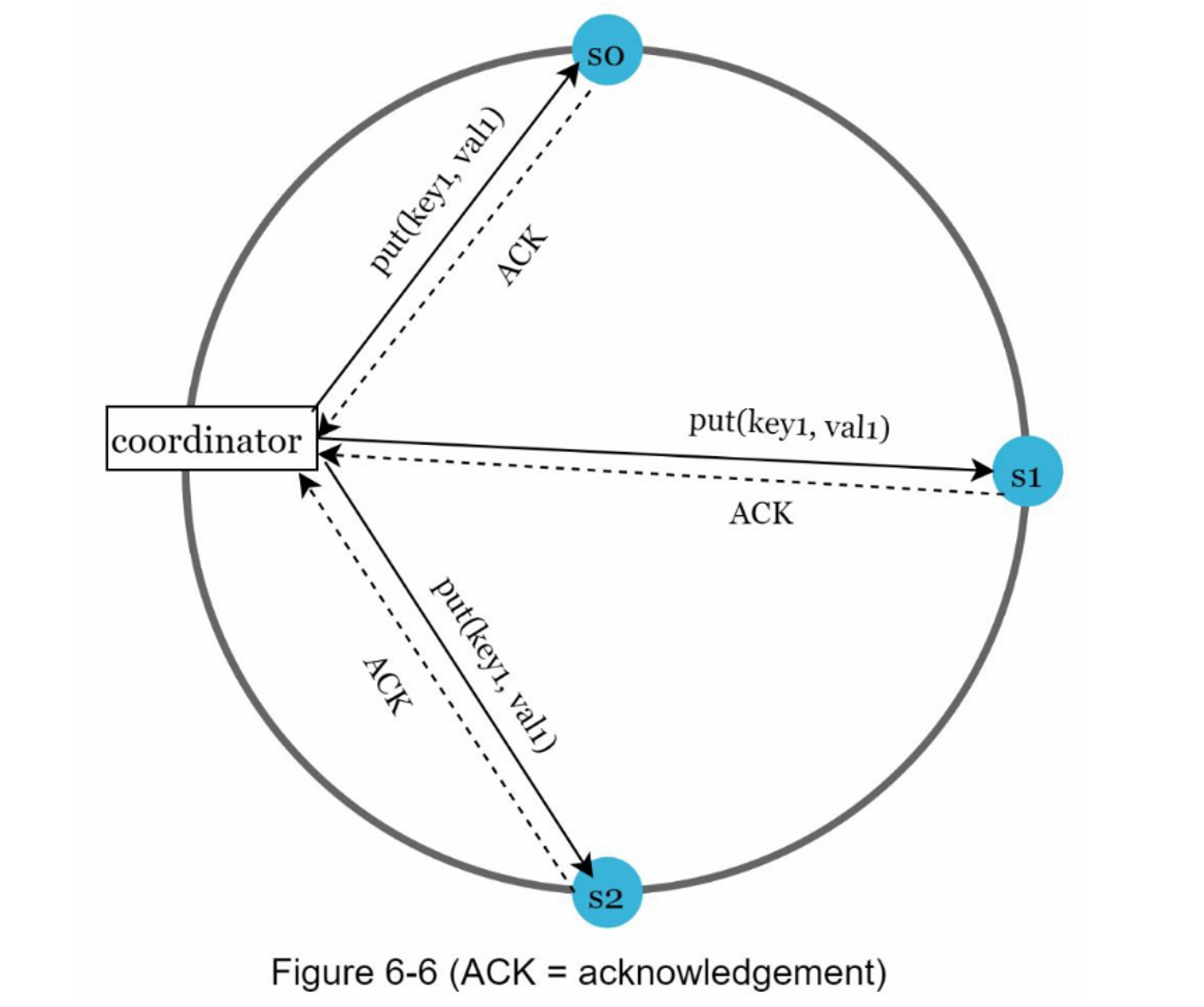
W = 1 并不意味着数据写在一台服务器上。 例如,对于图 6-6 中的配置,数据被复制到 s0、s1 和 s2。 W = 1 表示协调器必须至少收到一个确认才能认为写操作成功。例如,如果我们收到来自 s1 的确认,我们就不再需要等待来自 s0 和 s2 的确认。 协调器充当客户端和节点之间的代理。
W、R和N的配置是一个典型的延迟和一致性之间的权衡。如果W = 1 或R = 1,操作会很快返回,因为协调器只需要等待来自一个副本的响应。 如果 W 或 R > 1,系统提供更好的一致性; 但是,查询会变慢,因为协调器必须等待最慢副本的响应。
如果W+R>N,就能保证强一致性,因为至少有一个重叠的节点拥有最新的数据,以保证一致性。
如何配置N、W和R以适应我们的使用情况?
下面是一些可能的设置:
- 如果R=1,W=N,系统被优化为快速读取
- 如果W=1,R=N,系统被优化为快速写入
- 如果W+R>N,就可以保证强一致性(通常N=3,W=R=2)。
- 如果W+R<=N,则不能保证强一致性
根据要求,我们可以调整W、R、N的值,以达到理想的一致性水平。
一致性模型
一致性模型是设计键值存储时要考虑的另一个重要因素。 一致性模型定义了数据一致性的程度,并且存在多种可能的一致性模型:
- 强一致性:任何读操作都会返回一个与最新的写数据项的结果相对应的值。客户端永远不会看到过期的数据
- 弱一致性:后续的读操作可能看不到最新的值。
- 最终一致性:这是弱一致性的一种特殊形式。只要有足够的时间,所有的更新都会被传播,而且所有的副本都是一致的。
强一致性通常是通过强迫一个副本不接受新的读/写,直到每个副本都同意当前的写来实现的。这种方法对于高可用系统来说并不理想,因为它可能会阻塞新的操作。Dynamo和Cassandra采用最终一致性,这是我们推荐的键值存储的一致性模型。
从并发写入来看,最终一致性允许不一致的值进入系统,并迫使客户端读取这些值来进行调和。下一节将解释调和是如何与版本管理一起工作的。
不一致的解决方法:版本控制
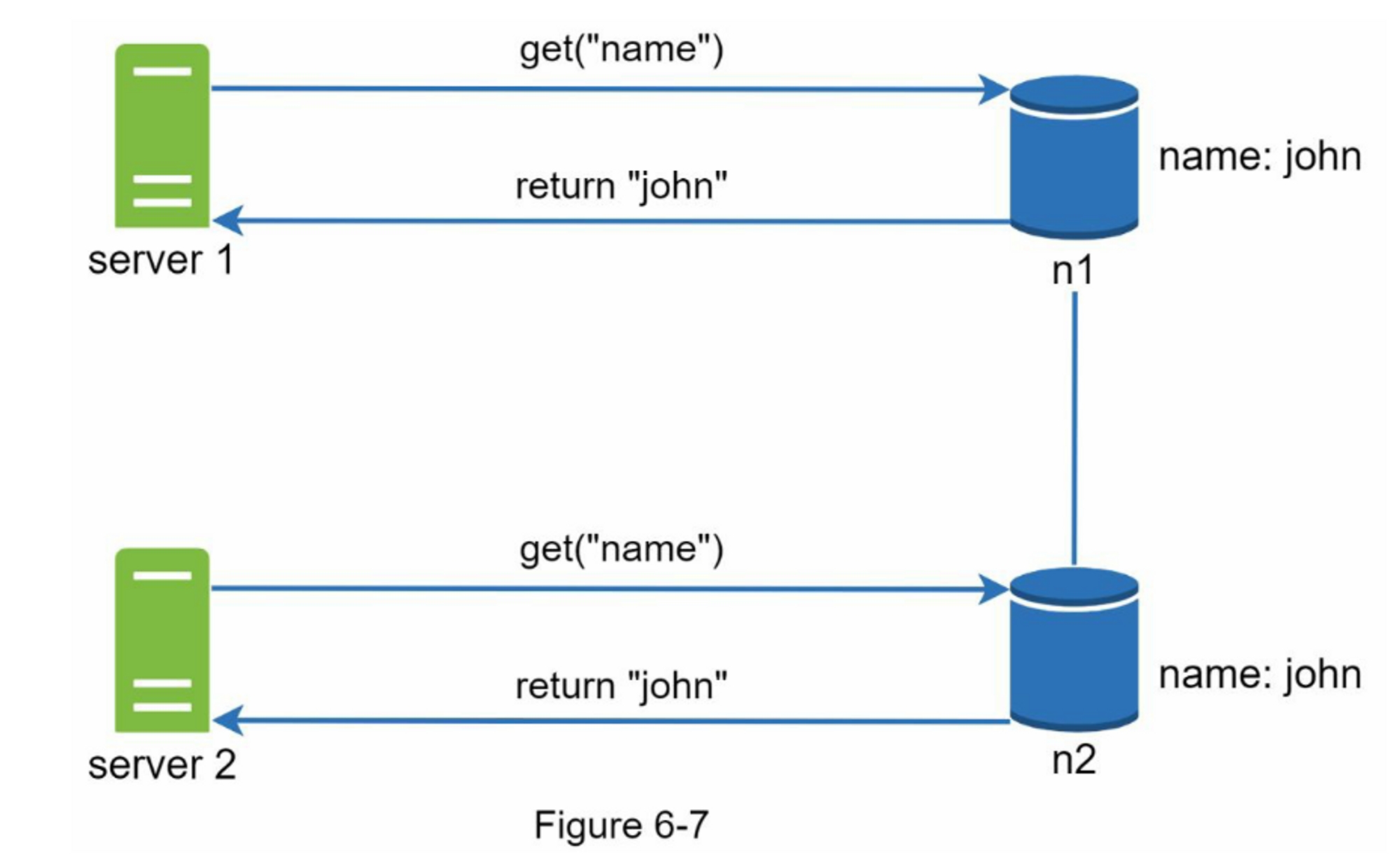
复制提供了高可用性,但会导致副本之间的不一致。 版本控制和矢量锁用于解决不一致问题。版本化意味着将每一次数据修改都视为一个新的不可更改的数据版本。在我们谈论版本控制之前,让我们用一个例子来解释不一致是如何发生的:
如图6-7所示,副本节点n1和n2的值相同。 让我们称这个值为原始值。 server 1 和 server 2 通过 get(“name”) 操作获得相同的值。
接下来,server 1 将名称更改为“johnSanFrancisco”,server 2 将名称更改为“johnNewYork”,如图 6-8 所示。 这两个更改是同时执行的。 现在,我们有冲突的值,称为版本 v1 和 v2。
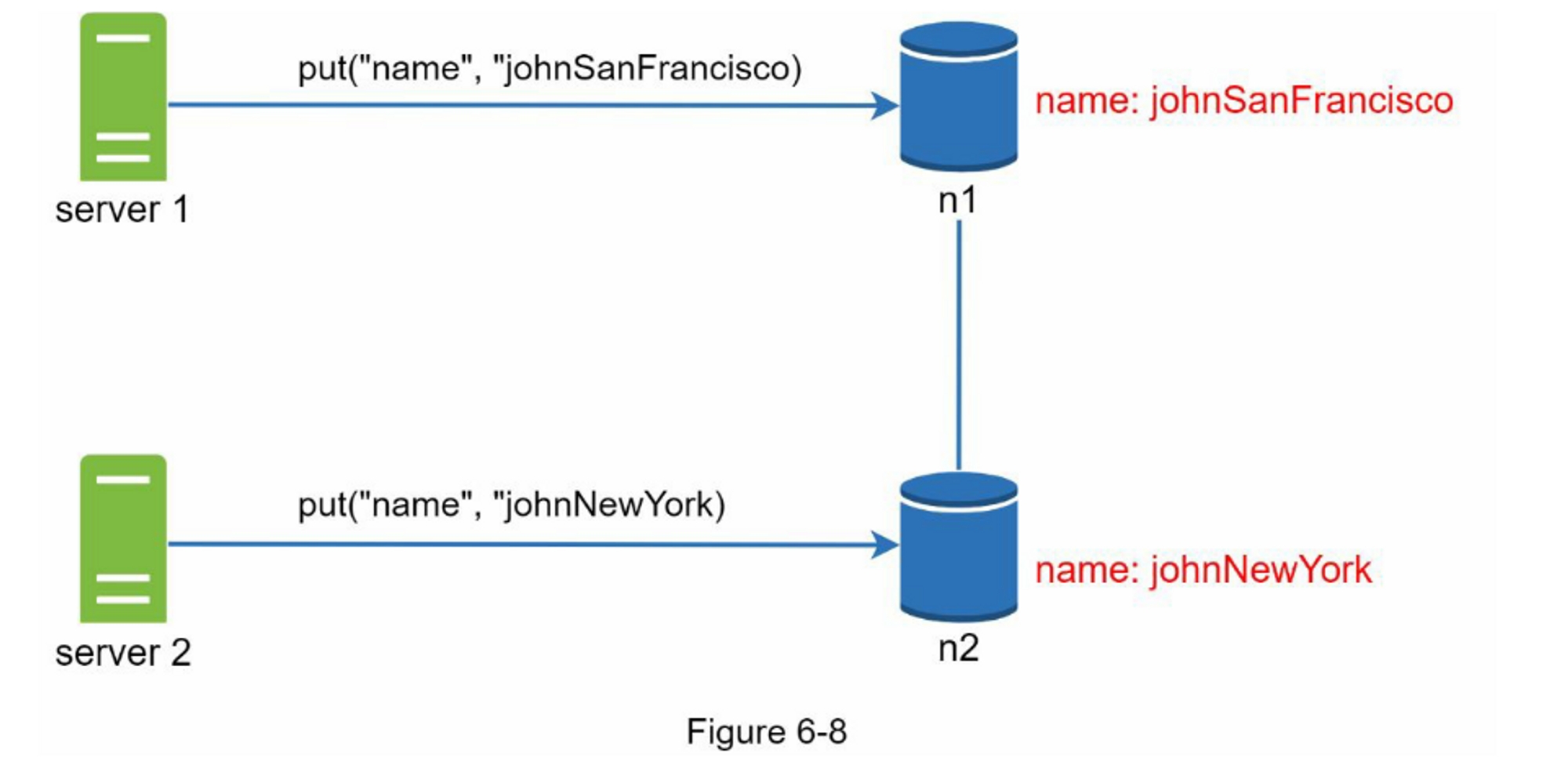
在此示例中,可以忽略原始值,因为修改是基于它的。 但是,没有明确的方法来解决最后两个版本的冲突。 为了解决这个问题,我们需要一个可以检测冲突并协调冲突的版本控制系统。
向量时钟是解决此问题的常用技术。
让我们来看看向量时钟是如何工作的。
向量时钟是与数据项关联的键值 [server, version] 对。 它可用于检查一个版本是否先于、成功或与其他版本冲突。
假设一个向量时钟用 D([S1, v1], [S2, v2], ..., [Sn, vn]) 表示,其中 D 是数据项,v1 是版本计数器,s1 是服务器数字等。如果数据项 D 被写入服务器 Si,系统必须执行以下任务之一:
- 如果 [Si, vi] 存在,则增加 vi。
- 否则,创建一个新的条目[Si, 1]。
上面的抽象逻辑用一个具体的例子来解释,如图6-9所示:
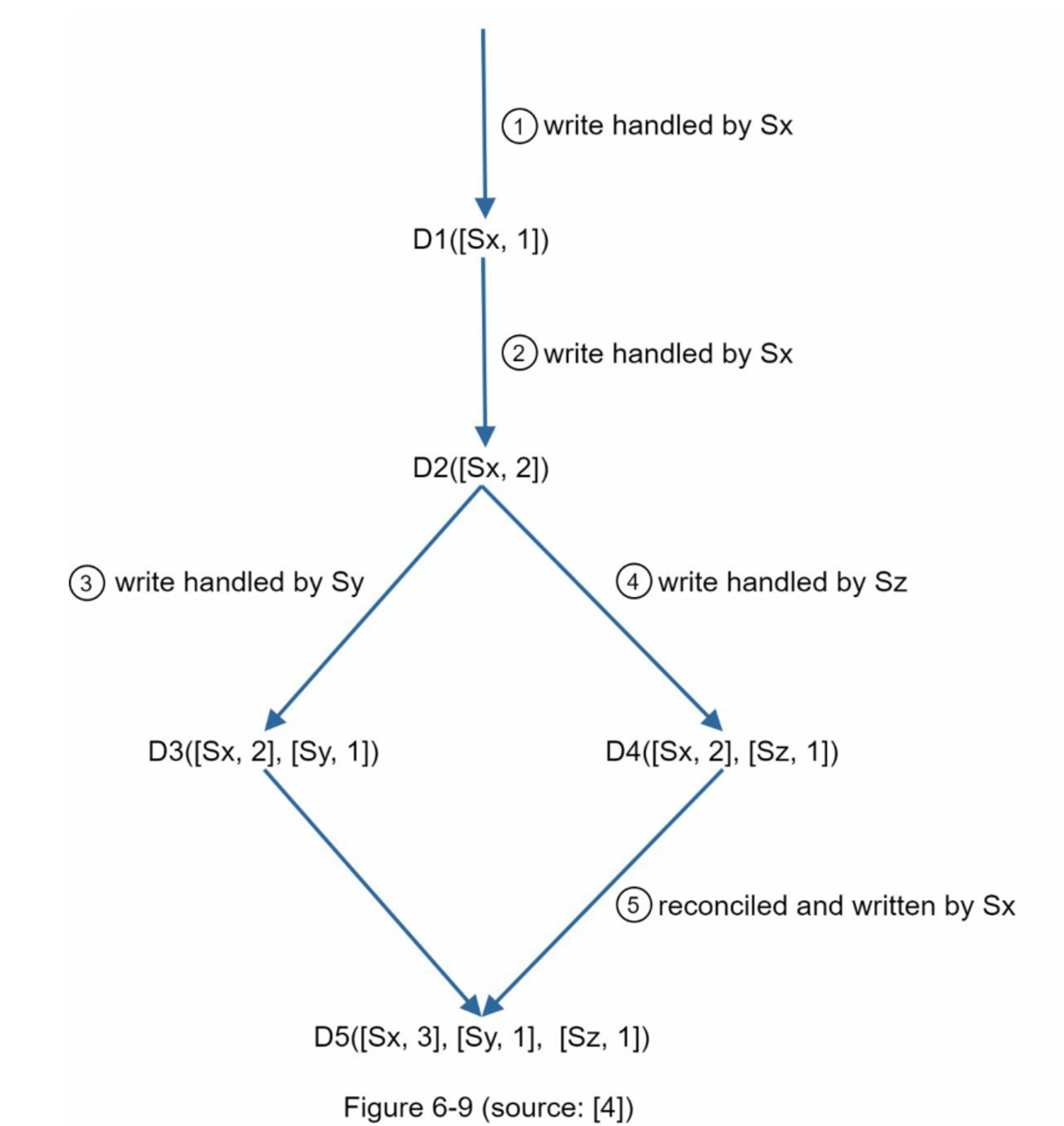
- 客户端向系统写入数据项 D1,写入由服务器 Sx 处理,服务器现在具有向量时钟 D1[(Sx, 1)]。
- 另一个客户端读取最新的 D1,将其更新为 D2,然后写回。 D2 继承自 D1,因此它会覆盖 D1。 假设写入由同一个服务器 Sx 处理,该服务器现在具有向量时钟 D2([Sx, 2])。
- 另一个客户端读取最新的 D2,将其更新为 D3,然后写回。 假设写操作由服务器 Sy 处理,它现在有向量时钟 D3([Sx, 2], [Sy, 1]))。
- 另一个客户端读取最新的 D2,将其更新为 D4,然后写回。 假设写入由服务器 Sz 处理,它现在有 D4([Sx, 2], [Sz, 1]))。
- 当另一个客户端读取D3和D4时,发现冲突,这是由于数据项D2被Sy和Sz同时修改造成的。 冲突由客户端解决,并将更新的数据发送到服务器。 假设写入由 Sx 处理,它现在有 D5([Sx, 3], [Sy, 1], [Sz, 1])。 我们将很快解释如何检测冲突。
使用向量时钟,如果Y的向量时钟中的每个参与者的版本计数器大于或等于版本X中的版本计数器,则很容易判断版本X是版本Y的祖先(即无冲突)。例如,向量时钟 D([s0, 1], [s1, 1])] 是 D([s0, 1], [s1, 2]) 的祖先。因此,未记录任何冲突。
类似地,如果 Y 的向量时钟中有任何参与者的计数器小于其在 X 中对应的计数器,则可以判断版本 X 是 Y 的兄弟版本(即存在冲突)。例如,以下两个 矢量时钟表示存在冲突:D([s0, 1], [s1,2]) 和 D([s0, 2], [s1, 1])
尽管向量时钟可以解决冲突,但也有两个明显的缺点。 首先,向量时钟增加了客户端的复杂性,因为它需要实现冲突解决逻辑。
其次,向量时钟中的 [server: version] 对可能会快速增长。为了解决这个问题,我们为长度设置了一个阈值,如果超过了限制,则删除最旧的对。这可能导致协调效率低下,因为后代关系无法准确确定。然而,基于Dynamo论文[4],亚马逊在生产中还没有遇到这个问题;因此,这可能是大多数公司可以接受的解决方案。
故障处理
与任何大规模的系统一样,故障不仅是不可避免的,而且是常见的。处理故障情况是非常重要的。在本节中,我们首先介绍检测故障的技术。然后,我们将介绍常见的故障解决策略。
-
故障检测
在分布式系统中,仅因为另一台服务器这样说就认为一台服务器已宕机是不够的。 通常,至少需要两个独立的信息源才能将服务器标记为宕机。
如图 6-10 所示,all-to-all 多播是一种直接的解决方案。 但是,当系统中有很多服务器时,这是低效的。
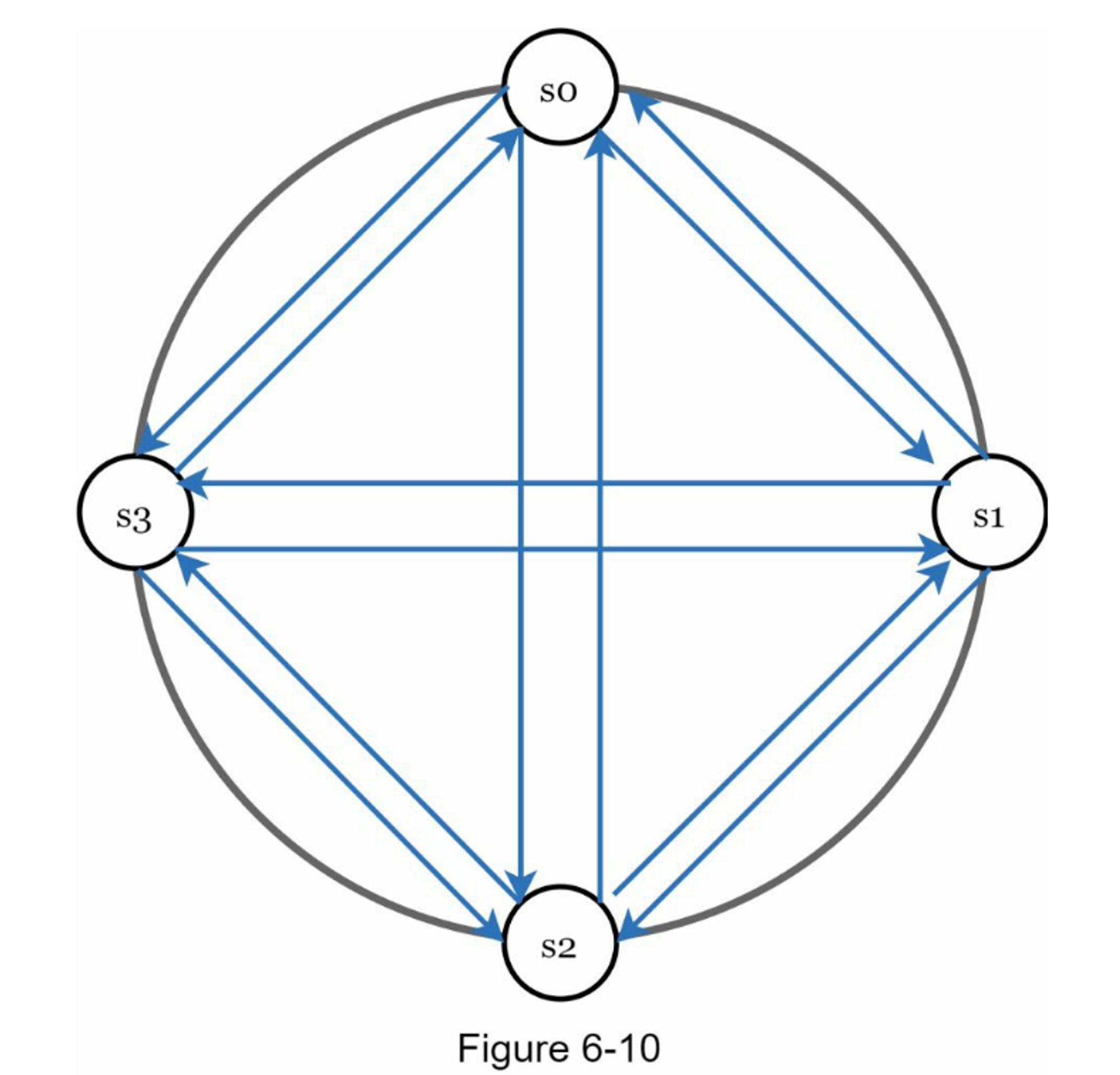
一个更好的解决方案是使用分散的故障检测方法,如
gossip协议。gossip协议的工作原理如下:- 每个节点维护一个节点成员列表,其中包含成员ID和心跳计数器。
- 每个节点定期增加它的心跳计数器
- 每个节点定期向一组随机节点发送心跳,然后再传播到另一组节点上
- 一旦节点收到心跳,成员名单就会更新到最新信息。
- 如果心跳没有增加超过预定的时间,该成员被认为是离线的。
如图6-11所示:
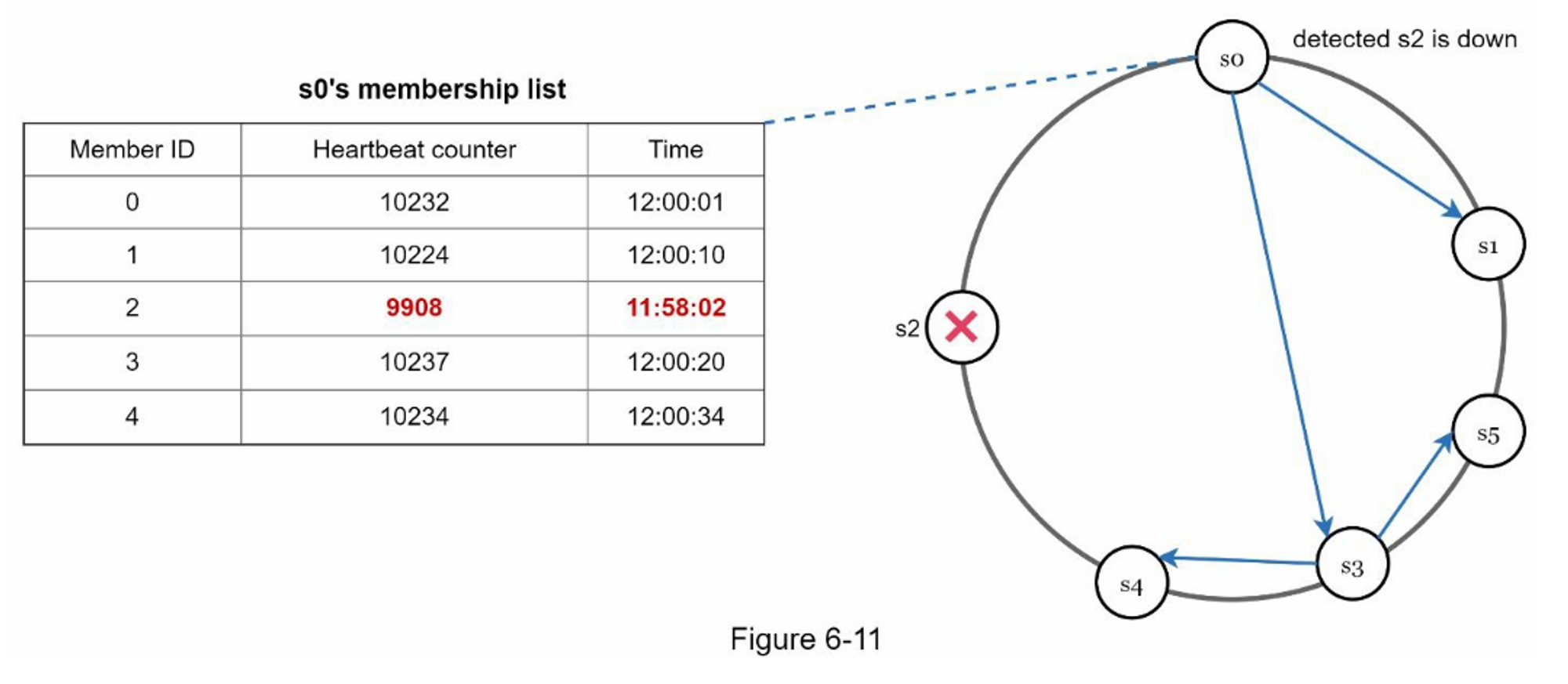
- 节点s0维护一个节点成员列表,如左侧所示
- 节点s0注意到节点s2(成员ID=2)的心跳计数器很长时间没有增加。
- 节点s0向一组随机节点发送包括s2的信息的心跳。一旦其他节点确认s2的心跳计数器长时间没有更新,节点s2就会被标记下来,这个信息会传播给其他节点。
-
处理暂时性故障
通过
gossip协议检测到故障后,系统需要部署一定的机制来确保可用性。 在严格的仲裁方法(quorum)中,读取和写入操作可以被阻止,如仲裁共识部分所示。一种称为“草率仲裁(
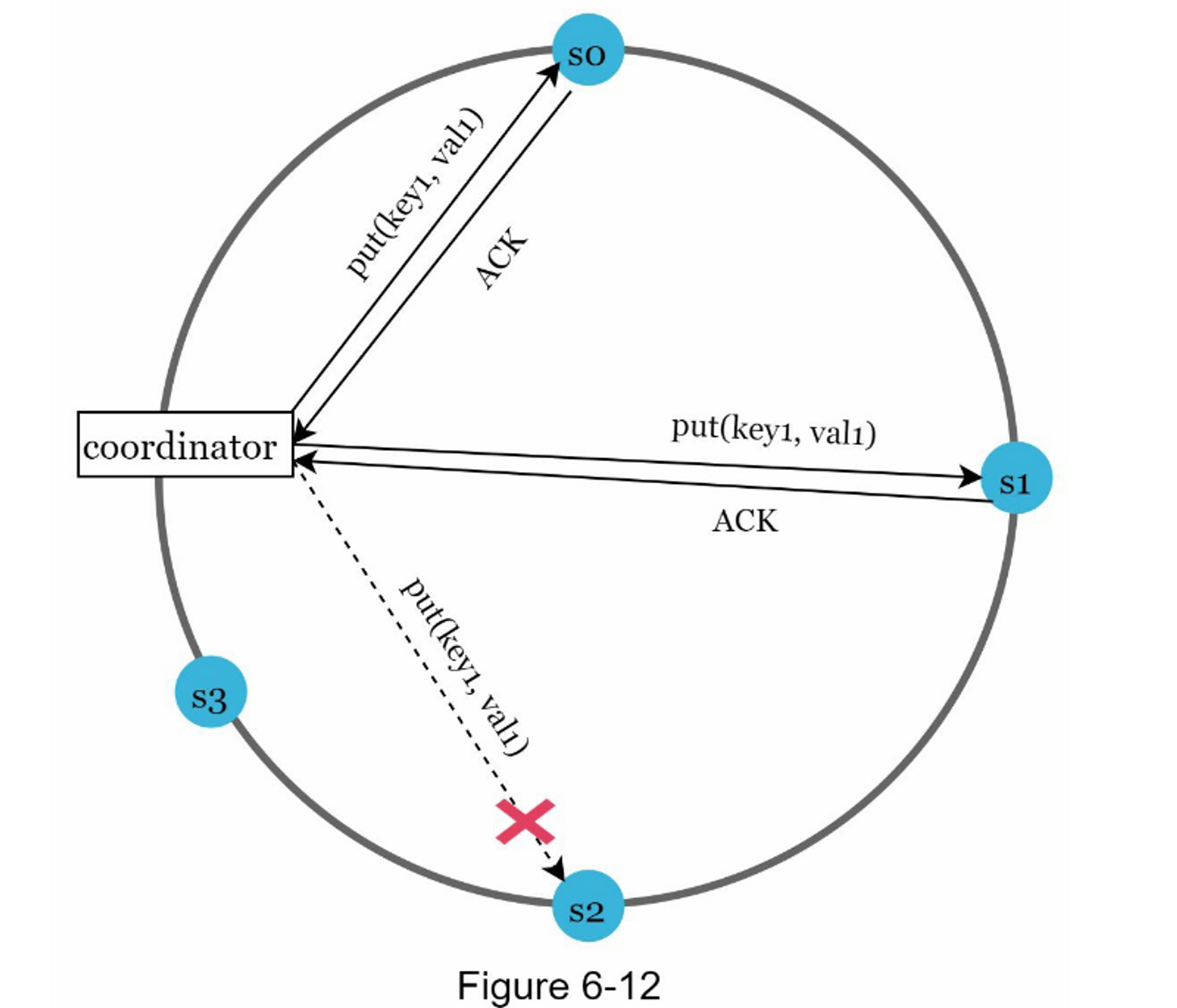
sloppy quorum)”[4] 的技术用于提高可用性。 系统不会强制执行法定人数要求,而是选择前 W 个健康的服务器进行写入,并选择前 R 个健康的服务器进行哈希环上的读取。 离线服务器将被忽略。如果由于网络或服务器故障导致服务器不可用,将由另一台服务器临时处理请求,当宕机服务器启动时,更改将被推回以实现数据一致性。这个过程称为暗示切换(hinted handof)。由于图6-12中s2不可用,读写暂时交由s3处理,当 s2 重新上线时,s3 会将数据交还给 s2。
-
处理永久性故障
提示切换用于处理临时故障。 如果副本永久不可用怎么办?
为了处理这种情况,我们实施了一个反熵协议(anti-entropy protocol) 来保持副本同步。 反熵需要比较副本上的每条数据,并将每个副本更新为最新版本。
Merkle树用于检测不一致,并尽量减少传输的数据量。
引自维基百科 [7]:“哈希树或 Merkle 树是一棵树,其中每个非叶节点都标有其子节点的标签或值(如果是叶子)的哈希值。 哈希树允许对大型数据结构的内容进行高效和安全的验证”。
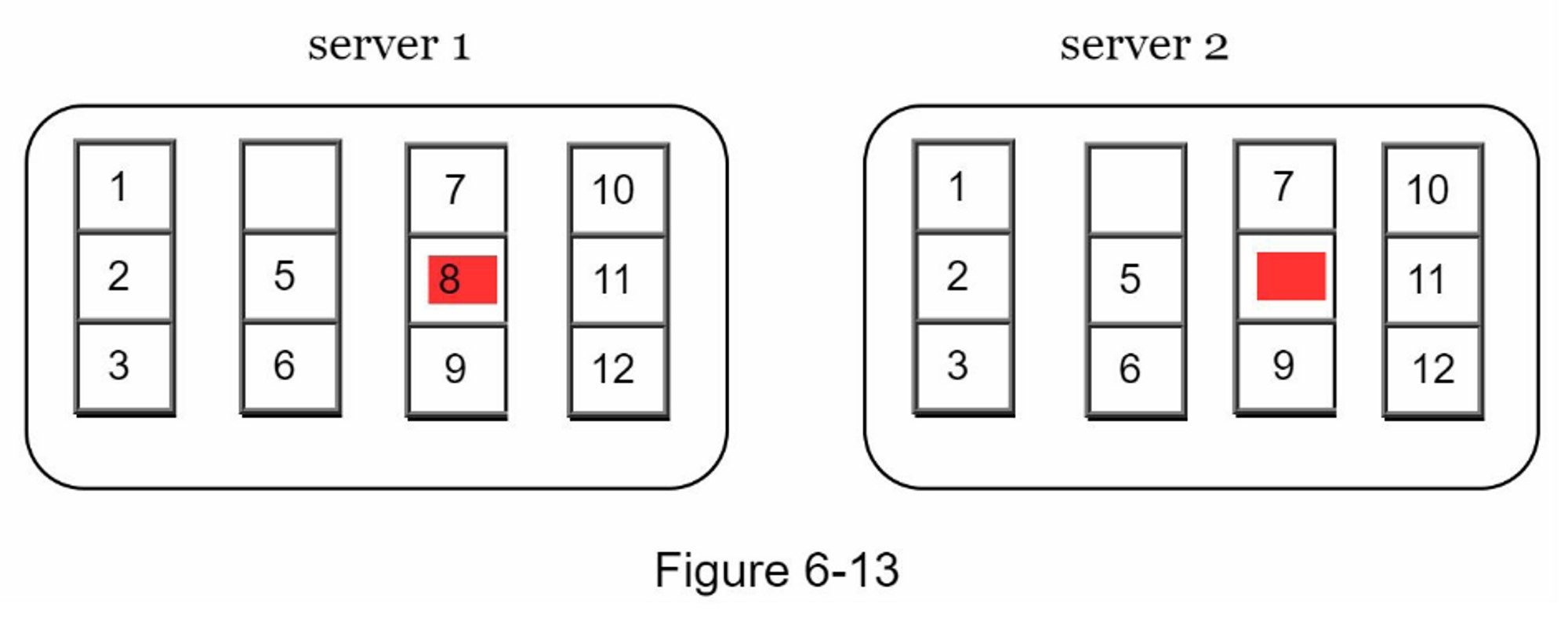
假设键空间是从 1 到 12,下面的步骤展示了如何构建 Merkle 树,突出显示的框表示不一致。
- 第1步:将密钥空间划分为桶(在我们的例子中为4个),如图6-13所示。 一个桶被用作根级节点,以保持树的有限深度
- 第2步:一旦创建了桶,使用统一的散列方法对桶中的每个密钥进行散列(图6-14)。
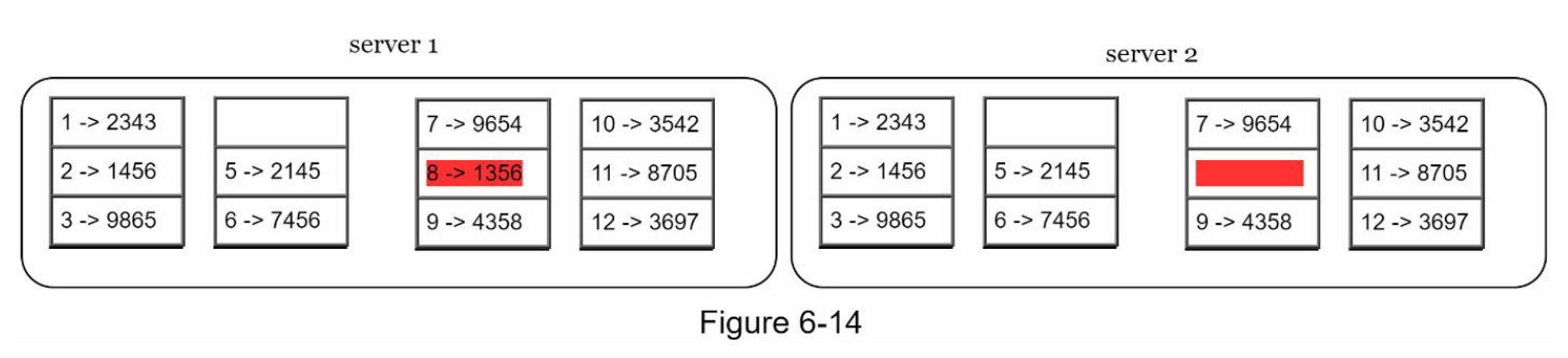
- 第3步:为每个桶创建一个哈希节点(图6-15)
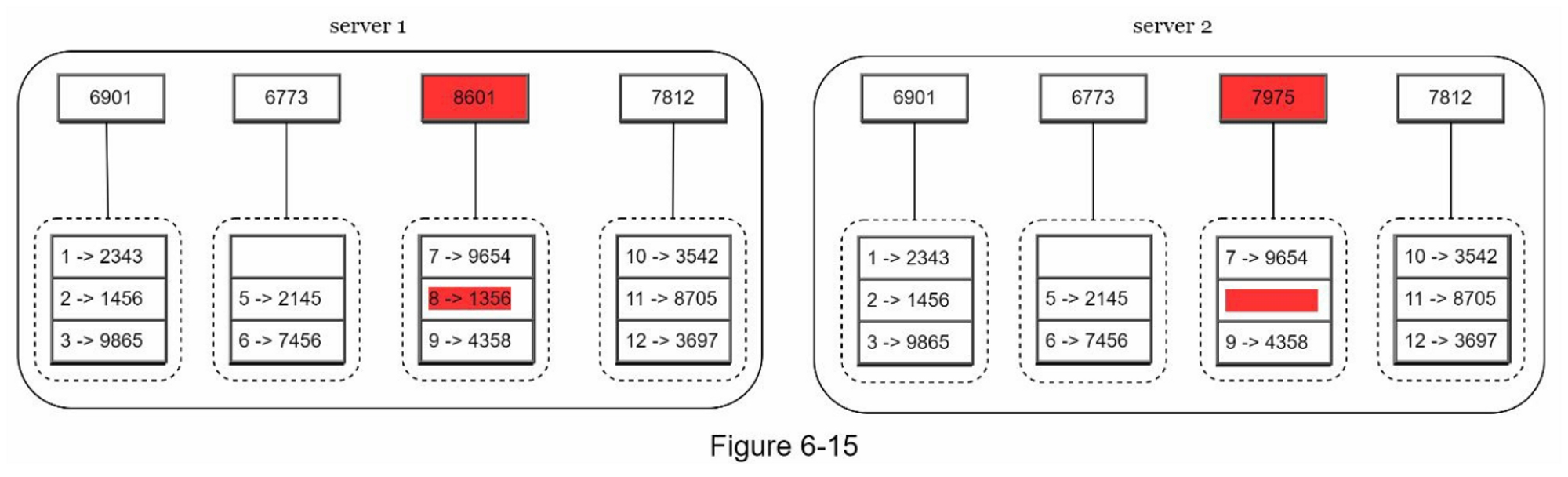
- 第4步:通过计算子代的哈希值,向上建立树,直到根(图6-16)。
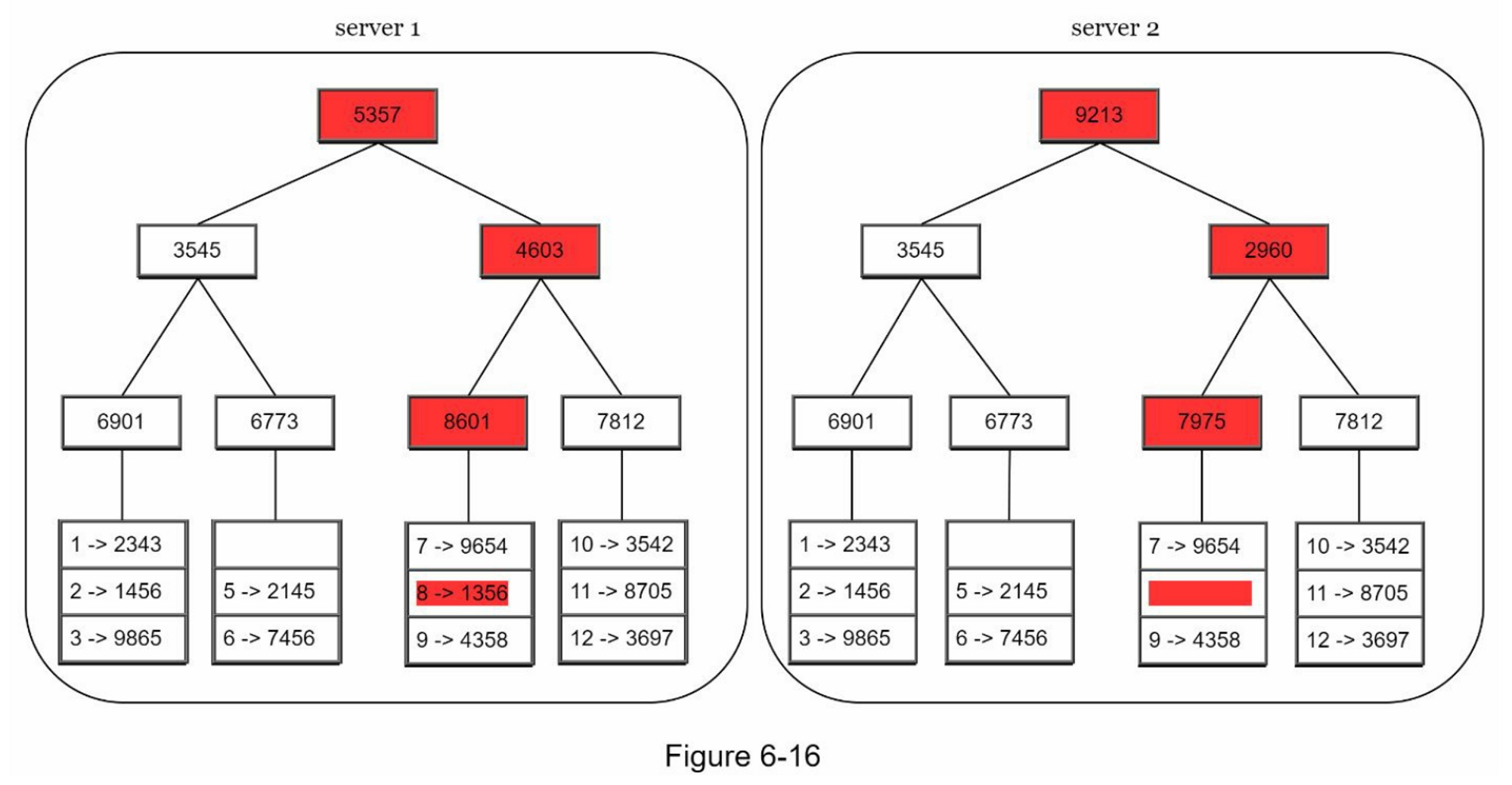
要比较两个Merkle树,首先要比较根哈希值。如果根哈希值匹配,则两个服务器有相同的数据。如果根哈希值不一致,那么就比较左边的子哈希值,然后是右边的子哈希值。你可以遍历该树,找到哪些桶没有被同步,并只同步这些桶。
使用Merkle树,需要同步的数据量与两个副本之间的差异成正比,而不是它们包含的数据量。在现实世界的系统中,桶的大小是相当大的。例如,一个可能的配置是每十亿个键有一百万个桶,所以每个桶只包含1000个键。
-
处理数据中心的中断故障
数据中心的中断可能是由于停电、网络中断、自然灾害等原因造成的。为了建立一个能够处理数据中心中断的系统,在多个数据中心之间复制数据是非常重要的。即使一个数据中心完全离线,用户仍然可以通过其他数据中心访问数据。
系统构架图
现在我们已经讨论了设计键值存储时的不同技术考虑,我们可以将注意力转移到架构图上,如图 6-17 所示。
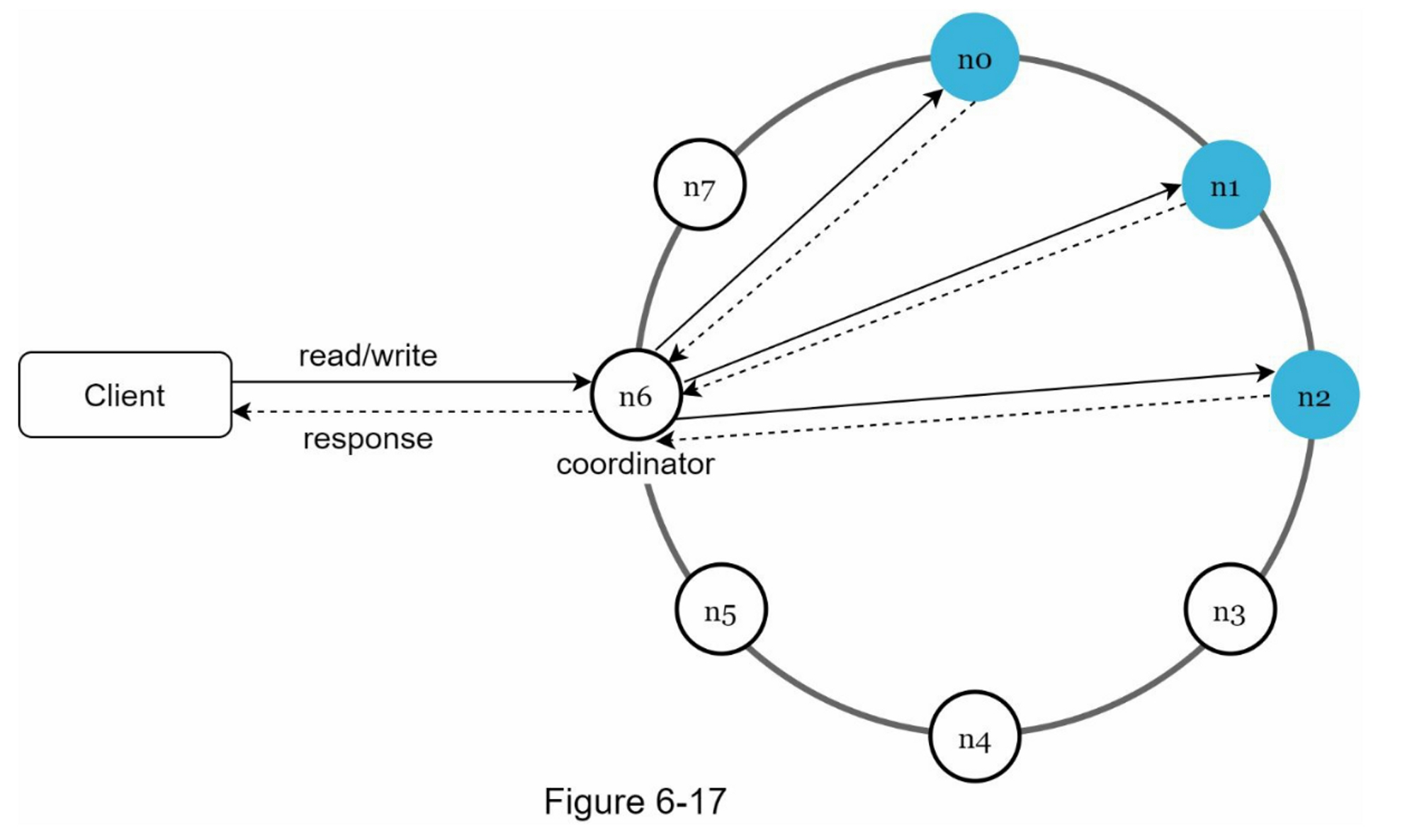
架构的主要特点列举如下:
- 客户端通过简单的API与键值存储通信:
get(key)和put(key, value)。 - 协调器是一个节点,在客户端和键值存储之间充当代理。
- 节点采用一致性hash的散列方式分布在一个环上。
- 该系统是完全去中心化的,所以添加和移动节点可以自动进行。
- 数据在多个节点上复制。
- 不存在单点故障,因为每个节点都有相同的职责。
由于设计是分散的,每个节点执行许多任务,如图6-18所示。
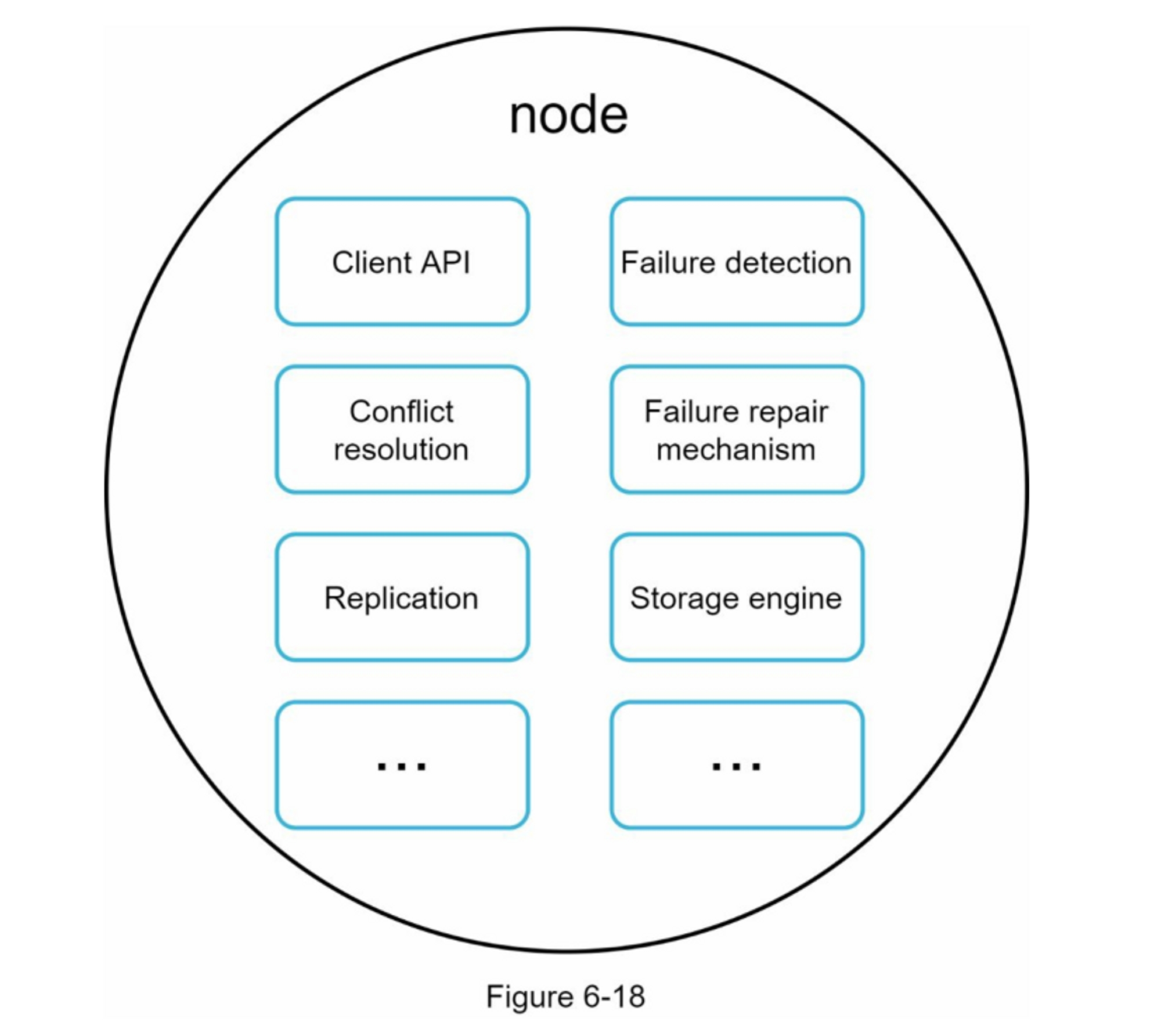
写入路径
图 6-19 解释了将写请求定向到特定节点后会发生什么。 请注意,建议的写/读路径设计主要基于 Cassandra [8] 的体系结构。
- 写入请求持久保存在提交日志文件中。
- 数据保存在内存缓存中。
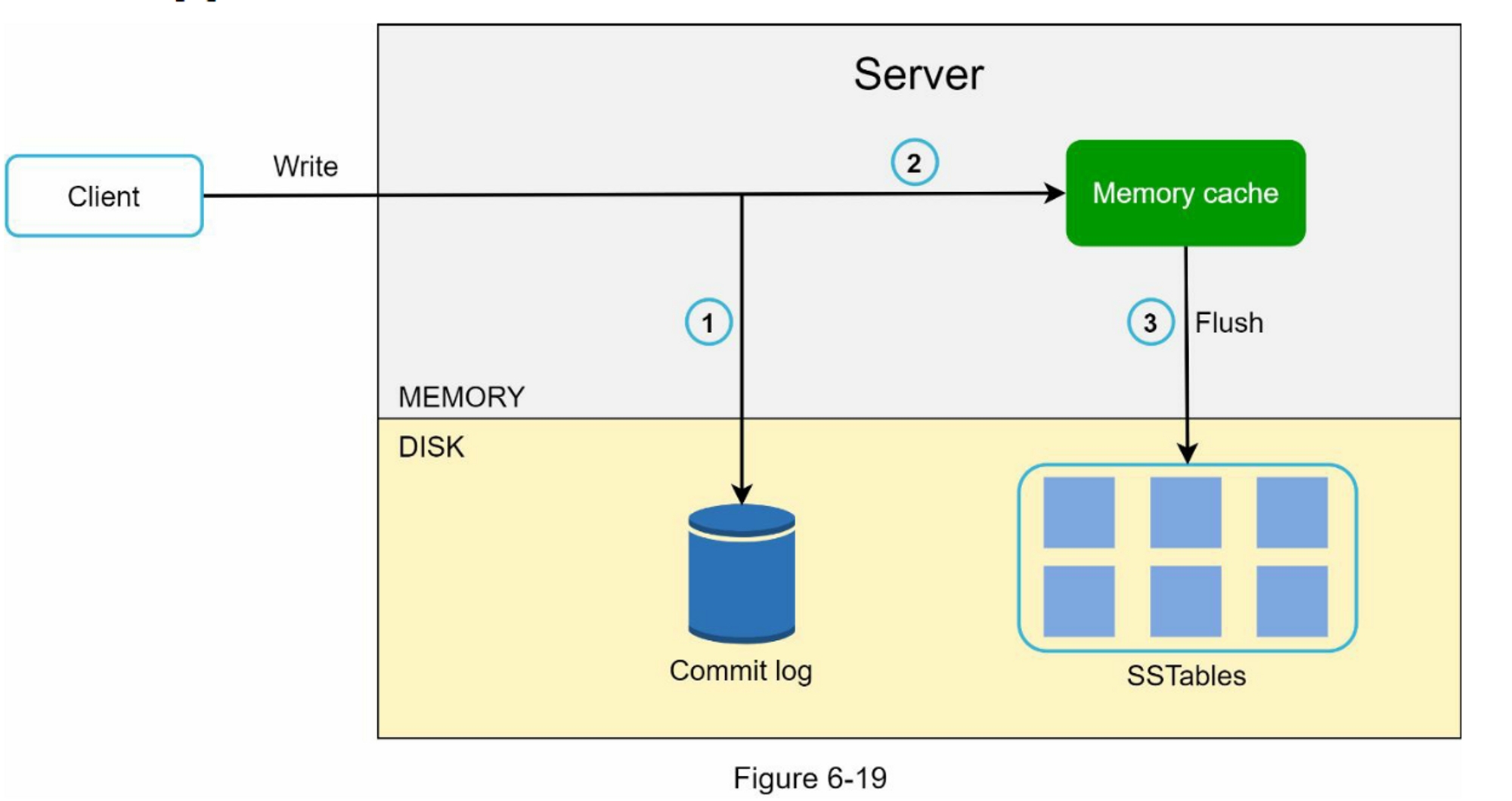
- 当内存缓存已满或达到预定义的阈值时,数据将刷新到磁盘上的 SSTable [9]。 注意:排序字符串表 (SSTable) 是 <key, value> 对的排序列表。 有兴趣进一步了解 SStable 的读者,请参阅参考资料 [9]。
读取路径
读取请求被引导到一个特定的节点后,它首先检查数据是否在内存缓存中。如果是,数据就会被返回给客户端,如图6-20所示。
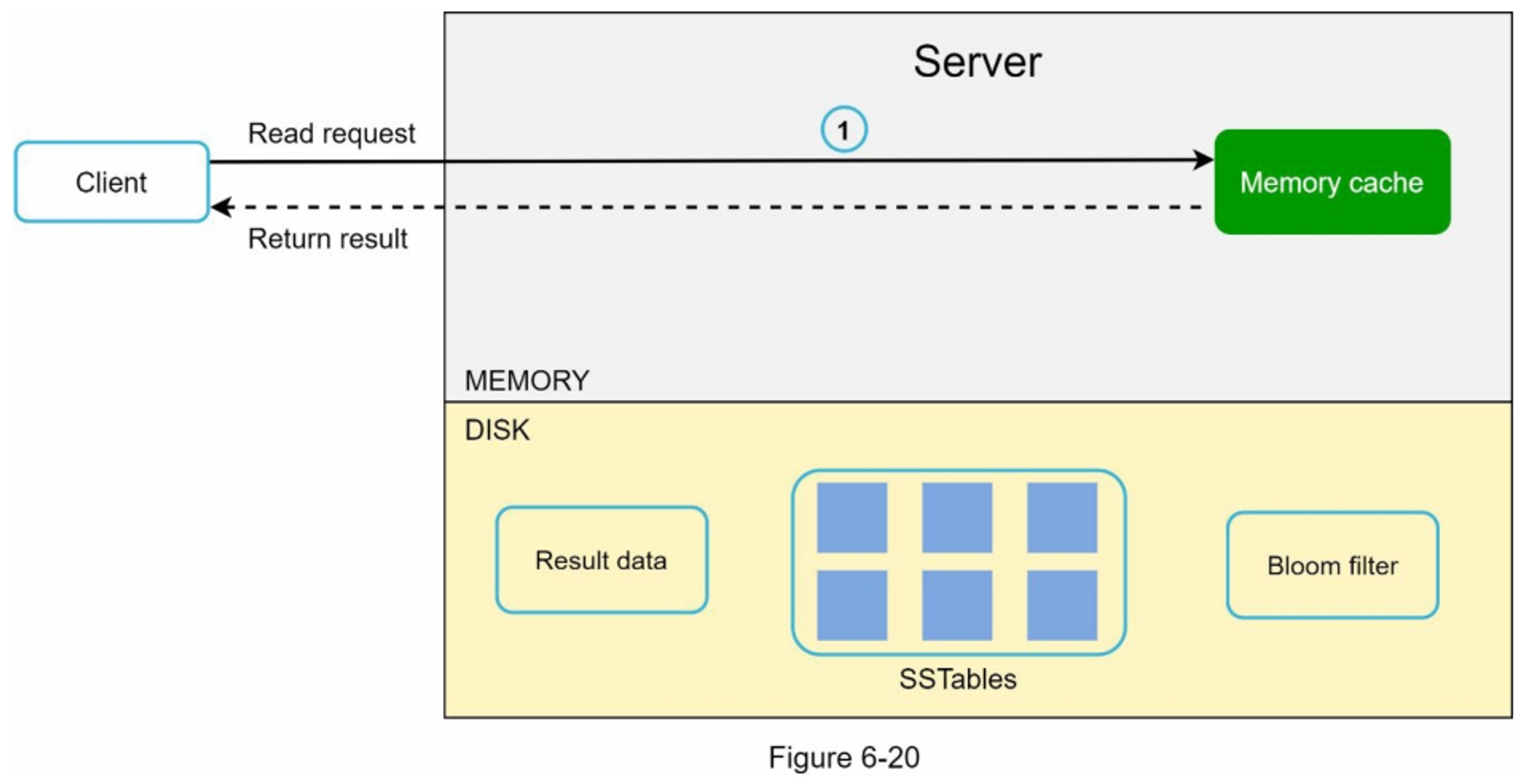
如果数据不在内存中,就会从磁盘中检索出来。我们需要一个有效的方法来找出哪个SSTable中包含了该键。布隆过滤器[10]通常被用来解决这个问题。
当数据不在内存中时,读取路径如图6-21所示。
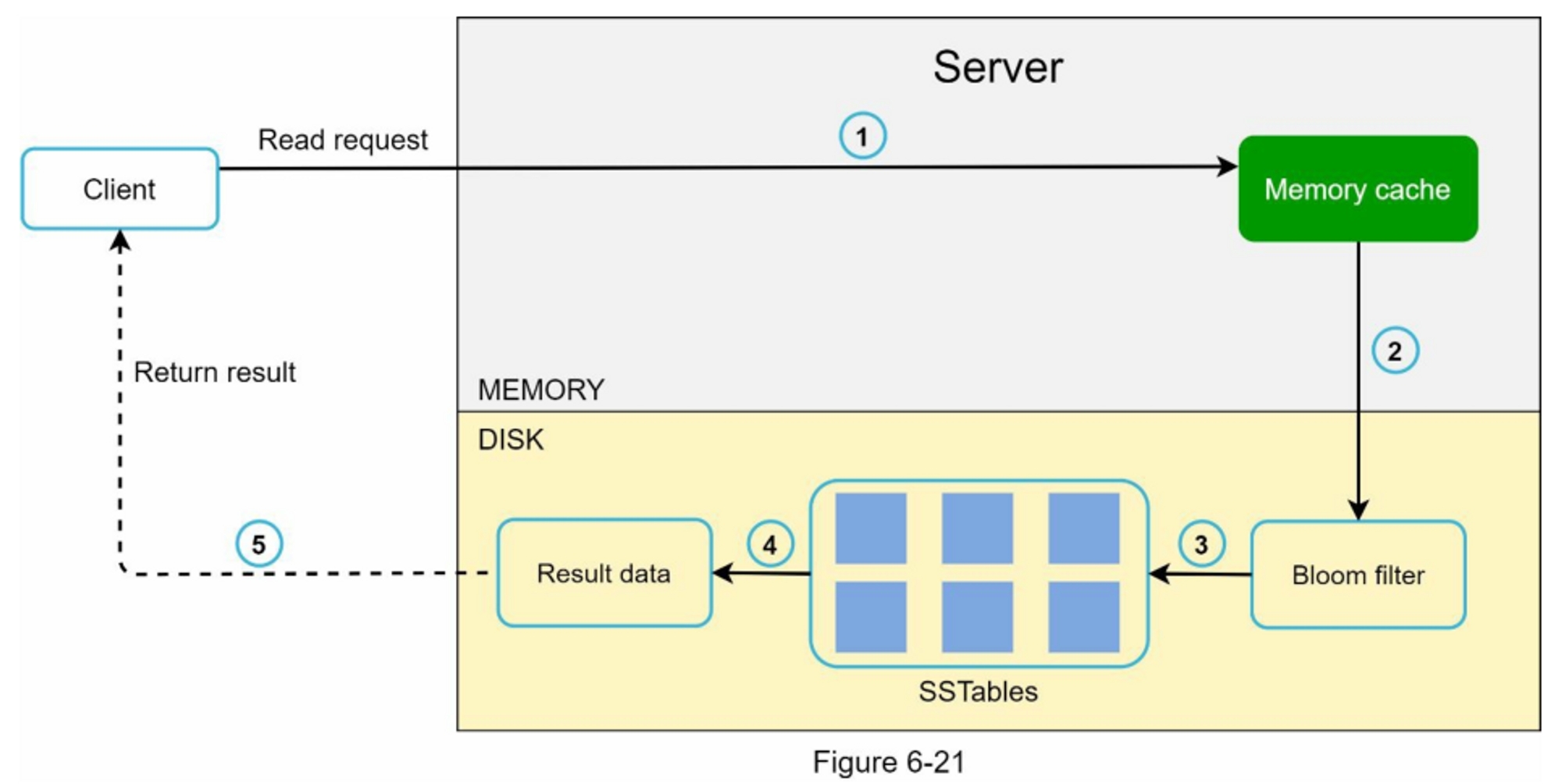
- 系统首先检查数据是否在内存中。如果没有,就转到第2步。
- 如果数据不在内存中,系统会检查Bloom过滤器。
- Bloom过滤器被用来计算哪些SSTables可能包含密钥。
- SSTables会返回数据集的结果。
- 数据集的结果被返回给客户端。
总结
本章涵盖了许多概念和技术。为了加深记忆,下表总结了分布式键值存储的特点和相应的技术。
| 目标/问题 | 技术 |
|---|---|
| 存储大数据的能力 | 使用一致性哈希将负载分散到多个服务器上 |
| 高可用性读取 | 数据复制 多数据中心设置 |
| 高可用性写入 | 使用向量时钟(vector clocks)进行版本控制和冲突解决 |
| 数据分区 | 一致性哈希 |
| 增量可扩展性 | 一致性哈希 |
| 异质性(heterogeneity) | 一致性哈希 |
| 处理临时性故障 | 草率仲裁(sloppy quorum)和暗示切换(hinted handoff) |
| 处理永久性故障 | Merkle 树 |
| 处理数据中心中断 | 跨数据中心复制 |
参考资料
- [1] Amazon DynamoDB: https://aws.amazon.com/dynamodb/
- [2] memcached: https://memcached.org/
- [3] Redis: https://redis.io/
- [4] Dynamo: Amazon’s Highly Available Key-value Store: https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
- [5] Cassandra: https://cassandra.apache.org/
- [6] Bigtable: A Distributed Storage System for Structured Data: https://static.googleusercontent.com/media/research.google.com/en//archive/bigtable- osdi06.pdf
- [7] Merkle tree: https://en.wikipedia.org/wiki/Merkle_tree
- [8] Cassandra architecture: https://cassandra.apache.org/doc/latest/architecture/
- [9] SStable: https://www.igvita.com/2012/02/06/sstable-and-log-structured-storage-leveldb/
- [10] Bloom filter https://en.wikipedia.org/wiki/Bloom_filter
第07章:在分布式系统中设计唯一 ID 生成器
在本章中,要求在分布式系统中设计一个唯一 ID 生成器。 你的第一个想法可能是在传统数据库中使用具有 auto_increment 属性的主键。 但是,auto_increment 在分布式环境中不起作用,因为 单个数据库服务器不够大,跨多个数据库以最小延迟生成唯一 ID 具有挑战性。 以下是唯一 ID 的一些示例:
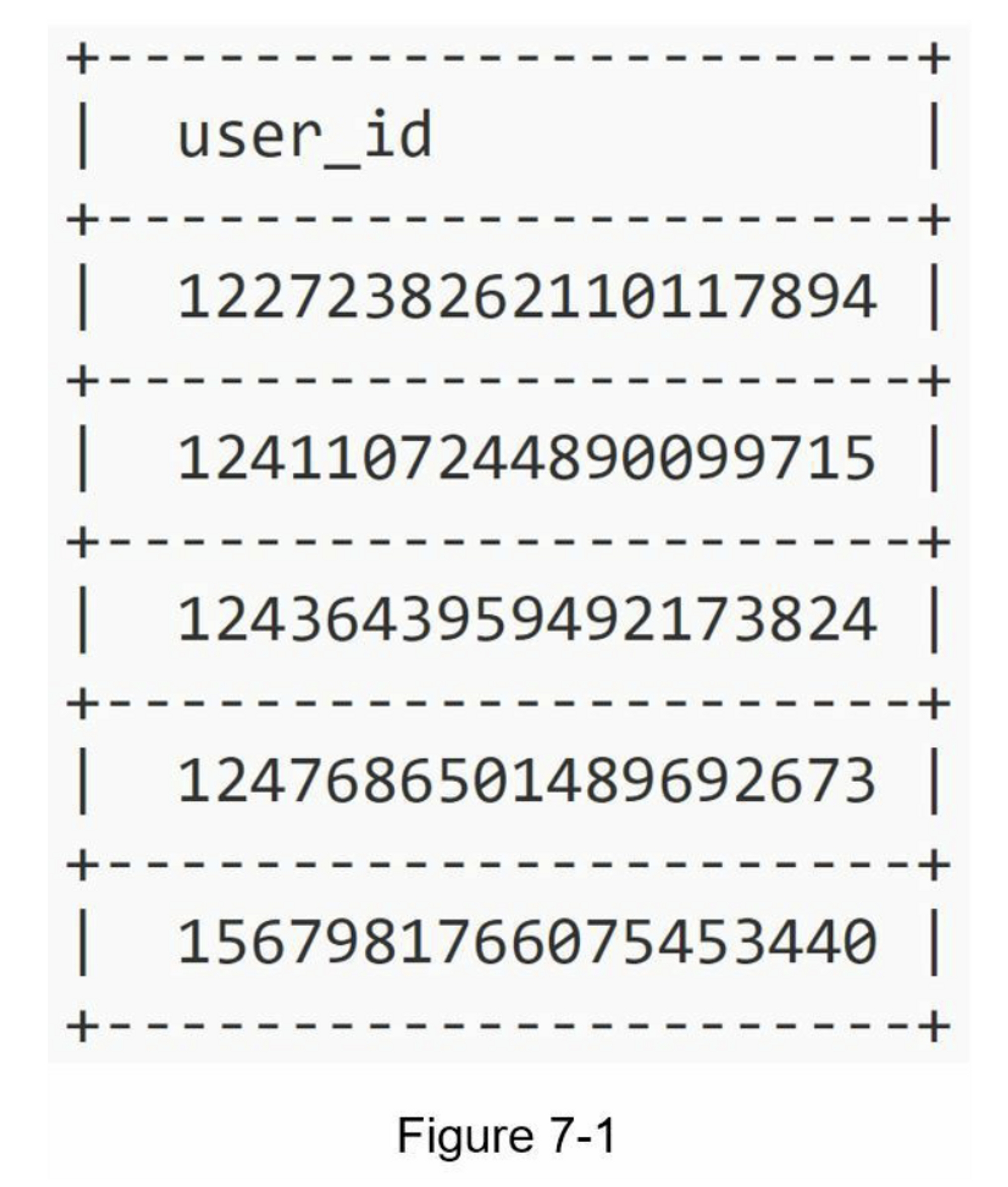
第1步:了解问题并确定设计范围
了解清楚问题是解决任何系统设计面试问题的第一步。下面是一个候选人与面试官互动的例子:
候选人:唯一ID有什么特点?
面试官:ID 必须是唯一的,并且是可排序的。
候选人:每增加一条记录,ID 是否加 1?
面试官:ID是按时间递增的,不一定只递增1,当天晚上创建的ID比早上创建的ID大。
候选人:ID 是否只包含数值?
面试官:是的,这很正确。
候选人:ID长度要求是多少?
面试官:ID 应该适合 64 位。
候选人:系统的规模是多少?
面试官:系统应该可以每秒生成10000个ID。
以上是可以向面试官提出的一些示例问题。了解需求并澄清歧义很重要。
本次面试题,要求如下:
- ID 必须是唯一的。
- ID 只是数值。
- ID 适合 64 位。
- ID 按日期排序。
- 能够每秒生成超过 10,000 个唯一 ID。
第2步:提出高层次的设计方案并获得认同
可以使用多个选项在分布式系统中生成唯一ID。
我们考虑的选项有:
- 多主复制
- 通用唯一标识符 (UUID)
- Ticket 服务器
- 推特雪花算法
让我们看看它们是如何工作的,以及每个选项的优缺点。
多主复制
如图7-2所示,第一种方式是多主复制。
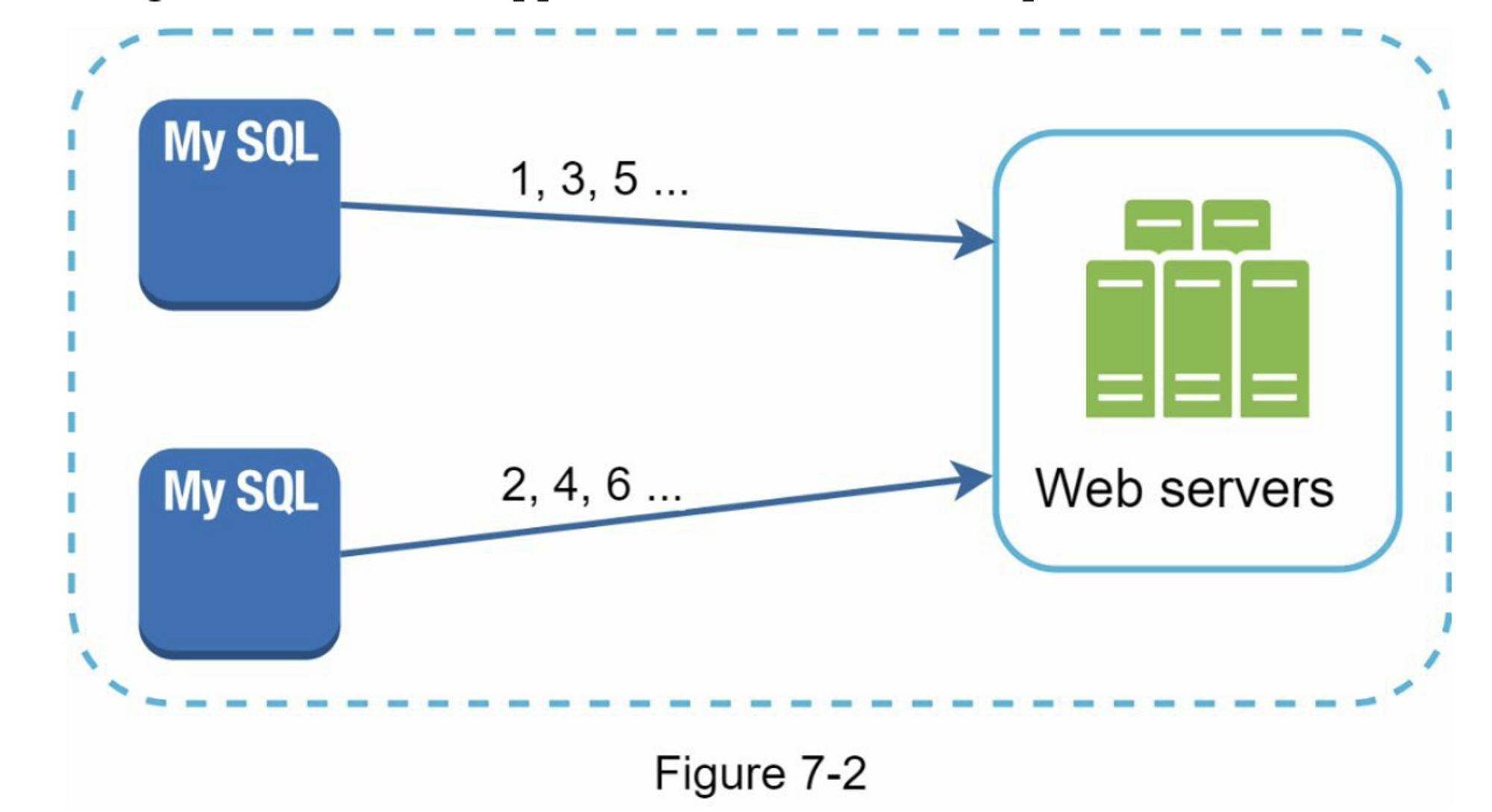
这种方法使用数据库的 auto_increment 特性。我们不是将下一个 ID 增加 1,而是将其增加 k,其中 k 是正在使用的数据库服务器的数量。如图 7-2 所示,下一个要生成的 ID 等于同一服务器中的前一个 ID 加 2。这解决了一些可扩展性问题,因为 ID 可以随着数据库服务器的数量而扩展。
然而,这种策略有一些主要的缺点:
- 难以通过多个数据中心进行扩展
- ID在多个服务器上不随时间而增长
- 在增加或删除服务器时,不能很好地扩展
UUID
UUID 是另一种获取唯一 ID 的简单方法。 UUID 是一个 128 位数字,用于识别计算机系统中的信息。UUID获得串通的概率非常低。引自维基百科,"在每秒产生10亿个UUIDs,大约100年后,创造一个重复的概率会达到50%" [1] 。
以下是 UUID 的示例:09c93e62-50b4-468d-bf8a-c07e1040bfb2。 UUID 可以独立生成,无需服务器之间的协调。图 7-3 展示了 UUID 的设计。
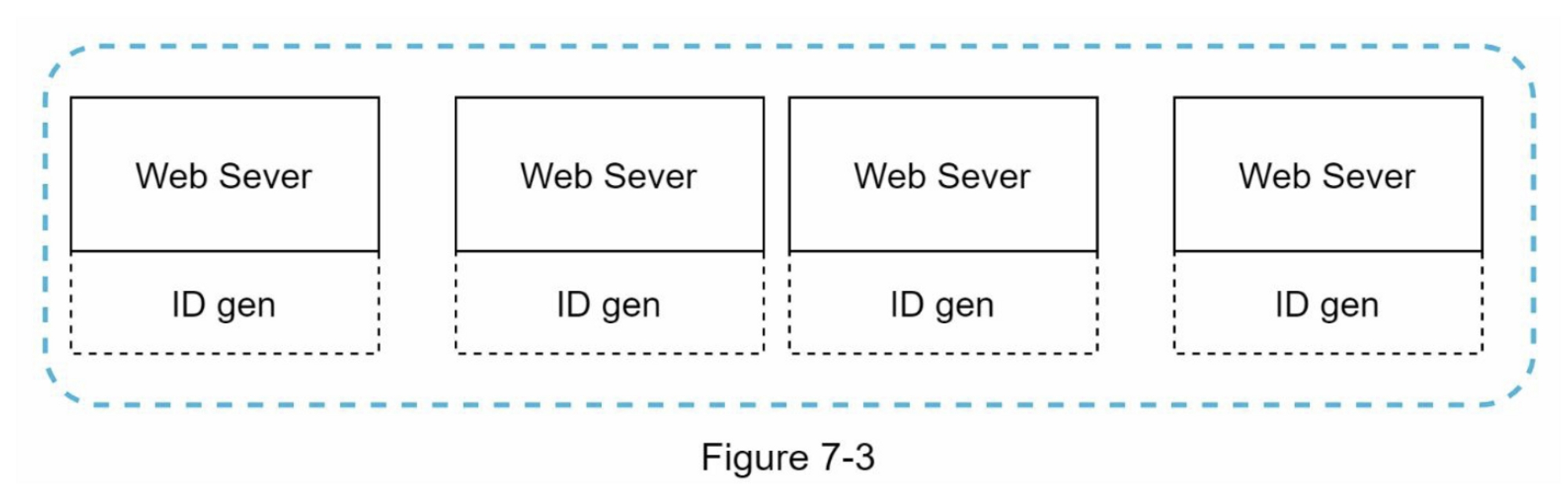
在这个设计中,每个Web服务器都包含一个ID生成器,并且Web服务器负责独立生成ID。
优点:
- 生成 UUID 很简单。服务器之间不需要协调,因此不会有任何同步问题。
- 该系统易于扩展,因为每个 Web 服务器负责生成它们使用的 ID。 ID 生成器可以轻松地与 Web 服务器一起扩展。
缺点:
- ID 是 128 位长,但我们的要求是 64 位。
- ID 不会随时间上升
- ID 可以是非数字的。
Ticket 服务器
票据服务器是产生唯一ID的另一种有趣的方式。Flicker开发了票据服务器来生成分布式主键[2]。值得一提的是,该系统是如何工作的。
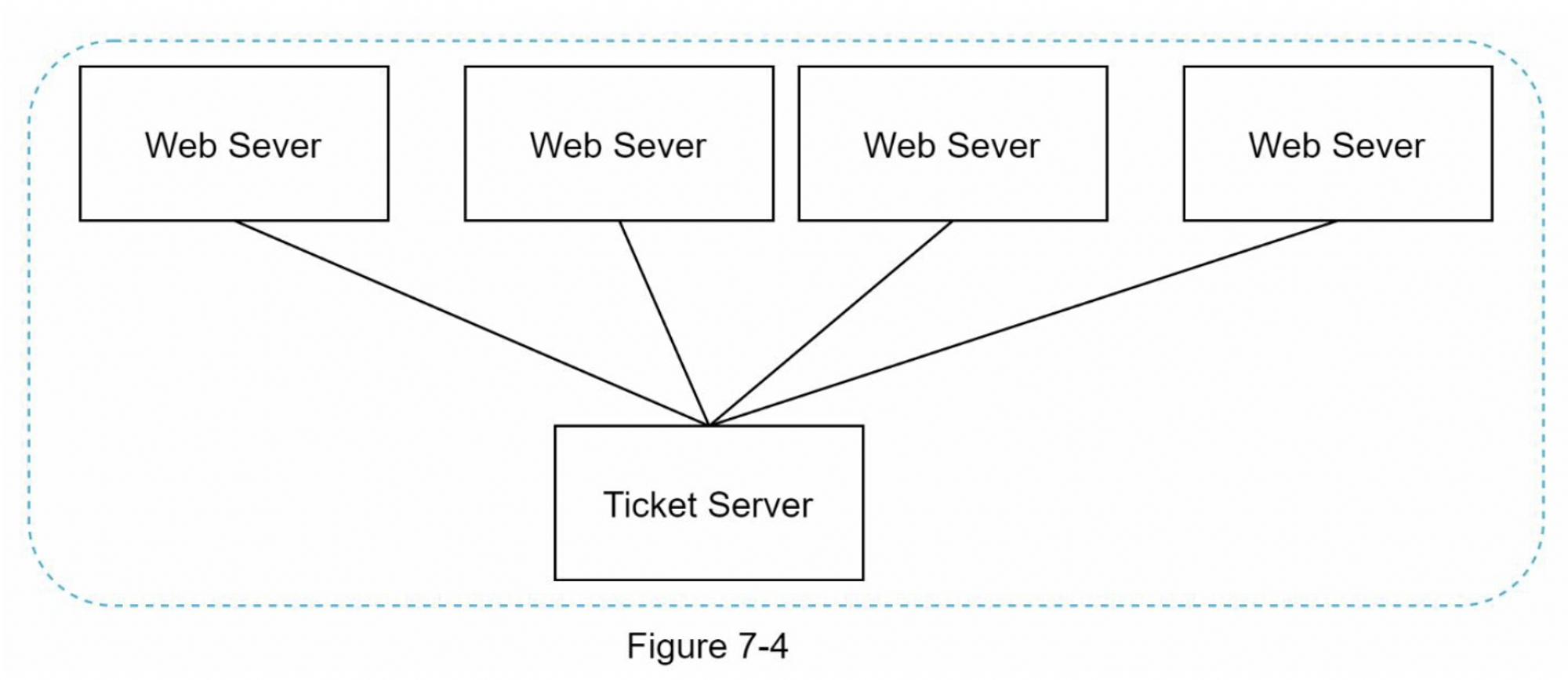
这个想法是在一个单一的数据库服务器(Ticket Server)中使用一个集中的自动增量功能。要了解更多这方面的信息,请参考flicker的工程博客文章[2] 。
优点:
- 数字 ID
- 易于实施,适用于中小型应用程序
缺点:
- 单点故障。单个票务服务器意味着如果票务服务器发生故障,所有依赖它的系统都将面临问题。为了避免单点故障,我们可以设置多个票务服务器。然而,这将引入新的挑战,如数据同步。
推特雪花算法
上面提到的方法给了我们一些关于不同的ID生成系统如何工作的想法。然而,它们都不符合我们的具体要求;因此,我们需要另一种方法。Twitter 独特的 ID 生成系统“snowflake”[3] 很有启发性,可以满足我们的要求。
分而治之是我们的朋友。我们不是直接生成一个ID,而是将一个ID分成不同的部分。图7-5显示了一个64位ID的布局。

下面对每个部分进行解释:
- 符号位:1 位,它将始终为 0。这是为将来使用保留的。它可以潜在地用于区分有符号数和无符号数。
- 时间戳:41 位。自纪元或自定义纪元以来的毫秒数。我们使用 Twitter 雪花默认纪元 1288834974657,相当于 2010 年 11 月 4 日 01:42:54 UTC。
- 数据中心 ID:5 位,这给了我们 $$2 ^ 5 = 32$$ 个数据中心。
- 机器 ID:5 位,每个数据中心有 $$2 ^ 5 = 32$$ 台机器
- 序列号:12 位。对于在该机器/进程上生成的每个 ID,序列号都会递增 1。该数字每毫秒重置为 0。
第3步:深入设计
在高层设计中,我们讨论了在分布式系统中设计唯一ID生成器的各种方案。我们确定了一种基于Twitter雪花ID生成器的方法。让我们深入了解一下这个设计。为了恢复我们的记忆,设计图被重新列在下面。

数据中心ID和机器ID是在启动时选择的,一般在系统运行后就固定下来。数据中心ID和机器ID的任何变化都需要仔细审查,因为这些数值的意外变化会导致ID冲突。时间戳和序列号是在ID生成器运行时生成的。
时间戳
最重要的41位组成了时间戳部分。由于时间戳随时间增长,ID可按时间排序。
图 7-7 显示了二进制表示如何转换为 UTC 的示例。您还可以使用类似的方法将 UTC 转换回二进制表示。
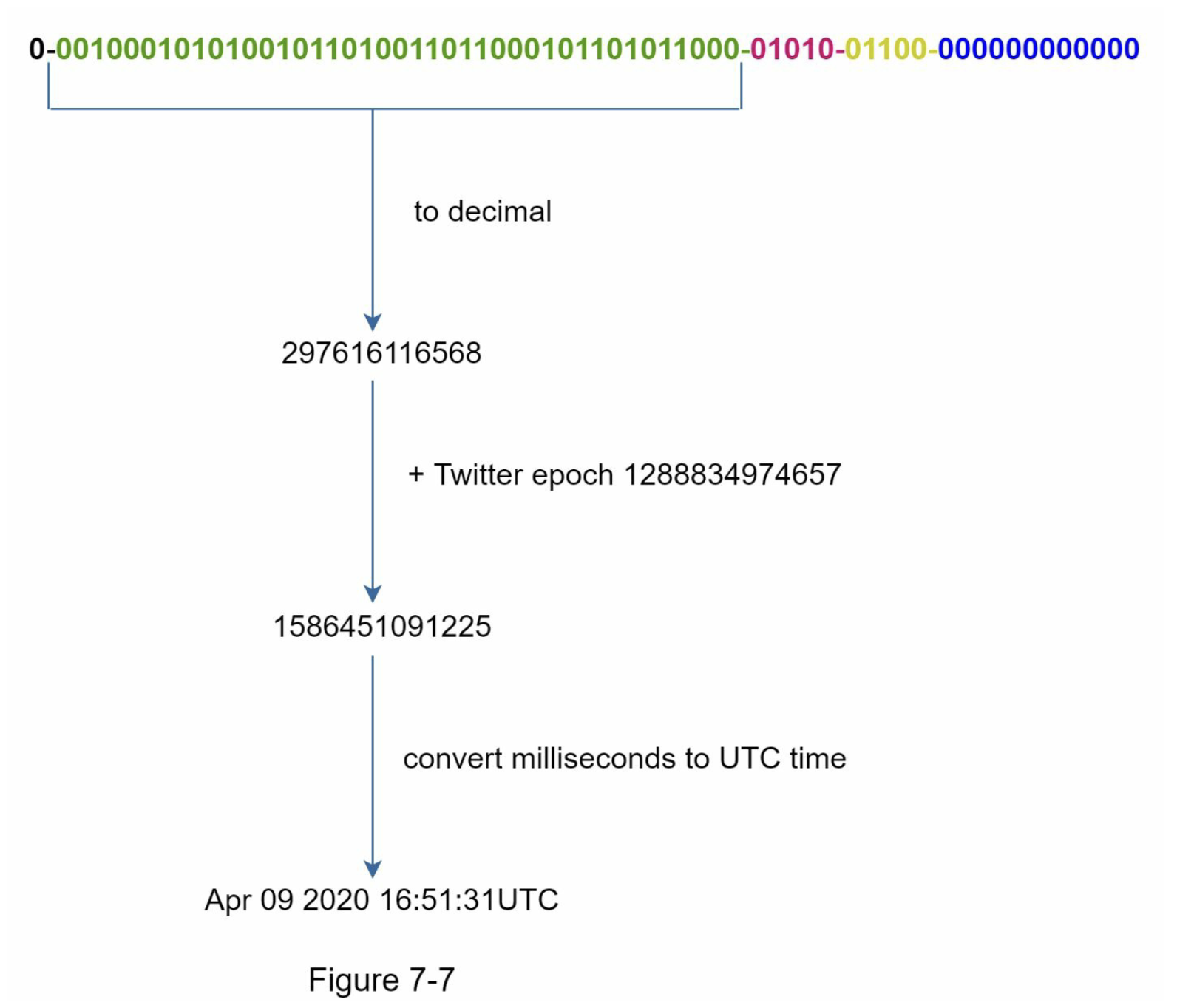
可以用 41 位表示的最大时间戳是: $$2 ^ {41} - 1 = 2199023255551毫秒(ms)$$,这样我们就可以得到。 $$\approx 69年=2199023255551毫秒/1000秒/365天/24小时/3600秒$$。
这意味着 ID 生成器将工作 69 年,并且自定义纪元时间接近今天的日期会延迟溢出时间。 69年后,我们将需要一个新的纪元时间或采用其他技术来迁移ID。
序列号
序列号是 12 位,这给了我们 $$\mathbf{2 ^ {12} = 4096}$$ 种组合。除非在同一台服务器上在一毫秒内生成多个 ID,否则该字段为 0。理论上,一台机器每毫秒最多可以支持4096个新ID。
第4步:总结
在本章中,我们讨论了设计唯一 ID 生成器的不同方法:多主复制、UUID、票务服务器和类似 Twitter 雪花的唯一 ID 生成器。我们选择了雪花,因为它支持我们所有的用例,并且在分布式环境中是可扩展的。
如果面试结束时有额外时间,这里有一些额外的谈话要点:
- 时钟同步。在我们的设计中,我们假设 ID 生成服务器具有相同的时钟。当服务器在多个内核上运行时,此假设可能不成立。同样的挑战存在于多机场景中。时钟同步的解决方案超出了本书的范围;但是,了解问题的存在很重要。网络时间协议是这个问题最流行的解决方案。有兴趣的读者可以参考参考资料[4]。
- 节段长度调整。例如,较少的序列号但较多的时间戳位对低并发性和长期应用是有效的。
- 高可用性。由于 ID 生成器是关键任务系统,因此它必须具有高可用性
恭喜你走到了这一步!现在给自己一个鼓励,干得漂亮!
参考资料
[1] Universally unique identifier: https://en.wikipedia.org/wiki/Universally_unique_identifier
[2] Ticket Servers: Distributed Unique Primary Keys on the Cheap:https://code.flickr.net/2010/02/08/ticket-servers-distributed-unique-primary-keys-on-the-cheap
[3] Announcing Snowflake: https://blog.twitter.com/engineering/en_us/a/2010/announcing-snowflake.html
[4] Network time protocol: https://en.wikipedia.org/wiki/Network_Time_Protocol
第08章:短网址设计
在这一章中,我们将解决一个有趣而经典的系统设计面试问题:设计一个像tinyurl一样的URL缩短服务。
第1步:了解问题并确定设计范围
系统设计的面试问题是故意留有余地的。为了设计一个精心设计的系统,关键是要问清楚问题。
候选人:你能举个例子说明URL缩短器的工作原理吗?
面试官:假设 URL https://www.systeminterview.com/q=chatsystem&c=loggedin&v=v3&l=long 是原始 URL。你的服务创建了一个长度较短的别名:https://tinyurl.com/y7keocwj。如果你单击较短的别名URL,它会将你重定向到原始 URL。
候选人:流量是多少?
面试官:每天产生1亿个URL。
候选人:缩短后的URL有多长?
面试官:越短越好。
候选人:缩短的网址中允许使用哪些字符?
面试官:短网址可以是数字(0-9)和字符(a-z,A-Z)的组合。
候选人:缩短的URL可以删除或更新吗?
面试官:为了简单起见,我们假设缩短的URL不能被删除或更新。
以下是基本用例:
- URL缩短:给定一个长的URL => 返回一个短得多的URL
- URL重定向:给定一个短的URL => 重定向到原来的URL
- 高可用性、可扩展性和容错考虑
粗略估计系统量级
- 写操作:每天产生1亿个URL。
- 每秒写操作:亿/24/3600 = 1160
- 读操作:假设读操作和写操作的比例为10:1,读每秒操作:1160 * 10 = 11,600
- 假设 URL 缩短服务将运行 10 年,这意味着我们必须支持 1 亿 * 365 * 10 = 3650 亿条记录。
- 假设平均 URL 长度为 100。
- 10 年的存储需求:3650 亿 * 100 字节 * 10 年 = 365 TB
重要的是,你要与面试官一起探讨假设和计算,以便你们两个人都在同一起跑线上。
第2步:提出高层次的设计方案并获得认同
在本节中,我们将讨论 API 端点、URL 重定向和 URL 缩短。
API 端点
API端点促进了客户和服务器之间的通信。我们将设计REST风格的API。如果你不熟悉restful API,你可以查阅外部资料,比如参考资料中的资料[1]。一个URL缩短器主要需要两个API端点。
-
网址缩短。 要创建一个新的短 URL,客户端发送一个 POST 请求,其中包含一个参数:原始长 URL。 API 如下所示:
POST api/v1/data/shorten
- 请求参数:{longUrl: longURLString}。
- 返回 shortURL
-
URL重定向。为了将一个短的URL重定向到相应的长的URL,一个客户端发送一个GET请求。该API看起来像这样:
GET api/v1/shortUrl
- 返回用于HTTP重定向的 longURL
URL 重定向
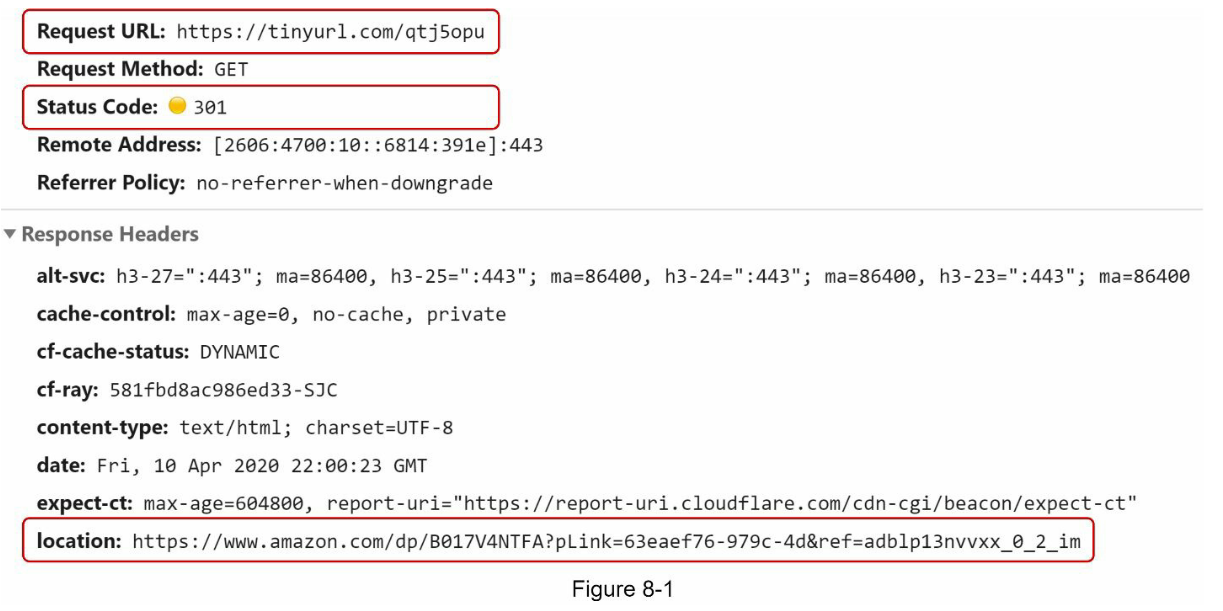
图8-1显示了当你在浏览器上输入一个tinyurl时会发生什么。一旦服务器收到tinyurl请求,它就会用301重定向将短网址改为长网址。
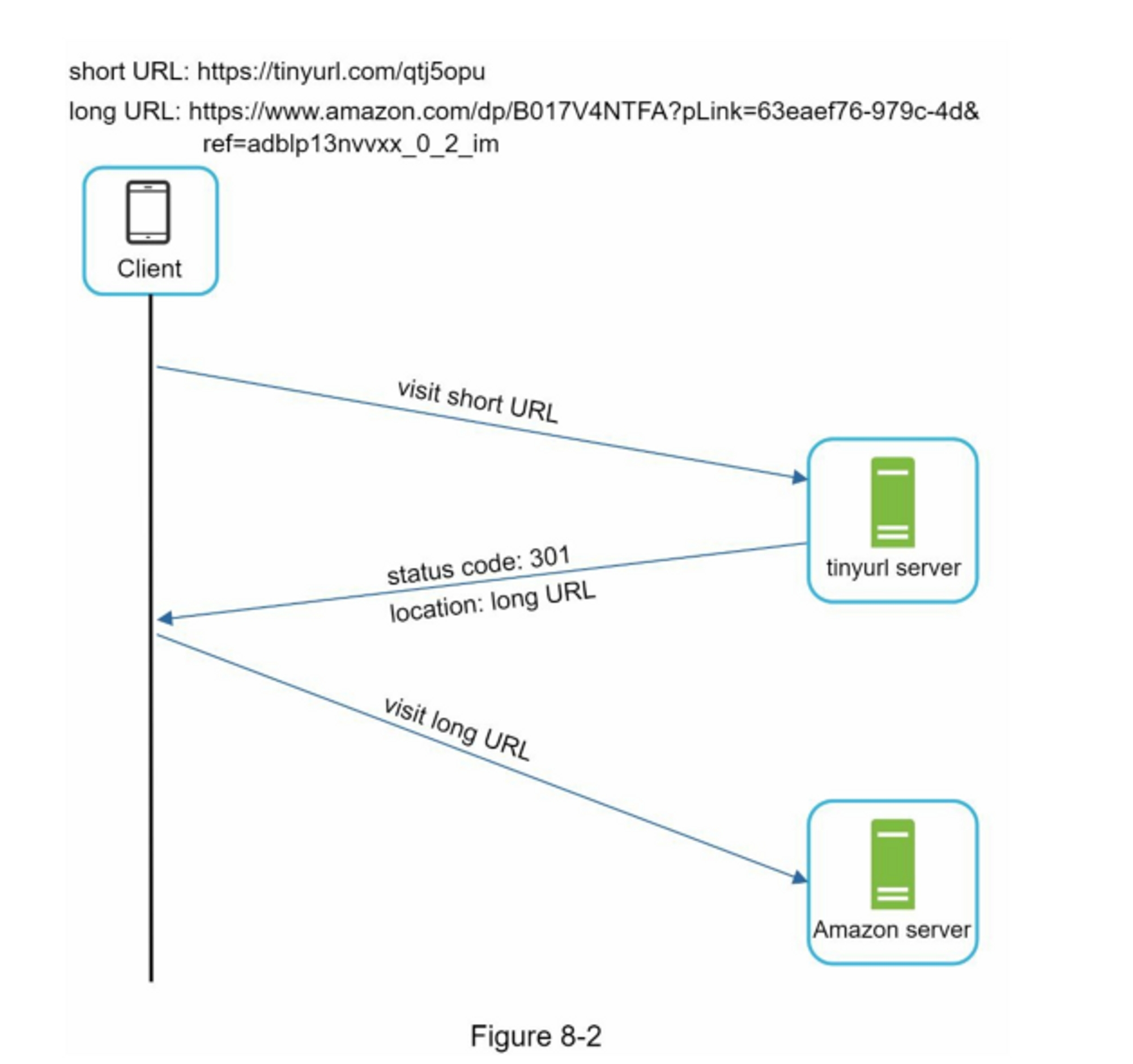
客户端和服务器之间的详细通信情况如图8-2所示。
值得在这里讨论的一件事是 301 重定向与 302 重定向。
- 301重定向。301重定向表明,请求的URL被 "永久 "地移到了长URL上。由于是永久重定向,浏览器会缓存响应,对同一URL的后续请求将不会被发送到URL缩短服务上。相反,请求将直接被重定向到长网址服务器。
- 302重定向。302重定向意味着URL被 "暂时 "移到长URL上,这意味着对同一URL的后续请求将首先被发送到URL缩短服务上。然后,它们会被重定向到长网址服务器。
每种重定向方法都有其优点和缺点。如果优先考虑减少服务器负载,使用301重定向是有意义的,因为只有同一URL的第一个请求被发送到URL缩短服务器。然而,如果分析是重要的,302重定向是一个更好的选择,因为它可以更容易地跟踪点击率和点击的来源。
实现URL重定向的最直观的方法是使用哈希表。假设哈希表存储<shortURL, longURL>对,URL重定向可以通过以下方式实现。
- 获取longURL:
longURL = hashTable.get(shortURL) - 一旦你得到longURL,就执行URL重定向。
缩短网址
让我们假设短的URL看起来像这样:www.tinyurl.com/{hashValue}。为了支持缩短URL的用例,我们必须找到一个哈希函数fx,将长URL映射到hashValue,如图8-3所示。
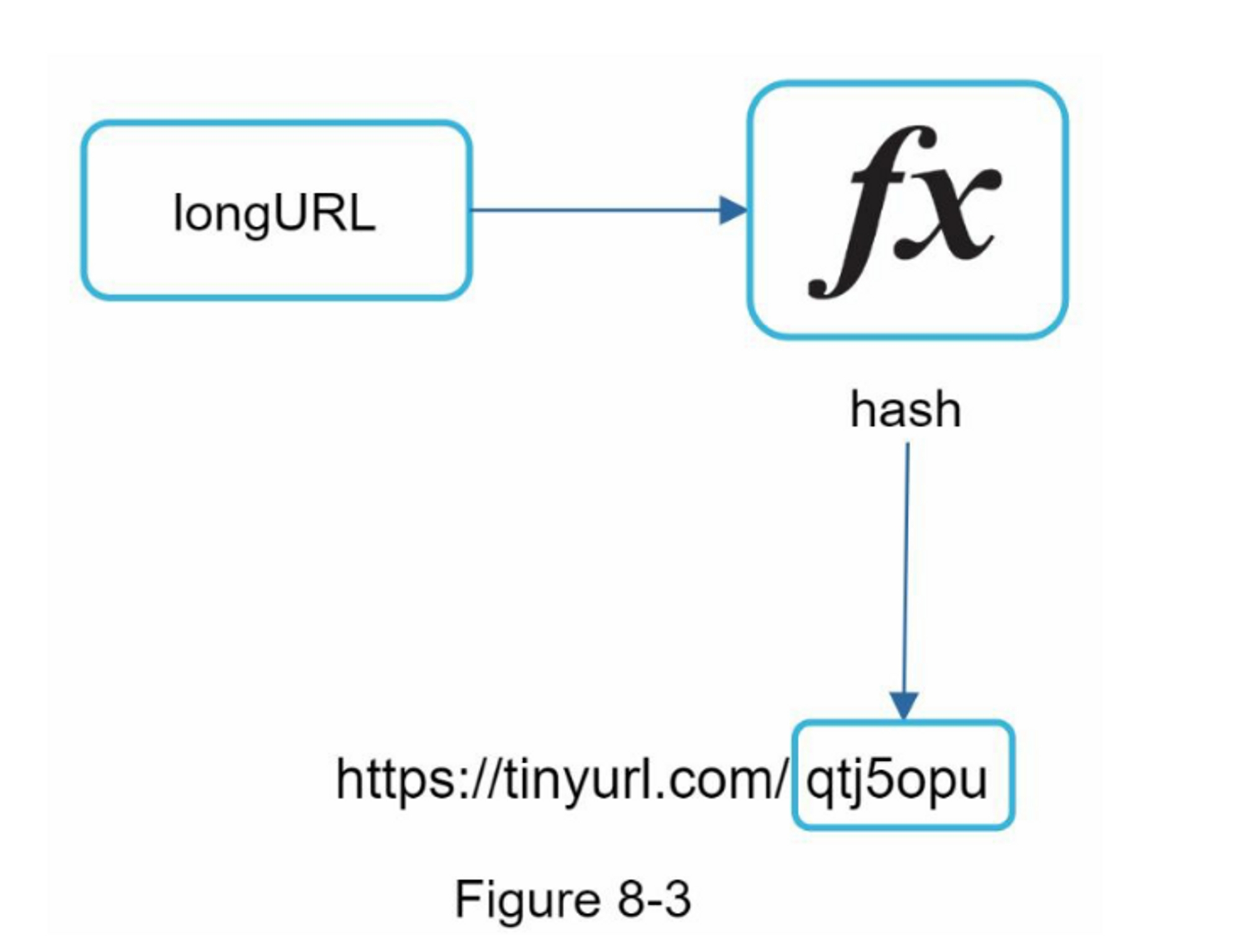
哈希函数必须满足以下要求。
- 每个longURL必须被散列成一个hashValue。
- 每个hashValue都可以被映射回longURL。
哈希函数的详细设计将深入讨论。
第3步:深入设计
到目前为止,我们已经讨论了URL缩短和URL重定向的高层设计。在本节中,我们将深入探讨以下内容:数据模型、哈希函数、URL缩短和URL重定向。
数据模型
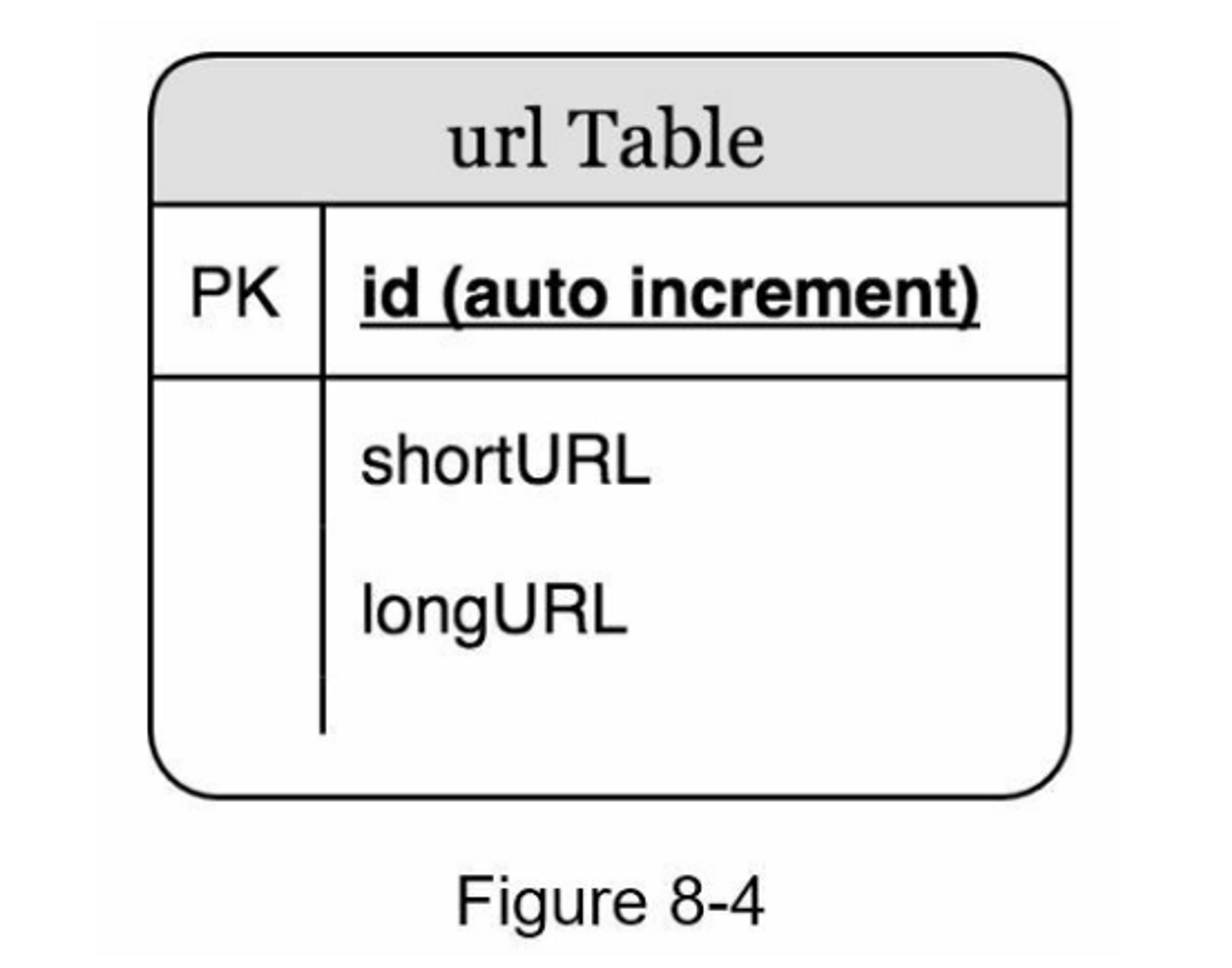
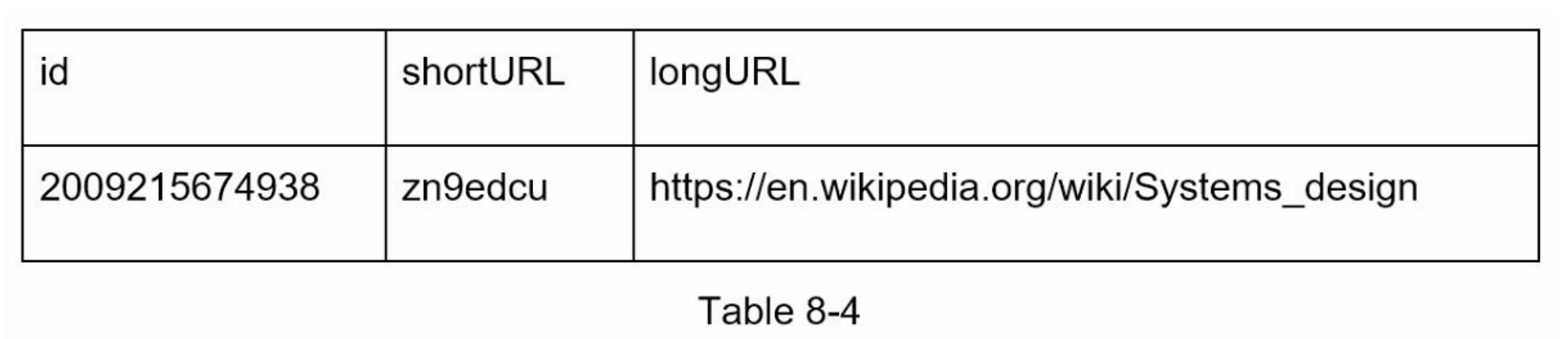
在高层设计中,所有的东西都存储在一个哈希表中。这是一个很好的起点;然而,这种方法在现实世界的系统中是不可行的,因为内存资源是有限的和昂贵的。一个更好的选择是将<shortURL, longURL>映射存储在一个关系数据库中。图8-4显示了一个简单的数据库表设计。简化版的表包含3列:id、shortURL、longURL。
哈希函数
哈希函数用于将一个长的URL哈希成一个短的URL,也称为 hashValue。
哈希值的长度
hashValue 由[0-9, a-z, A-Z]中的字符组成,包含 $$10+26+26=62$$ 个可能的字符。要计算 hashValue 的长度,请找出最小的 n,使 $$62^n \ge 365亿$$。根据估计,系统必须支持多达 3650 亿个 URL。 表 8-1 显示了 hashValue 的长度和它可以支持的相应的最大 URL 数。
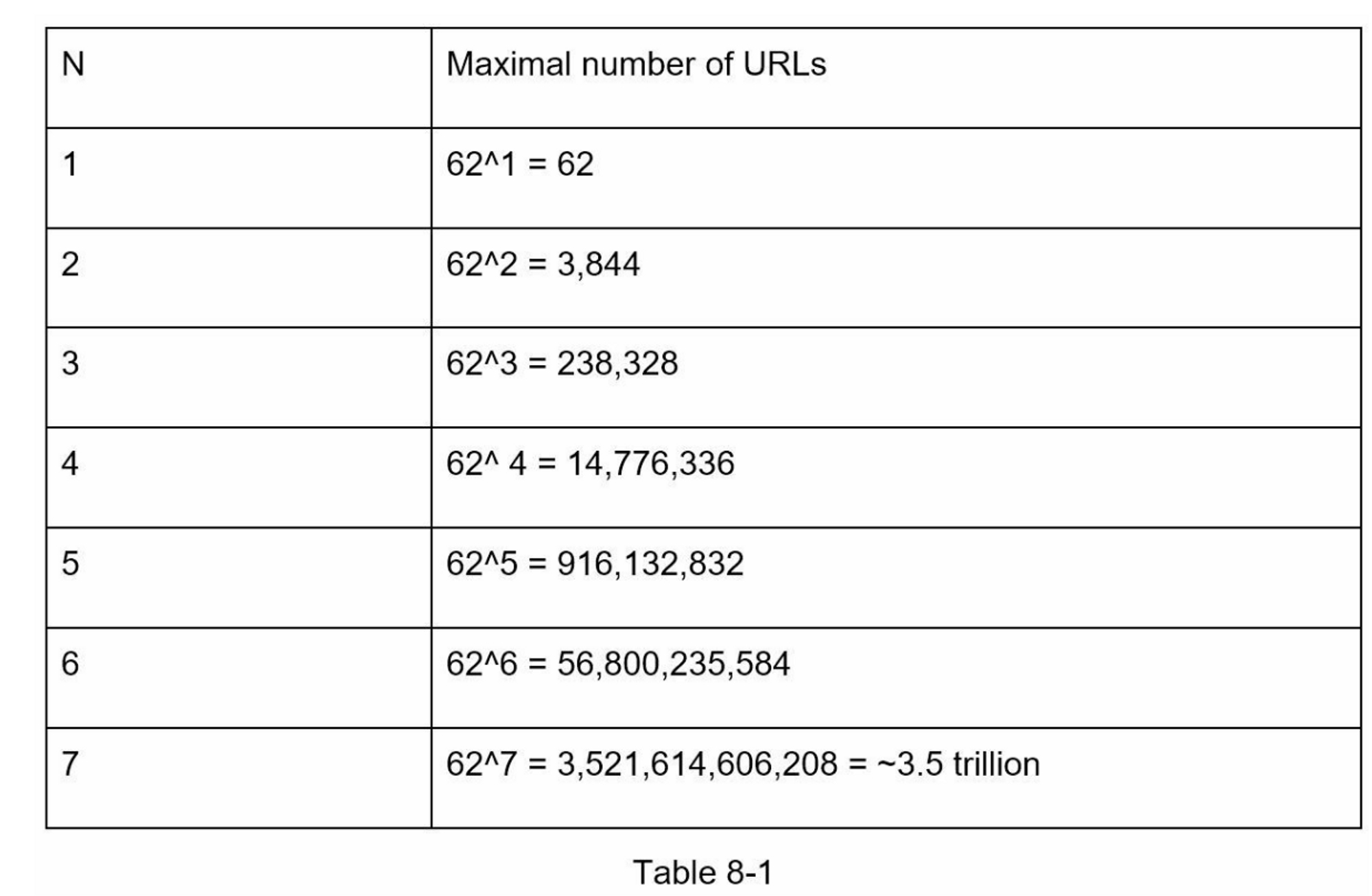
当 $$n = 7$$ 时, $$62 ^ n \approx 3.5万亿$$,3.5 万亿足以容纳 3650亿个URL,所以 hashValue 的长度为 7。
我们将探讨两种类型的URL缩短器的哈希函数。第一种是 "哈希+碰撞解决",第二种是 "base 62 转换"。让我们逐一来看看它们。
哈希+碰撞解决
为了缩短长的URL,我们应该实现一个散列函数,将长的URL散列成一个7个字符的字符串。一个直接的解决方案是使用知名的哈希函数,如CRC32、MD5或SHA-1。下表比较了在这个URL(https://en.wikipedia.org/wiki/Systems_design)上应用不同哈希函数后的哈希结果:
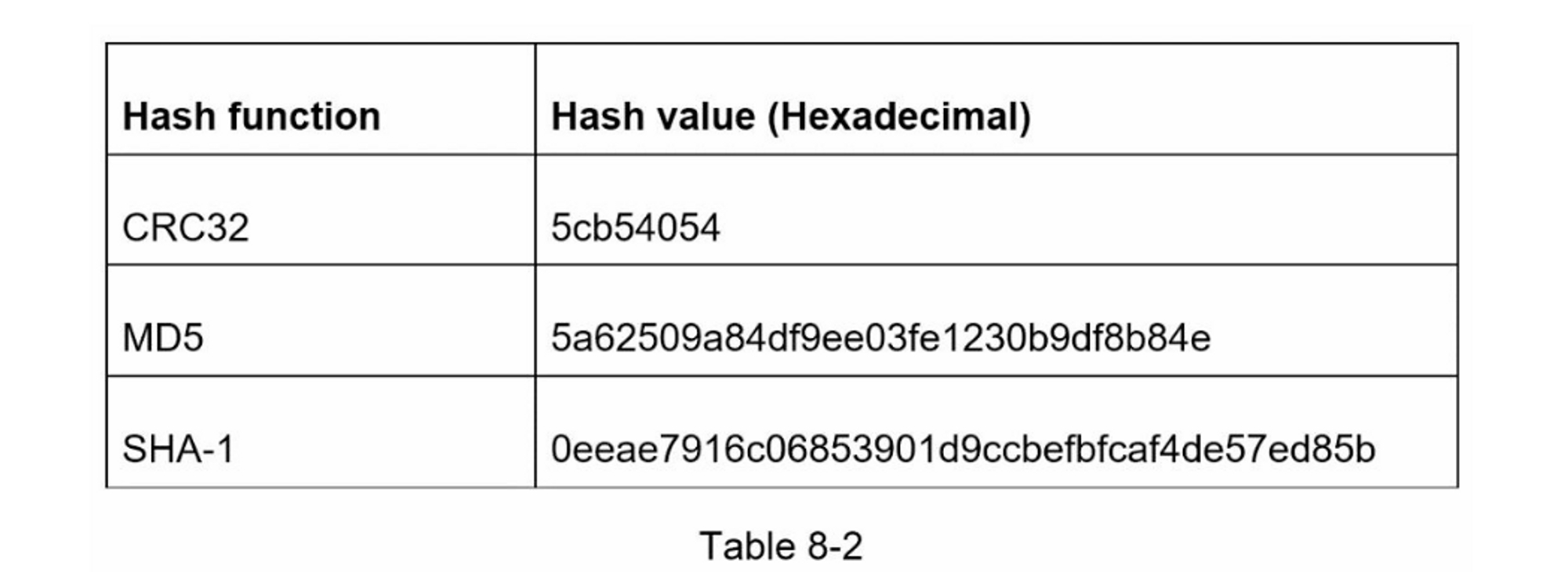
如表8-2所示,即使是最短的哈希值(来自CRC32)也太长了(超过7个字符)。我们怎样才能使它更短呢?
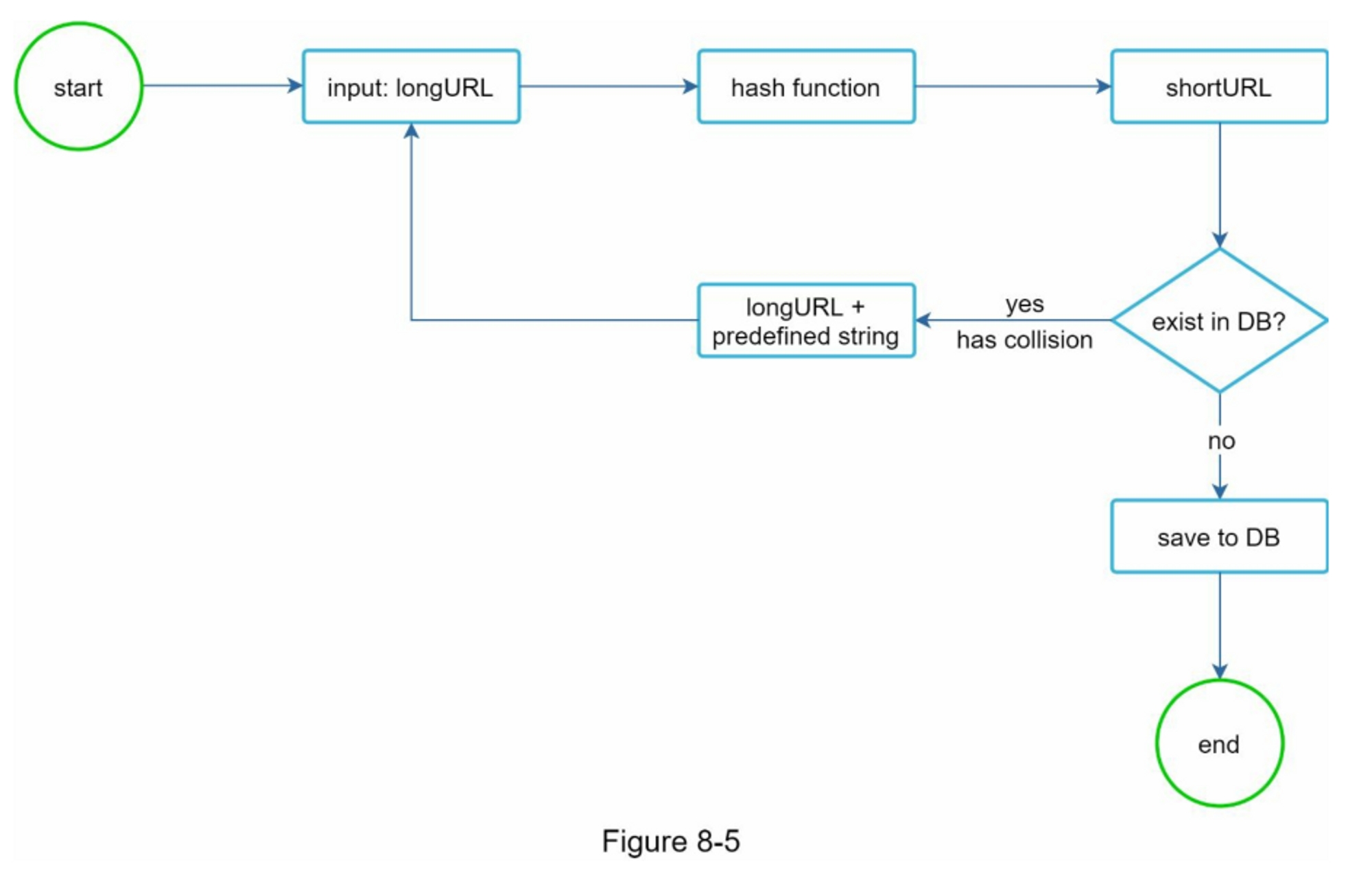
第一种方法是收集哈希值的前7个字符;然而,这种方法会导致哈希碰撞。为了解决哈希碰撞,我们可以递归地追加一个新的预定义字符串,直到不再发现碰撞。这一过程在图8-5中得到了解释。
这种方法可以消除碰撞;但是,查询数据库以检查每个请求是否存在短网址的成本很高。一种叫做Bloom过滤器的技术[2]可以提高性能。布隆过滤器是一种空间效率高的概率技术,用来测试一个元素是否是一个集合的成员。更多细节请参考参考资料[2]。
base 62 转换
Base 转换是 URL 缩短器常用的另一种方法。 Base 转换有助于在不同的数字表示系统之间转换成相同的数字。 使用 Base 62 转换,因为 hashValue 有 62 个可能的字符。 让我们用一个例子来解释转换的工作原理:将 $$11157_{10}$$ 转换为 base 62 表示( $$11157_{10}$$ 在 base 10 系统中表示 11157)。
-
从名字上看,base 62 是一种使用 62 个字符进行编码的方式。 映射是: 0-0, ..., 9-9, 10-a, 11-b, ..., 35-z, 36-A, ..., 61-Z,其中“a”代表 10,“Z” ' 代表 61,等等。
-
$$11157_{10} = 2 \times 62^2 + 55 \times 62^1 + 59 \times 62^0 = \left [2, 55, 59 \right ] \rightarrow \left [2, T, X \right]$$ 以 base 62 表示。
对话过程如图8-6所示。

-
因此,短网址是:https://tinyurl.com/2TX
两种方法的比较
下表显示了两种方法的差异。
| 哈希+碰撞解决 | base 62 转换 |
|---|---|
| 固定短URL长度 | 短URL长度不固定,它随着 id 变化 |
| 不需要唯一ID生成器 | 该选项依赖于唯一ID生成器 |
| 可能出现冲突,必须解决 | 碰撞是不可能的,因为 ID 是唯一的 |
| 不可能计算出下一个可用的短网址,因为它不依赖于ID。 | 如果新条目的 ID 递增 1,则很容易找出下一个可用的短 URL。 这可能是一个安全问题。 |
URL 缩短的深入研究
作为系统的核心部分之一,我们希望URL缩短的流程在逻辑上是简单和实用的。在我们的设计中使用了62进制转换。我们建立了以下图表(图8-7)来演示这个流程。
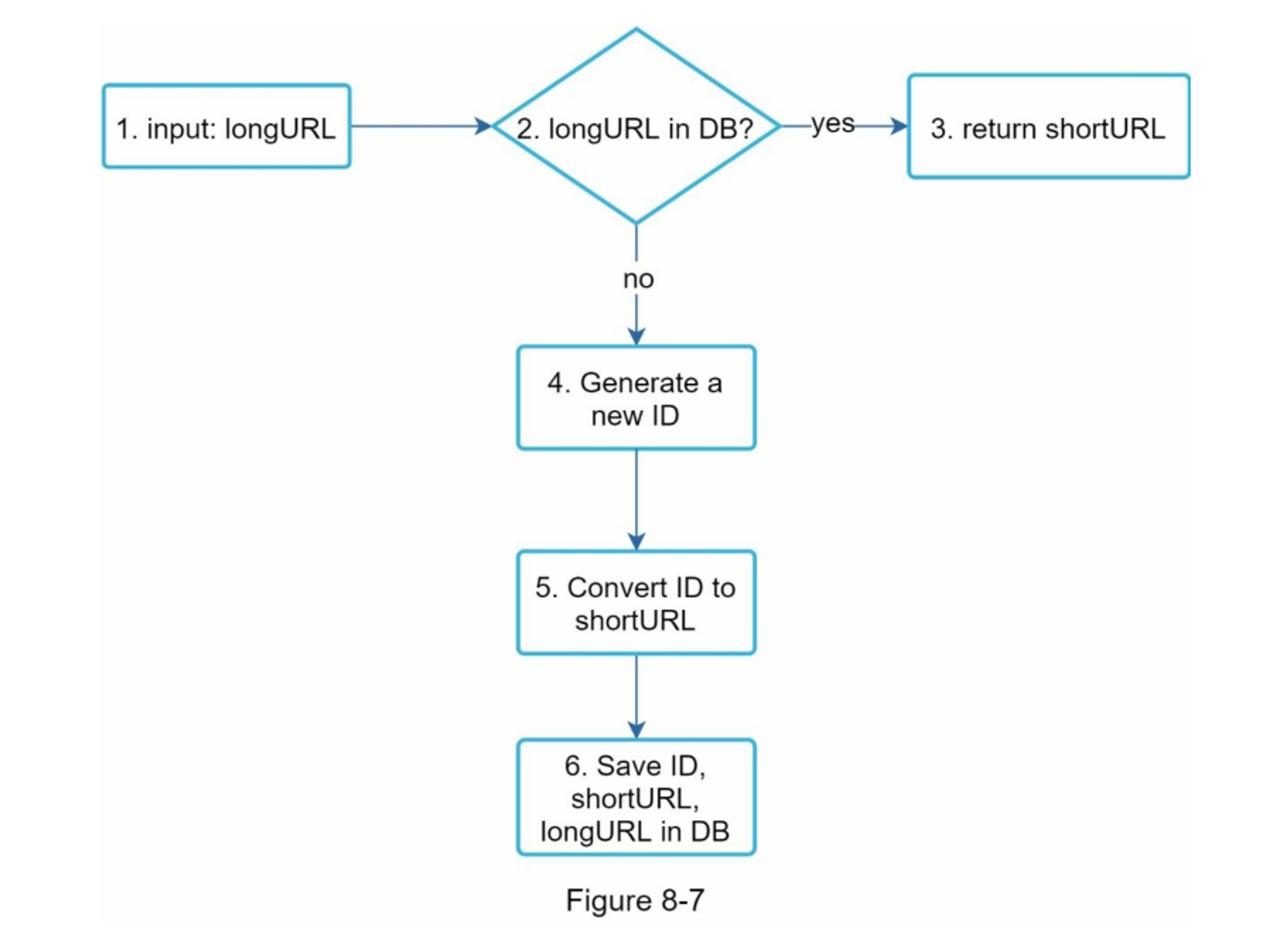
- longURL 是输入的
- 系统检查 longURL 是否存在于数据库中
- 如果是的话,这意味着longURL之前被转换为shortURL。在这种情况下,从数据库中获取shortURL并将其返回给客户端。
- 如果不是,longURL是新的。一个新的唯一ID(主键)由唯一ID生成器生成。
- 使用base 62转换将ID转换为shortURL。
- 用ID、shortURL和longURL创建一个新的数据库记录。
为了使流程更容易理解,让我们看一个具体的例子。
-
假设输入的longURL是:https://en.wikipedia.org/wiki/Systems_design
-
唯一ID生成器返回ID:2009215674938
-
使用62进制转换将ID转换为shortURL。ID(2009215674938)被转换为 "zn9edcu"。
-
将ID、shortURL和longURL保存到数据库,如表8-4所示。
值得一提的是分布式唯一 ID 生成器。 它的主要功能是生成全局唯一 ID,用于创建 shortURL。 在高度分布式的环境中,实现唯一 ID 生成器具有挑战性。 幸运的是,我们已经在“第 7 章:在分布式系统中设计唯一 ID 生成器”中讨论了一些解决方案。 你可以回过头来回顾它来刷新你的记忆。
URL重定向的深入研究
图 8-8 显示了 URL 重定向的详细设计。 由于读取多于写入,<shortURL, longURL> 映射存储在缓存中以提高性能。
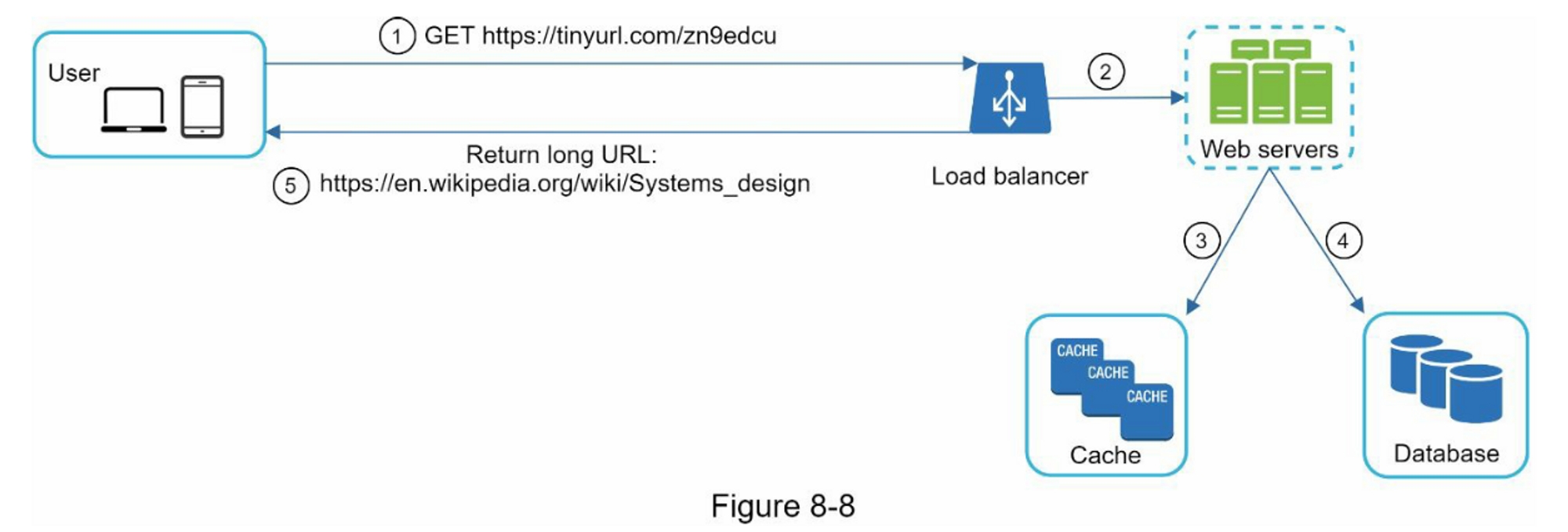
URL重定向的流程总结如下:
- 一个用户点击了一个短的URL链接:
https://tinyurl.com/zn9edcu - 负载均衡器将请求转发给网络服务器
- 如果shortURL已经在缓存中,直接返回longURL。
- 如果短URL不在缓存中,从数据库中获取长URL。如果它不在数据库中,很可能是用户输入了一个无效的短网址。
- longURL被返回给用户。
第4步:总结
在本章中,我们讨论了 API 设计、数据模型、哈希函数、URL 缩短和 URL 重定向。
如果在面试结束时有多余的时间,这里有几个额外的谈话要点:
- 速率限制器:我们可能面临的一个潜在安全问题是恶意用户发送大量的 URL 缩短请求。 速率限制器有助于根据 IP 地址或其他过滤规则过滤掉请求。 如果您想重温有关速率限制的记忆,请参阅“第 4 章:设计速率限制器”。
- Web 服务器扩展:由于 Web 层是无状态的,因此很容易通过添加或删除 Web 服务器来扩展 Web 层。
- 数据库的扩展。数据库复制和分片是常见的技术。
- 分析。数据对商业成功越来越重要。将分析解决方案整合到URL缩短器中,可以帮助回答一些重要的问题,如有多少人点击一个链接?他们何时点击链接?等等。
- 可用性、一致性和可靠性。这些概念是任何大型系统成功的核心。我们在第1章中对它们进行了详细讨论,请对这些主题进行复习记忆
恭喜你走到了这一步!现在给自己一个鼓励,干得漂亮!
参考资料
[1] A RESTful Tutorial: https://www.restapitutorial.com/index.html
[2] Bloom filter: https://en.wikipedia.org/wiki/Bloom_filter
第09章:网络爬虫设计
本章重点介绍网络爬虫设计:一道有趣且经典的系统设计面试题。
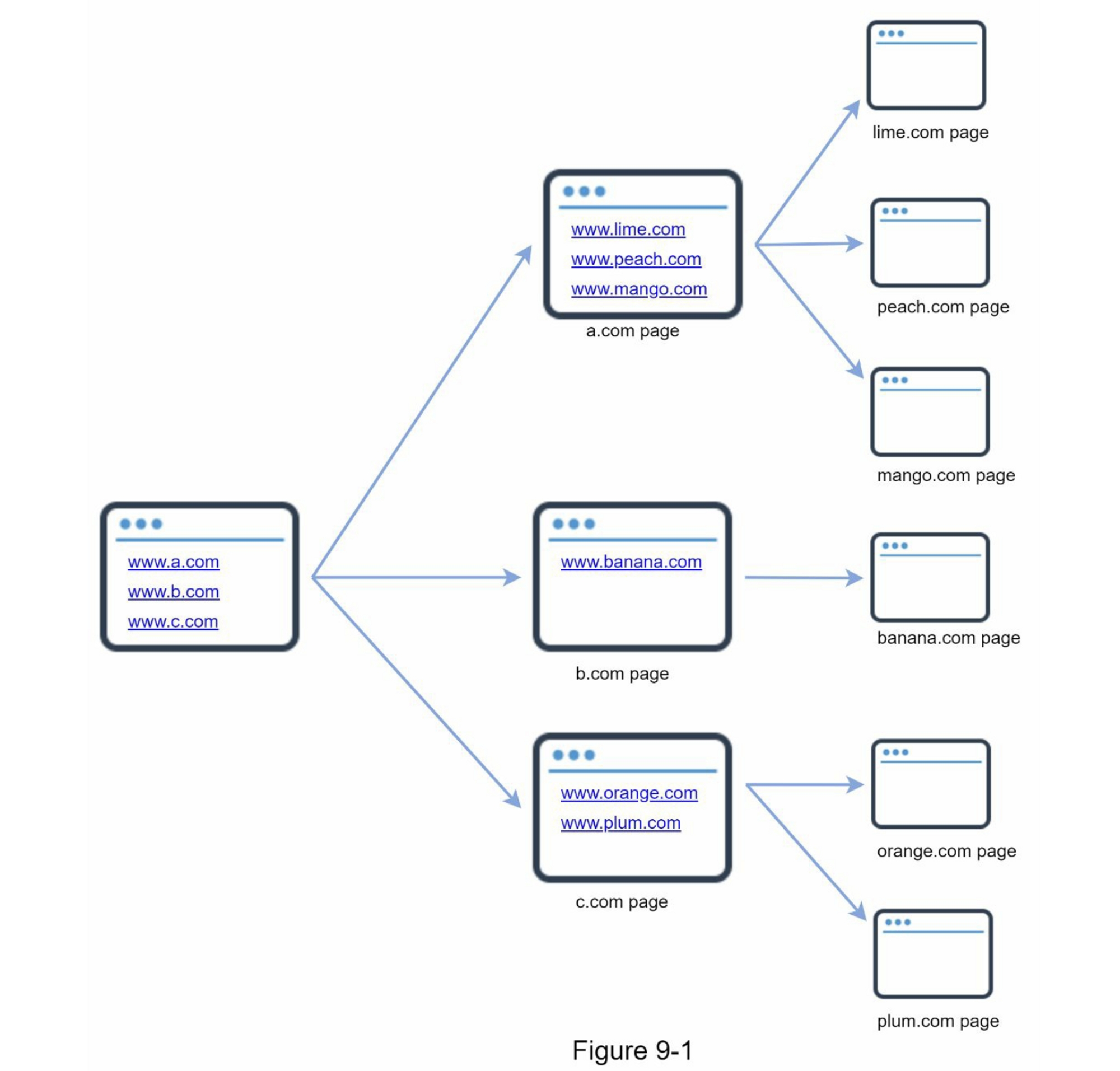
网络爬虫被称为机器人或蜘蛛。搜索引擎广泛使用它来发现 Web 上的新内容或更新内容。内容可以是网页、图像、视频、PDF 文件等。网络爬虫首先收集一些网页,然后按照这些页面上的链接收集新内容。图 9-1 显示了抓取过程的可视化示例。
爬虫有多种用途:
- 搜索引擎索引:这是最常见的用例。爬虫收集网页以为搜索引擎创建本地索引。例如,Googlebot 是 Google 搜索引擎背后的网络爬虫。
- 网络存档:这是从网络收集信息以保存数据以备将来使用的过程。例如,许多国家图书馆运行爬虫来存档网站。著名的例子是美国国会图书馆 [1] 和欧盟网络档案馆 [2]。
- 网络挖掘:网络的爆炸式增长为数据挖掘提供了前所未有的机会。 网络挖掘有助于从 Internet 中发现有用的知识。例如,顶级金融公司使用爬虫下载股东大会和年度报告以了解公司的关键举措。
- 网络监控:这些爬虫有助于监控 Internet 上的版权和商标侵权行为。例如,Digimarc [3] 利用爬虫来发现盗版作品和报告。
开发网络爬虫的复杂性取决于我们打算支持的规模。它可以是一个只需要几个小时即可完成的小型学校项目,也可以是一个需要专门的工程团队不断改进的大型项目。因此,我们将在下面探讨支持的规模和功能。
第1步:了解问题并确定设计范围
网络爬虫的基本算法很简单:
- 给定一组URLs,下载所有由URLs指向的网页。
- 从这些网页中提取 URL。
- 将新的 URL 添加到要下载的 URL 列表中。重复这3个步骤。
网络爬虫真的像这个基本算法一样简单吗?不完全是。设计一个高度可扩展的网络爬虫是一项极其复杂的任务。任何人都不太可能在面试时间内设计出一个庞大的网络爬虫。在进入设计之前,我们必须提出问题以了解需求并建立设计范围:
候选人:爬虫的主要目的是什么?它用于搜索引擎索引、数据挖掘或其他用途吗?
面试官:搜索引擎索引。
候选人:网络爬虫每个月收集多少网页?
采访者:10 亿页。
候选人:包括哪些内容类型?仅 HTML 还是其他内容类型(如 PDF 和图像)?
面试官:只有 HTML。
候选人:我们是否考虑新增或编辑的网页?
面试官:是的,我们应该考虑新添加或编辑的网页。
候选人:我们需要存储从网络上爬取的 HTML 页面吗?
面试官:是的,最多5年
应聘者:我们如何处理内容重复的网页?
面试官:重复内容的页面应该忽略。
以上是您可以向面试官提出的一些示例问题。了解需求并澄清歧义很重要。即使你被要求设计一个简单的产品,比如网络爬虫,你和你的面试官可能不会有相同的假设。
除了要向面试官澄清的功能之外,记下优秀网络爬虫的以下特征也很重要:
- 可伸缩性(Scalability):网络非常大。那里有数十亿个网页。使用并行化网络爬行应该非常有效。
- 鲁棒性(Robustness):网络充满了陷阱。错误的 HTML、无响应的服务器、崩溃、恶意链接等都很常见。爬虫必须处理所有这些边缘情况。
- 礼貌(Politeness):爬虫不应该在短时间间隔内向网站发出太多请求。
- 可扩展性(Extensibility):系统非常灵活,因此只需进行最少的更改即可支持新的内容类型。比如我们以后要抓取图片文件,应该不需要重新设计整个系统。
粗略估算
以下估算基于许多假设,与面试官沟通以达成共识很重要。
- 假设每月下载 10 亿个网页。
- QPS: $$1,000,000,000 / 30 天 / 24 小时 / 3600 秒 = 400 页/秒。$$
- $$峰值 QPS = 2 \times QPS = 800$$
- 假设平均网页大小为 500k
- $$10 亿页 \times 500k = 每月 500 TB$$ 存储空间。如果您对数字存储单元不清楚,请重新阅读第 2 章中的“2 的幂”部分。
- 假设数据存储五年, $$500 TB \times 12 个月 \times 5 年 = 30 PB$$。需要 30 PB 的存储来存储五年的内容。
第2步:提出高层次的设计方案并获得认同
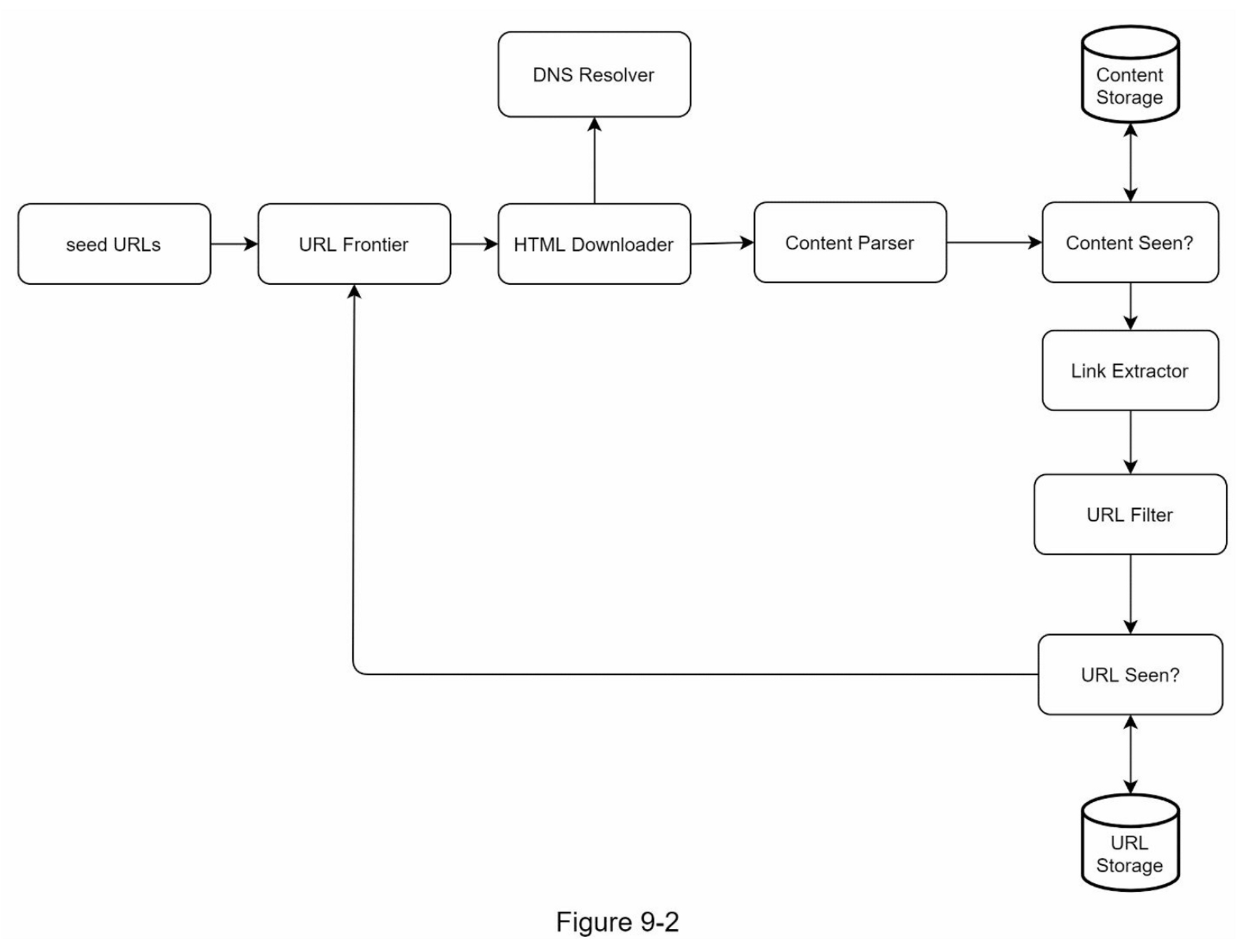
一旦需求明确了,我们就开始进行高层设计。受以前关于网络抓取的研究[4][5]的启发,我们提出了一个高层设计,如图9-2所示。
首先,我们探索每个设计组件以了解它们的功能。然后,我们逐步检查爬虫工作流程。
Seed URLs
网络爬虫使用种子 URL 作为爬网过程的起点。例如,要抓取大学网站的所有网页,选择种子 URL 的一种直观方法是使用大学的域名。
要抓取整个网络,我们需要创造性地选择种子 URL。一个好的种子 URL 是一个很好的起点,爬虫可以利用它来遍历尽可能多的链接。一般的策略是将整个 URL 空间分成更小的空间。第一个提议的方法是基于位置的,因为不同的国家可能有不同的流行网站.
另一种方法是根据主题选择种子网址;例如,我们可以将 URL 空间划分为购物、体育、医疗保健等。种子 URL 选择是一个开放式问题,您不应该给出完美的答案,先大胆想想。
URL Frontier
大多数现代网络爬虫将爬行状态分为两种:待下载和已下载。存储待下载的URL的组件被称为URL Frontier。你可以把它称为先进先出(FIFO)队列。关于URL Frontier的详细信息,请参考深入研究的内容。
HTML Downloader
HTML Downloader 从互联网上下载网页。这些URL是由URL Frontier提供的。
DNS Resolver
要下载网页,必须将 URL 转换为 IP 地址。 HTML Downloader 调用 DNS Resolver 为 URL 获取相应的 IP 地址。例如,截至 2019 年 3 月 5 日,URL www.wikipedia.org 已转换为 IP 地址 198.35.26.96。
Content Parser
下载网页后,必须对其进行解析和验证,因为格式错误的网页可能会引发问题并浪费存储空间。在爬网服务器中实现内容解析器会减慢爬网过程。因此,Content Parser(内容解析器)是一个单独的组件。
Content Seen?
在线研究[6]显示,29%的网页是重复的内容,这可能导致同一内容被多次存储。我们引入了 "Content Seen? "数据结构,以消除数据的冗余,缩短处理时间。它有助于检测以前存储在系统中的新内容。为了比较两个HTML文档,我们可以逐个字符进行比较。然而,这种方法既慢又费时,特别是当涉及到数十亿的网页时。完成这项任务的一个有效方法是比较两个网页的哈希值[7]。
Content Storage
它是一个用于存储HTML内容的存储系统。存储系统的选择取决于诸如数据类型、数据大小、访问频率、寿命等因素,磁盘和内存都被使用。
- 大部分内容存储在磁盘上,因为数据集太大而无法放入内存。
- 热门内容保存在内存中以减少延迟。
URL Extractor
URL Extractor(网址提取器) 从 HTML 页面解析和提取链接。图 9-3 显示了链接提取过程的示例。通过添加“https://en.wikipedia.org”前缀将相对路径转换为绝对 URL。

URL Filter
URL Filter 排除某些内容类型、文件扩展名、错误链接和“黑名单”站点中的 URL。
URL Seen?
"URL Seen? "是一个数据结构,用于跟踪之前被访问过的或已经在Frontier中的URL。"URL Seen? "有助于避免多次添加相同的URL,因为这可能会增加服务器负载并导致潜在的无限循环。
布隆过滤器和哈希表是实现 "URL Seen? "组件的常用技术。我们不会在这里介绍布隆过滤器和哈希表的详细实现。欲了解更多信息,请参考参考资料[4][8]。
URL Storage
URL Storage 存储已经访问过的 URL。到目前为止,我们已经讨论了每个系统组件。接下来,我们将它们放在一起来解释工作流程。
网络爬虫工作流程
为了更好地逐步解释工作流程,在设计图中添加了序列号,如图 9-4 所示。
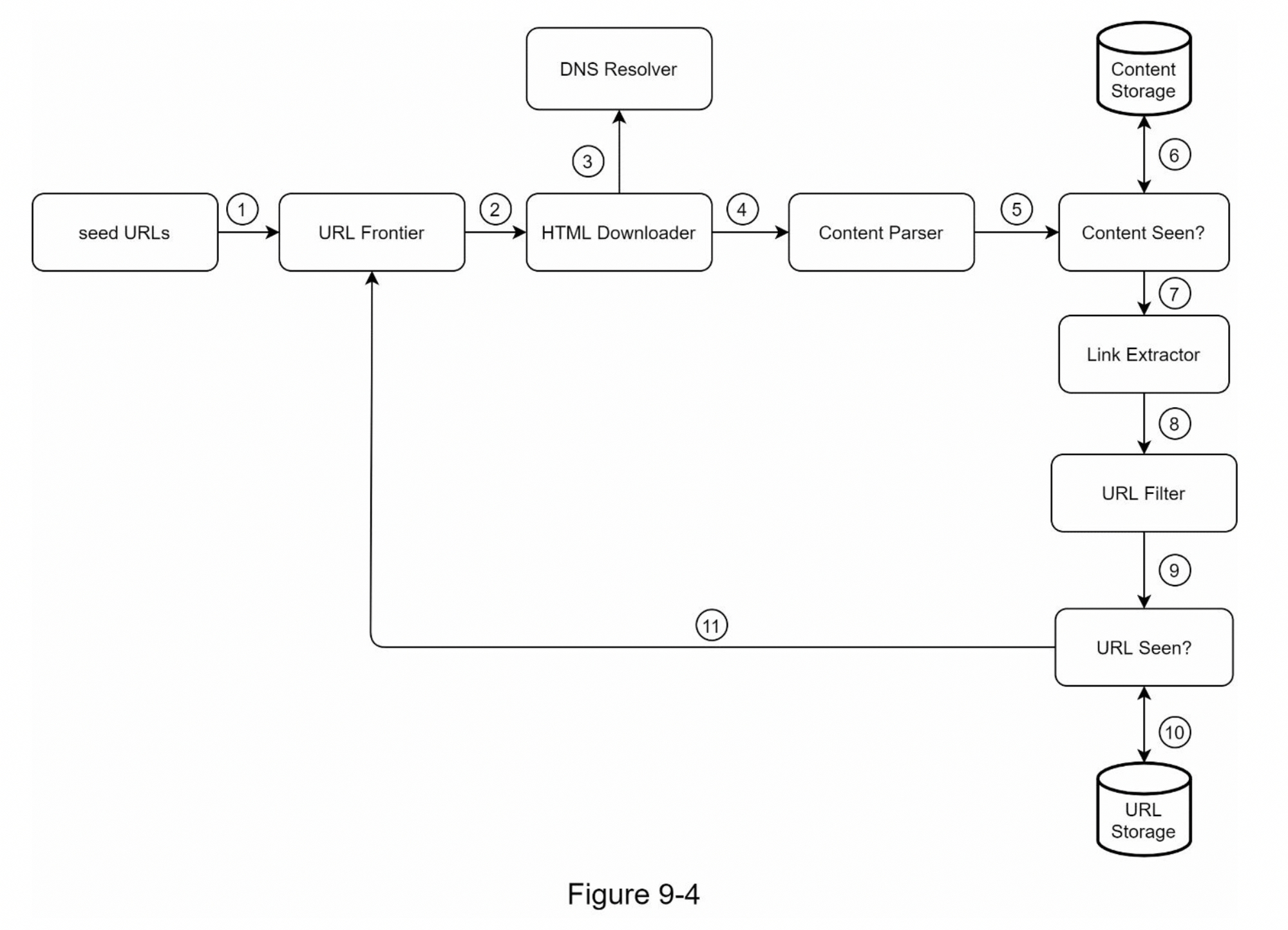
第 1 步:将种子 URL 添加到 URL Frontier
第 2 步:HTML 下载器从 URL Frontier 获取 URL 列表。
第 3 步:HTML 下载器从 DNS 解析器获取 URL 的 IP 地址并开始下载。
第 4 步:Content Parser 解析 HTML 页面并检查页面是否格式错误。
第 5 步:内容经过解析和验证后,传递给“Content Seen?”组件。
第 6 步:“Content Seen”组件检查 HTML 页面是否已在存储中。
- 如果在存储中,这意味着不同URL 中的相同内容已经被处理过。在这种情况下,HTML 页面将被丢弃。
- 如果不在存储中,则系统之前没有处理过相同的内容。内容被传递给链接提取器。
第 7 步:网址提取器从 HTML 页面中提取网址。
第 8 步:将提取的网址传递给 URL 过滤器。
第 9 步:网址过滤后,传递给“URL Seen?”组件。
第 10 步:“URL Seen”组件检查一个URL是否已经在存储中,如果是,则之前处理过,不需要做任何事情。
第 11 步:如果一个 URL 以前没有被处理过,它被添加到 URL Frontier。
第3步:深入设计
到目前为止,我们已经讨论了高层设计。接下来,我们将深入讨论最重要的构建组件和技术:
- 深度优先搜索 (DFS) 与广度优先搜索 (BFS)
- URL Frontier
- HTML Downloader
- 鲁棒性(Robustness)
- 可扩展性(Extensibility)
- 检测并避免有问题的内容
DFS vs BFS
你可以把网络想象成一个有向图,其中网页作为节点,超链接(URL)作为边。抓取过程可以被视为从一个网页到其他网页的有向图的遍历。两种常见的图形遍历算法是DFS和BFS。然而,DFS通常不是一个好的选择,因为DFS的深度可能很深。
BFS 通常被网络爬虫使用,并通过先进先出 (FIFO) 队列实现。在 FIFO 队列中,URL 按照它们入队的顺序出队。但是,这种实现有两个问题:
-
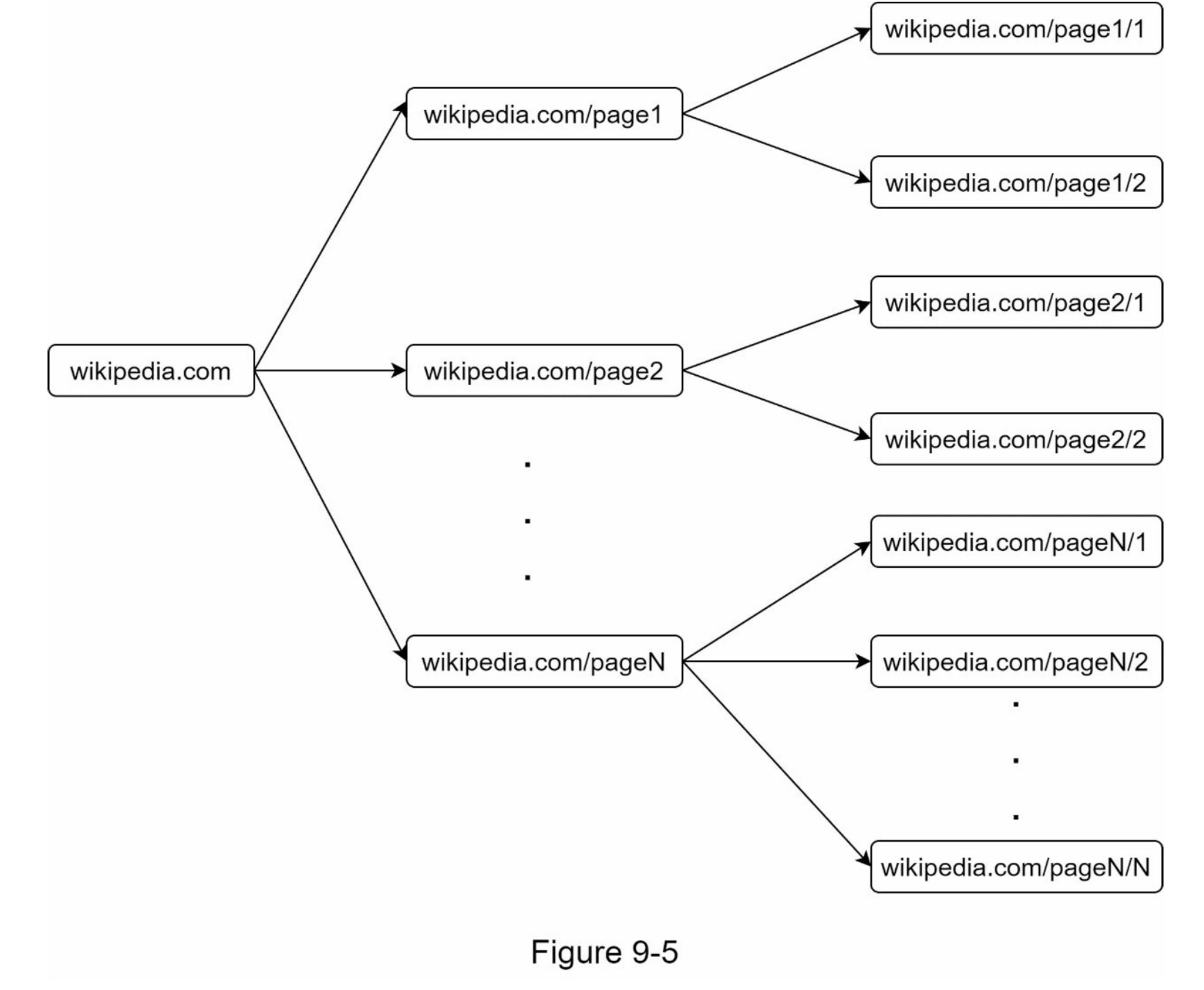
来自同一网页的大多数链接都链接回同一主机。在图 9-5 中,wikipedia.com 中的所有链接都是内部链接,使得爬虫忙于处理来自同一主机(wikipedia.com)的 URL。当爬虫试图并行下载网页时,维基百科服务器将被请求淹没。这被认为是“不礼貌的”
-
标准的BFS没有考虑到一个URL的优先级。网络很大,不是每个页面都有相同的质量和重要性。因此,我们可能希望根据页面排名、网络流量、更新频率等来确定URL的优先级。
URL Frontier
URL Frontier 有助于解决这些问题。 URL Frontier 是一种存储要下载的 URL 的数据结构。 URL Frontier 是确保礼貌、URL 优先级和新鲜度的重要组成部分。参考资料 [5] [9] 中提到了一些关于 URL Frontier 的值得注意的论文。这些论文的研究结果如下:
-
礼貌性
一般来说,网络爬虫应该避免在短时间内向同一个托管服务器发送过多的请求。发送过多请求会被视为“不礼貌”,甚至被视为拒绝服务 (DOS) 攻击。例如,在没有任何限制的情况下,爬虫可以每秒向同一个网站发送数千个请求。这会使 Web 服务器不堪重负。
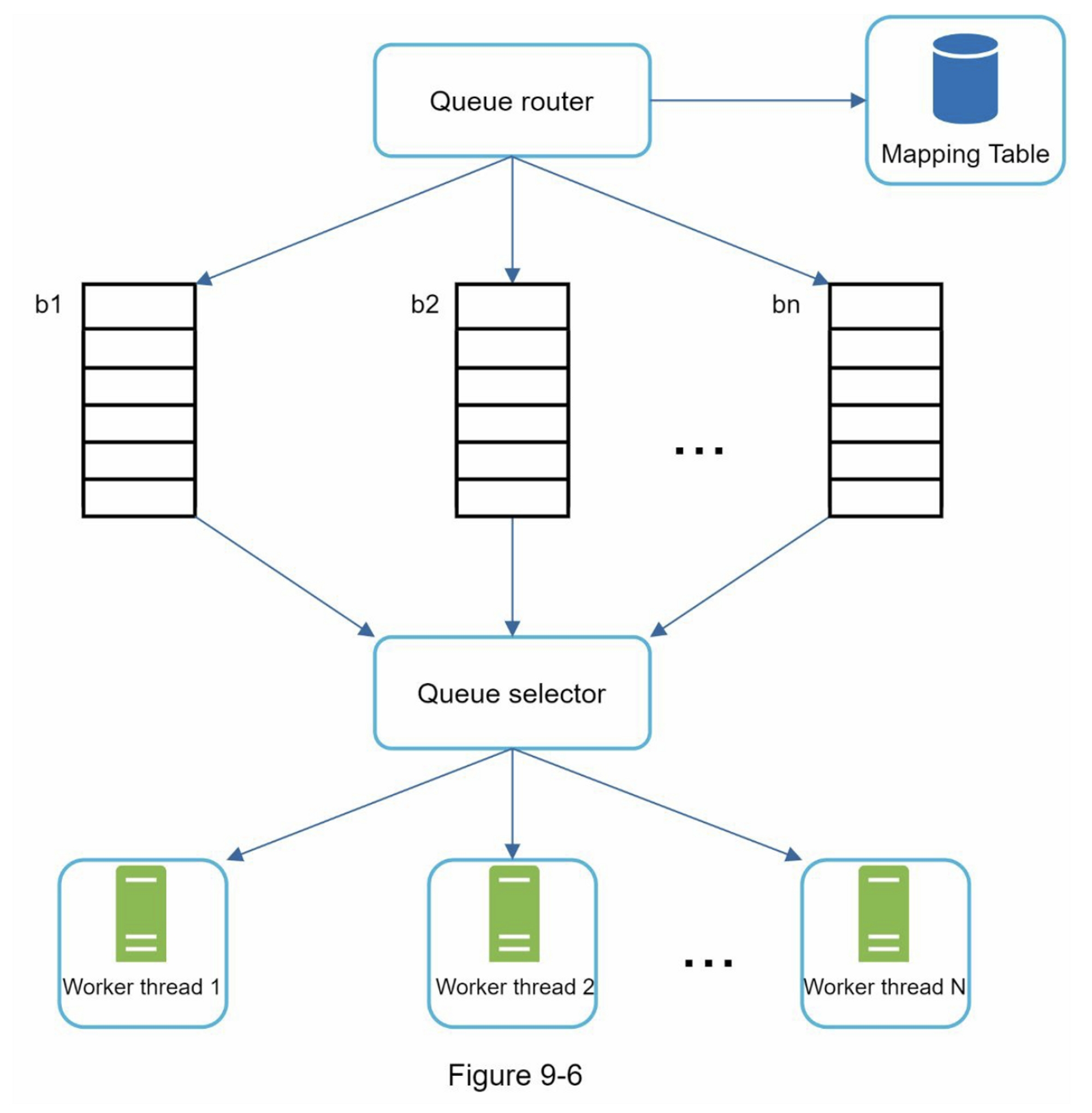
强制礼貌的一般想法是一次从同一主机下载一个页面。可以在两个下载任务之间添加延迟。礼貌约束是通过维护从网站主机名到下载(工作)线程的映射来实现的。每个下载线程都有一个单独的 FIFO 队列,并且只下载从该队列中获得的 URL。图 9-6 显示了管理礼貌的设计。
-
Queue router:它确保每个队列(b1,b2,... bn)仅包含来自同一主机的 URL。
-
Mapping table::它将每个主机映射到一个队列
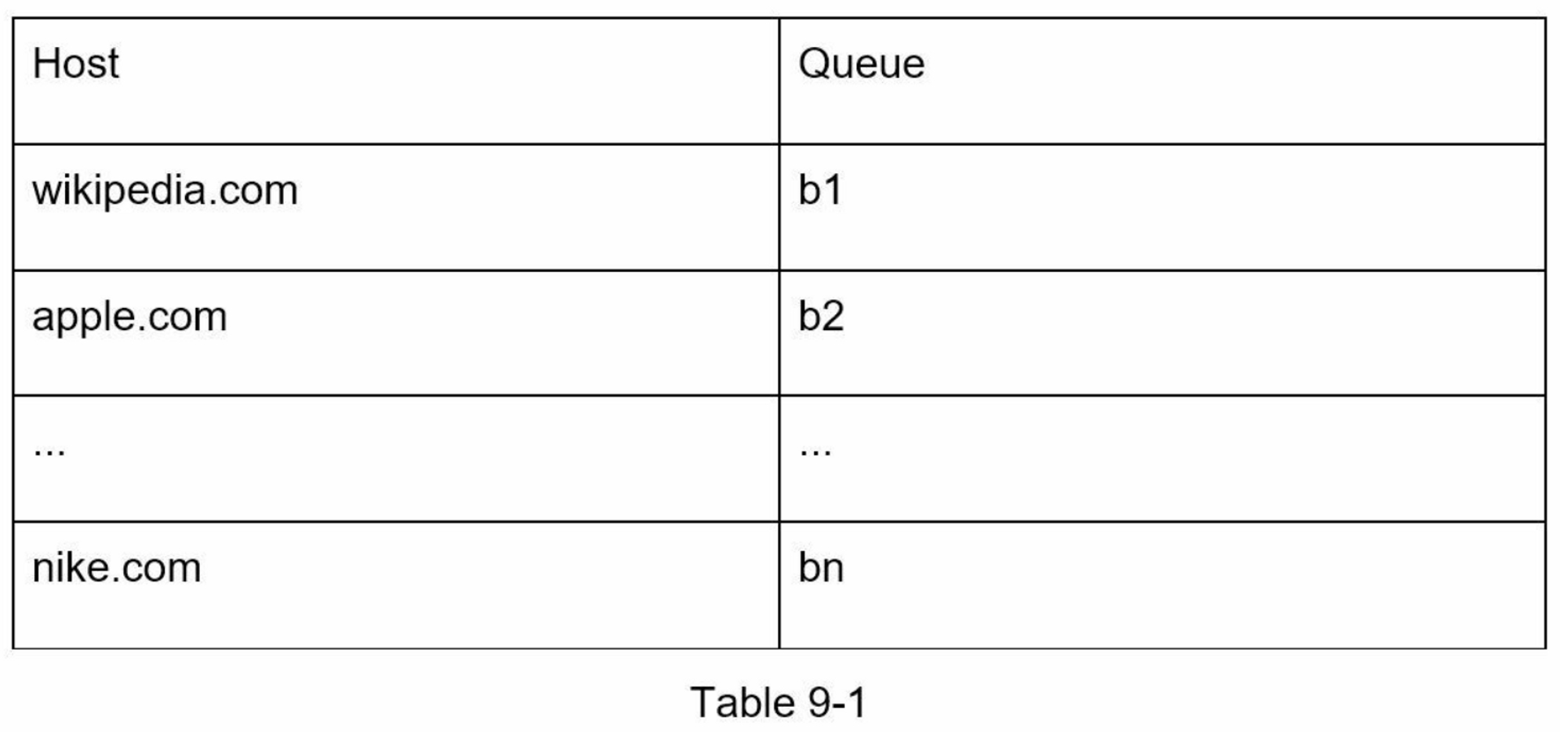
-
FIFO 队列 b1、b2 到 bn:每个队列包含来自同一主机的 URL。
-
Queue selector:每个工作线程都映射到一个 FIFO 队列,它只从该队列下载 URL。队列选择逻辑由Queue selector完成
-
Worker thread 1 t到 N:一个工作线程从同一台主机上一个接一个地下载网页,可以在两个下载任务之间添加延迟。
-
-
优先级
一个关于 Apple 产品的讨论论坛上的随机帖子与苹果主页上的帖子具有非常不同的权重。尽管它们都有 "Apple "这个关键词,但爬虫首先抓取 Apple 主页是明智之举。
我们根据实用性对 URL 进行优先级排序,这可以通过 PageRank [10]、网站流量、更新频率等来衡量。“Prioritizer”是处理 URL 优先级的组件。有关此概念的深入信息,请参阅参考资料 [5] [10]。
图 9-7 显示了管理 URL 优先级的设计。
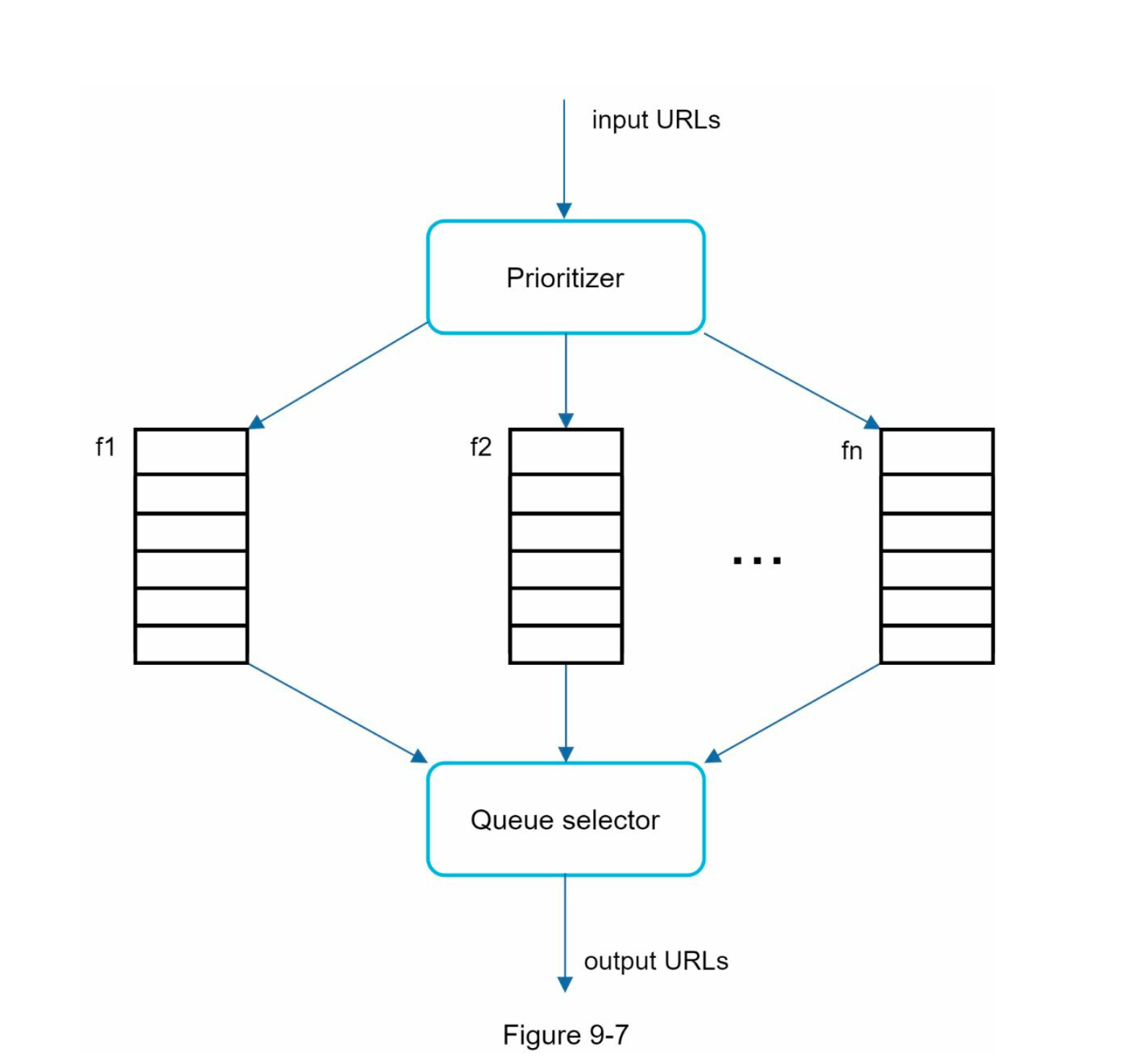
- Prioritizer:它将 URL 作为输入并计算优先级。 •
- Queue f1 到 fn::每个队列都有一个分配的优先级。优先级高的队列被选中的概率更高。
- Queue selector:随机选择一个偏向于具有更高优先级的队列
图 9-8 展示了 URL frontier 设计,它包含两个模块:
- 前端队列:管理优先级
- 后端队列:管理礼貌
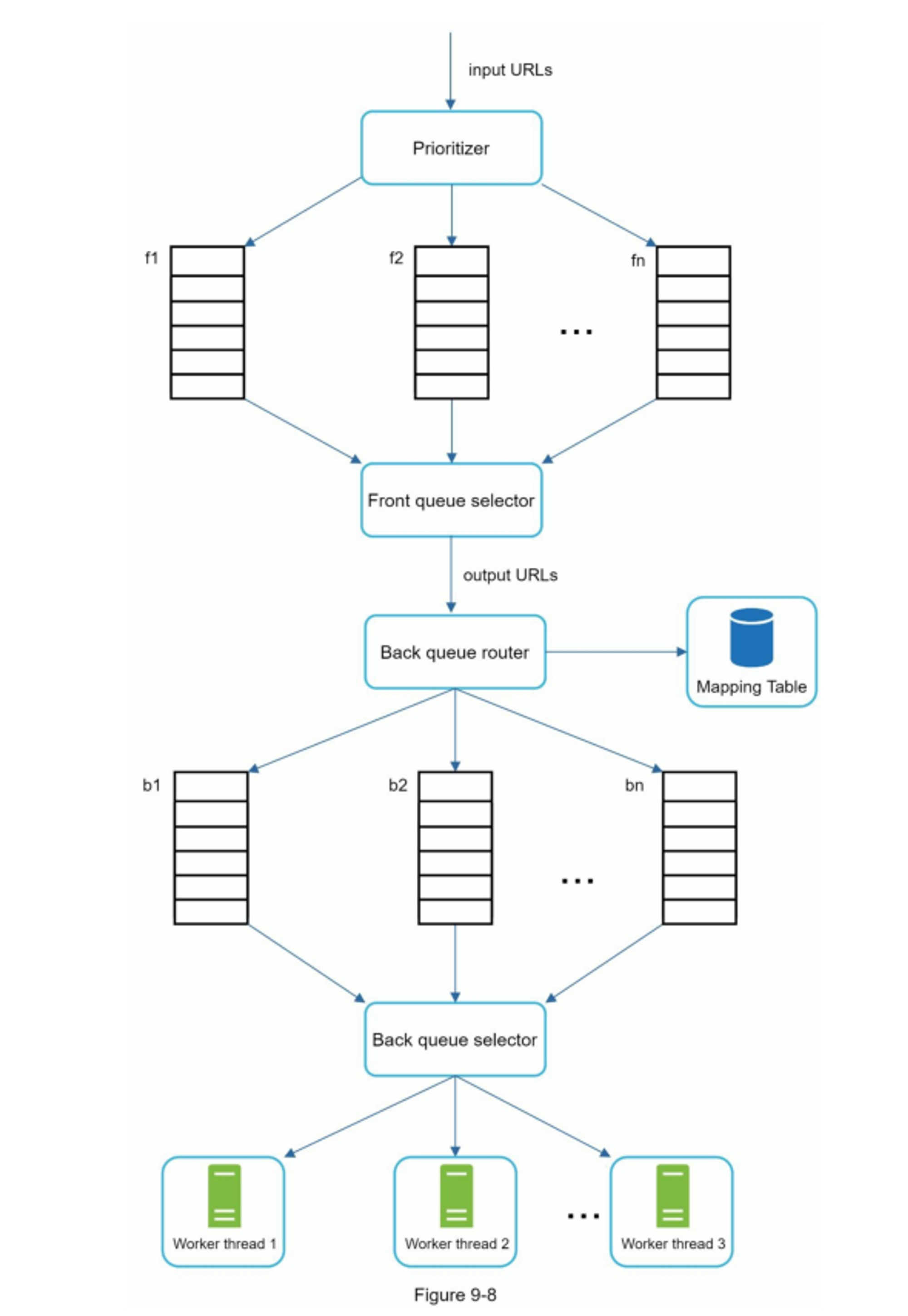
-
新鲜度
网页不断被添加、删除和编辑。网络爬虫必须定期重新抓取下载的页面以保持我们的数据集最新。重新抓取所有 URL 既耗时又耗费资源。下面列出了几种优化新鲜度的策略:
- 根据网页的更新历史重新抓取。
- 对URL进行优先排序,优先和频繁地重新抓取重要页面。
-
URL Frontier 存储
在搜索引擎的真实世界抓取中,frontier 的 URL 数量可能达到数亿 [4]。将所有内容都放在内存中既不耐用也不可扩展。将所有内容都保存在磁盘中是不可取的,因为磁盘很慢;它很容易成为抓取的瓶颈。我们采用了混合方法。大多数 URL 都存储在磁盘上,因此存储空间不是问题。为了降低从磁盘读取和写入磁盘的成本,我们在内存中维护缓冲区以进行入队/出队操作。缓冲区中的数据会定期写入磁盘。
HTML 下载器
HTML下载器使用HTTP协议从互联网上下载网页。在讨论HTML下载器之前,我们先看一下Robots排除协议。
Robots.txt
Robots.txt,称为Robots排除协议,是网站用来与爬虫沟通的标准。它规定了爬虫可以下载哪些页面。在尝试爬行一个网站之前,爬虫应首先检查其相应的robots.txt,并遵守其规则。为了避免重复下载 robots.txt 文件,我们对该文件的结果进行了缓存。该文件会定期下载并保存到缓存中。下面是取自https://www.amazon.com/robots.txt 的robots.txt文件的一个片段。一些目录,如creatorhub,是不允许谷歌机器人访问的。
User-agent: Googlebot
Disallow: /creatorhub/*
Disallow: /rss/people/*/reviews
Disallow: /gp/pdp/rss/*/reviews
Disallow: /gp/cdp/member-reviews/
Disallow: /gp/aw/cr/
除了 robots.txt,性能优化是我们将为HTML下载器介绍的另一个重要概念。
性能优化
以下是HTML下载器的性能优化列表.
-
分布式抓取
为了实现高性能,抓取工作被分配到多个服务器,每个服务器运行多个线程。URL空间被分割成更小的部分;因此,每个下载器负责URL的一个子集。图9-9显示了一个分布式抓取的例子。
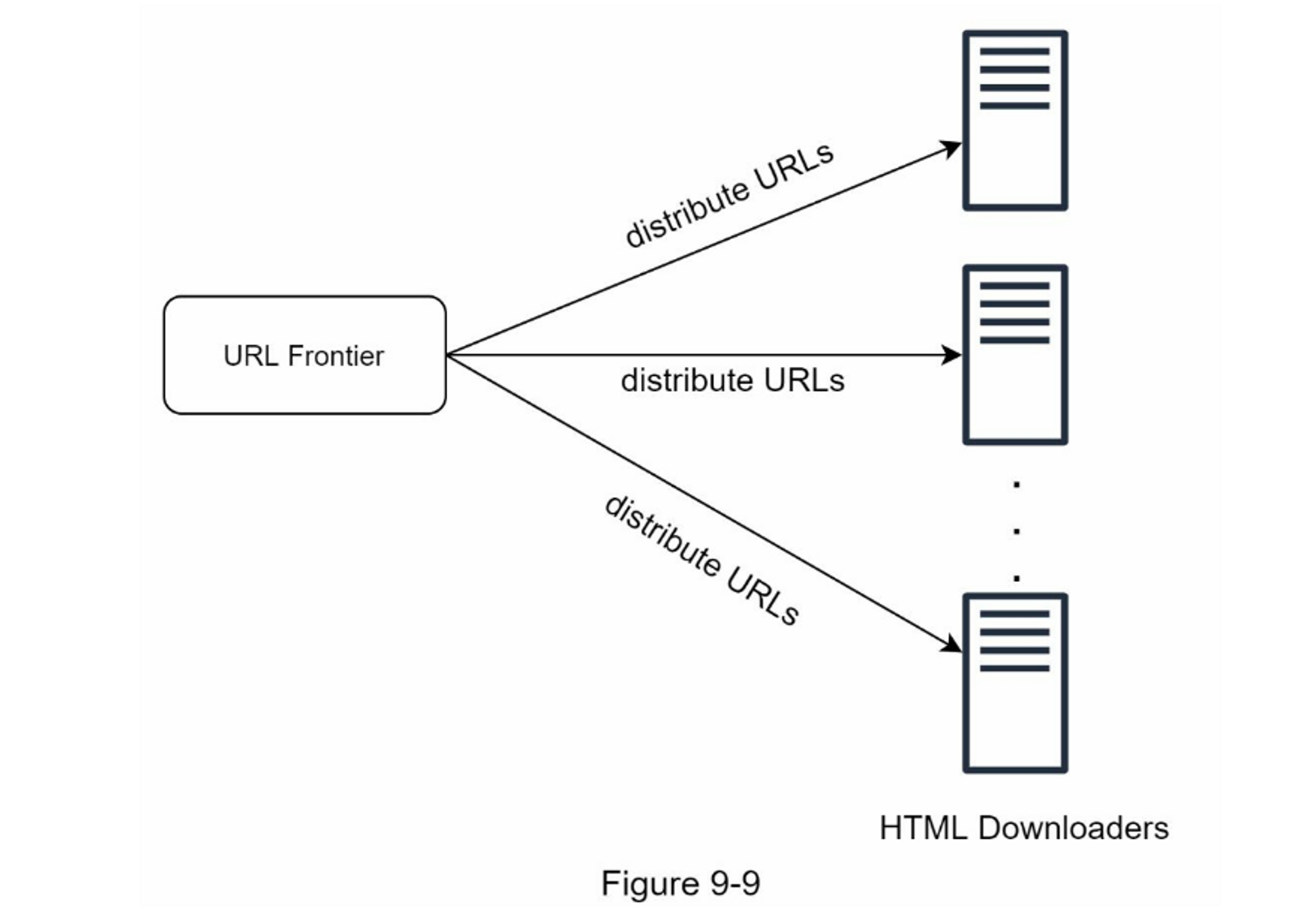
-
缓存DNS解析器
DNS解析器是爬虫的一个瓶颈,因为由于许多DNS接口的同步性,DNS请求可能需要时间。DNS响应时间从10ms到200ms不等。一旦爬虫线程对DNS进行了请求,其他线程就会被阻断,直到第一个请求完成。维护我们的DNS缓存以避免频繁调用DNS是一种有效的速度优化技术。我们的DNS缓存保持域名到IP地址的映射,并通过cron作业定期更新。
-
位置
按地理分布抓取服务器。当爬行服务器离网站主机较近时,爬行者会体验到更快的下载时间。设计定位适用于大多数系统组件:抓取服务器、缓存、队列、存储等。
-
短暂的超时
有些网络服务器响应缓慢,或者根本不响应。为了避免漫长的等待时间,指定了一个最大的等待时间。如果一个主机在预定的时间内没有反应,爬虫将停止工作并抓取一些其他的网页。
鲁棒性
除了性能优化,鲁棒性也是一个重要的考虑因素。我们提出了一些提高系统鲁棒性的方法。
- 一致性哈希:这有助于在下载者之间分配负载。 可以使用一致性哈希添加或删除新的下载服务器。 有关详细信息,请参阅第 5 章:设计一致性哈希。
- 保存爬行状态和数据:为了防止失败,爬行状态和数据被写入存储系统。 通过加载保存的状态和数据,可以轻松地重新启动中断的爬网。
- 异常处理:错误在大型系统中是不可避免的,也是常见的。 爬虫必须在不使系统崩溃的情况下优雅地处理异常。
- 数据校验:这是防止系统出错的重要措施。
可扩展性(Extensibility)
差不多每个系统都在不断发展,设计目标之一是使系统足够灵活,以支持新的内容类型。抓取器可以通过插入新的模块来扩展。图9-10显示了如何添加新模块。
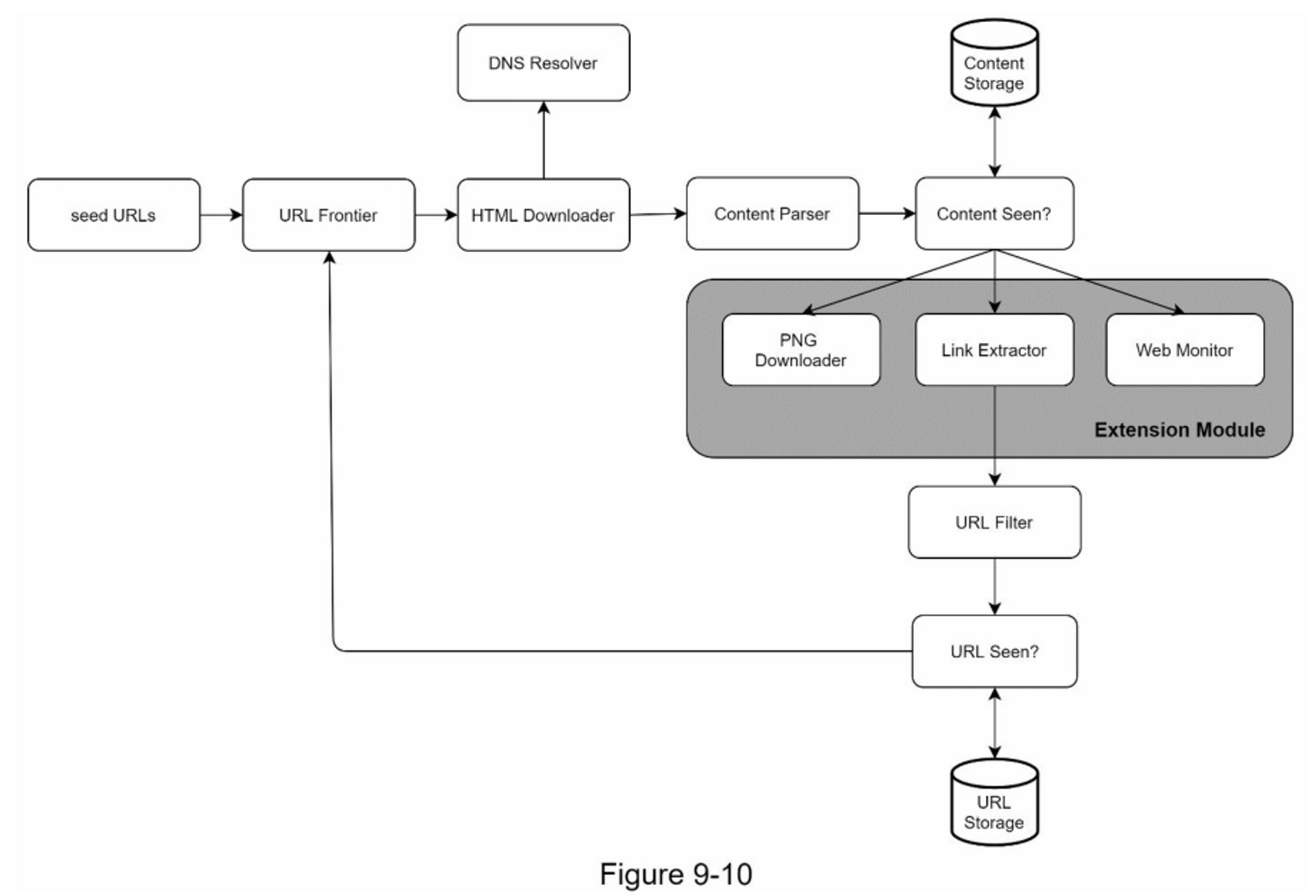
- PNG下载器模块是用于下载PNG文件的插件。
- 增加了网络监控模块,以监控网络并防止版权和商标侵权。
检测并避免有问题的内容
本节讨论冗余、无意义或有害内容的检测和预防。
-
冗余内容
如前所述,近30%的网页是重复的。哈希值或校验和有助于检测重复[11]。
-
搜索引擎蜘蛛陷阱
搜索引擎蜘蛛陷阱是导致爬虫陷入无限循环的网页。 例如,一个无限深的目录结构如下:
http://www.spidertrapexample.com/foo/bar/foo/bar/foo/bar/...可以通过设置 URL 的最大长度来避免此类蜘蛛陷阱。但是,不存在检测蜘蛛陷阱的万能解决方案。 包含蜘蛛陷阱的网站很容易识别,因为在此类网站上发现的网页数量异常多。 很难开发自动算法来避免蜘蛛陷阱; 但是,用户可以手动验证和识别蜘蛛陷阱,并从爬虫中排除这些网站或应用一些自定义的 URL 过滤器。 -
垃圾数据
有些内容价值很小或没有价值,例如广告、代码片段、垃圾邮件 URL 等。这些内容对爬虫没有用,应尽可能排除。
第4步:总结
在本章中,我们首先讨论了一个好的爬虫的特征:可伸缩性、礼貌性、可扩展性和健壮性。 然后,我们提出了设计方案并讨论了关键组件。 构建可扩展的网络爬虫并不是一项简单的任务,因为网络非常庞大且充满陷阱。 即使我们涵盖了所有主题,我们仍然遗漏了许多相关的讨论要点:
- 服务器端渲染:众多的网站使用JavaScript、AJAX等脚本来即时生成链接。如果我们直接下载并解析网页,我们将无法检索到动态生成的链接。为了解决这个问题,我们在解析网页之前先进行服务器端的渲染(也叫动态渲染)[12]。
- 过滤不需要的页面:有限的存储容量和抓取资源,反垃圾信息组件有利于过滤掉低质量和垃圾页面 [13] [14]。
- 数据库复制和分片:复制和分片等技术用于提高数据层的可用性、可扩展性和可靠性。
- 水平扩展:对于大规模爬取,需要数百甚至数千台服务器来执行下载任务。 关键是保持服务器无状态。
- 可用性、一致性和可靠性。这些概念是任何大型系统成功的核心。我们在第1章中详细讨论了这些概念。重温一下你对这些主题的记忆。
- 分析:收集和分析数据是任何系统的重要组成部分,因为数据是微调的关键要素。
恭喜你走到了这一步!现在给自己一个鼓励,干得漂亮!
参考资料
- [1] US Library of Congress: https://www.loc.gov/websites/
- [2] EU Web Archive: http://data.europa.eu/webarchive
- [3] Digimarc: https://www.digimarc.com/products/digimarc-services/piracy-intelligence
- [4] Heydon A., Najork M. Mercator: A scalable, extensible web crawler World Wide Web, 2 (4) (1999), pp. 219-229
- [5] By Christopher Olston, Marc Najork: Web Crawling. http://infolab.stanford.edu/~olston/publications/crawling_survey.pdf
- [6] 29% Of Sites Face Duplicate Content Issues: https://tinyurl.com/y6tmh55y
- [7] Rabin M.O., et al. Fingerprinting by random polynomials Center for Research in Computing Techn., Aiken Computation Laboratory, Univ. (1981)
- [8] B. H. Bloom, “Space/time trade-offs in hash coding with allowable errors,” Communications of the ACM, vol. 13, no. 7, pp. 422–426, 1970.
- [9] Donald J. Patterson, Web Crawling: https://www.ics.uci.edu/~lopes/teaching/cs221W12/slides/Lecture05.pdf
- [10] L. Page, S. Brin, R. Motwani, and T. Winograd, “The PageRank citation ranking: Bringing order to the web,” Technical Report, Stanford University, 1998.
- [11] Burton Bloom. Space/time trade-offs in hash coding with allowable errors. Communications of the ACM, 13(7), pages 422--426, July 1970.
- [12] Google Dynamic Rendering: https://developers.google.com/search/docs/guides/dynamic-rendering
- [13] T. Urvoy, T. Lavergne, and P. Filoche, “Tracking web spam with hidden style similarity,” in Proceedings of the 2nd International Workshop on Adversarial Information Retrieval on the Web, 2006.
- [14] H.-T. Lee, D. Leonard, X. Wang, and D. Loguinov, “IRLbot: Scaling to 6 billion pages and beyond,” in Proceedings of the 17th International World Wide Web Conference, 2008.
第10章:设计一个通知系统
近年来,通知系统已经成为许多应用程序非常流行的功能。 通知提醒用户重要信息,如突发新闻、产品更新、活动、优惠等。它已成为我们日常生活中不可或缺的一部分。 在本章中,您需要设计一个通知系统。
通知不仅仅是移动推送通知,三种类型的通知格式:移动推送通知、短信和电子邮件。 图 10-1 显示了每个通知的示例。
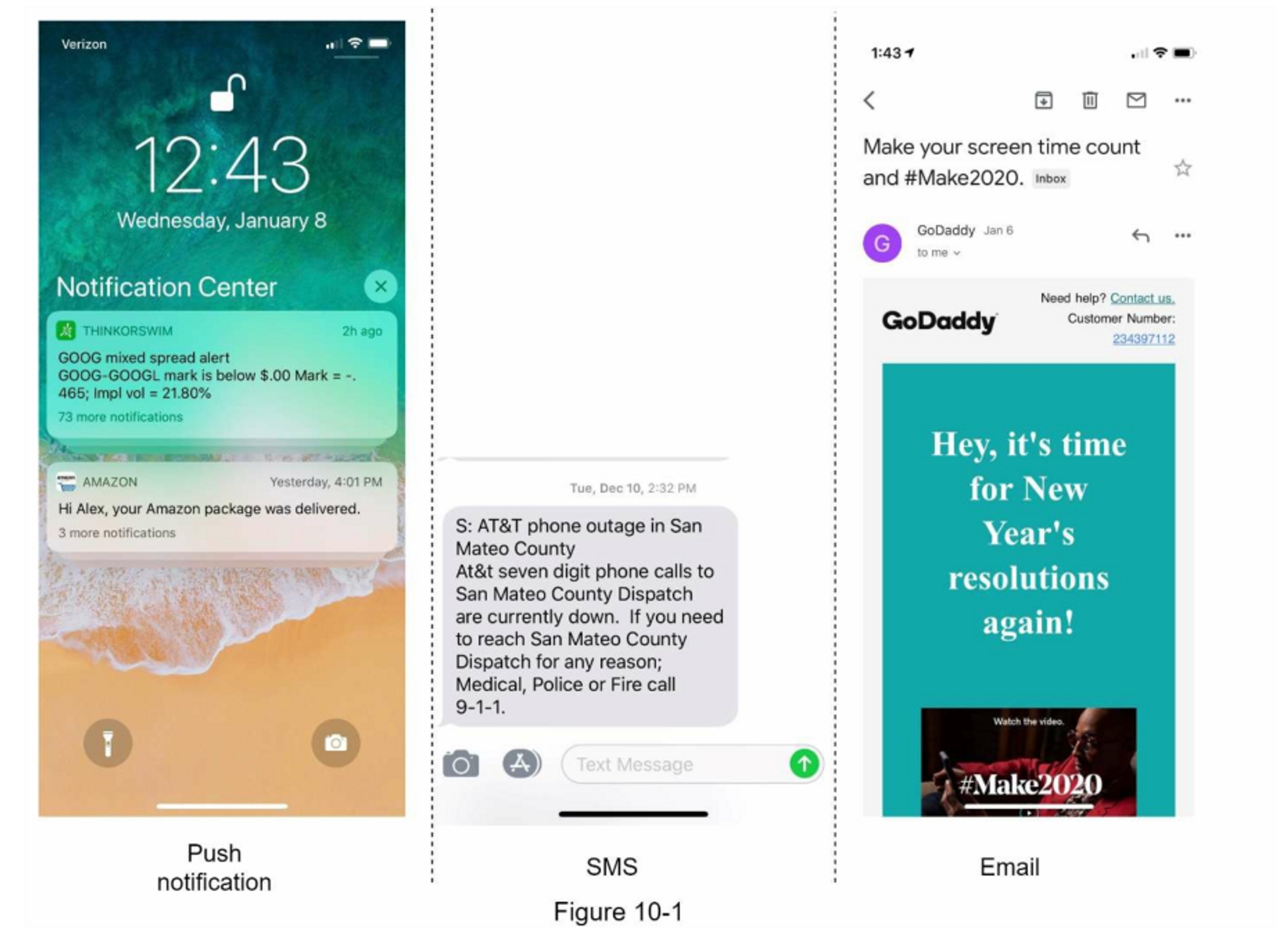
第1步:了解问题并确定设计范围
构建一个每天发送数百万条通知的可扩展系统并非易事。 它需要对通知生态系统有深入的了解。 面试问题特意设计为开放式和模棱两可的,你有责任提出问题以明确要求。
候选人:系统支持哪些类型的通知? 面试官:推送通知、短信、邮件。
候选人:它是一个实时的系统吗?
采访者。让我们说这是一个软实时系统。我们希望用户能尽快收到通知。但是,如果系统处于高负荷工作状态,稍有延迟也是可以接受的。
候选人:支持的设备有哪些?
面试官:iOS设备、安卓设备和笔记本电脑/台式机。
候选人:什么触发通知?
面试官:通知可以由客户端应用程序触发。 他们也可以由服务器端调度。
候选人:用户是否能够选择退出?
面试官:是的,选择退出的用户将不再收到通知。
候选人:每天发出多少份通知?
面试官:1000万条移动推送通知,100万条短信,500万封电子邮件。
第2步:提出高层次的设计方案并获得认同
本节展示了支持各种通知类型的高层设计:iOS推送通知、Android推送通知、短信和电子邮件。它的结构如下:
- 不同的通知类型
- 联系人信息收集流程
- 通知发送/接收流程
不同的通知类型
我们先看一下每种通知类型在高层次上是如何工作的。
iOS推送通知
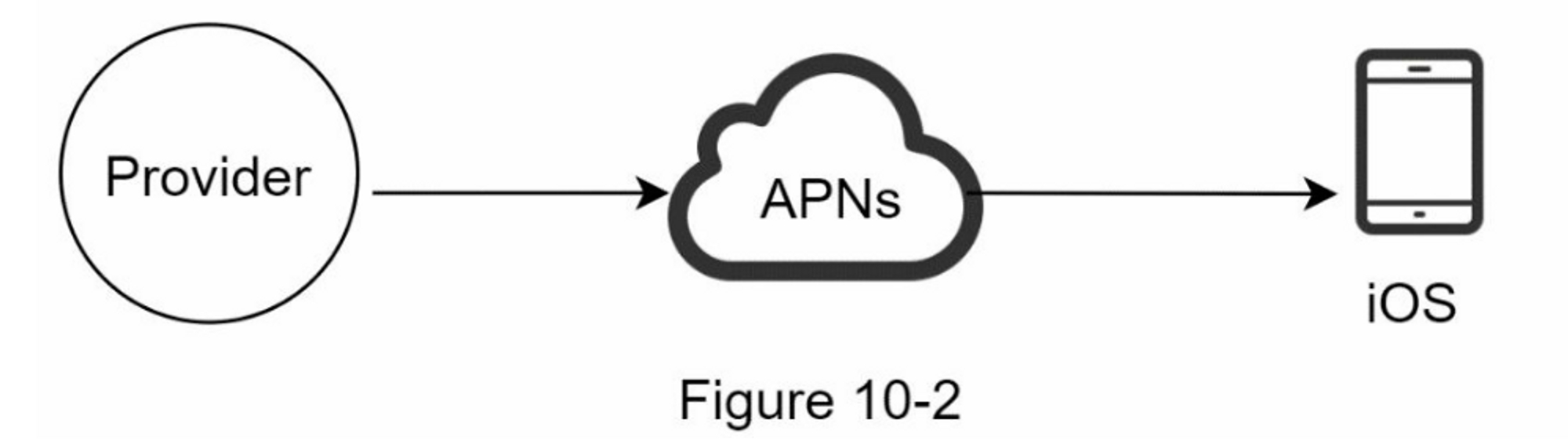
我们主要需要三个组件来发送 iOS 推送通知:
- Provider(提供商):提供商构建通知请求并将其发送到 Apple 推送通知服务 (APNS)。 要构建推送通知,提供者提供以下数据:
-
设备 token:这是用于发送推送通知的唯一标识符。
-
有效载荷:是一个包含通知有效载荷的 JSON 字典。 例子:
{ "aps": { "alert": { "title": "Game Request", "body": "Bob wants to play chess", "action-loc-key": "PLAY" }, "badge": 5 } }
-
- 苹果推送通知服务(APNS): 这是 Apple 提供的远程服务,用于将推送通知传播到 iOS 设备。
- iOS 设备:它是接收推送通知的终端客户端。
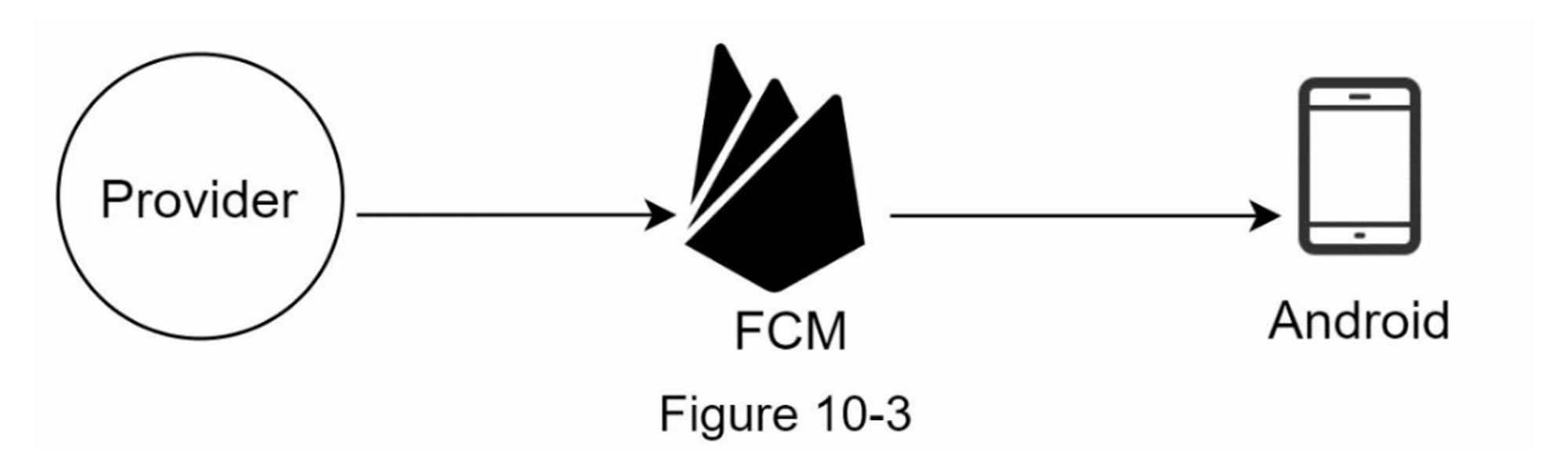
Android推送通知
Android 采用了类似的通知流程。 Firebase Cloud Messaging (FCM) 通常用于向 Android 设备发送推送通知,而不是使用 APN。
短信
对于SMS信息,通常使用第三方SMS服务,如Twilio[1]、Nexmo[2]和其他许多服务。它们中的大多数是商业服务。
邮件
虽然公司可以设置自己的电子邮件服务器,但其中许多公司选择商业电子邮件服务。 Sendgrid [3] 和 Mailchimp [4] 是最受欢迎的电子邮件服务之一,它们提供更好的交付率和数据分析。
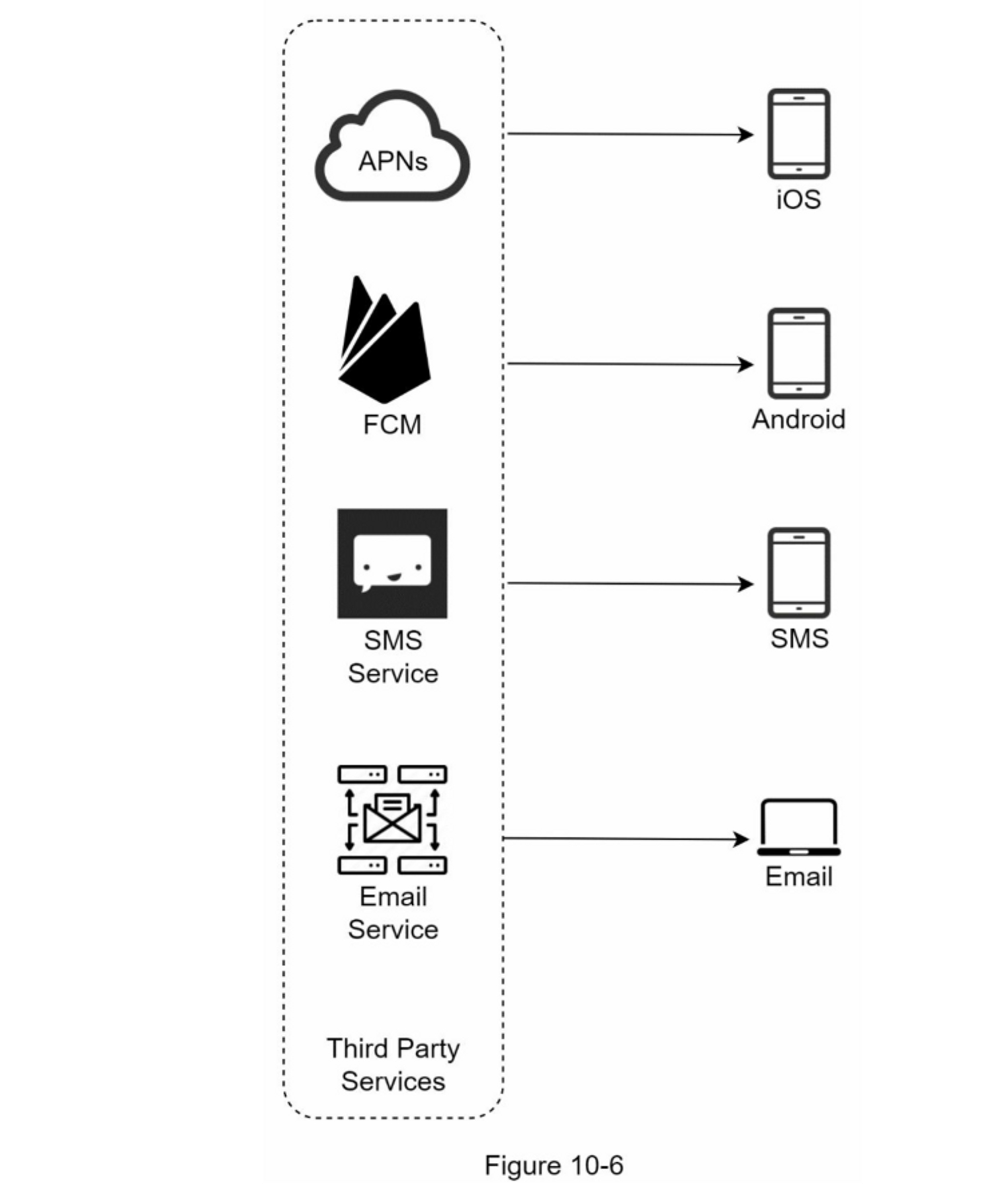
图 10-6 显示了包含所有第三方服务后的设计。
联系人信息收集流程
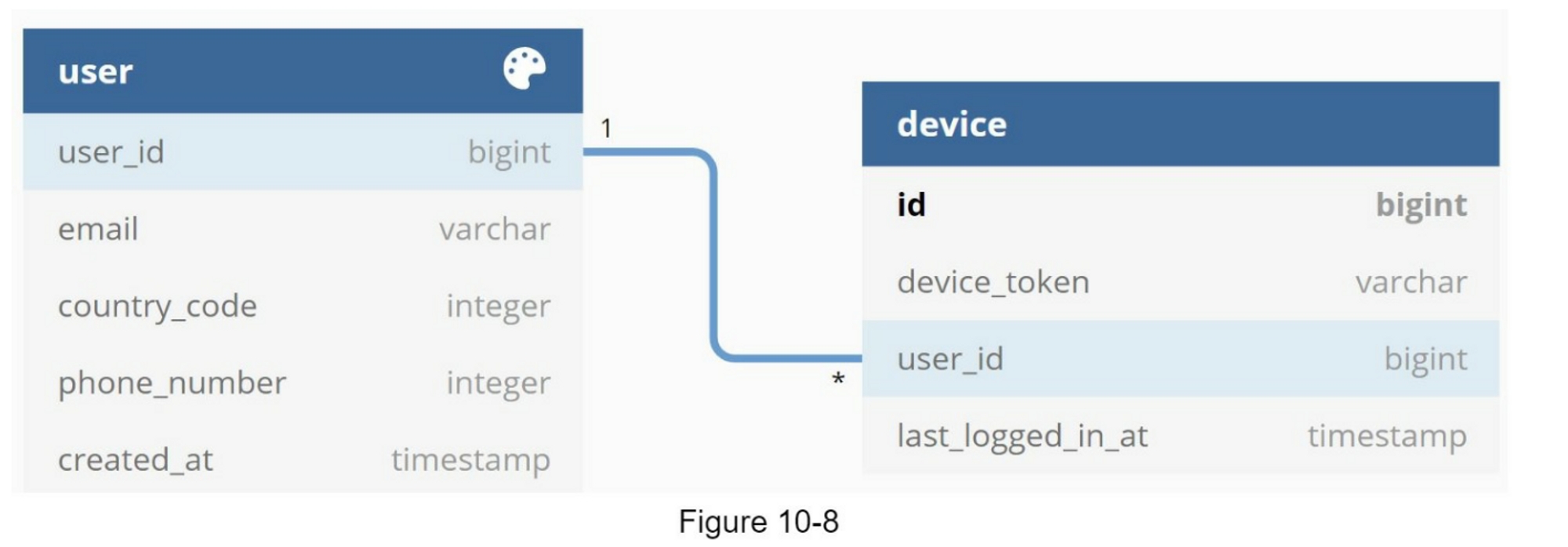
要发送通知,我们需要收集移动设备令牌、电话号码或电子邮件地址。 如图 10-7 所示,当用户安装我们的应用程序或首次注册时,API 服务器会收集用户联系信息并将其存储在数据库中。
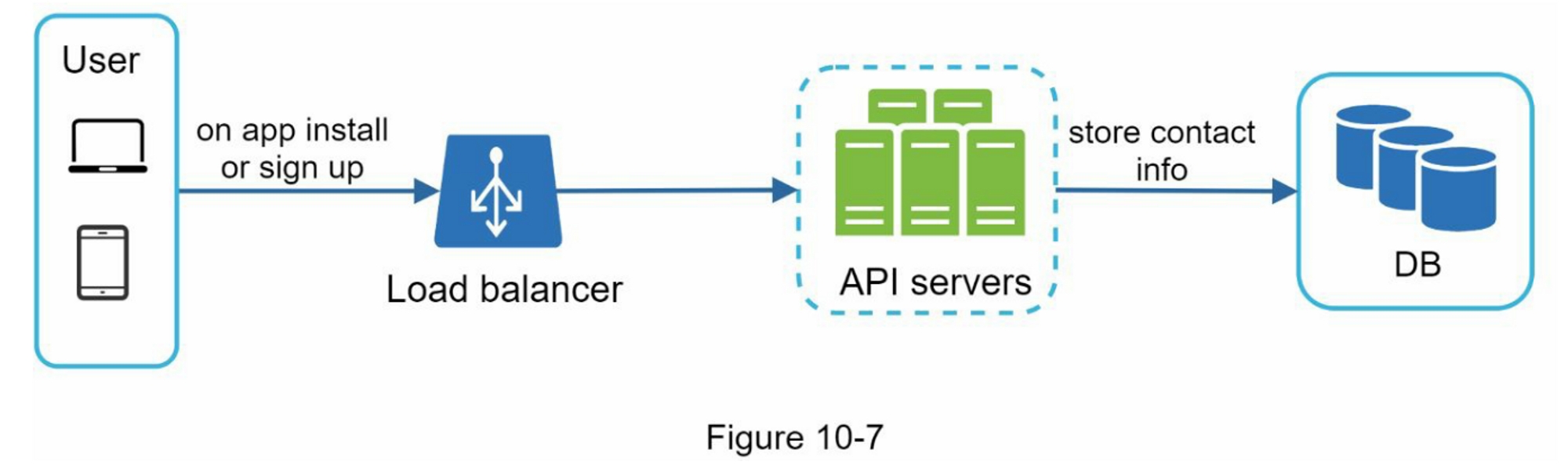
图10-8显示了存储联系人信息的简化数据库表。电子邮件地址和电话号码存储在用户表中,而设备令牌则存储在设备表中。一个用户可以有多个设备,表明推送通知可以被发送到所有的用户设备上。
通知发送/接收流程
我们将首先介绍初始设计;然后,提出了一些优化方案。
高层设计
图 10-9 显示了设计,下面解释了每个系统组件。
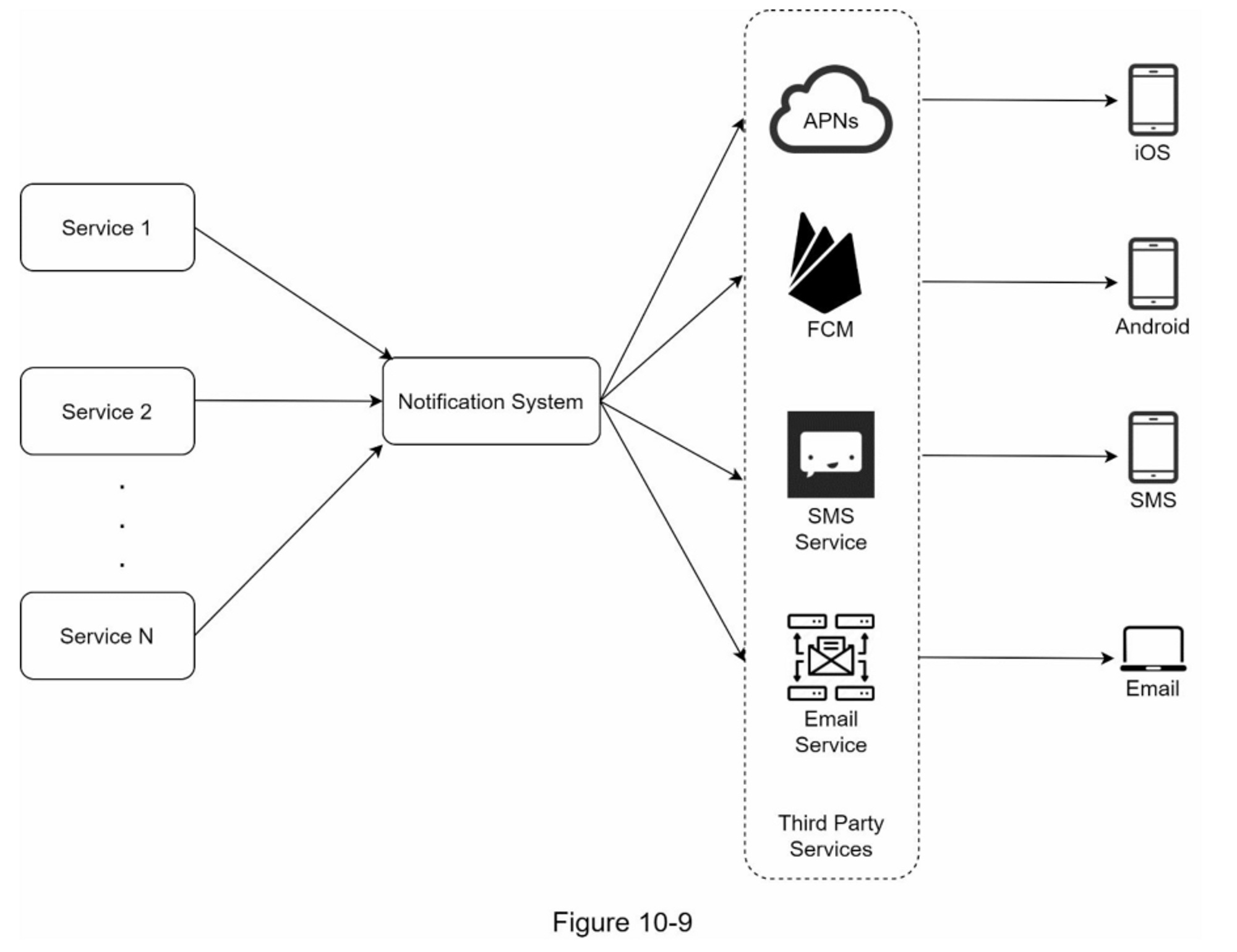
服务1到N:一个服务可以是一个微服务,一个cron job,或者一个触发通知发送事件的分布式系统。例如,一个计费服务发送电子邮件提醒客户到期付款,或者一个购物网站通过短信告诉客户他们的包裹明天会被送到。
通知系统:通知系统是发送/接收通知的中心环节。从简单的东西开始,只使用一个通知服务器。它为服务1到N提供API,并为第三方服务建立通知有效载荷。
第三方服务:第三方服务负责向用户发送通知。在与第三方服务集成时,我们需要特别注意可扩展性。良好的可扩展性意味着一个灵活的系统可以很容易地插入或拔出第三方服务。另一个重要的考虑因素是,第三方服务可能在新的市场或在未来无法使用。例如,FCM在中国是不可用的。因此,在那里使用替代的第三方服务,如Jpush、PushY等。
iOS, Android, SMS, Email:用户在其设备上收到通知。
在这个设计中,发现了三个问题:
- 单点故障(SPOF):单一通知服务器意味着SPOF。
- 难以扩展:通知系统在一台服务器上处理所有与推送通知有关的事情。要独立扩展数据库、缓存和不同的通知处理组件是很有挑战性的。
- 性能瓶颈:处理和发送通知可能是资源密集型的。例如,构建HTML页面和等待第三方服务的响应可能需要时间。在一个系统中处理所有事情可能会导致系统过载,尤其是在高峰期。
高层设计(改进后的)
在列举了初始设计中的挑战后,我们对设计进行了如下改进:
- 将数据库和缓存从通知服务器中移出
- 添加更多的通知服务器,并设置自动水平缩放功能
- 引入消息队列,使系统组件解耦
图10-10显示了改进后的高层设计。
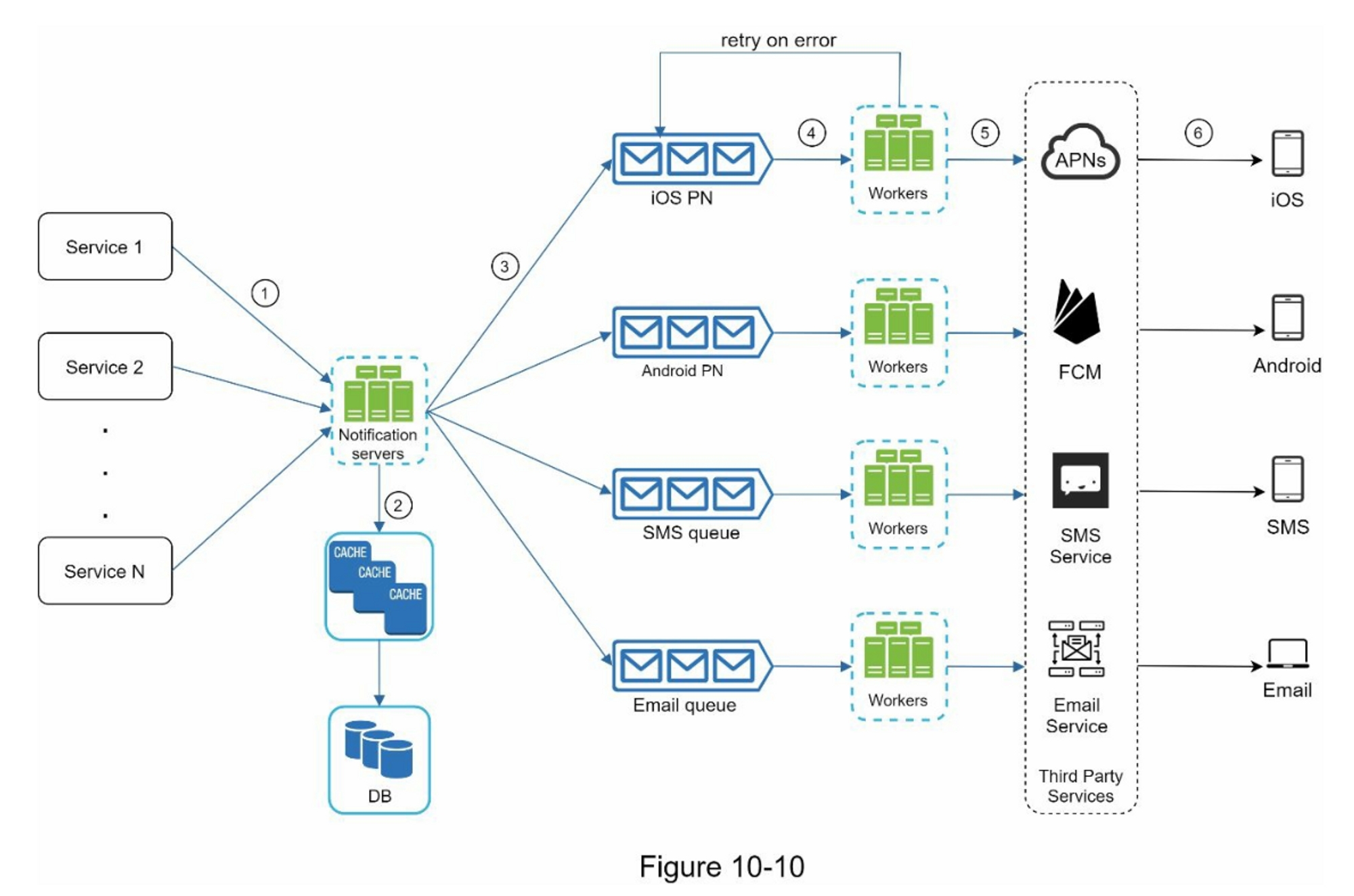
浏览上图的最佳方式是从左到右。
- 服务1到N:它们代表不同的服务,通过通知服务器提供的API发送通知。
- 通知服务器: 它们提供以下功能:
-
为服务提供发送通知的API。这些API只能由内部或经过验证的客户访问,以防止垃圾邮件。
-
进行基本验证,以核实电子邮件、电话号码等。
-
查询数据库或缓存以获取渲染通知所需的数据。
-
将通知数据放到消息队列中进行并行处理。
下面是一个发送电子邮件的API的例子:
POST https://api.example.com/v/sms/send
Request body:

-
- 缓存:用户信息、设备信息、通知模板都被缓存了。
- 数据库:它存储了关于用户、通知、设置等方面的数据。
- 消息队列:它们消除了组件之间的依赖性。当大量的通知被发送出去时,消息队列可以作为缓冲区。每种通知类型都被分配了一个不同的消息队列,所以一个第三方服务的中断不会影响其他通知类型。
- Workers:Workers 是一组服务器,它们从消息队列中拉取通知事件并将它们发送到相应的第三方服务。
- 第三方服务:在最初的设计中已经解释过。
- iOS, Android, SMS, Email:在最初的设计中已经说明。
接下来,让我们来看看每个组件是如何一起工作来发送通知的。
- 一个服务调用通知服务器提供的API来发送通知
- 通知服务器从缓存或数据库中获取元数据,如用户信息、设备令牌和通知设置。
- 一个通知事件被发送到相应的队列进行处理。例如,一个iOS推送通知事件被发送到iOS PN队列中。
- 工作者从消息队列中获取通知事件。
- 工作者向第三方服务发送通知。
- 第三方服务向用户设备发送通知。
第3步:深入设计
在高层设计中,我们讨论了不同类型的通知、联系信息收集流程和通知发送/接收流程。我们将深入探讨以下内容。
- 可靠性(Reliability)
- 其他组件和考虑因素:通知模板、通知设置、速率限制、重试机制、推送通知的安全性、监控排队通知和事件跟踪。
- 更新后的设计
可靠性
在分布式环境中设计通知系统时,我们必须回答几个重要的可靠性问题。
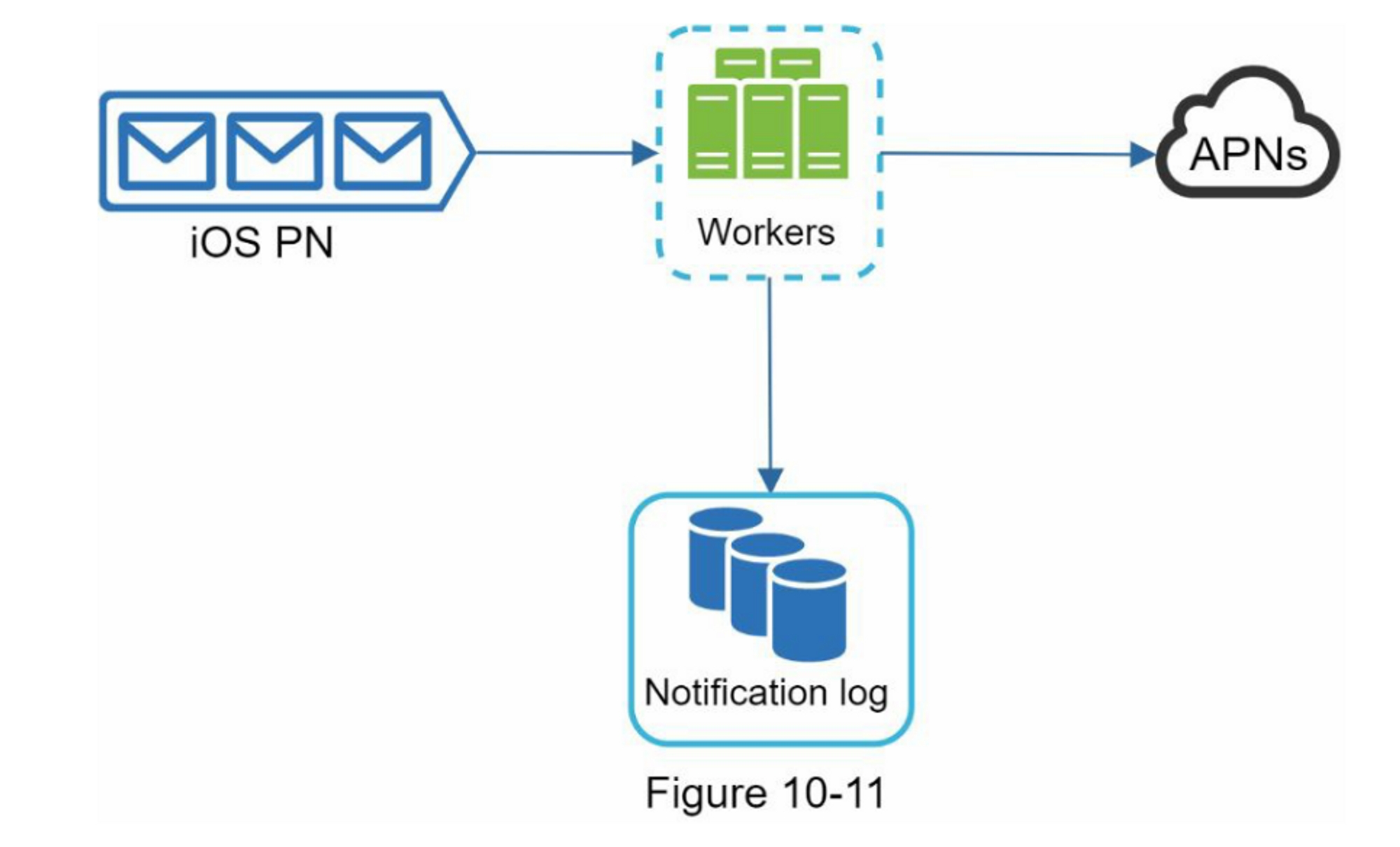
如何防止数据丢失?
通知系统最重要的要求之一是它不能丢失数据。 通知通常可以延迟或重新排序,但绝不会丢失。 为了满足这个需求,通知系统将通知数据持久化到数据库中,并实现了重试机制。 包含通知日志数据库以实现数据持久化,如图 10-11 所示。
接受者只会收到一次通知吗?
最简洁的答案是不。 尽管大多数时候通知只发送一次,但分布式特性可能会导致重复通知。 为了减少重复的发生,我们引入了重复数据删除机制并仔细处理每个失败案例。 这是一个简单的重复数据删除逻辑:
当一个通知事件第一次到达时,我们通过检查事件的ID来检查它是否在之前出现过。如果在之前出现过,它将被丢弃。否则,我们将发送通知。有兴趣的读者可以研究一下为什么我们不能仅一次发送,请参考参考资料[5]。
其他组件和考虑因素
我们已经讨论了如何收集用户的联系信息,发送和接收通知。一个通知系统远不止这些。在这里,我们讨论了额外的组件,包括模板重复使用、通知设置、事件跟踪、系统监控、速率限制等。
-
通知模板
一个大型的通知系统每天会发出数百万条通知,其中许多通知都遵循类似的格式。通知模板的引入是为了避免从头开始建立每一个通知。通知模板是一个预先格式化的通知,通过自定义参数、样式、跟踪链接等来创建你独特的通知。下面是一个推送通知的例子模板。
BODY: You dreamed of it. We dared it. [ITEM NAME] is back — only until [DATE]. CTA: Order Now. Or, Save My [ITEM NAME] The benefits of using notification templates include maintaining a consistent format, reducing the margin error, and saving time. -
通知设置
用户一般每天都会收到太多的通知,他们很容易感到不堪重负。因此,许多网站和应用程序让用户对通知设置进行细化控制。这些信息存储在通知设置表中,有以下字段:
user_id bigInt channel varchar # push notification, email or SMS opt_in boolean # opt-in to receive notification在向用户发送任何通知之前,我们首先检查用户是否选择接收这种类型的通知。
-
速率限制
为了避免用户被过多的通知所淹没,我们可以限制一个用户可以收到的通知数量。这一点很重要,因为如果我们发送得太频繁,接收者可能会完全关闭通知。
-
重试机制
当第三方服务无法发送通知时,该通知将被添加到消息队列中进行重试。如果问题持续存在,将向开发者发出警报。
-
推送通知的安全问题
对于iOS或Android应用程序,appKey和appSecret被用来保护推送通知API[6]。只有经过认证或验证的客户端才允许使用我们的API发送推送通知。有兴趣的用户应该参考参考资料[6]。
-
监视排队通知
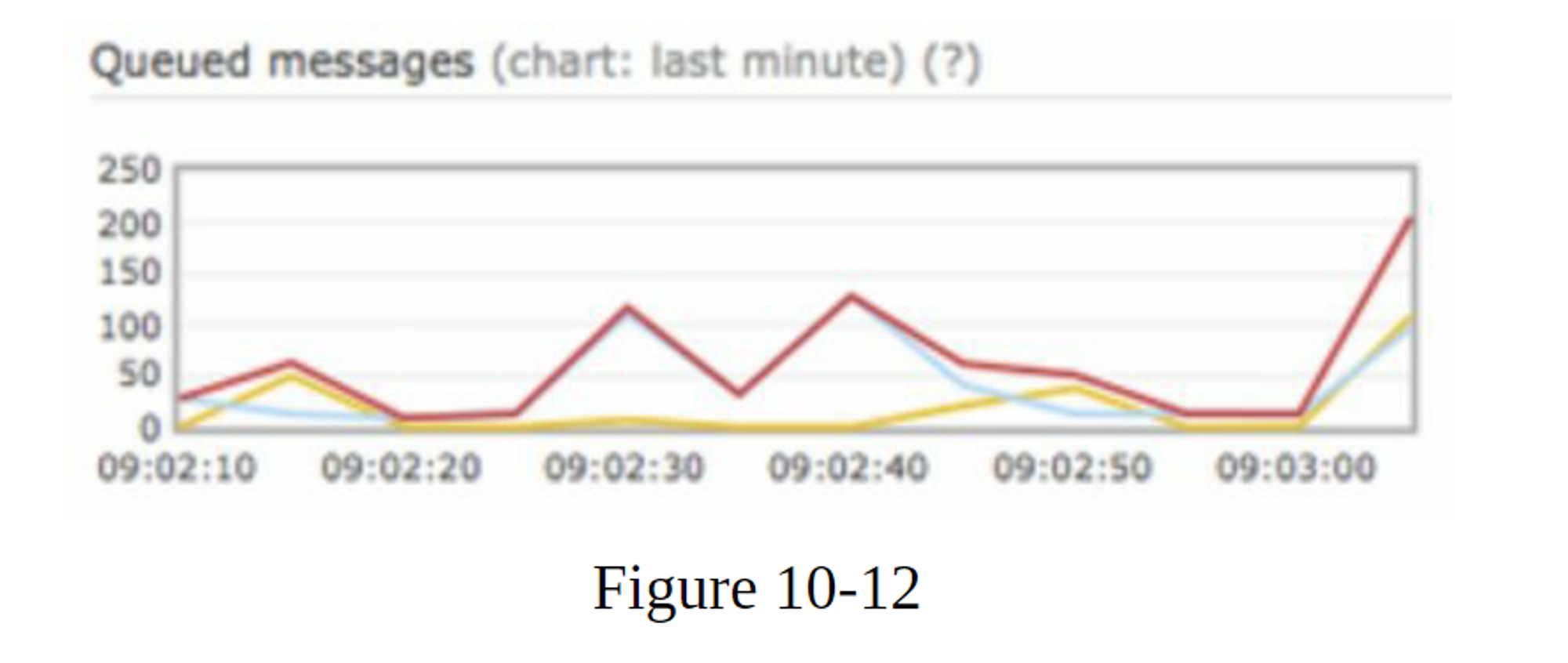
要监控的一个关键指标是排队通知的总数。如果这个数字很大,说明 workers 处理通知事件的速度不够快。为了避免通知交付的延迟,需要更多的工作者。图10-12(归功于[7])显示了一个待处理的排队消息的例子。
-
事件跟踪
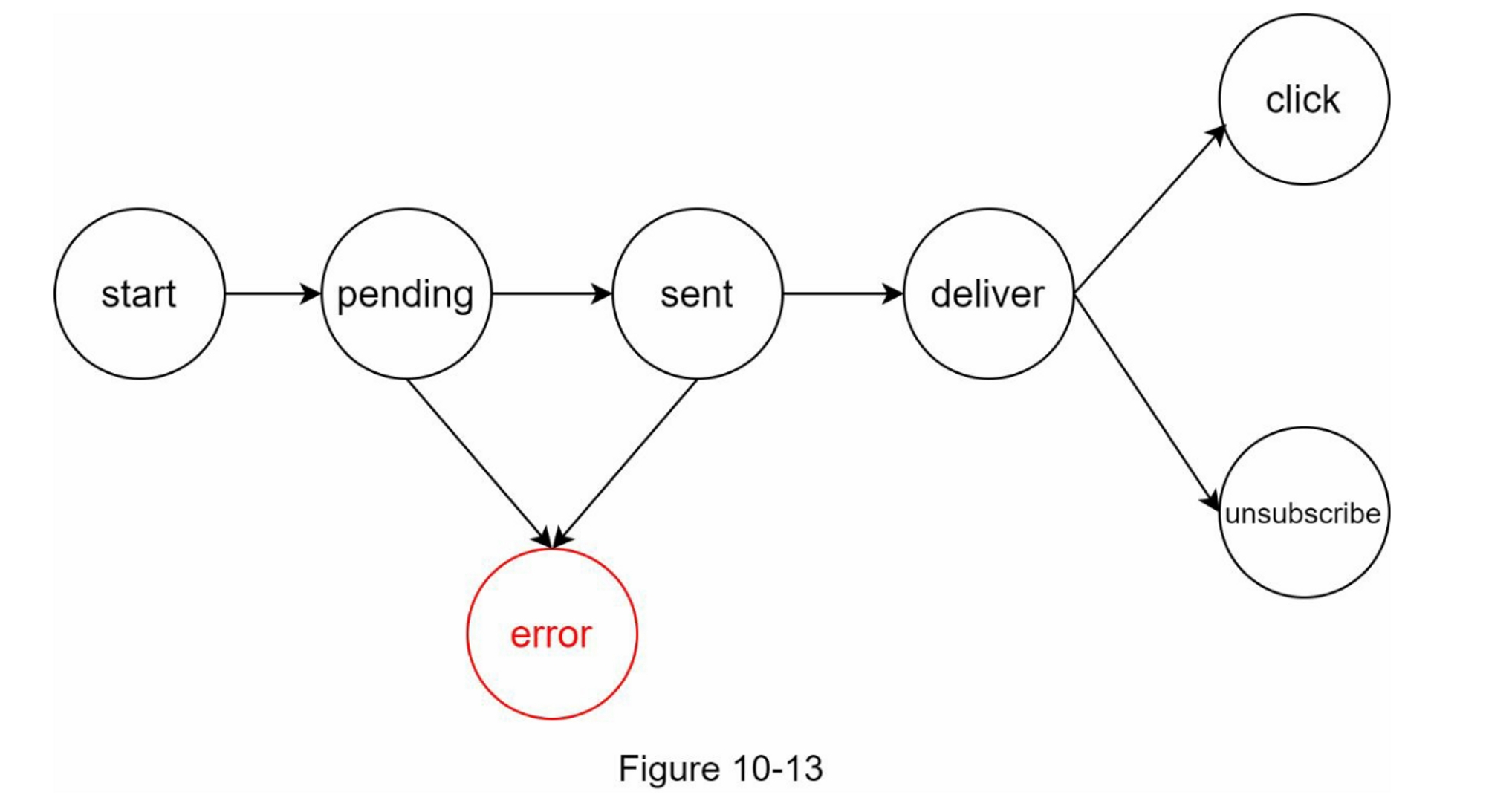
打开率、点击率和参与度等通知指标对于了解客户行为非常重要。 分析服务实现事件跟踪。 通常需要通知系统和分析服务之间的集成。 图 10-13 显示了可能出于分析目的而被跟踪的事件示例。
更新后的设计
把所有东西放在一起,图10-14显示了更新的通知系统设计。
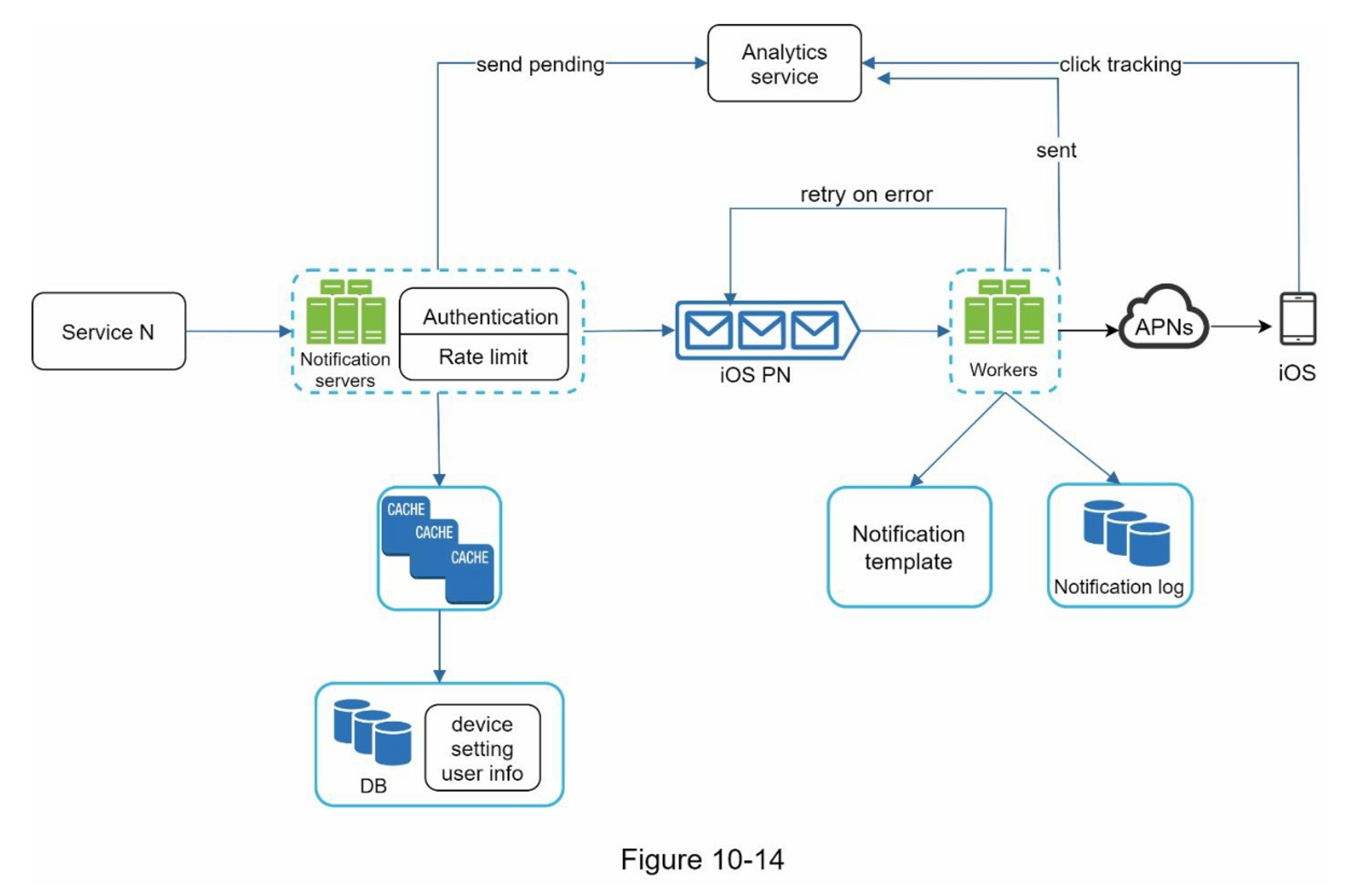
在这个设计中,与以前的设计相比,增加了许多新的组件。
- 通知服务器配备了两个更关键的功能:认证(authentication)和速率限制(rate limiti)。
- 我们还添加了一个重试机制来处理通知失败。如果系统发送通知失败,它们会被放回消息队列中,工作者会重试预定的次数。
- 此外,通知模板提供一致且高效的通知创建过程。
- 最后,为系统健康检查和未来改进增加了监测和跟踪系统。
第4步:总结
通知是不可缺少的,因为它们让我们及时了解重要信息。它可能是关于你在Netflix上最喜欢的电影的推送通知,关于新产品折扣的电子邮件,或关于你在线购物付款确认的信息。
在这一章中,我们描述了一个可扩展的通知系统的设计,它支持多种通知格式。推送通知、SMS消息和电子邮件。我们采用了消息队列来解耦系统组件。
除了高层次的设计,我们还深入挖掘了更多的组件和优化。
- 可靠性:我们提出了一个强大的重试机制,以尽量减少失败率。
- 安全性:AppKey/appSecret对用于确保只有经过验证的客户才能发送通知。
- 跟踪和监测:这些都是在通知流程的任何阶段实施的,以捕捉重要的统计资料。
- 尊重用户设置:用户可以选择不接收通知。 我们的系统在发送通知之前首先检查用户设置。
- 速率限制:用户会喜欢对他们收到的通知数量设置频率上限。
恭喜你走到了这一步!现在给自己一个鼓励,干得漂亮!
参考资料
- [1] Twilio SMS: https://www.twilio.com/sms
- [2] Nexmo SMS: https://www.nexmo.com/products/sms
- [3] Sendgrid: https://sendgrid.com/
- [4] Mailchimp: https://mailchimp.com/
- [5] You Cannot Have Exactly-Once Delivery: https://bravenewgeek.com/you-cannot-have-exactly-once-delivery
- [6] Security in Push Notifications: https://cloud.ibm.com/docs/services/mobilepush
- [7] RadditMQ: https://bit.ly/2sotIa6
第11章:设计一个信息推送系统
在本章中,您需要设计一个信息推送系统。 什么是信息推送? 根据 Facebook 帮助页面,“动态是位于首页中间不断更新的动态列表。动态包括您在 Facebook 上关注的用户、公共主页和小组发布的状态更新、照片、视频、链接、应用事件和点赞。”[1]。 这是一个流行的面试问题。 类似的常见问题有:设计 Facebook 信息推送、Instagram 推送、Twitter 时间线等。

第1步:了解问题并确定设计范围
第一组解释问题是为了了解当面试官要求你设计一个信息推送系统时,她的想法是什么。最起码,你应该弄清楚要支持哪些功能。下面是一个候选人与面试官互动的例子。
候选人:这是一个移动应用程序吗?还是一个网络应用?或者两者都是?
面试官:都是
候选人:哪些是重要的特征?
面试官:用户可以发布帖子,并在信息流页面上看到她朋友的帖子。
候选人:信息是按逆时针顺序排序,还是按任何特定顺序,如主题得分?例如,你的亲密朋友的帖子有更高的分数。
面试官:为了简单起见,让我们假设推送是按逆时针顺序排序的。
候选人:一个用户可以有多少个朋友?
面试官:5000
候选人:业务流量是多少?
面试官:1000万DAU
候选人:推送可以包含图片、视频,还是只有文字?
面试官:它可以包含媒体文件,包括图片和视频。
现在你已经收集了需求,我们把重点放在设计系统上。
第2步:提出高层次的设计方案并获得认同
该设计分为两个流程:信息流发布和信息流构建:
- 信息发布(Feed publishing):当用户发布帖子时,相应的数据被写入缓存和数据库。帖子被推送到她朋友的动态中。
- 信息流构建(Newsfeed building):为简单起见,我们假设信息推送是通过按时间倒序聚合朋友的帖子来构建的。
信息流发布 API
信息流 API是客户与服务器通信的主要方式。这些API是基于HTTP的,允许客户执行操作,其中包括发布状态、检索信息流、添加朋友等。
我们讨论两个最重要的API:信息流发布 API 和信息流检索 API。
-
信息流发布 API
要发布一个帖子,将向服务器发送一个HTTP POST请求。该API显示如下。
POST /v1/me/feed参数:
content:帖子内容的文本。auth_token:它用于验证API请求。
-
信息流检索 API
检索信息流的API如下:
GET /v1/me/feed参数:
auth_token:它用于验证API请求。
信息发布(Feed publishing)
图11-2显示了发布流程的高层设计。
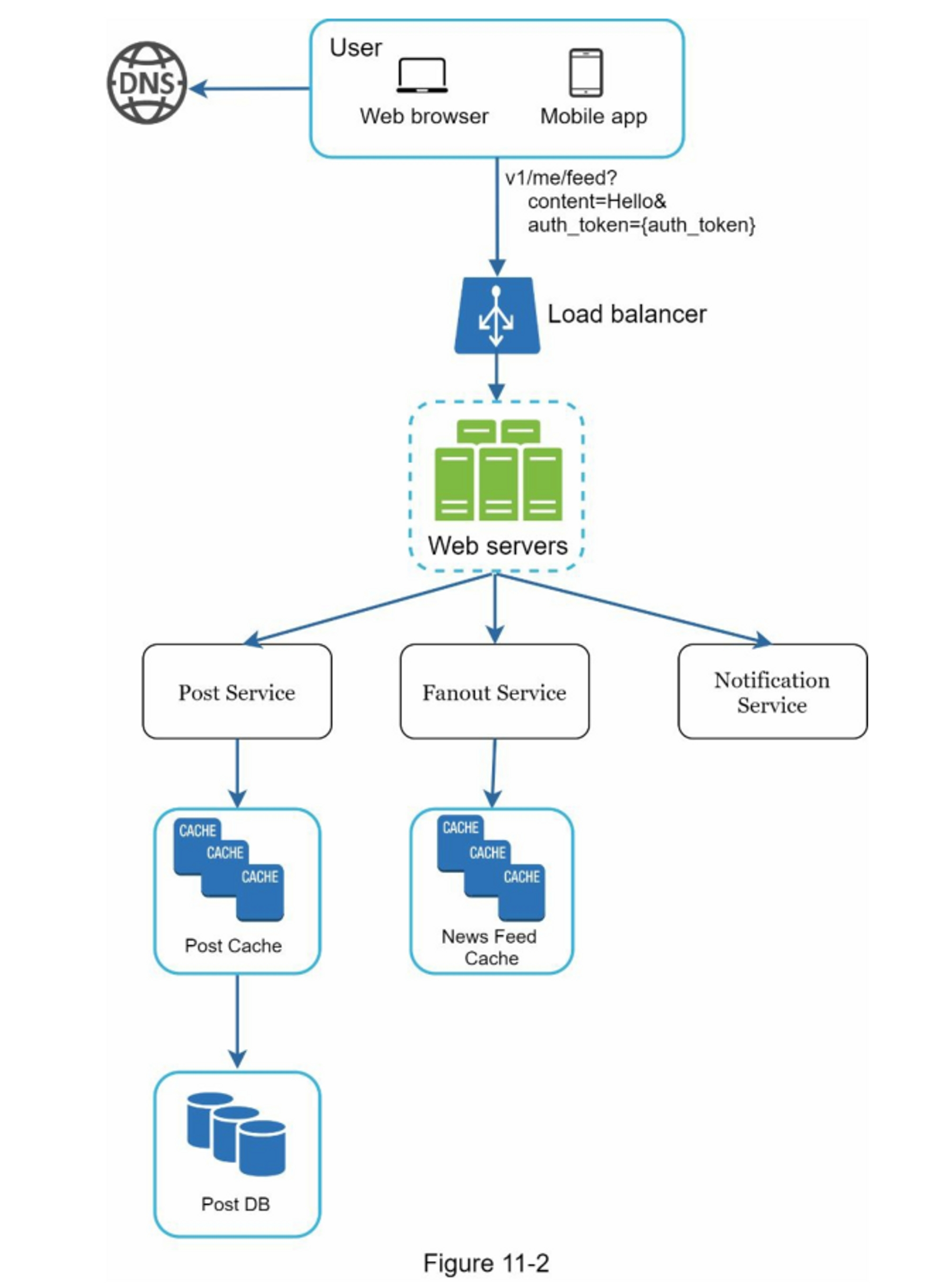
- User(用户):用户可以在浏览器或移动应用程序上查看信息流。一个用户通过API发布内容为 "你好 "的帖子:
/v1/me/feed?content=Hello&auth_token={auth_token} - Load balancer(负载均衡器):将流量分配给网络服务器。
- Web servers(网络服务器):网络服务器将流量重定向到不同的内部服务。
- Post service(帖子服务):在数据库和缓存中持久保存帖子。
- Fanout service(扇出服务):推送新内容到朋友的信息流。信息流数据存储在缓存中,以便快速检索。
- 通知服务:通知朋友有新内容,并发送推送通知。
信息流构建(Newsfeed building)
在这一节中,我们将讨论信息流是如何在幕后构建的。
图11-3显示了高层设计。
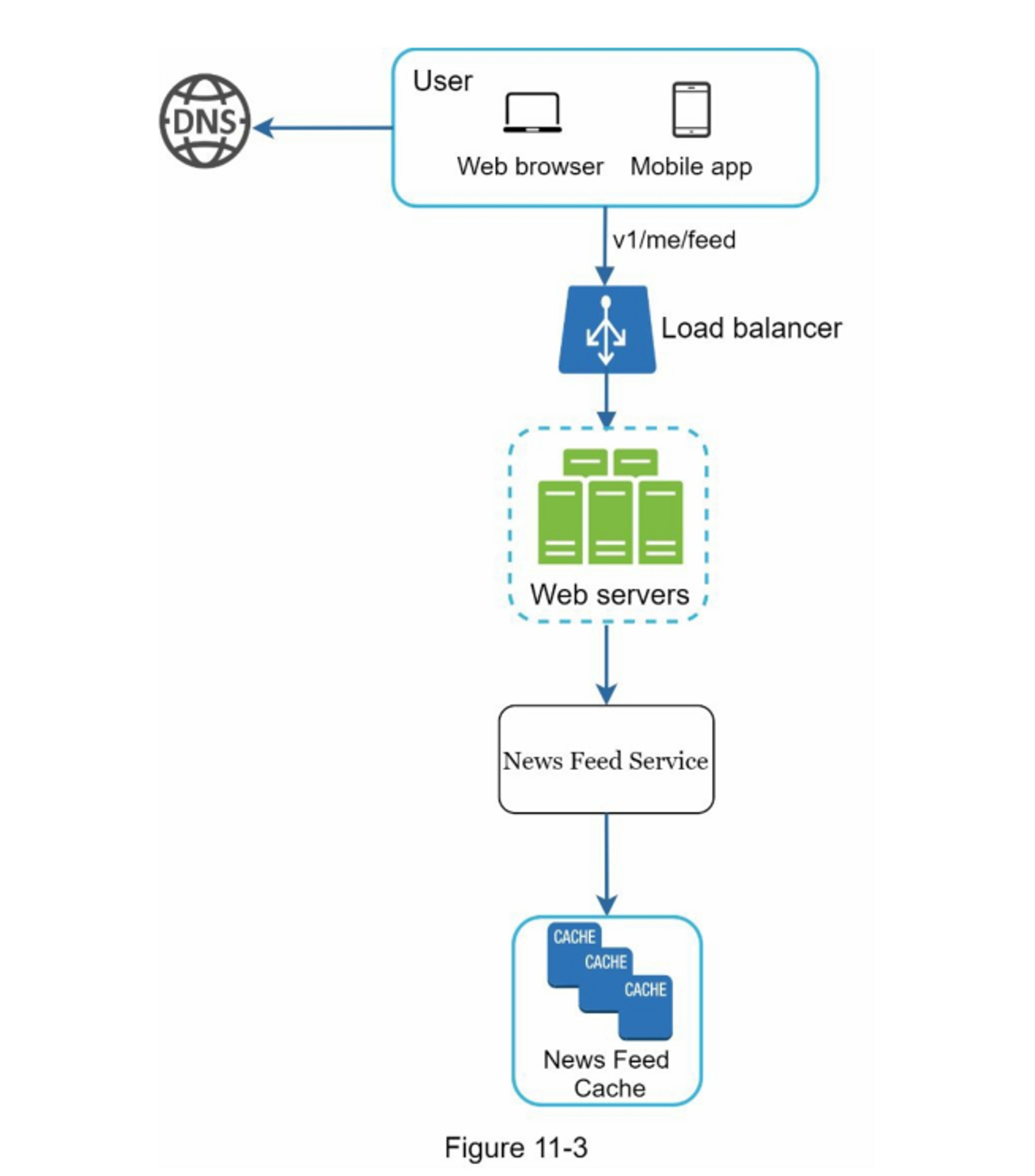
- User(用户):一个用户发送了一个请求来检索她的信息。 该请求看起来像这样:
/v1/me/feed。 - Load balancer(负载均衡器):将流量分配给网络服务器。
- Web servers(网络服务器):网络服务器将请求路由到信息发布服务。
- Newsfeed service(信息馈送服务):信息馈送服务从缓存中获取信息。
- Newsfeed cache(信息流缓存):存储渲染信息流所需的信息ID。
第3步:深入设计
高层设计简要地涵盖了两个流程:信息发布和信息流构建。在这里,我们更深入地讨论这些主题。
信息发布深入研究
图 11-4 概述了信息发布的详细设计。我们已经讨论了高层次设计中的大部分组件,我们将重点关注两个组件:Web 服务器和扇出服务。
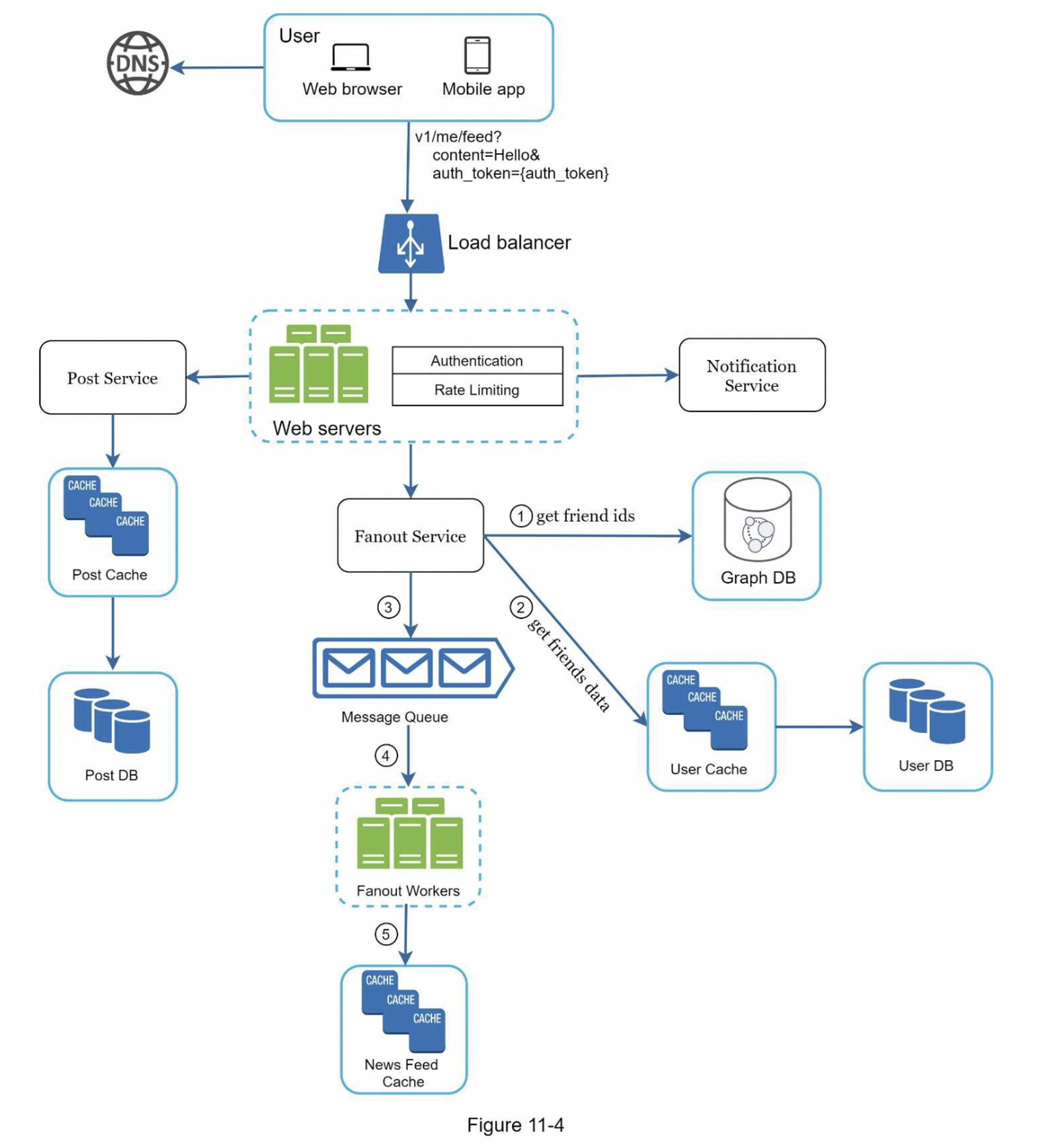
web 服务
除了与客户端通信外,Web 服务器还执行身份验证和速率限制。只有使用有效 auth_token 登录的用户才可以发帖。该系统限制用户在一定时期内可以发布的帖子数量,这对于防止垃圾邮件和滥用内容至关重要。
扇出服务
Fanout 是将帖子传递给所有朋友的过程。两种类型的扇出模型是:写扇出(也称为推模型)和读扇出(也称为拉模型)。两种模型各有利弊。我们解释他们的工作流程并探索支持我们系统的最佳方法。
写扇出
通过这种方法,信息流在写的时候就被预先计算了。一个新的帖子在发布后会立即被送到朋友的缓存中。
优点:
- 动态消息是实时生成的,可以第一时间推送给朋友。
- 获取信息流的速度很快,因为信息流是在写的时候预先计算的。
缺点:
- 如果一个用户有很多朋友,获取朋友列表并为所有朋友生成信息流是很慢的,而且很耗时间。这被称为热键问题。
- 对于不活跃的用户或那些很少登录的用户,预先计算的信息流会浪费计算资源。
读扇出
信息源是在阅读时间内产生的。这是一个按需分配的模式。当用户加载她的主页时,最近的帖子被拉出。
优点:
- 对于不活跃的用户或那些很少登录的用户,读取时的扇出效果更好,因为它不会在他们身上浪费计算资源。
- 数据不会被推送给朋友,所以不存在热键的问题。
缺点:
- 获取信息源的速度很慢,因为信息源不是预先计算的。
我们采用了一种混合方法,以获得两种方法的好处并避免其中的缺点。由于快速获取信息流是至关重要的,我们对大多数用户使用推送模式。对于名人或有很多朋友/粉丝的用户,我们让粉丝按需提取信息内容以避免系统过载。一致性哈希是缓解热键问题的一个有用技术,因为它有助于更均匀地分配请求/数据。
让我们仔细看看图11-5中所示的扇出服务。
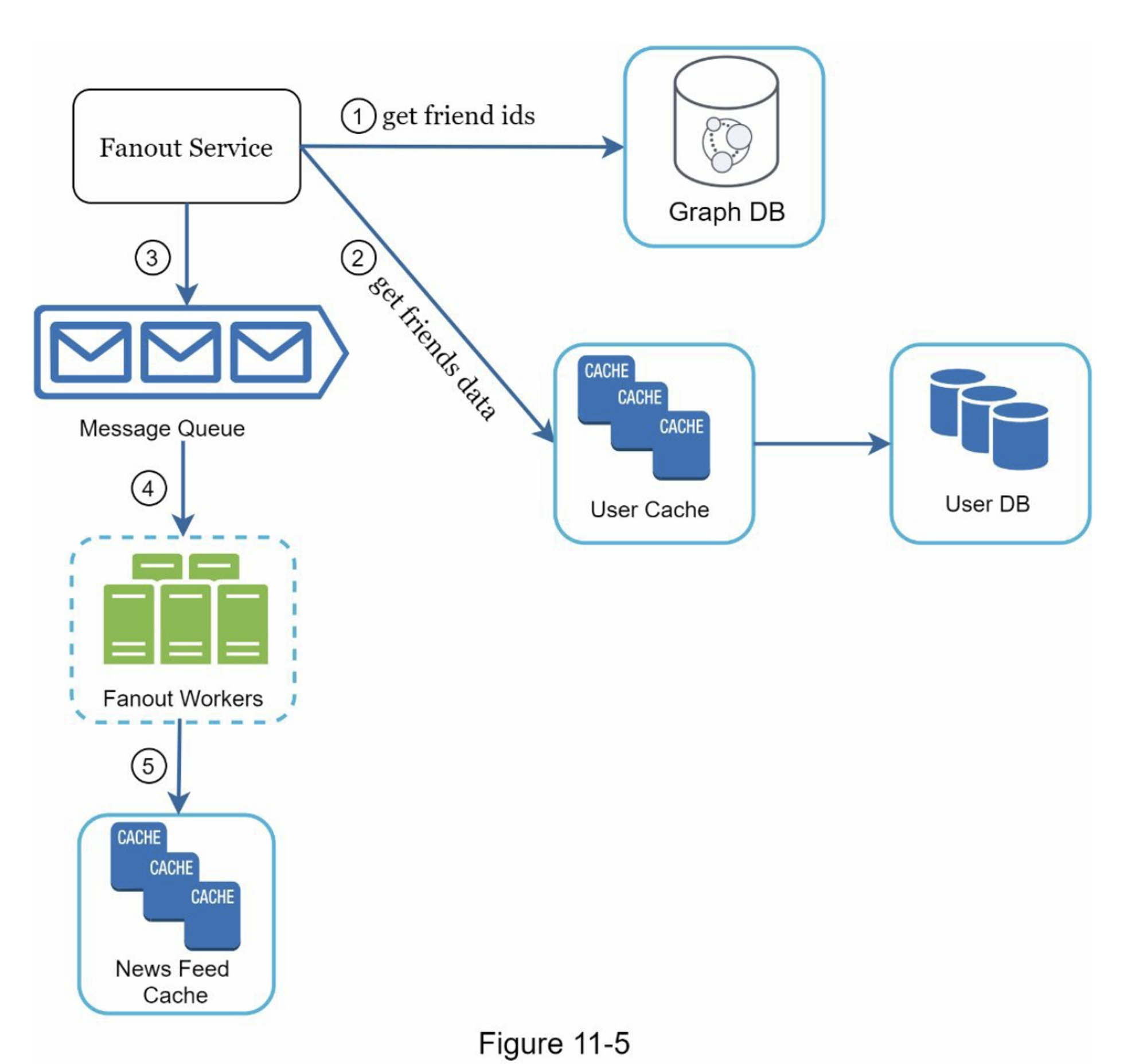
扇出服务的工作原理如下:
-
从图形数据库中获取朋友 ID。 图数据库适用于管理朋友关系和朋友推荐。 希望了解更多有关此概念的感兴趣的读者应参阅参考资料 [2]。
-
从用户缓存中获取朋友信息。然后,系统根据用户设置过滤出朋友。例如,如果你把某人调成静音,她的帖子将不会显示在你的信息流中,尽管你们仍然是朋友。帖子可能不显示的另一个原因是,用户可以有选择地与特定的朋友分享信息或对其他人隐藏信息。
-
将好友列表和新帖子 ID 发送到消息队列。
-
Fanout worker 从消息队列中获取数据并将信息流数据存储在信息流缓存中。 你可以将信息流缓存视为一个
<post_id, user_id>结构的映射表。 每当发布新帖子时,新帖子将被追加到信息流表中,如图 11-6 所示。 如果我们将整个用户和帖子对象存储在缓存中,内存消耗会变得非常大。 因此,仅存储 ID。 为了保持较小的内存大小,我们设置了一个可配置的限制。 用户滚动浏览信息流中数千个帖子的机会很小。 大多数用户只对最新的内容感兴趣,所以缓存未命中率低。 -
将
<post_id, user_id>存储在信息流缓存中。 图 11-6 显示了缓存中信息流的示例。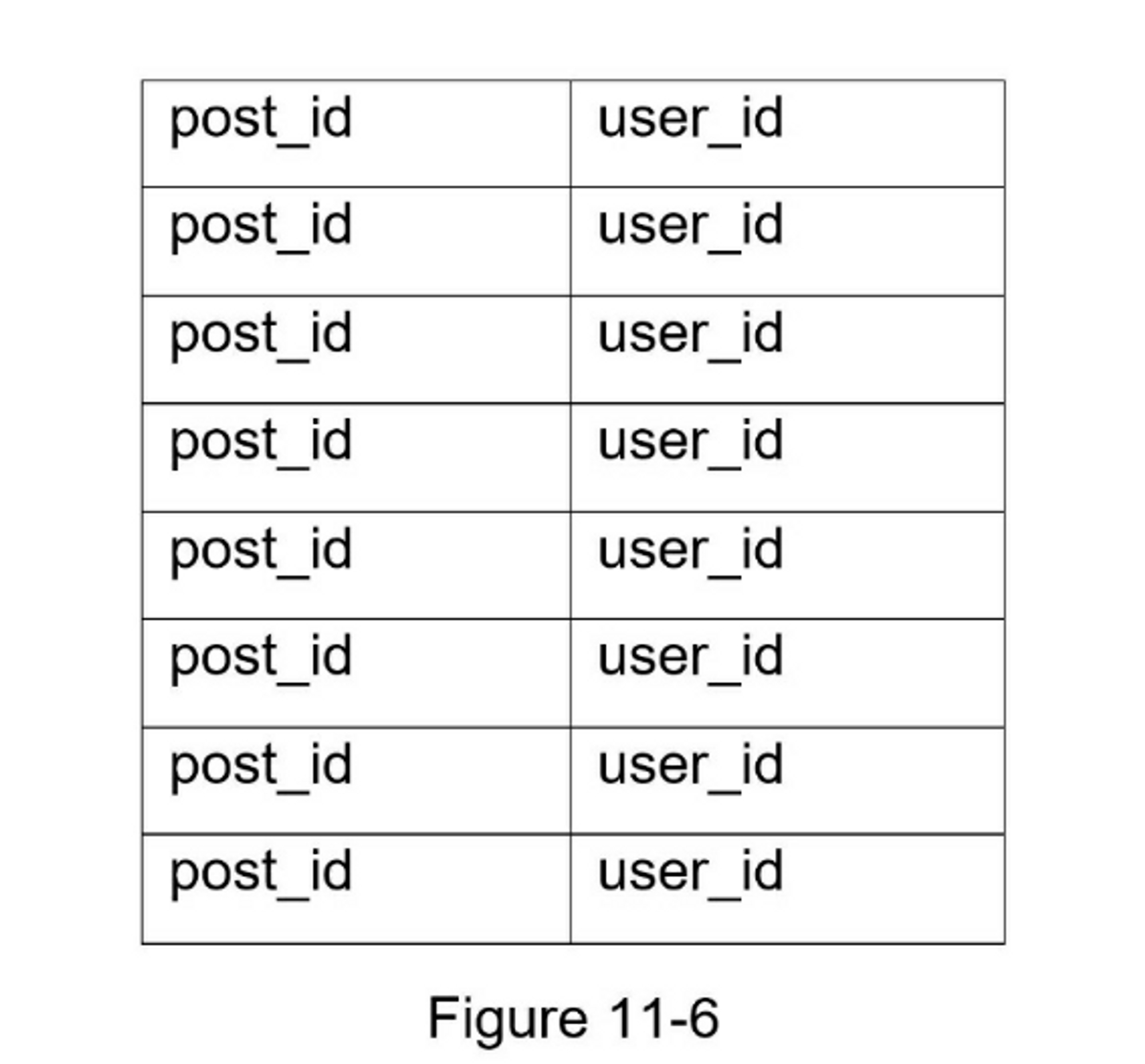
信息源检索深入研究
图 11-7 说明了信息检索的详细设计。
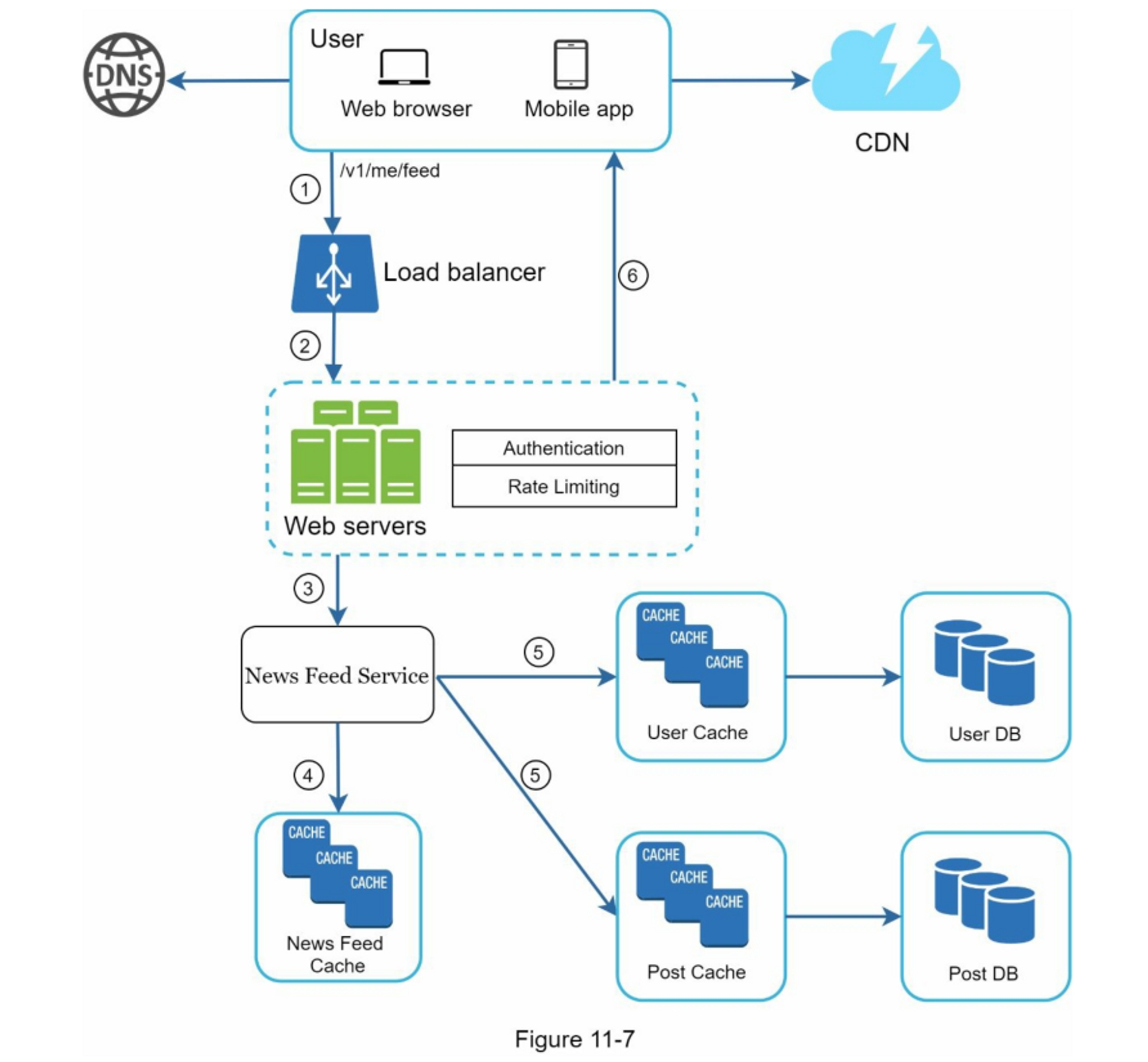
如图11-7所示,媒体内容(图片、视频等)存储在CDN中,便于快速检索。 让我们看看客户端如何检索信息流。
- 一个用户发送了一个请求来检索她的信息流。该请求看起来像这样:
/v1/me/feed - 负载均衡将请求重新分配给网络服务器。
- Web 服务器调用信息流服务(News Feed Service)获取信息流。
- 信息流服务从信息流缓存中获得一个帖子ID列表。
- 用户的信息流不仅仅是 feed ID 列表。 它包含用户名、个人资料图片、帖子内容、帖子图片等。因此,信息流服务从缓存(用户缓存和帖子缓存)中获取完整的用户和帖子对象,以构建完全整合的信息流。
- 完全整合的信息流以JSON格式返回到客户端进行渲染。
-
缓存架构
缓存对于信息流系统非常重要。 我们将缓存层分为 5 层,如图 11-8 所示。
- News Feed:它存储了信息的ID。
- Content:它存储每个帖子的数据。受欢迎的内容被存储在热缓存中。
- Social Graph:它存储用户关系数据。
- Action:它存储有关用户是否喜欢帖子、回复帖子或对帖子执行其他操作的信息。
- Counters:它存储点赞、回复、关注者、关注等的计数器。
第4步:总结
在本章中,我们设计了一个信息推送系统。 我们的设计包含两个流程:信息发布和信息检索。
与任何系统设计面试问题一样,没有完美的系统设计方法。 每个公司都有其独特的限制,您必须设计一个系统来适应这些限制。 了解您的设计和技术选择的权衡很重要。 如果还剩几分钟,您可以讨论可扩展性问题。 为避免重复讨论,下面仅列出高层次的谈话要点。
数据库扩展:
- 垂直扩展 vs 水平扩展
- SQL vs NoSQL
- 主从复制
- 读写分离
- 一致性模型
- 数据库分片
其他谈话要点:
- 保持网络层的无状态
- 尽可能多地缓存数据
- 支持多个数据中心
- 使用消息队列降低耦合
- 监控关键指标。 例如,高峰时段的 QPS 和用户刷新信息流时的延迟值得监控。
恭喜你走到了这一步!现在给自己一个鼓励,干得漂亮!
参考资料
[1] How News Feed Works:
https://www.facebook.com/help/327131014036297/
[2] Friend of Friend recommendations Neo4j and SQL Sever:
第12章:设计一个聊天系统
在本章中,我们将探讨聊天系统的设计,几乎每个人都使用聊天应用程序。 图 12-1 显示了市场上一些最流行的应用程序。

聊天应用程序对不同的人执行不同的功能。敲定确切的要求是极其重要的。例如,当面试官想到一对一的聊天时,你不希望设计一个专注于群组聊天的系统。探索功能要求是很重要的。
第1步:了解问题并确定设计范围
就要设计的聊天应用类型达成一致至关重要。市场上有Facebook Messenger、微信和WhatsApp等一对一聊天应用,Slack等专注于群聊的办公聊天应用,Discord等专注于大型群聊和低语音聊天延迟的游戏聊天应用。
第一组需要弄清楚的问题是应该明确面试官要求设计一个聊天系统时她的想法到底是什么。至少要弄清楚你是应该专注于一对一的聊天还是群组聊天应用。
你可以问的一些问题如下:
候选人:我们要设计什么样的聊天应用? 1对1还是群聊? 面试官:应该支持1对1和群聊。
候选人:这是一个手机APP?还是一个web APP?或者两者都是?
面试官:都是。
候选人:这个应用程序的规模是多少?是创业公司的应用还是大规模的?
面试官:它应该支持5000万日活跃用户(DAU)。
候选人:对于小组聊天,小组成员的限制是什么?
面试官:最多100人
候选人:对于聊天应用程序来说,哪些功能是重要的?它能支持附件吗?
面试官:1对1聊天,群聊,在线状态。系统只支持文本信息。
候选人:信息大小有限制吗?
面试官:是的,文本长度应少于100,000字符。
候选人:是否需要端对端加密?
面试官:暂时不需要,但如果时间允许,我们会讨论这个问题。
候选人:我们应将聊天记录保存多长时间?
面试官:永久。
在这一章中,我们着重于设计一个类似于Facebook messenger的聊天应用,重点是以下功能:
- 一对一的聊天,消息传递延迟低
- 小组聊天(最多100人)。
- 在线状态
- 支持多个设备,同一账户可以同时登录多个设备。
- 推送通知
就设计规模达成一致也很重要,我们将设计一个支持 5000 万 DAU 的系统。
第2步:提出高层次的设计方案并获得认同
为了开发一个高质量的设计,我们应该对客户和服务器的通信方式有一个基本的了解。在一个聊天系统中,客户端可以是移动应用程序或Web应用程序。客户端之间并不直接交流。相反,每个客户端都连接到一个聊天服务,它支持上面提到的所有功能。让我们专注于基本操作。聊天服务必须支持以下功能:
- 接收来自其他客户端的信息。
- 为每条信息找到合适的收件人,并将信息转达给收件人。
- 如果一个收件人不在线,就在服务器上保留该收件人的信息,直到她在线。
图 12-2 显示了客户端(发送方和接收方)与聊天之间的关系服务。
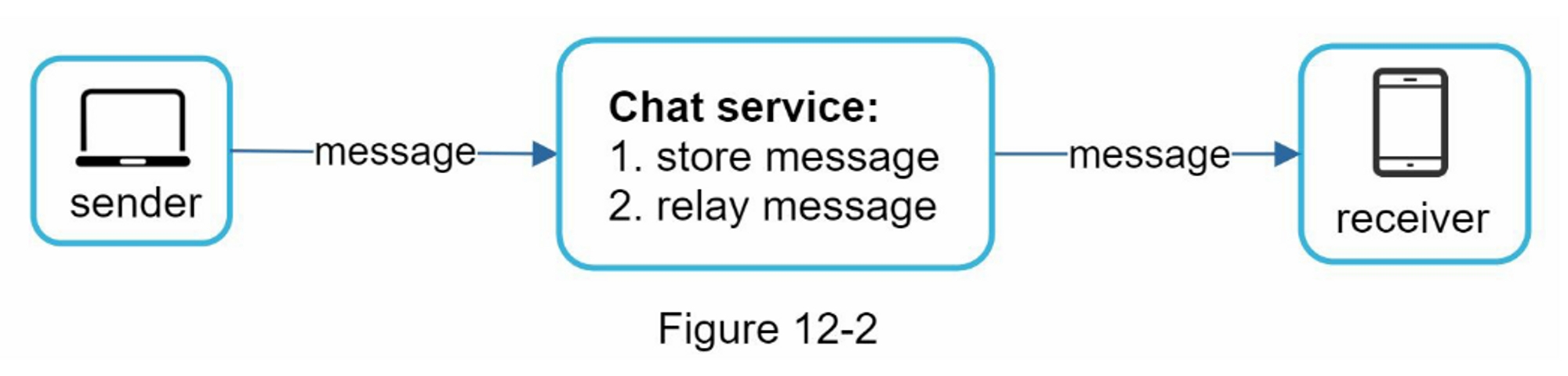
当客户打算开始聊天时,它使用一个或多个网络协议连接聊天服务。对于一个聊天服务,网络协议的选择很重要。让我们与面试官讨论一下这个问题。
对于大多数客户端/服务器应用程序,请求由客户端发起。 对于聊天应用程序的发送方也是如此。
在图 12-2 中,当发送方通过聊天服务向接收方发送消息时,它使用久经考验的 HTTP 协议,这是最常见的 Web 协议。 在此场景中,客户端打开与聊天服务的 HTTP 连接并发送消息,通知服务将消息发送给接收者。 Keep-Alive 对此很有效,因为 Keep-Alive 标头允许客户端与聊天服务保持持久连接。 它还减少了 TCP 握手的次数。 HTTP 在发送端是一个不错的选择,许多流行的聊天应用程序(例如 Facebook [1])最初使用 HTTP 来发送消息。
然而,接收方的情况就比较复杂了。由于HTTP是由客户发起的,因此从服务器发送消息并非易事。多年来,许多技术被用来模拟服务器发起的连接:轮询(Polling)、长轮询(Long polling)和 WebSocket。这些都是在系统设计面试中广泛使用的重要技术,所以让我们逐一研究。
轮询
如图12-3所示,轮询是一种技术,客户端定期询问服务器是否有消息可用。根据轮询的频率,轮询的成本可能很高。它可能会消耗宝贵的服务器资源来回答一个大部分时间都没有答案的问题。
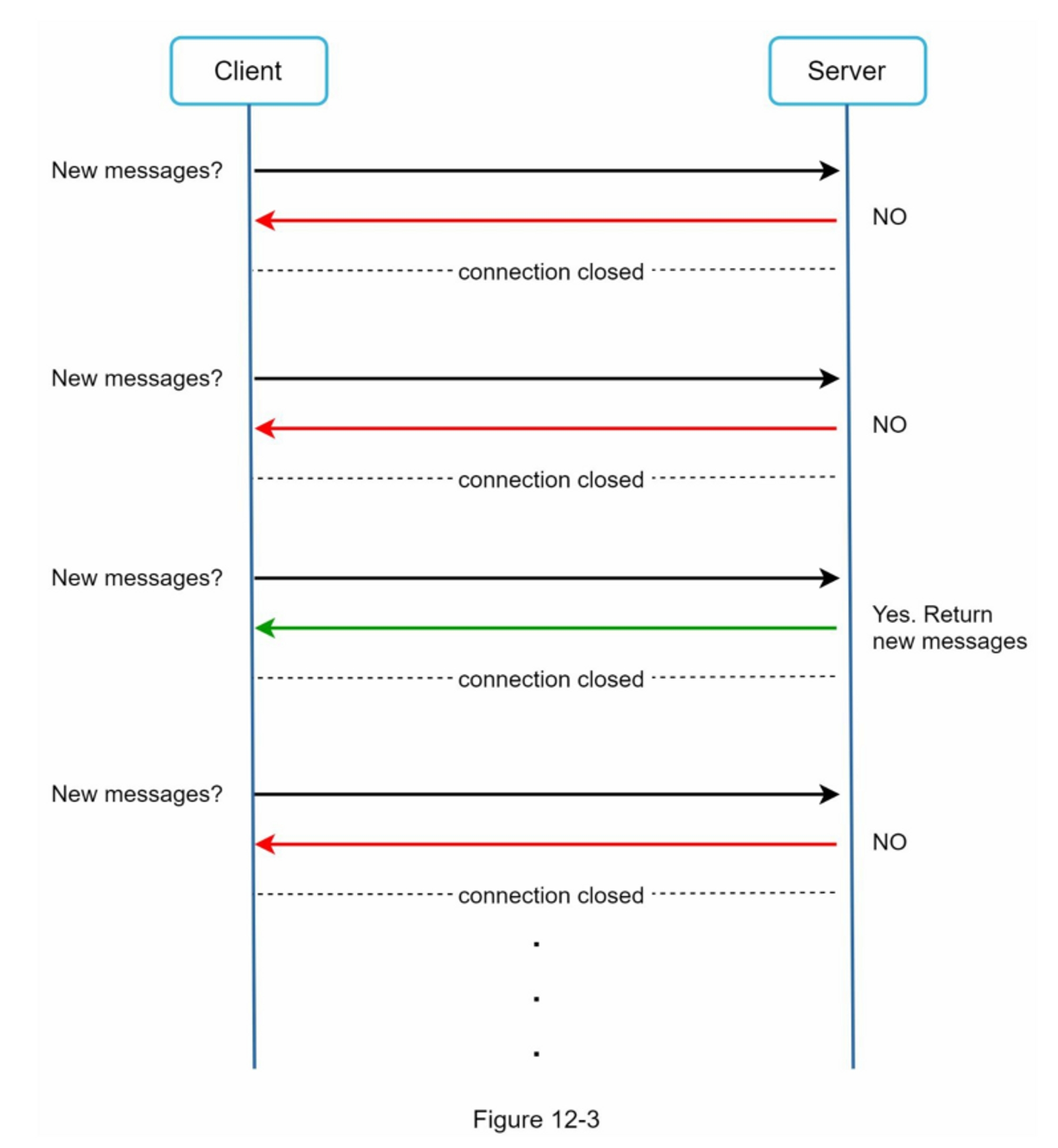
长轮询
因为轮询可能是低效的,接下来的是长轮询(图12-4)。
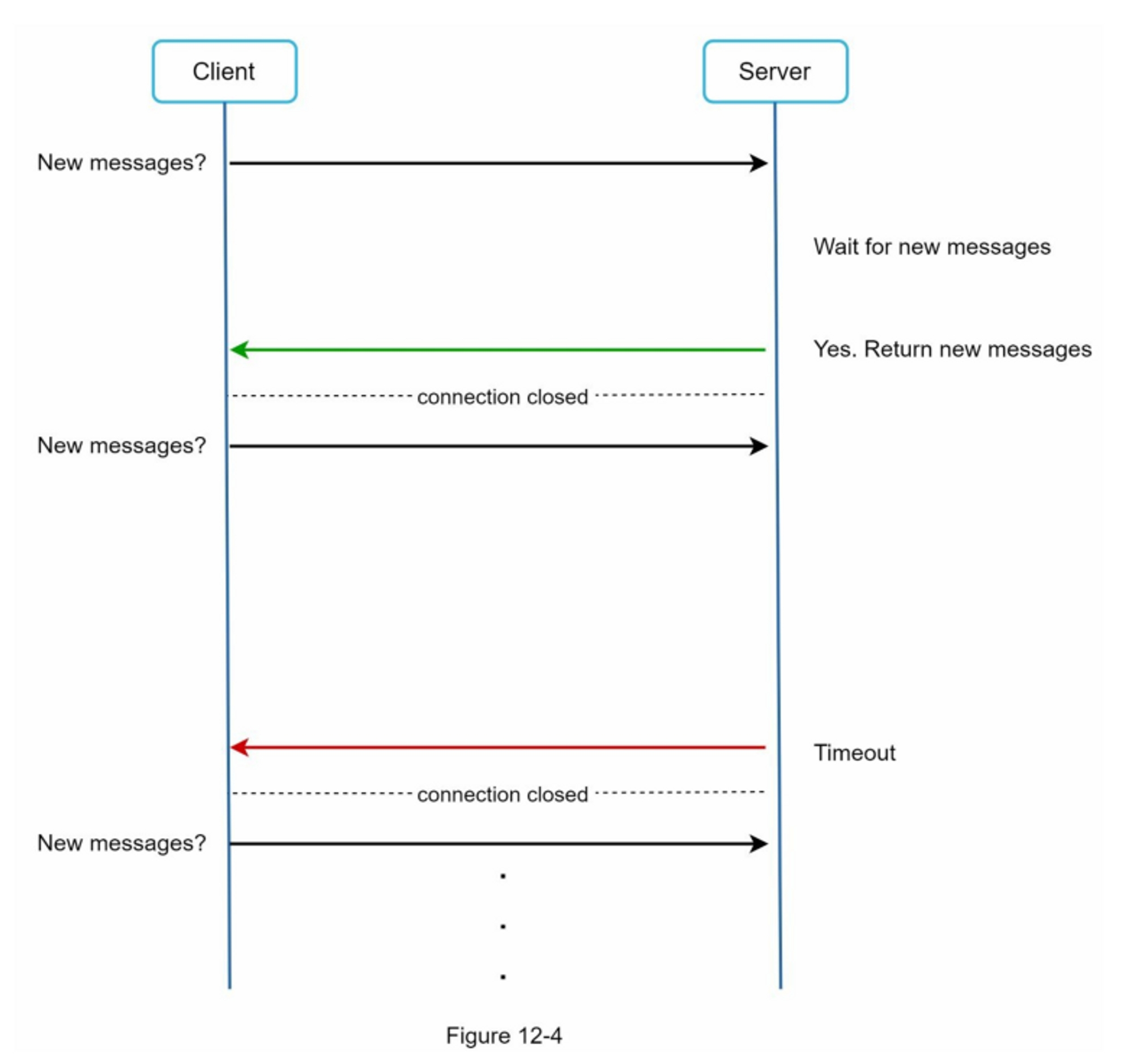
在长轮询中,客户端保持连接打开,直到实际有新消息可用或达到超时阈值。一旦客户端收到新消息,它会立即向服务器发送另一个请求,重新启动进程。
长轮询有一些缺点:
- 发送方和接收方可能不会连接到同一个聊天服务器。基于HTTP的服务器通常是无状态的。如果使用轮回技术进行负载平衡,接收信息的服务器可能没有与接收信息的客户端建立长期轮回连接。
- 服务器没有很好的方法来判断一个客户是否断开了连接。
- 它的效率很低。如果一个用户不怎么聊天,长时间的轮询仍然会在超时后进行周期性的连接。
WebSocket
WebSocket是从服务器向客户端发送异步更新的最常见解决方案。
图12-5显示了它的工作原理。
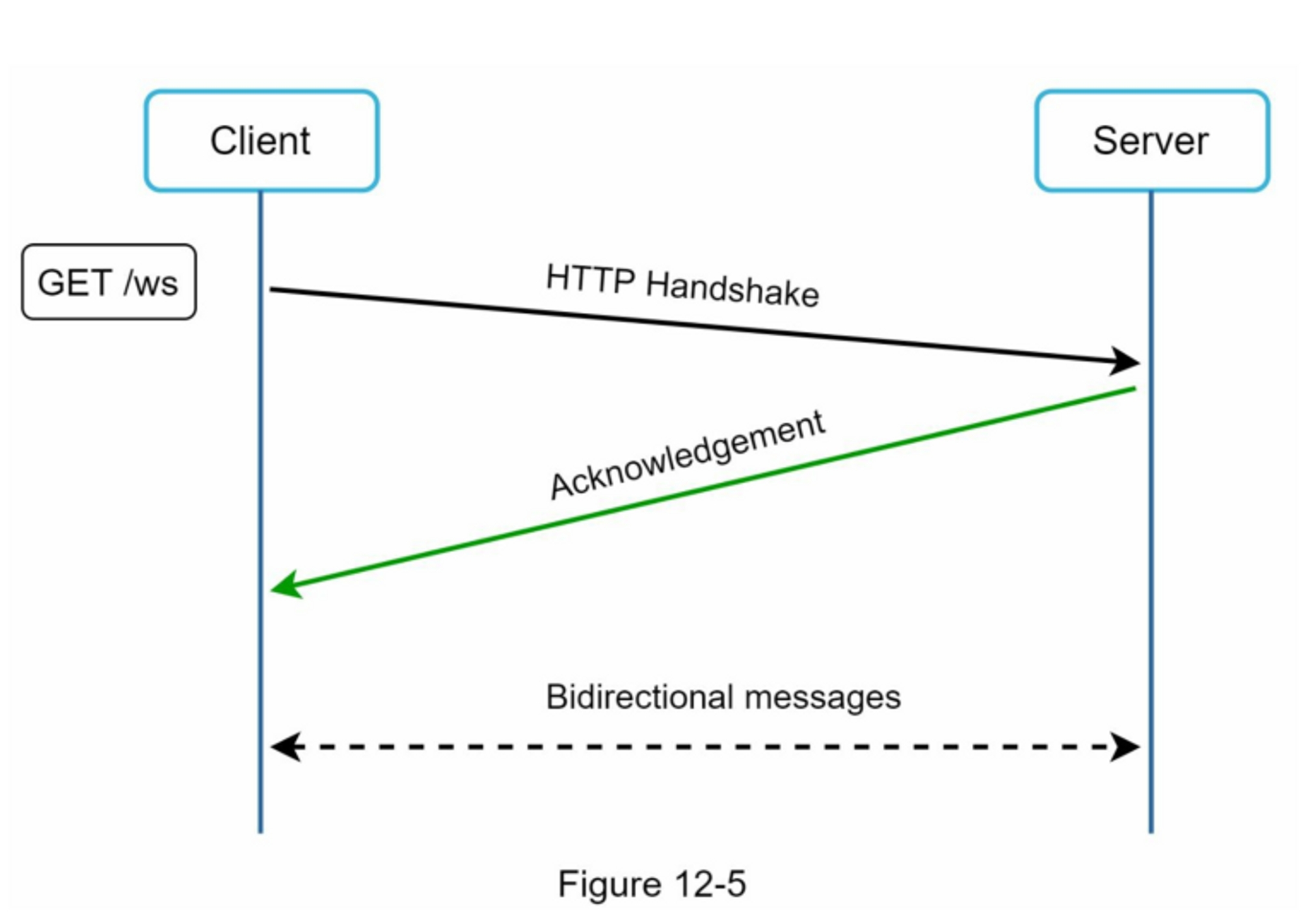
WebSocket连接是由客户端发起的。它是双向且持久的。它以HTTP连接的形式开始,并可通过一些定义明确的握手方式 "升级 "为WebSocket连接。通过这种持久的连接,服务器可以向客户端发送更新。即使有防火墙,WebSocket连接通常也能工作。这是因为它们使用80或443端口,这些端口也被HTTP/HTTPS连接所使用。
前面我们说过,在发送方使用HTTP是一个很好的协议,但由于WebSocket是双向的,没有充分的技术理由不把它也用于发送。
图12-6显示了WebSockets(ws)在发送方和接收方的使用情况。
通过使用WebSocket进行发送和接收,它简化了设计,并使客户端和服务器上的实现更加直接。由于WebSocket连接是持久的,因此有效的连接管理在服务器端至关重要。
高层次设计
刚才我们提到,选择WebSocket作为客户端和服务器之间的主要通信协议,是因为它的双向通信,需要注意的是,其他一切都不一定是WebSocket。事实上,聊天应用程序的大多数功能(注册、登录、用户资料等)都可以使用HTTP上的传统请求/响应方法。
让我们深入了解一下,看看系统的高级组件。
如图12-7所示,聊天系统被分成三大类:无状态服务、有状态服务和第三方集成。
-
无状态的服务
无状态服务是传统的面向公众的请求/响应服务,用于管理登录、注册、用户资料等。这些是许多网站和应用程序中的常见功能。
无状态服务位于负载均衡器后面,其工作是根据请求路径将请求路由到正确的服务。这些服务可以是单体的,也可以是单独的微服务。我们不需要自己建立许多这样的无状态服务,因为市场上有一些服务可以很容易地被集成。
我们将深入讨论的一个服务是服务发现。它的主要工作是给客户提供一个客户可以连接到的聊天服务器的DNS主机名列表。
-
有状态的服务
唯一有状态的服务是聊天服务。该服务是有状态的,因为每个客户都与一个聊天服务器保持持久的网络连接。在这个服务中,只要服务器仍然可用,客户通常不会切换到另一个聊天服务器。服务发现与聊天服务密切协调,以避免服务器过载。我们将在深入研究中详细介绍。
-
第三方集成
对于一个聊天应用程序,推送通知是最重要的第三方集成。它是一种在新消息到来时通知用户的方式,即使应用程序没有运行。正确整合推送通知是至关重要的。更多信息请参考第10章 设计一个通知系统。
可扩展性
在小范围内,上面列出的所有服务都可以放在一台服务器中。即使以我们设计的规模,理论上也有可能在一个现代云服务器中处理所有的用户连接。服务器可以处理的并发连接数很可能是限制因素。在我们的场景中,在 100w 并发用户的情况下,假设每个用户连接在服务器上需要10K内存(这是一个非常粗略的数字,非常依赖于语言选择),则只需要大约10GB的内存即可将所有连接保存在一个服务器上。
如果我们提出一种将所有内容都放在一台服务器中的设计,这可能会在面试官的脑海中升起一个大大的不好信号。 没有技术专家会在单个服务器中设计这样的规模。由于多种因素,单服务器设计是交易的障碍,单点失败是其中最大的。
然而,从单一的服务器设计开始是完全可以的。只要确保面试官知道这只是一个起点。把我们提到的一切放在一起,图12-8显示了调整后的高层设计。
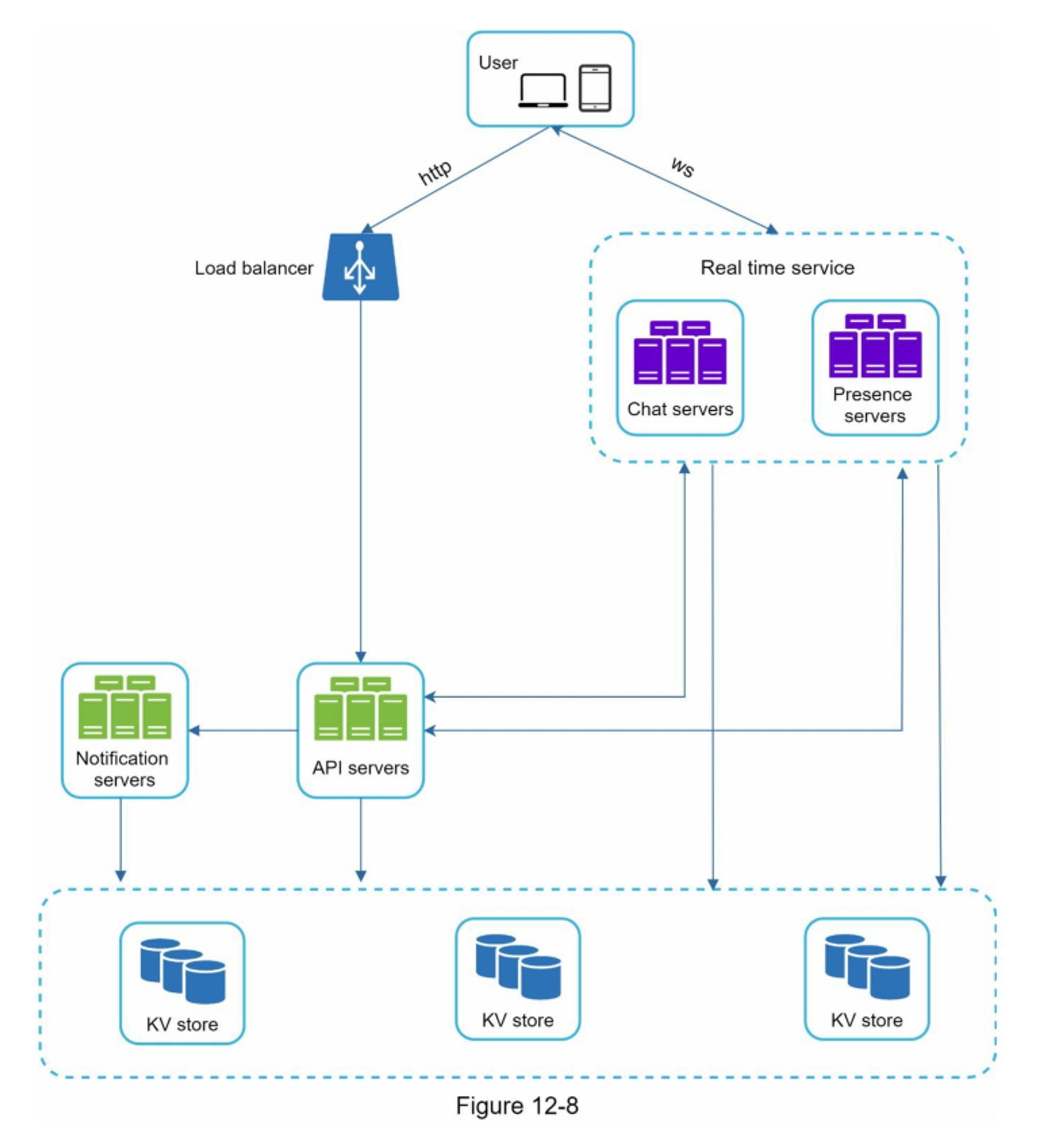
在图12-8中,客户端与聊天服务器保持一个持久的 WebSocket 连接,用于实时消息传递。
- 聊天服务器 (Chat servers) 促进了信息的发送/接收。
- 在线服务器 (Presence servers) 管理在线/离线状态。
- API服务器 (API servers) 处理一切,包括用户登录、注册、更改资料等。
- 通知服务器 (Notification servers) 发送推送通知。
- 最后,键值存储 (KV store) 用于存储聊天历史。当一个离线用户上线时,她会看到她以前所有的聊天历史。
储存
在这一点上,我们已经准备好了服务器,服务已经开始运行,第三方集成已经完成。在技术栈的深处是数据层。数据层通常需要一些努力才能得到正确的结果。我们必须做出的一个重要决定是,决定使用正确的数据库类型:关系型数据库还是NoSQL数据库?为了做出一个明智的决定,我们将检查数据类型和读/写模式。
在一个典型的聊天系统中存在两类数据。
第一类是通用数据,如用户资料、设置、用户朋友列表。这些数据被存储在强大而可靠的关系数据库中。复制和分片是满足可用性和扩展性要求的常见技术。
第二种是聊天系统特有的:聊天历史数据。了解读/写模式很重要。
- 聊天系统的数据量是巨大的。之前的一项研究[2]显示,Facebook 和 Whatsapp 每天要处理600亿条信息。
- 只有最近的聊天记录被频繁访问。用户通常不会查找旧的聊天记录。
- 虽然在大多数情况下都会查看最近的聊天记录,但用户可能会使用需要随机访问数据的功能,如搜索、查看您的提及内容、跳转到特定的消息等。这些情况应该由数据访问层来支持。
- 一对一聊天应用程序的读写比约为 1:1。
选择正确的存储系统,支持我们所有的使用案例是至关重要的。我们推荐键值存储,理由如下。
- 键值存储允许容易的水平扩展。
- 键值存储为访问数据提供了非常低的延迟。
- 关系型数据库不能很好地处理长尾[3]的数据。当索引变大时,随机访问是很昂贵的。
- 键值存储被其他成熟可靠的聊天应用程序所采用。例如,Facebook 和 Discord 都使用键值存储。Facebook 使用 HBase[4],而 Discord 使用 Cassandra[5]。
数据模型
刚才,我们谈到了使用键值存储作为我们的存储层。最重要的数据是消息数据。让我们仔细看一下。
-
一对一聊天的消息表
图12-9显示了1对1聊天的消息表。主键是
message_id,它有助于决定消息的顺序。我们不能依靠created_at来决定消息的顺序,因为两条消息可以同时创建。
-
群聊消息表
图12-10显示了群聊的消息表。复合主键是
(channel_id,message_id)。频道和组在此表示相同的含义。channel_id是分区键,因为群聊天中的所有查询都在一个通道中运行。
-
消息ID
如何生成
message_id是一个值得探索的有趣话题。message_id承担着确保消息顺序的责任。为了确定消息的顺序,message_id必须满足以下两个要求。- ID 必须唯一。
- ID应该可以按时间排序,也就是说,新行的ID要比旧行高。
我们如何才能实现这两项保证呢?我想到的第一个想法是 MySQL 中的
auto_increment关键字。然而,NoSQL数据库通常不提供这样的功能。第二种方法是使用像Snowflake[6]那样的全局64位序列号发生器。这将在 "第七章:在分布式系统中设计一个唯一的ID生成器" 中讨论。
最后一种方法是使用本地序列号生成器。本地意味着ID只在一个组内是唯一的。本地ID发挥作用的原因是,在一对一的信道或一个组的信道内维持消息序列就足够了。与全局ID的实现相比,这种方法更容易实现。
第3步:深入设计
在系统设计面试中,通常希望你能深入了解高层次设计中的一些组件。对于聊天系统,服务发现、消息流和在线/离线值得深入探讨。
服务发现
服务发现的主要作用是根据地理位置、服务器容量等标准,为客户推荐最佳的聊天服务器。Apache Zookeeper [7] 是一个流行的服务发现开源解决方案。它注册了所有可用的聊天服务器,并根据预定义的标准为客户挑选最佳聊天服务器。
图12-11显示了服务发现(Zookeeper)是如何工作的。
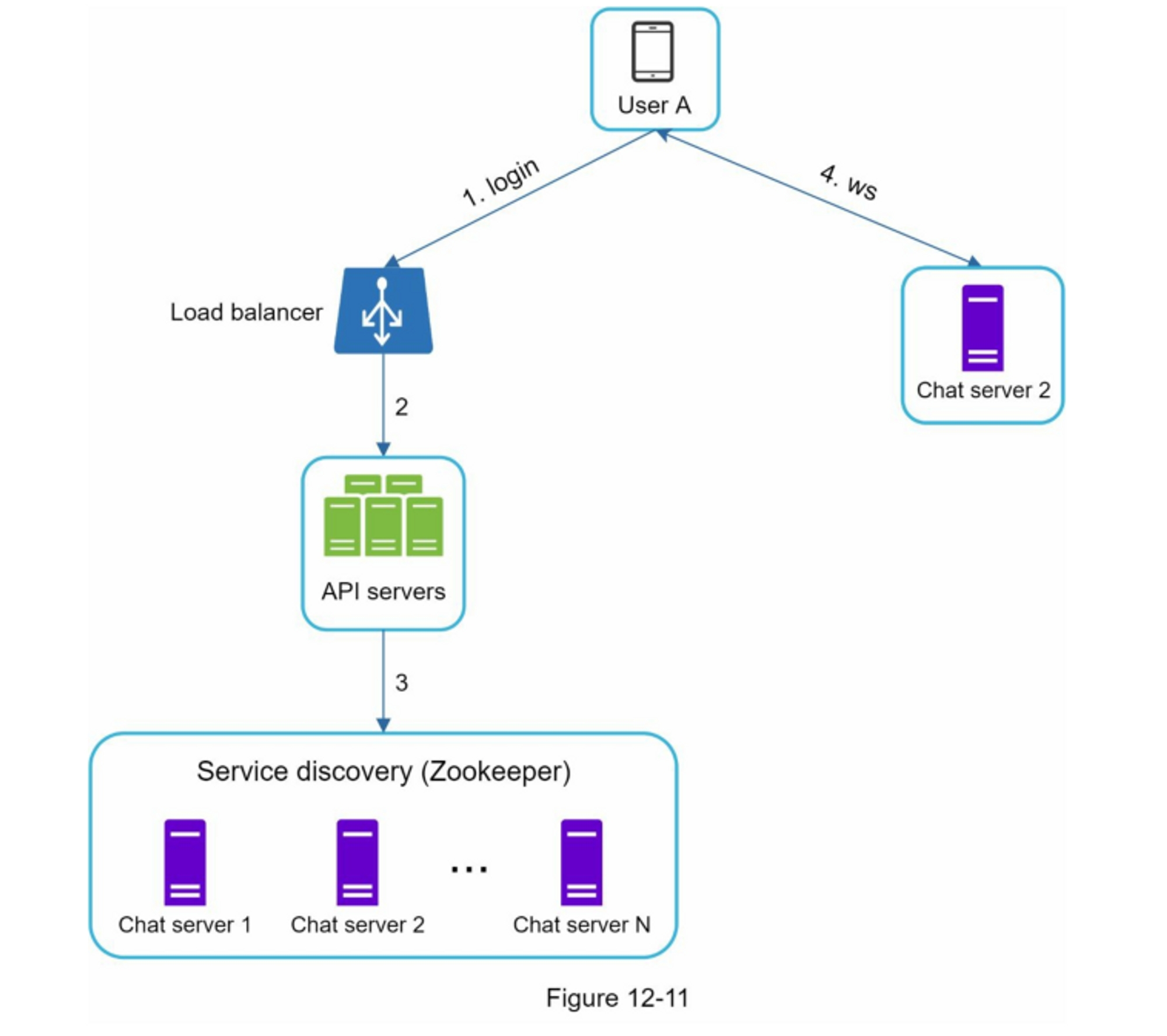
- 用户A尝试登录APP
- 负载均衡器发送登录请求到API服务
- 在后端认证用户后,服务发现为用户A找到最佳的聊天服务器。在这个例子中,服务器2被选中,服务器信息被返回给用户A。
- 用户A通过 WebSocket 连接到聊天服务器2。
消息流
了解一个聊天系统的端到端流程是很有趣的。在本节中,我们将探讨1对1的聊天流程、跨多个设备的信息同步和群组聊天流程。
1对1聊天
图12-12解释了当用户A向用户B发送消息时发生的情况。
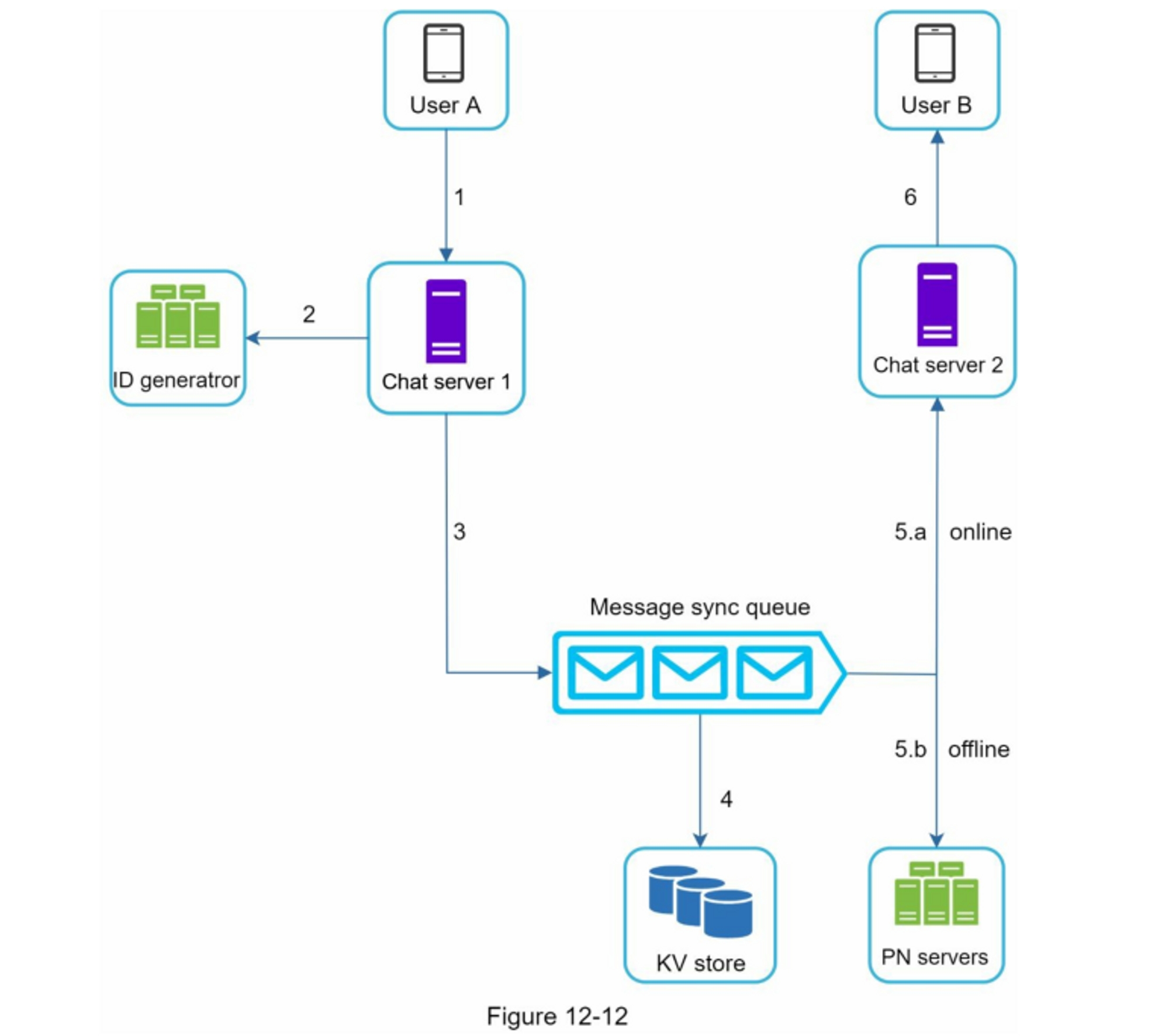
- 用户A向聊天服务器1发送了一条聊天信息。
- 聊天服务器1从ID生成器获得一个信息ID。
- 聊天服务器1将消息发送至消息同步队列。
- 消息被储存在一个键值存储中。
- a. 如果用户B在线,信息被转发到用户B所连接的聊天服务器2。
- b. 如果用户B处于离线状态,则从推送通知(PN)服务器发送推送通知。
- 聊天服务器2将消息转发给用户B,用户B和聊天服务器2之间有一个持久的WebSocket连接。
多个设备间的信息同步
许多用户有多个设备。我们将解释如何在多个设备上同步消息。图12-13显示了一个消息同步的例子。
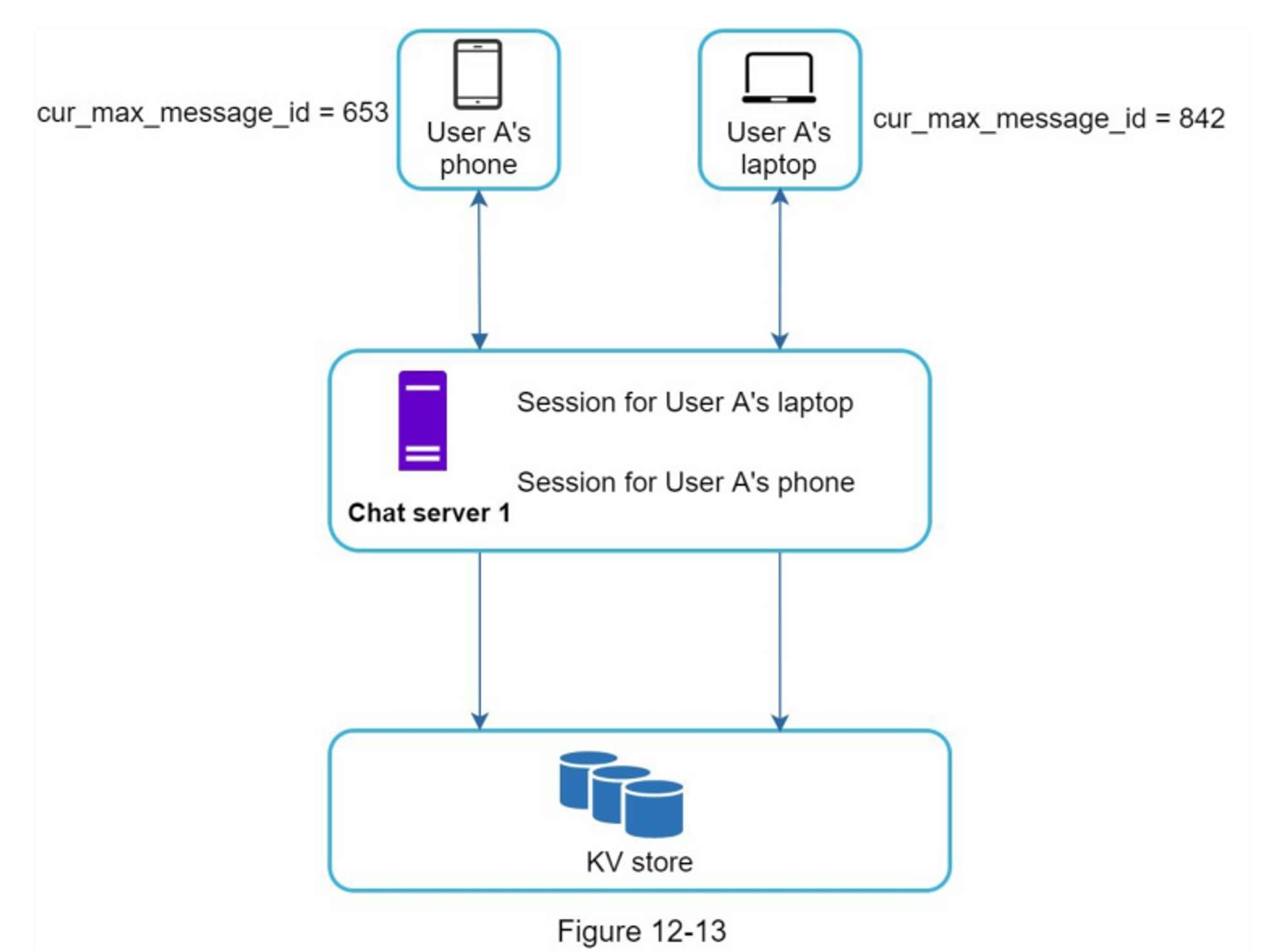
在图12-13中,用户A有两台设备:一台手机和一台笔记本电脑。当用户A用手机登录聊天应用程序时,它与聊天服务器1建立了一个WebSocket连接。同样地,笔记本电脑和聊天服务器1之间也有一个连接。
每个设备都维护着一个叫做 cur_max_message_id的变量,它记录着设备上最新的消息ID。满足以下两个条件的消息被认为是新消息。
- 收件人ID等于当前登录的用户ID。
- 键值存储中的消息ID大于
cur_max_message_id
由于每个设备上都有不同的 cur_max_message_id,信息同步很容易,因为每个设备都可以从键值存储获得新的信息。
群组聊天流程
与一对一的聊天相比,群组聊天的逻辑更加复杂。图12-14和12-15解释了这个流程。
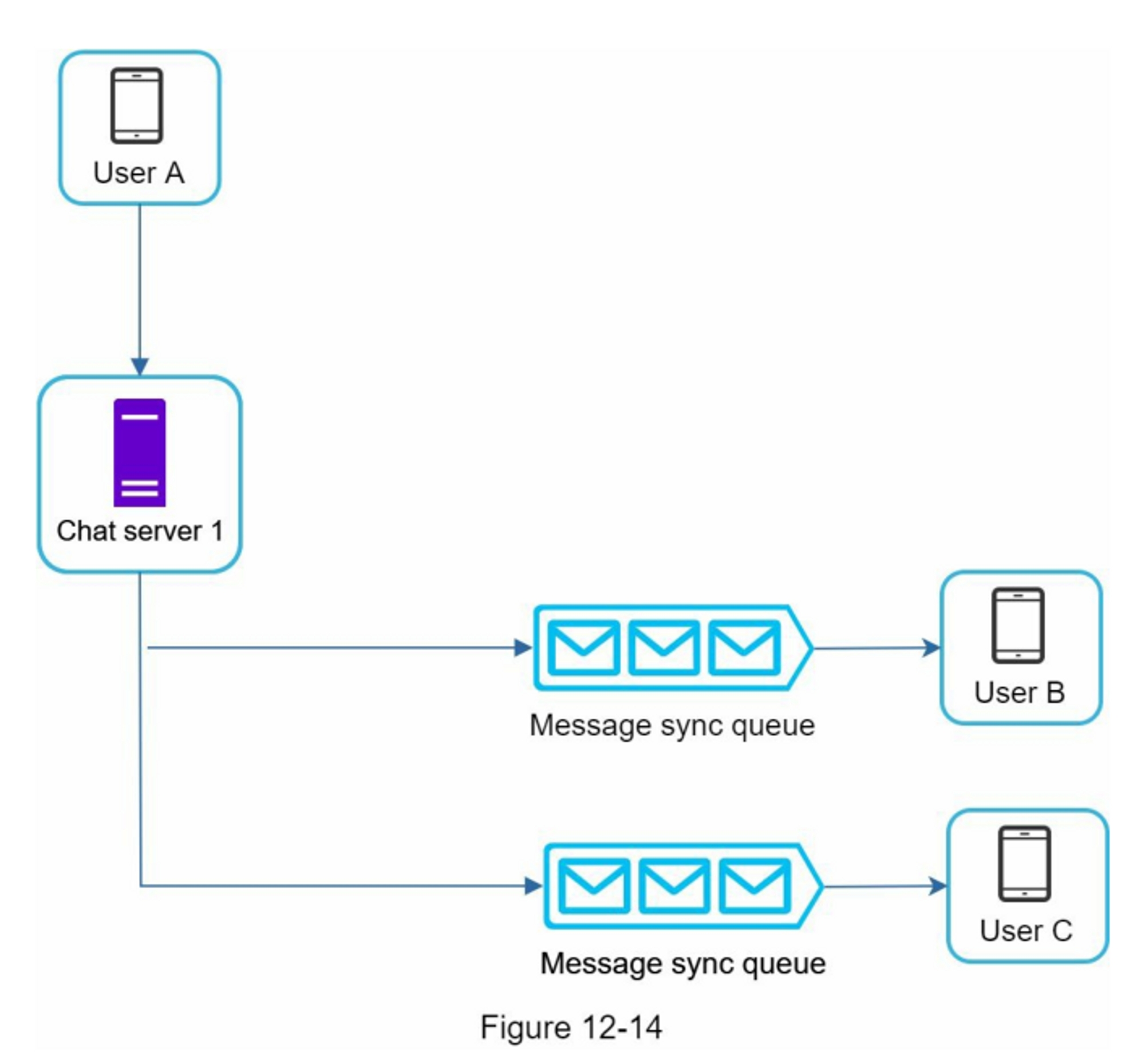
图12-14解释了用户A在群聊中发送消息时发生的情况。假设群里有3个成员(用户A、用户B和用户C)。首先,用户A的消息被复制到每个组员的消息同步队列中:一个给用户B,另一个给用户C。你可以把消息同步队列看成是一个收件人的收件箱。这种设计选择很适合小群组聊天,因为。
- 它简化了信息同步流程,因为每个客户只需要检查自己的收件箱就可以获得新的信息。
- 当群组人数较少时,在每个收件人的收件箱中存储一份副本并不太昂贵。
微信使用类似的方法,它将一个群组限制在500个成员[8]。然而,对于拥有大量用户的群组来说,为每个成员存储一份信息副本是不可接受的。
在收件人方面,一个收件人可以接收来自多个用户的信息。每个收件人都有一个收件箱(消息同步队列),其中包含来自不同发送者的消息。图12-15说明了这种设计。
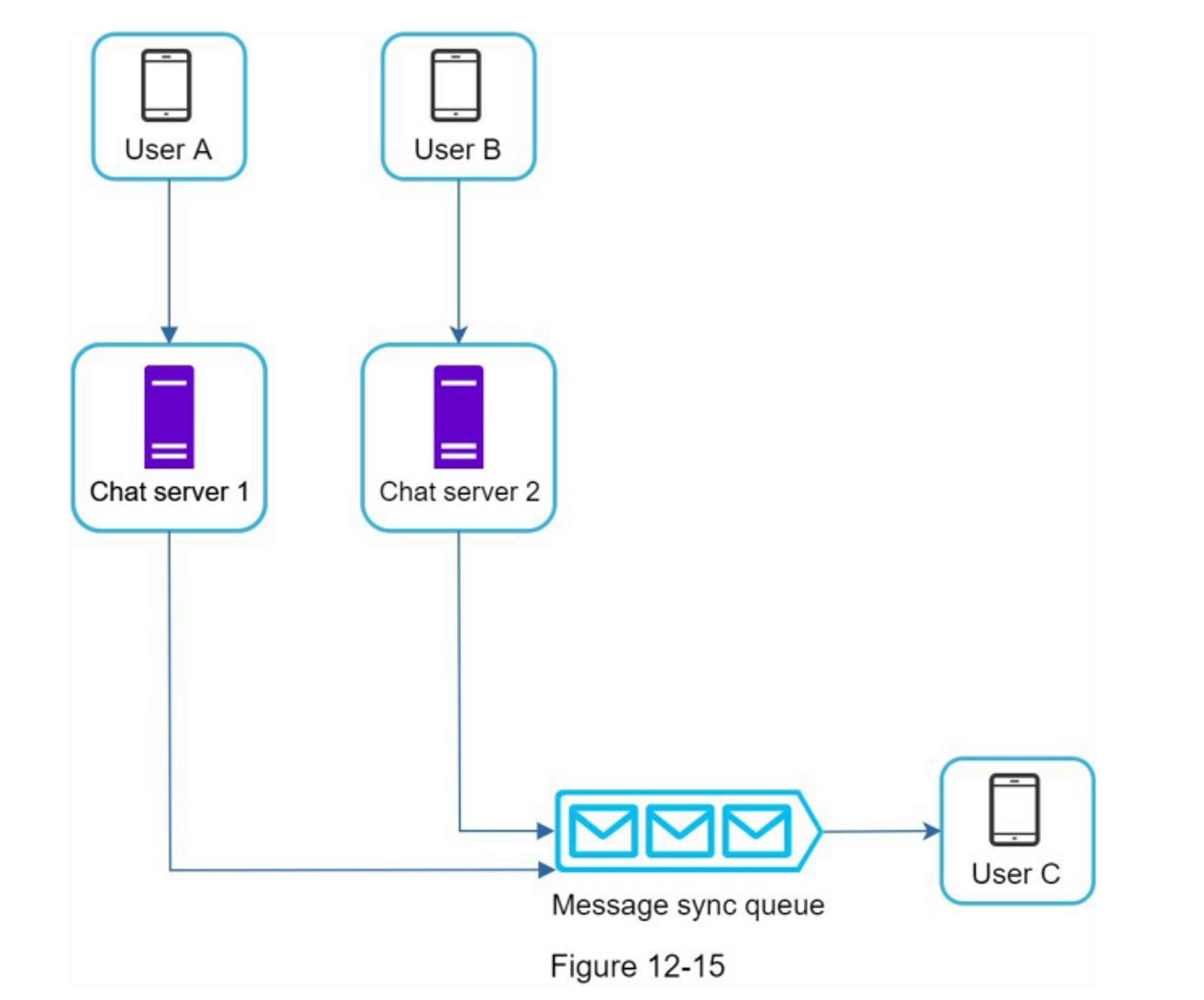
在线状态
在线状态指示器是许多聊天应用程序的一个基本功能。通常情况下,你可以在用户的个人照片或用户名旁边看到一个绿点。本节解释幕后发生的事情。
在高层设计中,在线服务器负责管理在线状态,并通过WebSocket与客户端进行通信。有几个流程会触发在线状态的变化。让我们来看看它们中的每一个。
用户登入
用户登录的流程在 "服务发现 "一节中解释。在客户端和实时服务之间建立WebSocket连接后,用户A的在线状态和最后活动时间戳被保存在KV存储中。状态指示器显示用户在登录后处于在线状态。
用户登出
当用户注销登录时,会经历如图 12-17 所示的用户注销流程。 KV store 中在线状态变为离线状态。 状态指示器显示用户离线。
用户断开连接
我们都希望我们的互联网连接是一致和可靠的。然而,情况并非总是如此;因此,我们必须在设计中解决这个问题。当一个用户从互联网上断开连接时,客户端和服务器之间的持久连接就会丢失。处理用户断开连接的一个天真的方法是将用户标记为离线,并在连接重新建立时将其状态改为在线。然而,这种方法有一个重大缺陷。用户在短时间内频繁地断开和重新连接到互联网是很常见的。例如,当用户通过隧道时,网络连接可能会打开和关闭。在每次断开/重新连接时更新在线状态会使存在指标变化得太频繁,导致用户体验不佳。
我们引入一个心跳机制来解决这个问题。定期地,一个在线客户端向状态服务器发送一个心跳事件。如果状态服务器在一定时间内收到心跳事件,比如说来自客户端的X秒,那么用户被认为是在线的。否则,它就处于离线状态。
在图12-18中,客户端每5秒向服务器发送一个心跳事件。在发送了3个心跳事件后,客户端被断开连接,并且在x=30秒内没有重新连接(这个数字是任意选择的,以演示逻辑)。在线状态被改变为离线。
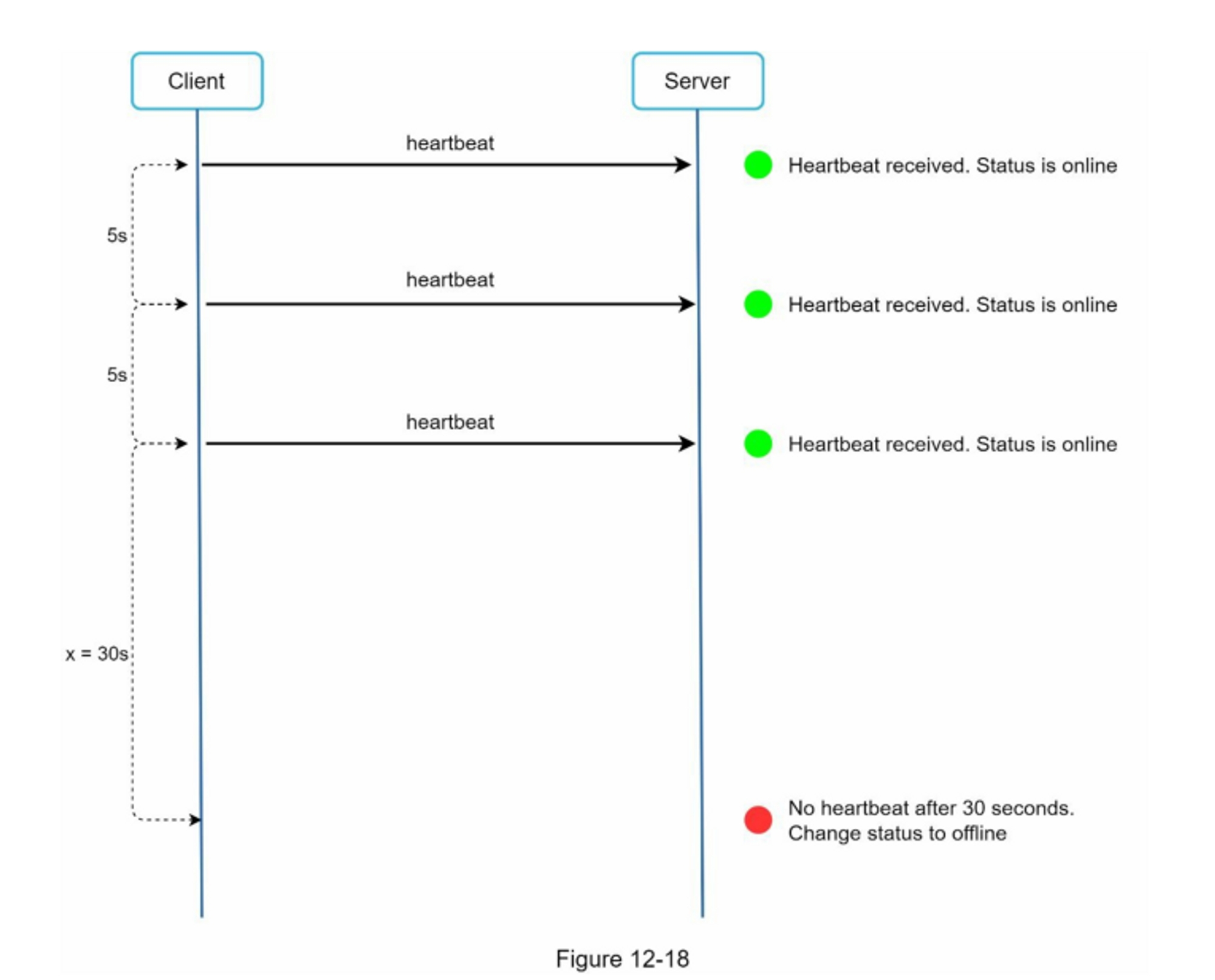
在线状态输出
用户 A 的好友如何知道状态变化? 图 12-19 解释了它是如何工作的。 状态服务器使用发布-订阅模型,其中每个朋友对都维护一个频道。 当用户A的在线状态发生变化时,将事件发布到三个频道,频道A-B,A-C,A-D。 这三个频道分别由用户 B、C 和 D 订阅。 因此,朋友们很容易获得在线状态更新。 客户端和服务器之间的通信是通过实时 WebSocket 进行的。
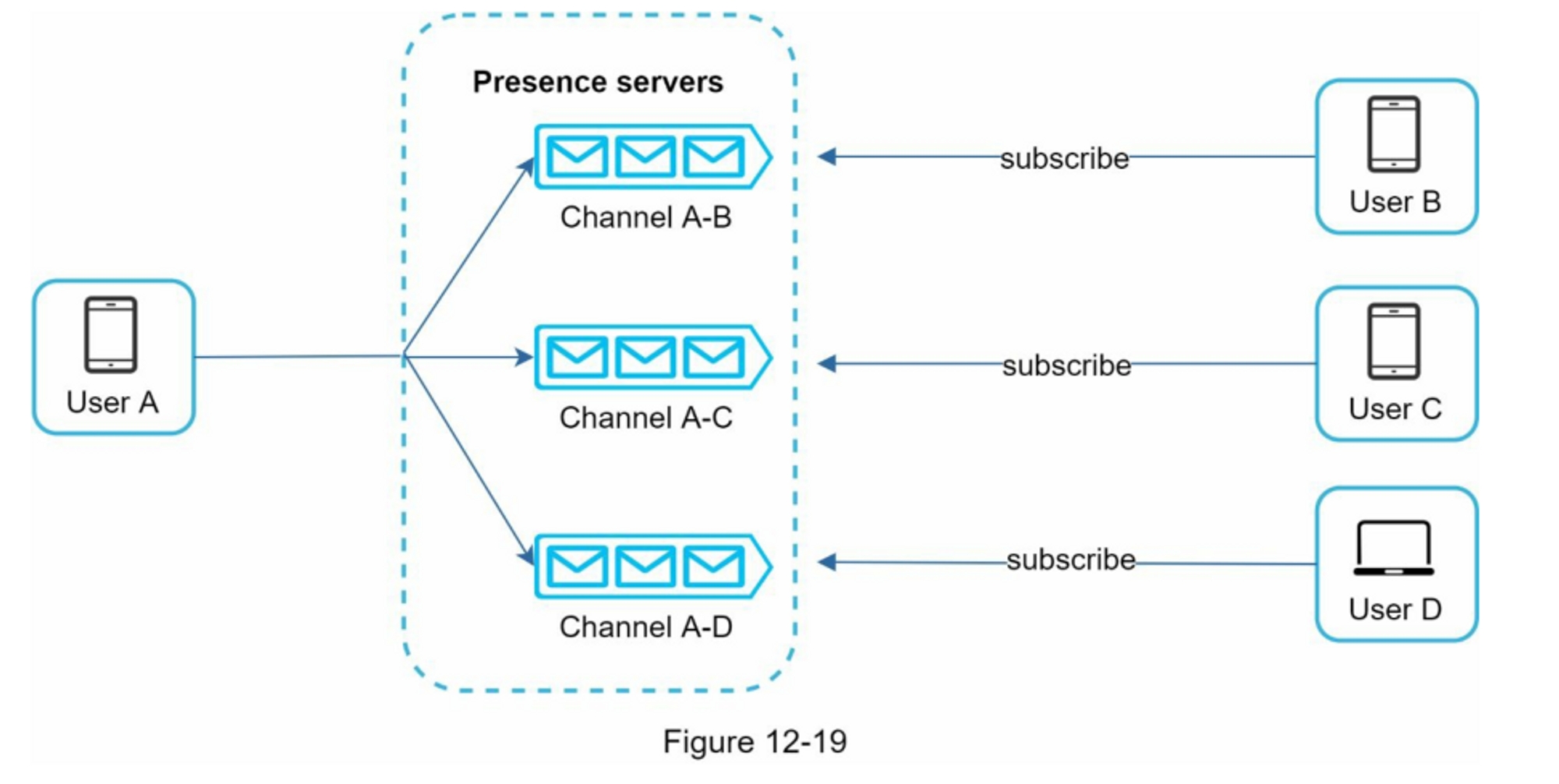
上述设计对小规模的用户群是有效的。例如,微信使用类似的方法,因为它的用户群上限为500人。对于较大的群组,通知所有成员的在线状态是昂贵和耗时的。假设一个群组有100,000个成员。每一个状态变化将产生100,000个事件。为了解决性能瓶颈,一个可能的解决方案是只在用户进入群组或手动刷新好友列表时获取在线状态。
第4步:总结
在本章中,我们介绍了一个聊天系统架构,它支持1对1的聊天和小群组聊天。WebSocket用于客户端和服务器之间的实时通信。聊天系统包含以下组件:用于实时消息传递的聊天服务器、用于管理在线状态的状态服务器、用于发送推送通知的推送通知服务器、用于聊天历史持久性的键值存储以及用于其他功能的API服务器。
如果你在面试结束时有多余的时间,这里有额外的谈话要点:
- 扩展聊天应用程序以支持媒体文件,如照片和视频。媒体文件的大小明显大于文本。压缩、云存储和缩略图是值得讨论的话题。
- 端到端加密。Whatsapp支持信息的端到端加密。只有发件人和收件人可以阅读信息。有兴趣的读者请参考参考资料中的文章[9]。
- 在客户端缓存信息,可以有效地减少客户端和服务器之间的数据传输。
- 提高加载时间。Slack建立了一个地理分布的网络来缓存用户的数据、频道等,以获得更好的加载时间[10]。
- 故障处理。
- 聊天服务器错误。可能有数十万,甚至更多的,坚持不懈的连接到一个聊天服务器。如果一个聊天服务器离线,服务发现(Zookeeper)会提供一个新的聊天服务器,让客户建立新的连接。
- 消息重发机制。重试和排队是重发消息的常用技术。
恭喜你走到了这一步!现在给自己一个鼓励,干得漂亮![Goo][1]
参考资料
- [1] Erlang at Facebook: https://www.erlang-factory.com/upload/presentations/31/EugeneLetuchy-ErlangatFacebook.pdf
- [2] Messenger and WhatsApp process 60 billion messages a day: https://www.theverge.com/2016/4/12/11415198/facebook-messenger-whatsapp-number-messages-vs-sms-f8-2016
- [3] Long tail: https://en.wikipedia.org/wiki/Long_tail
- [4] The Underlying Technology of Messages: https://www.facebook.com/notes/facebook-engineering/the-underlying-technology-of-messages/454991608919/
- [5] How Discord Stores Billions of Messages: https://blog.discordapp.com/how-discord-stores-billions-of-messages-7fa6ec7ee4c7
- [6] Announcing Snowflake: https://blog.twitter.com/engineering/en_us/a/2010/announcing-snowflake.html
- [7] Apache ZooKeeper: https://zookeeper.apache.org/
- [8] From nothing: the evolution of WeChat background system (Article in Chinese): https://www.infoq.cn/article/the-road-of-the-growth-weixin-background
- [9] End-to-end encryption: https://faq.whatsapp.com/820124435853543/
- [10] Flannel: An Application-Level Edge Cache to Make Slack Scale: https://slack.engineering/flannel-an-application-level-edge-cache-to-make-slack-scale-b8a6400e2f6b
第13章:设计一个搜索自动完成系统
当你在谷歌上搜索或在亚马逊购物时,在搜索框中输入,会有一个或多个与搜索词相匹配的内容呈现给你。这一功能被称为自动完成、提前输入、边输入边搜索或增量搜索。图13-1是谷歌搜索的一个例子,当在搜索框中输入"dinner"时,显示了一个自动完成的结果列表。搜索自动完成是许多产品的一个重要功能。这就把我们引向了面试问题:设计一个搜索自动完成系统,也叫 "设计 top k "或 "设计 top k 搜索最多的查询"。
第1步:了解问题并确定设计范围
解决任何系统设计面试问题的第一步是提出足够多的问题来阐明需求。 这是候选人与面试官互动的示例:
候选人:是否只支持在搜索查询的开始阶段进行匹配,还是在中间也支持?
面试官:只有在搜索查询的开始阶段。
候选人:系统应该返回多少个自动完成的建议?
面试官:5
候选人:系统如何知道要返回哪5条建议?
面试官:这是由受欢迎程度决定的,由历史查询频率决定。
应聘者:系统是否支持拼写检查?
面试官:不,不支持拼写检查或自动更正。
候选人:搜索查询是用英语吗?
面试官:是的。如果最后时间允许,我们可以讨论多语言支持。
候选人:我们允许大写字母和特殊字符吗?
面试官:不,我们假设所有的搜索查询都是小写字母。
候选人:有多少用户使用该产品?
面试官:1000万DAU。
需求
以下是对要求的总结:
- 快速的响应时间:当用户输入搜索查询时,自动完成的建议必须足够快地显示出来。一篇关于Facebook自动完成系统的文章[1]显示,该系统需要在100毫秒内返回结果,否则会造成卡顿。
- 相关性:自动完成的建议应该与搜索词相关。
- 已排序:系统返回的结果必须按受欢迎程度或其他排名模式进行排序。
- 可扩展性:该系统可以处理高流量。
- 高度可用:当系统的一部分脱机、速度减慢或遇到意外的网络错误时,系统应保持可用和可访问。
粗略估算
- 假设有1000万日活跃用户(DAU)
- 一个人平均每天进行10次搜索。
- 每个查询字符串有20字节的数据。
- 假设我们使用ASCII字符编码。1个字符=1个字节
- 假设一个查询包含4个词,而每个词平均包含5个字符。
- 也就是说,每次查询有 $$4 \times 5 = 20个字节$$。
- 对于在搜索框中输入的每个字符,客户端都会向后端发送请求以获取自动完成建议。 平均而言,每个搜索查询会发送 20 个请求。 例如,当您输入完 "dinner" 时,以下 6 个请求将发送到后端。
search?q=dsearch?q=disearch?q=dinsearch?q=dinnsearch?q=dinnesearch?q=dinner
- $$QPS \approx 24,000次/秒 = 10,000,000用户 \times 10次/天 \times 20个字符/24小时/3600秒 $$。
- $$峰值QPS = QPS \times 2 \approx 48,000$$
- 假设 20% 的日常查询是新的。 $$1000 万 \times 10 个查询/天 \times 每个查询 20 字节 \times 20 % = 0.4 GB$$。 这意味着每天有 0.4GB 的新数据被添加到存储中。
第2步:提出高层次的设计方案并获得认同
在高层次上,该系统被分解成两个部分。
- 数据收集服务:它收集用户的输入查询,并实时汇总它们。对于大型数据集来说,实时处理是不实际的;但是,它是一个很好的起点。我们将在深入研究中探索一个更现实的解决方案。
- 查询服务:给定一个搜索查询或前缀,返回5个最经常搜索的术语。
数据收集服务
让我们用一个简化的例子来看看数据收集服务是如何工作的。假设我们有一个频率表,存储查询字符串和它的频率,如图13-2所示。在开始时,频率表是空的。后来,用户依次输入查询 "twitch"、"twitter"、"twitter "和 "twillo"。图13-2显示了频率表的更新情况。
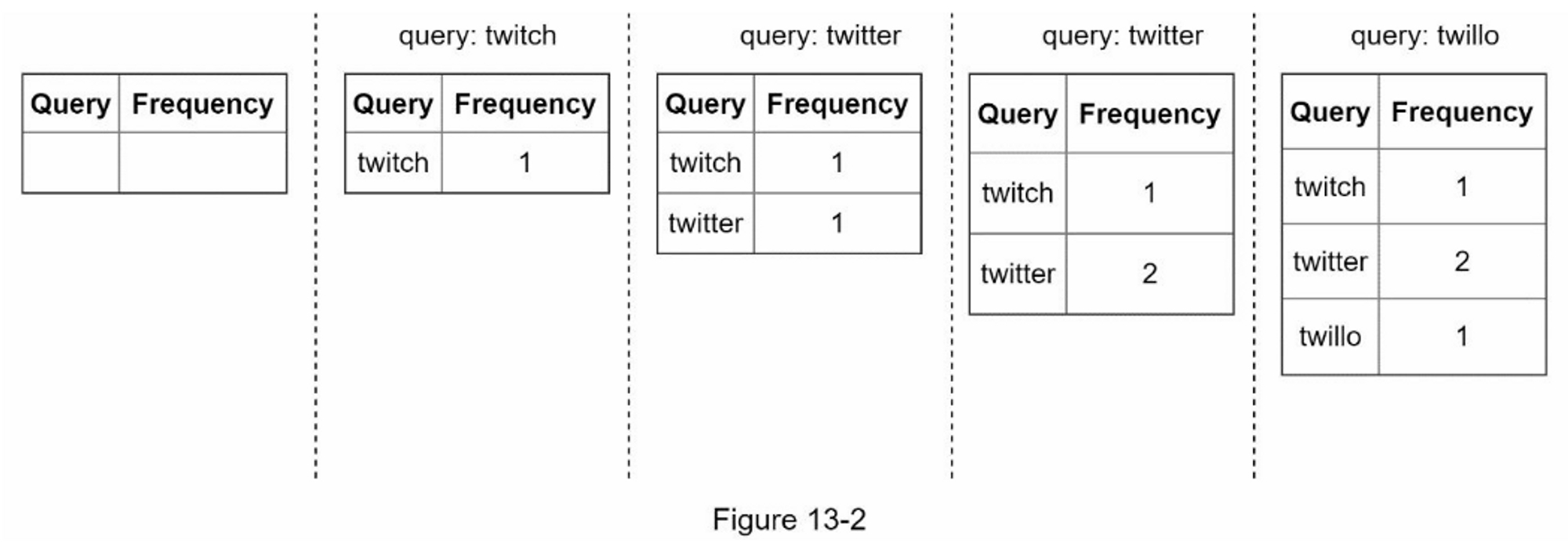
查询服务
假设我们有一个频率表,如表13-1所示。它有两个字段。
Query:它存储查询字符串。
Frequency:它代表一个查询被搜索的次数。

当用户在搜索框中输入 "tw" 时,假设频率表以表13-1为基础,就会显示以下前5个被搜索的查询(图13-3)。

要获得前5个经常搜索的查询,执行以下SQL查询。

当数据集较小时,这是一个可以接受的解决方案。当它很大时,访问数据库就会成为一个瓶颈。我们将在深入探讨优化问题。
第3步:深入设计
在高层次设计中,我们讨论了数据收集服务和查询服务。高层设计并不是最优的,但它是一个很好的起点。在这一节中,我们将深入研究几个组件,并探讨以下的优化方法。
- Trie 数据结构
- 数据收集服务
- 数据查询
- 扩展存储
- Trie 操作
Trie 数据结构
在高层设计中,关系型数据库被用于存储。然而,从关系型数据库中获取前5个搜索查询是低效的。数据结构trie(前缀树)被用来克服这个问题。由于trie数据结构对系统至关重要,我们将投入大量时间来设计一个定制的trie。请注意,一些想法来自文章[2]和[3]。
了解基本的tree数据结构对于这个面试问题来说是至关重要的。然而,这更像是一个数据结构问题,而不是一个系统设计问题。此外,许多在线材料都解释了这个概念。
在本章中,我们将只讨论trie数据结构的概述,并重点讨论如何优化基本trie以提高响应时间。
Trie(发音为“try”)是一种树状数据结构,可以紧凑地存储字符串。 该名称来自单词检索(retrieval),这表明它是为字符串检索操作而设计的。
trie 的主要思想包括以下内容:
- trie是一种树状的数据结构。
- 根代表一个空字符串。
- 每个节点存储一个字符并有 26 个子节点,每个节点对应一个可能的字符。 为了节省空间,我们不绘制空链接。
- 每个树节点代表一个单词或一个前缀字符串。
图13-5显示了一个带有搜索查询 "tree"、"try"、"true"、"toy"、"wish"、"win "的 trie。搜索查询以较粗的边框突出显示。
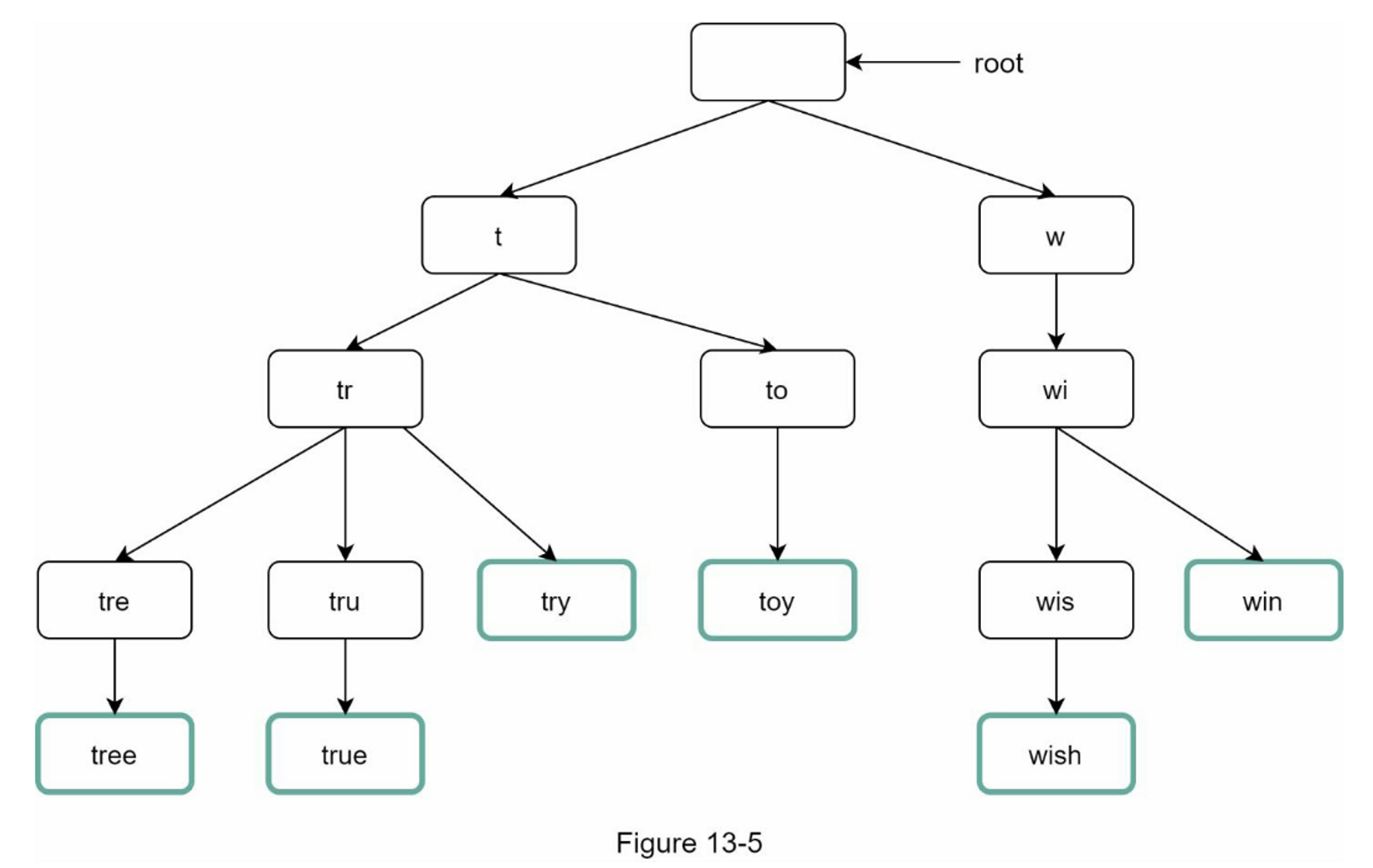
基本的trie数据结构在节点中存储字符。为了支持按频率排序,频率信息需要包含在节点中。假设我们有以下频率表。
在向节点添加频率信息后,更新的 trie 数据结构如图 13-6 所示。
自动完成是如何在Trie中工作的?在深入研究该算法之前,让我们先定义一些术语:
- p:前缀的长度
- n:trie中的总节点数量
- c:一个给定节点的子女数
下面列出了获得前 k 个搜索最多的查询的步骤:
- 找到前缀。时间复杂度: $$O(p)$$。
- 从前缀节点遍历子树,得到所有有效的子节点。如果一个子节点能够形成一个有效的查询字符串,它就是有效的。时间复杂度: $$O(c)$$
- 对孩子节点进行排序并获得前 k。 时间复杂度: $$O(c \log c)$$
让我们用一个如图13-7所示的例子来解释这个算法。假设k等于2,一个用户在搜索框中输入 "tr"。该算法的工作原理如下。
- 第一步:找到前缀节点 "tr"。
- 第二步:遍历子树以获得所有有效的子节点。在这种情况下,节点[tree:10]、[true:35]、[try:29]是有效的。
- 第3步:对孩子节点进行排序,得到前两名。[true: 35]和[try: 29]是前缀为 "tr "的前两个查询。
这个算法的时间复杂度是上述每个步骤所花费的时间之和。 $$O(p) + O(c) + O(c \log c)$$
上述算法很简单,但是,它太慢了,因为在最坏的情况下,我们需要遍历整个 trie 来获得前 k 个结果。
下面是两个优化方案。
- 限制前缀的最大长度
- 缓存每个节点的热门搜索查询
限制前缀的最大长度
用户很少在搜索框中键入长搜索查询。 因此,可以安全地说 p 是一个小整数,比如 50。如果我们限制前缀的长度,“查找前缀”的时间复杂度可以从 $$O(p)$$ 降低到 $$O(small constant)$$, 又名 $$O(1)$$。
缓存每个节点的热门搜索查询
为了避免遍历整个 trie,我们在每个节点存储前 k 个最常用的查询。 由于 5 到 10 个自动完成建议对用户来说就足够了,因此 k 是一个相对较小的数字。 在我们的具体案例中,只有前 5 个搜索查询被缓存。
通过在每个节点缓存热门搜索查询,我们显着降低了检索前 5 个查询的时间复杂度。 但是,这种设计需要大量空间来存储每个节点的热门查询。
以空间换时间是非常值得的,因为快速响应时间非常重要。
图13-8显示了更新后的 trie 数据结构。每个节点上都存储了前5个查询。例如,前缀为 "be" 的节点存储以下内容。[best: 35, bet: 29, bee: 20, be: 15, beer: 10]。
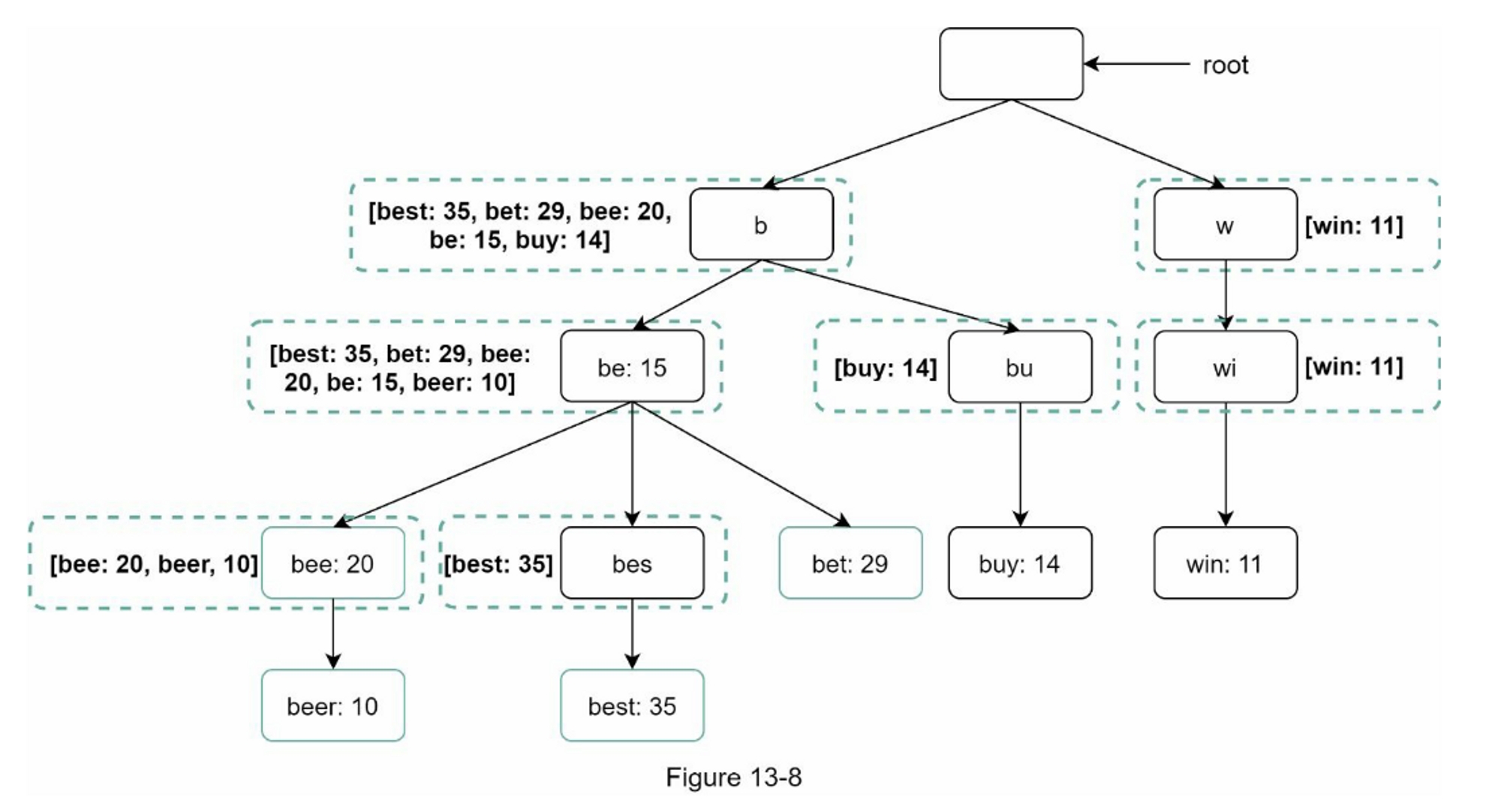
让我们重新审视一下应用这两个优化后的算法的时间复杂性。
- 找到前缀节点。时间复杂度: $$O(1)$$
- 返回前 k。 由于缓存了前 k 个查询,因此这一步的时间复杂度为 $$O(1)$$。 随着每个步骤的时间复杂度降低到 $$O(1)$$,我们的算法只需要 $$O(1)$$ 来获取前 k 个查询。
数据收集服务
在我们以前的设计中,每当用户键入一个搜索查询,数据就会实时更新。由于以下两个原因,这种方法并不实用。
- 用户每天可能会输入数十亿次的查询。在每次查询中更新 trie,会大大减慢查询服务的速度。
- 构建 trie 后,热门建议可能不会有太大变化。 因此,没有必要经常更新 trie。
为了设计可扩展的数据收集服务,我们检查数据的来源和使用方式。 像 Twitter 这样的实时应用程序需要最新的自动完成建议。 但是,许多 Google 关键字的自动完成建议每天可能不会有太大变化。
尽管用例不同,但数据收集服务的底层基础保持不变,因为用于构建 trie 的数据通常来自分析或日志服务。
图 13-9 显示了重新设计的数据收集服务。 每个组件都经过一一检查。
-
Analytics Logs(分析性日志):
它存储有关搜索查询的原始数据。 日志是附加的,没有索引。 表 13-3 显示了日志文件的示例。
-
Aggregators(聚合器)
分析日志的大小通常非常大,而且数据格式不正确。 我们需要汇总数据,以便我们的系统可以轻松处理这些数据。
根据用例,我们可能会以不同方式聚合数据。 对于 Twitter 等实时应用程序,我们会在较短的时间间隔内聚合数据,因为实时结果很重要。 另一方面,以较低的频率聚合数据,比如每周一次,对于许多用例来说可能就足够了。 在面试过程中,验证实时结果是否重要。 我们假设 trie 每周重建一次。
-
Aggregated Data(聚合数据)
表 13-4 显示了每周聚合数据的示例。 "time" 字段表示一周的开始时间。"frequency" 字段是相应查询在该周内出现的总和。
-
Workers
工作者是一组服务器,以固定的时间间隔执行异步工作。他们建立Trie数据结构并将其存储在Trie DB中。
-
Trie Cache
Trie Cache是一个分布式缓存系统,它将Trie保存在内存中,以便快速读取。它每周对数据库进行一次快照。
-
Trie DB
Trie DB是持久性存储。有两个选项可用于存储数据。
-
文档数据库
由于每周都会建立一个新的trie,我们可以定期对其进行快照,序列化,并将序列化后的数据存储在数据库中。 像 MongoDB [4] 这样的文档存储非常适合序列化数据。
-
键值存储
可以通过应用以下逻辑以哈希表形式 [4] 表示一个 Trie 树:
- trie 中的每个前缀都映射到哈希表中的键。
- 每个 trie 节点上的数据都映射到哈希表中的一个值。
图 13-10 显示了 trie 和哈希表之间的映射。
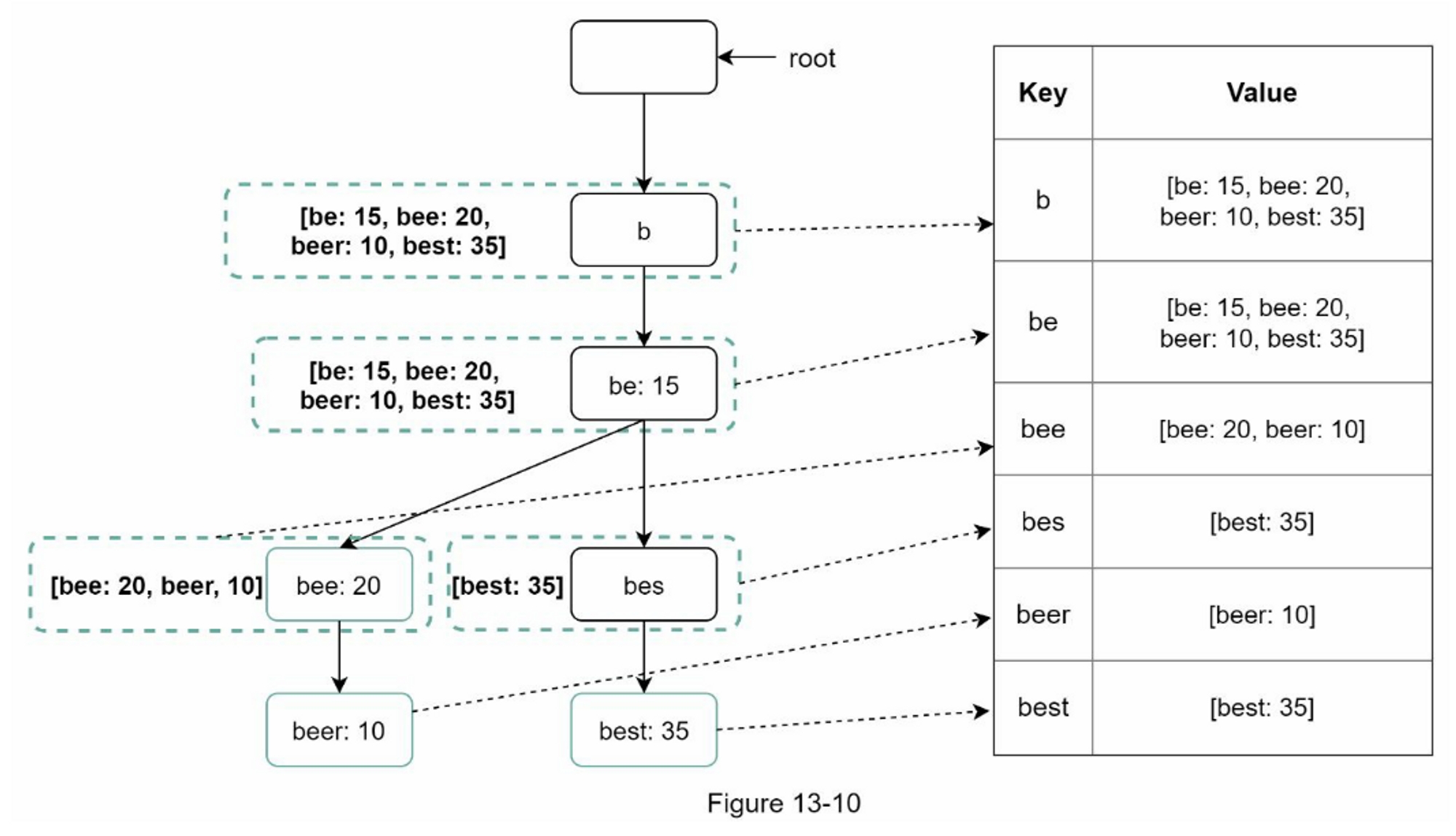
在图13-10中,左边的每个 trie 节点被映射到右边的 <key, value> 对。如果你不清楚键值存储如何工作,请参考第6章:设计键值存储。
-
查询服务
在高层设计中,查询服务直接调用数据库来获取前5个结果。图13-11显示了改进后的设计,因为之前的设计效率很低。
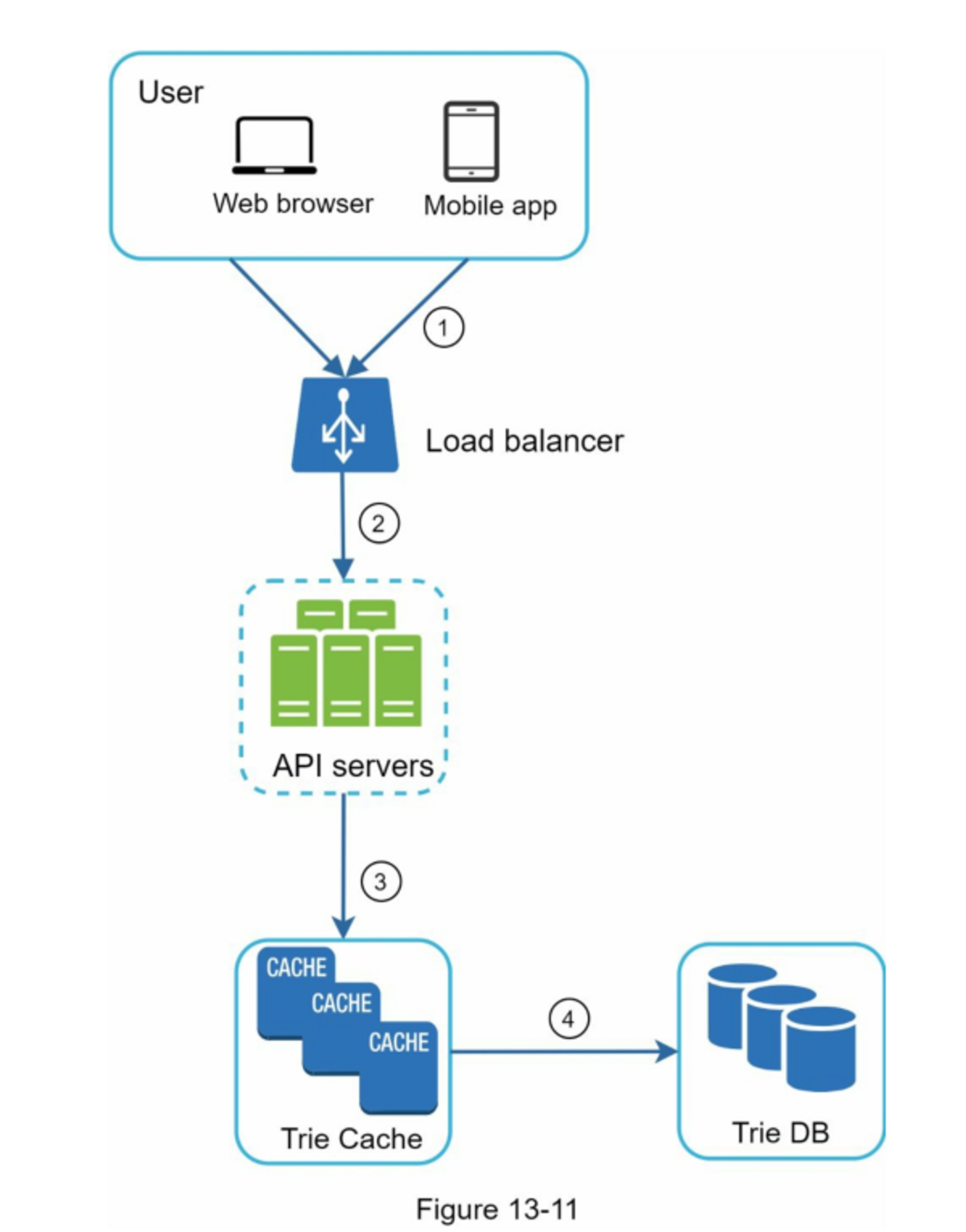
- 一个搜索查询被发送到负载均衡器。
- 负载均衡器将请求路由到API服务器。
- API服务器从Trie Cache获得Trie数据,并为客户端构建自动完成建议。
- 如果数据不在Trie Cache中,我们会将数据补充到缓存中。这样一来,所有对同一前缀的后续请求都从缓存中返回。当缓存服务器没有内存或脱机时,就会发生缓存缺失。
查询服务需要闪电般的速度。 我们提出以下优化:
-
AJAX 请求:对于 Web 应用程序,浏览器通常会发送 AJAX 请求来获取自动完成结果。 AJAX 的主要好处是发送/接收请求/响应不会刷新整个网页。
-
浏览器缓存:对于许多应用程序,自动完成搜索建议可能不会在短时间内发生太大变化。 因此,自动完成建议可以保存在浏览器缓存中,以允许后续请求直接从缓存中获取结果。 Google 搜索引擎使用相同的缓存机制。 图 13-12 显示了当您在 Google 搜索引擎上键入 "system design interview" 时的响应标题。 如您所见,Google 将结果缓存在浏览器中 1 小时。 请注意:缓存控制中的
private意味着结果仅供单个用户使用,不得由共享缓存缓存。max-age=3600表示缓存的有效期为 3600 秒,也就是一个小时。
-
数据采样:对于大型系统,记录每个搜索查询需要大量的处理能力和存储空间。 数据采样很重要。 例如,系统仅记录每 N 个请求中的 1 个。
Trie 操作
Trie 是自动完成系统的核心组件。 让我们看看 trie 操作(创建、更新和删除)是如何工作的。
创建
Trie 是由工作人员使用聚合数据创建的。 数据源来自 Analytics Log/DB。
更新
有两种方法可以更新 trie。
方法一:每周更新 trie。一旦创建了新的 trie,新的 trie 将取代旧的 trie。
方法二:直接更新单个 trie 节点。 我们尽量避免这种操作,因为它很慢。 但是,如果 trie 的大小很小,这是一个可以接受的解决方案。 当我们更新一个 trie 节点时,它一直到根的祖先都必须更新,因为祖先存储子节点的热门查询。 图 13-13 显示了更新操作如何工作的示例。 在左侧,搜索查询“beer”的原始值为 10。在右侧,它更新为 30。如您所见,节点及其祖先的 "beer" 值已更新为 30。
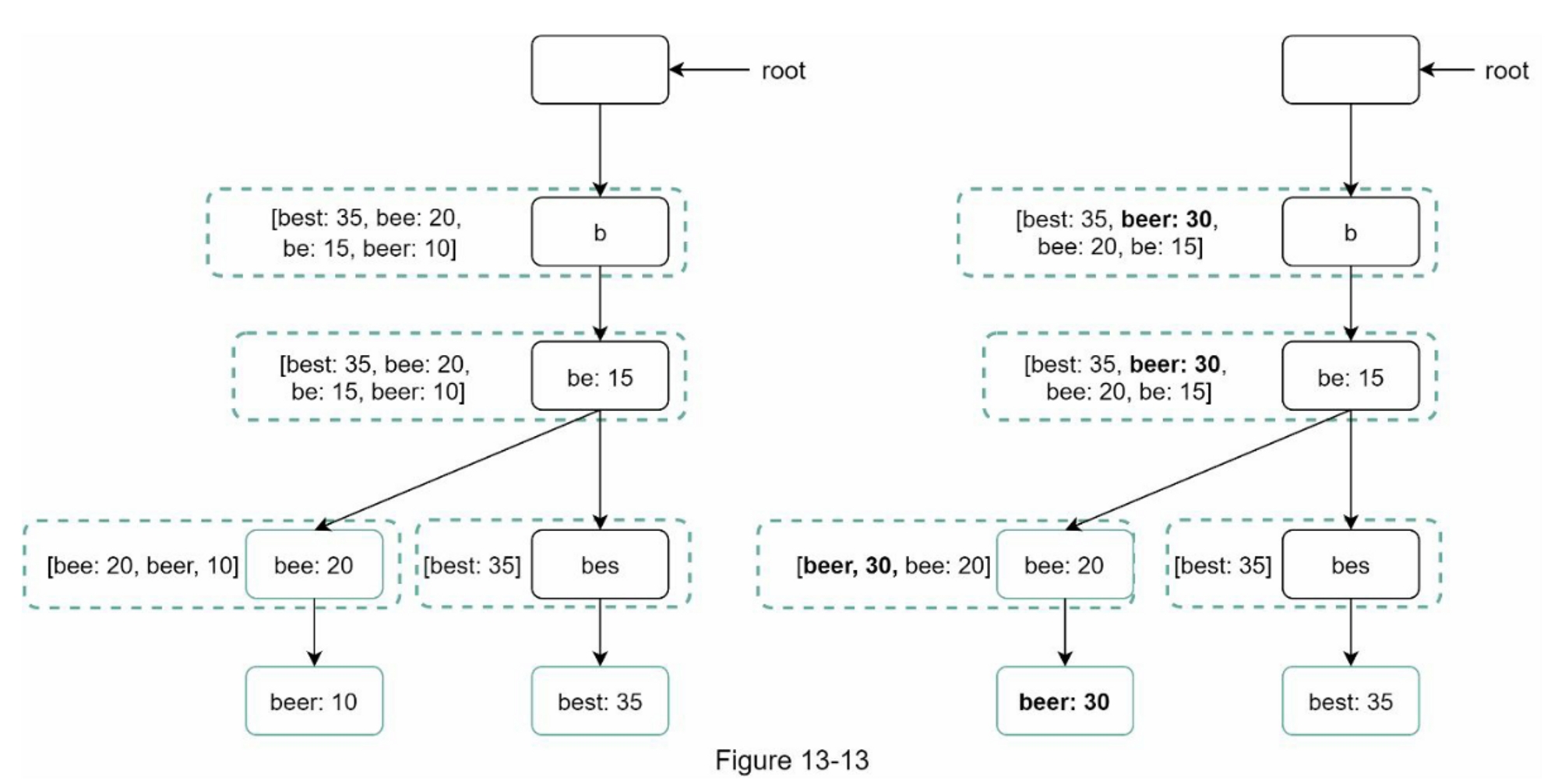
删除
我们必须删除仇恨、暴力、色情或危险的自动完成建议。 我们在 Trie 缓存前面添加一个过滤层(图 13-14)以过滤掉不需要的建议。
拥有过滤层使我们能够灵活地根据不同的过滤规则删除结果。
不需要的建议会以异步方式从数据库中物理删除,以便在下一个更新周期中使用正确的数据集来构建 trie。
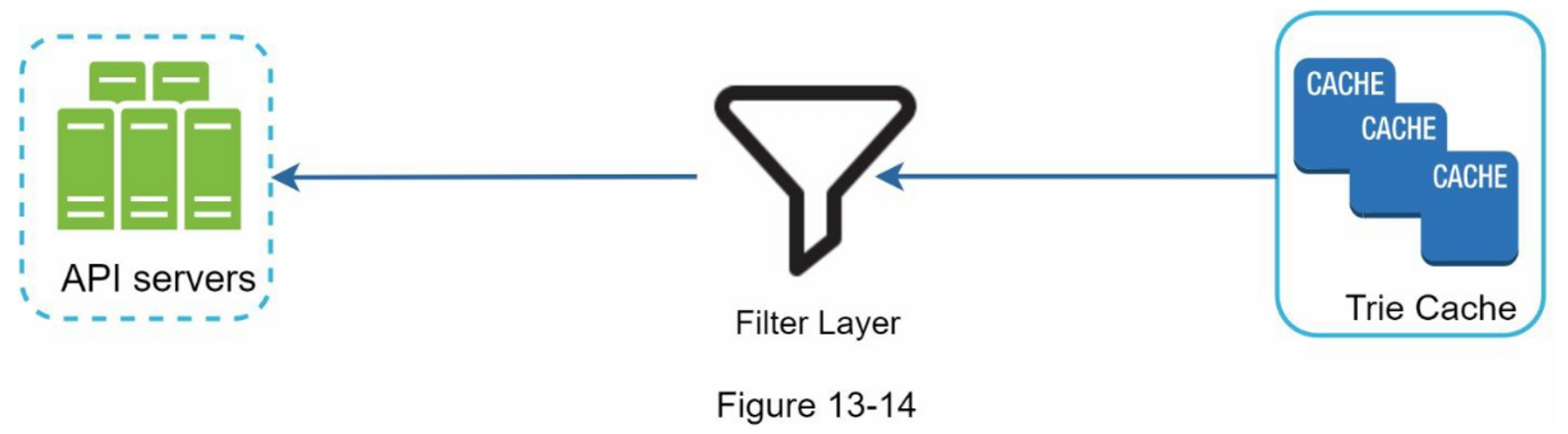
扩展存储
现在我们已经开发了一个系统,将自动完成的查询带给用户,现在是时候解决当 trie 增长到无法在一台服务器中容纳时的可扩展性问题了。
由于英语是唯一被支持的语言,一种简单的分片方式是基于第一个字符。这里有一些例子。
- 如果我们需要两台服务器来存储,我们可以在第一台服务器上存储从'a'到'm'的查询,而在第二台服务器上存储'n'到'z'的查询。
- 如果我们需要三个服务器,我们可以把查询分成'a'到'i','j'到'r'和's'到'z'。
按照这个逻辑,我们可以将查询分成26个服务器,因为英语中有26个字母。让我们把基于第一个字符的分片定义为第一层分片。要存储超过26个服务器的数据,我们可以在第二层甚至第三层进行分片。例如,以'a'开头的数据查询可以分成4个服务器:'aa-ag','ah- an','ao-au'和'av-az'。
乍一看,这种方法似乎很合理,直到你意识到以字母'c'开头的单词比'x'多得多。这就造成了分布不均。
为了缓解数据不平衡问题,我们分析历史数据分布模式并应用更智能的分片逻辑,如图 13-15 所示。 分片映射管理器维护一个查找数据库,用于标识应将行存储在何处。 例如,如果对 "s" 和 "u"、"v"、"w"、"x"、"y" 和 "z" 的合并历史查询数量相似,我们可以维护两个分片:一个 用于 "s",一个用于 "u" 到 "z"。
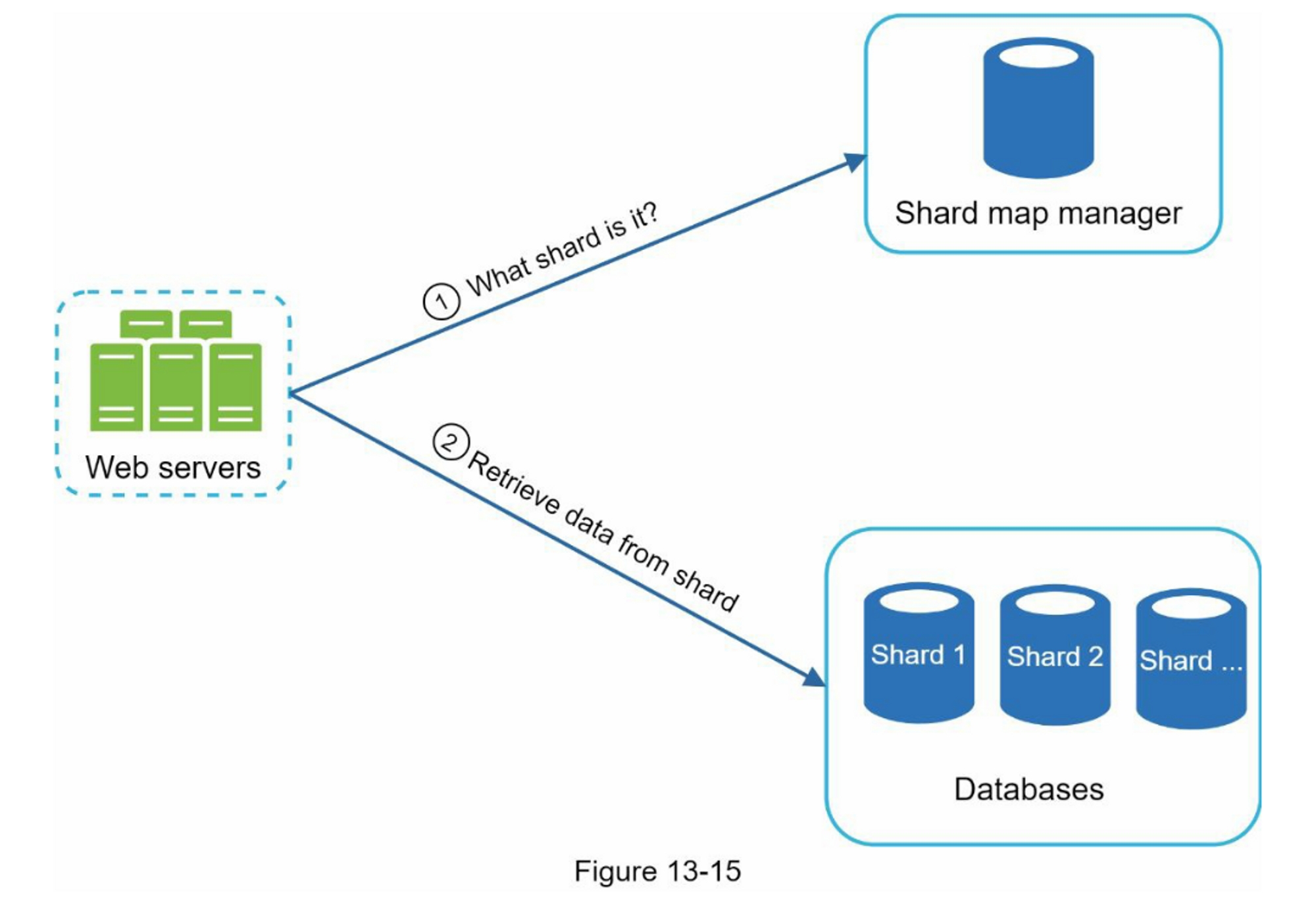
第4步:总结
在你完成深入探讨后,你的面试官可能会问佴一些后续问题。
面试官:你如何扩展你的设计以支持多语言?
为了支持其他非英语查询,我们将 Unicode 字符存储在 trie 节点中。 如果您不熟悉 Unicode,这里是定义:“一种编码标准涵盖了世界上所有现代和古代书写系统的所有字符”[5]。
面试官:如果一个国家/地区的热门搜索查询与其他国家/地区不同怎么办?
在这种情况下,我们可能会为不同的国家建立不同的 trie。 为了缩短响应时间,我们可以将 trie 存储在 CDN 中。
面试官:我们如何支持趋势(实时)搜索查询?
假设一个新闻事件爆发了,一个搜索查询突然变得很流行。我们原来的设计将无法工作,因为:
- 离线工人还没有安排更新 trie,因为这被安排在每周的基础上运行。
- 即使安排了,也需要太长的时间来建立 trie。
构建一个实时搜索的自动完成器是很复杂的,超出了本书的范围,所以我们只给出一些想法:
- 通过分片减少工作数据集。
- 更改排名模型并为最近的搜索查询分配更多权重。
- 数据可能以流的形式出现,因此我们无法一次访问所有数据。 流数据意味着数据是连续产生的。 流处理需要一组不同的系统:Apache Hadoop MapReduce [6]、Apache Spark Streaming [7]、Apache Storm [8]、Apache Kafka [9] 等。因为所有这些主题都需要特定的领域知识,所以我们不会 在这里详细介绍。
恭喜你走到了这一步!现在给自己一个鼓励,干得漂亮!
参考资料
- [1] The Life of a Typeahead Query: https://www.facebook.com/notes/facebook-engineering/the-life-of-a-typeahead-query/389105248919/
- [2] How We Built Prefixy: A Scalable Prefix Search Service for Powering Autocomplete: https://medium.com/@prefixyteam/how-we-built-prefixy-a-scalable-prefix-search-service-for-powering-autocomplete-c20f98e2eff1
- [3] Prefix Hash Tree An Indexing Data Structure over Distributed Hash Tables: https://people.eecs.berkeley.edu/~sylvia/papers/pht.pdf
- [4] MongoDB wikipedia: https://en.wikipedia.org/wiki/MongoDB
- [5] Unicode frequently asked questions: https://www.unicode.org/faq/basic_q.html
- [6] Apache hadoop: https://hadoop.apache.org/
- [7] Spark streaming: https://spark.apache.org/streaming/
- [8] Apache storm: https://storm.apache.org/
- [9] Apache kafka: https://kafka.apache.org/documentation
第14章:设计 YouTube
在本章中,你被要求设计YouTube。这个问题的解决方案可以应用于其他面试问题,如设计一个视频共享平台,如Netflix和Hulu。图14-1显示了YouTube的主页。
YouTube 看起来很简单:内容创作者上传视频,观众点击播放。 真的那么简单吗? 并不真地。 简单的背后隐藏着许多复杂的技术。 让我们来看看 2020 年 YouTube 的一些令人印象深刻的统计数据、人口统计数据和有趣的事实 [1] [2]。
- 每月活跃用户总数:20亿。
- 每天观看的视频数量:50亿。
- 73%的美国成年人使用 YouTube。
- 在 YouTube 上有5000万创作者。
- 2019年全年,YouTube 的广告收入为151亿美元,比2018年增长36%。
- YouTube 占所有移动互联网流量的37%。
- YouTube 有80种不同的语言。
从这些统计数据中,我们知道YouTube是巨大的、全球性的,并且赚了很多钱。
第1步:了解问题并确定设计范围
如图14-1所示,除了观看视频,你还可以在YouTube上做很多事情。例如,评论、分享或喜欢一个视频,将一个视频保存到播放列表中,订阅一个频道,等等。在45或60分钟的面试中,不可能设计所有内容。
因此,提出问题以缩小范围是很重要的。
候选人:哪些功能是重要的?
面试官:能够上传视频和观看视频。
候选人:我们需要支持哪些客户?
面试官:移动应用、浏览器和智能电视。
候选人:我们有多少日活跃用户?
面试官:500万
候选人:平均每天花在产品上的时间是多少?
面试官:30分钟。
候选人:我们需要支持国际用户吗?
面试官:是的,很大比例的用户是国际用户。
候选人:支持的视频分辨率是多少?
面试官:本系统接受大部分的视频分辨率和格式。
候选人:是否需要加密?
面试官:是的。
候选人:对视频的文件大小有要求吗?
面试官:我们的平台专注于小型和中型的视频,允许的最大视频大小为1GB。
候选人:我们能否利用亚马逊、谷歌或微软提供的一些现有云计算基础设施?
面试官:这是个好问题。对于大多数公司来说,从头开始建立一切是不现实的,建议利用一些现有的云服务。
在这一章中,我们着重于设计一个具有以下特点的视频流媒体服务:
- 快速上传视频的能力
- 流畅的视频流
- 能够改变视频的质量
- 基础设施成本低
- 高可用性、可扩展性和可靠性的要求
- 支持的客户端:移动应用、浏览器和智能电视
粗略估计
下面的估计是基于许多假设,所以与面试官沟通以确保和她在同一起跑线上是很重要的。
- 假设该产品有500万日活跃用户(DAU)。
- 用户每天观看5个视频。
- 10%的用户每天上传1个视频。
- 假设平均视频大小为300MB。
- 每天需要的总存储空间。 $$500万 \times 10 % \times 300MB = 150TB$$
- CDN成本
- 当云计算CDN提供视频时,你要为从CDN传输出来的数据付费。
- 让我们使用亚马逊的CDN CloudFront进行成本估算(图14-2)[3]。假设100%的流量都来自美国。每GB的平均成本为0.02美元。为简单起见,我们只计算视频流的成本。
- $$500万 \times 5个视频 \times 0.3GB \times 0.02美元 = 15万美元/天$$
从粗略的成本估算中,我们知道从CDN提供视频的成本很高。即使云供应商愿意为大客户大幅降低CDN成本,但成本仍然很高。我们将深入讨论降低CDN成本的方法。
第2步:提出高层次的设计方案并获得认同
如前所述,面试官建议利用现有的云服务,而不是从头开始构建所有内容。 CDN 和 blob 存储是我们将利用的云服务。 有些读者可能会问为什么不自己构建所有东西? 原因如下:
- 系统设计面试并不是要从头开始建立一切。在有限的时间内,选择正确的技术来做好一项工作比详细解释技术的工作原理更重要。例如,提到用于存储源视频的blob存储就足以应付面试了。谈论blob存储的详细设计可能是一种矫枉过正。
- 构建可扩展的blob存储或CDN是非常复杂和昂贵的。即使像Netflix或Facebook这样的大公司也不会自己建立一切。Netflix利用亚马逊的云服务[4],而Facebook使用Akamai的CDN[5]。
在高层次上,该系统由三个部分组成(图14-3)。
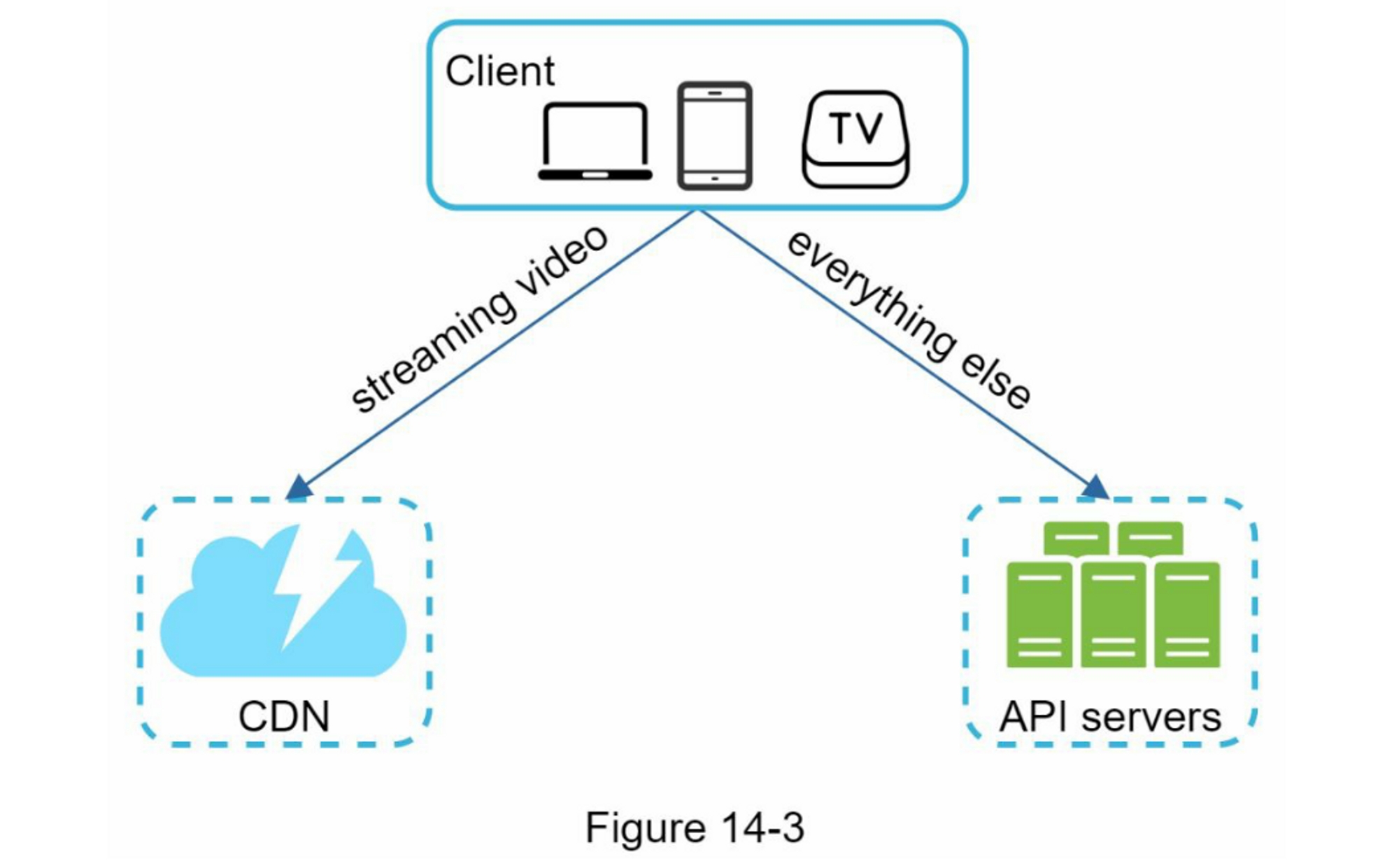
Client:你可以在你的电脑、手机和智能电视上观看YouTube。
CDN:视频被存储在CDN中。当你按下播放键时,视频就会从CDN上流传下来。
API servers:除了视频流之外的所有其他内容都通过 API 服务器。 这包括提要推荐、生成视频上传 URL、更新元数据数据库和缓存、用户注册等。
在问答环节,面试官表现出对两个流程的兴趣:
- 视频上传流程
- 视频流
我们将探讨其中每一个的高层设计。
视频上传流程
图14-4显示了视频上传的高级设计。
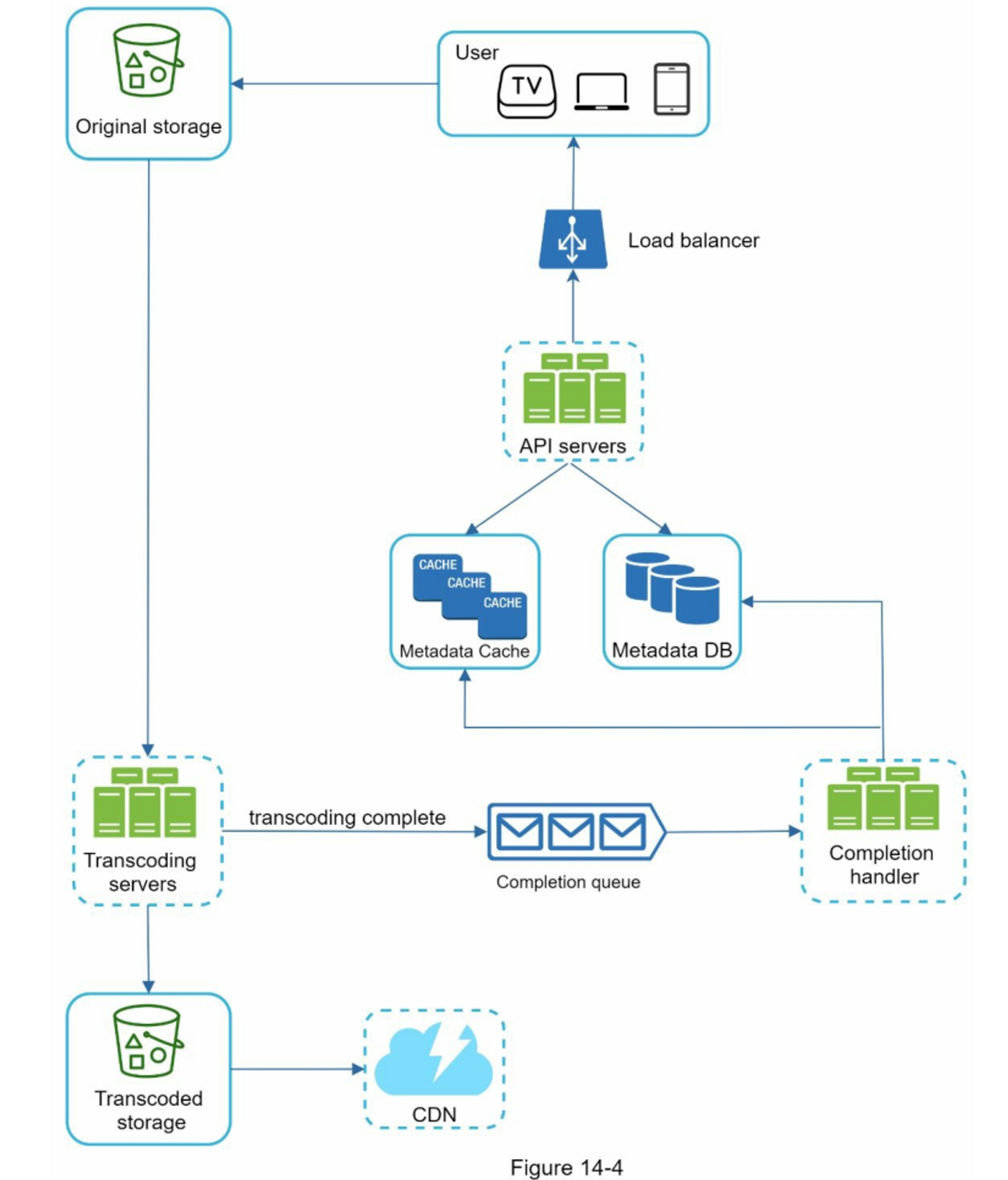
它由以下几个部分组成:
- User(用户):用户在电脑、移动电话或智能电视等设备上观看YouTube。
- Load balancer(负载均衡器):负载平衡器在API服务器之间均匀地分配请求。
- API servers(API服务):除了视频流,所有用户请求都要通过API服务器。
- Metadata DB(元数据数据库):视频元数据被存储在元数据数据库中。它是分片和复制的,以满足性能和高可用性要求。
- Metadata cache(元数据缓存):为了提高性能,视频元数据和用户对象被缓存起来。
- Original storage(原始存储):blob存储系统用来存储原始视频。维基百科中关于blob存储的一段引文显示。"二进制大对象(BLOB)是数据库管理系统中作为单一实体存储的二进制数据的集合" [6]。
- Transcoding servers(转码服务器):视频转码也被称为视频编码。它是将一种视频格式转换为其他格式(MPEG、HLS等)的过程,为不同设备和带宽能力提供可能的最佳视频流。
- Transcoded storage(转码存储):它是一个储存转码视频文件的blob存储。
- CDN(内容分发网络):视频被缓存在CDN中。当你点击播放按钮时,视频会从CDN上流传下来。
- Completion queue(完成队列):它是一个消息队列,存储有关视频转码完成事件的信息。
- Completion handler(完成处理程序):他由一个工作者列表组成,从完成队列中提取事件数据并更新元数据缓存和数据库。
现在我们已经单独了解了每个组件,让我们来看看视频上传流程是如何工作的。该流程被分解为两个平行运行的过程。
-
上传真正的视频。
-
更新视频元数据。元数据包含有关视频URL、大小、分辨率、格式、用户信息等信息。
-
流程 1:上传真正的视频
图 14-5 显示了如何上传真正的视频。 解释如下图:
- 视频被上传到原始的存储空间。
- 转码服务器从原始存储中获取视频并开始转码。
- 一旦转码完成,以下两个步骤将被平行执行。
- 转码后的视频被发送到转码后的存储空间。
- 转码完成事件被排在完成队列中。
- (3a.1)转码后的视频被分发到CDN。
- (3b.1)完成处理程序包含一堆工作者,他们不断地从队列中提取事件数据。
- (3a.1和3b.1)完成处理程序在视频转码完成后更新元数据数据库和缓存。
- API服务器通知客户,视频已经成功上传,可以进行流媒体播放。
-
流程2:更新视频元数据
当文件被上传到原始存储区时,并行的客户端会发送一个更新视频元数据的请求,如图14-6所示。该请求包含视频元数据,包括文件名、大小、格式等。API服务器更新元数据缓存和数据库。
视频流
当你在YouTube上观看一个视频时,它通常立即开始流媒体,你不会等到整个视频被下载。下载意味着整个视频被复制到你的设备上,而流媒体意味着你的设备不断接收来自远程源视频的视频流。当你观看流媒体视频时,你的客户端每次加载一点数据,所以你可以立即和连续地观看视频。
在我们讨论视频流媒体流程之前,让我们看看一个重要的概念:流媒体协议。这是一种控制视频流数据传输的标准化方式。
流行的流媒体协议有:
- MPEG–DASH:MPEG代表 "移动图像专家组",DASH代表 "HTTP动态自适应流"。
- 苹果 HLS:HLS是 "HTTP实时流媒体 "的缩写。
- 微软 Smooth Streaming。
- Adobe HTTP动态流(HDS)。
你不需要完全理解甚至记住这些流媒体协议的名称,因为它们是需要特定领域知识的低层次细节。这里重要的是要明白,不同的流媒体协议支持不同的视频编码和播放机。当我们设计一个视频流媒体服务时,我们必须选择正确的流媒体协议来支持我们的用例。要了解更多关于流媒体协议的信息,这里有一篇优秀的文章[7]。
视频是直接从CDN流式传输的。离你最近的边缘服务器将提供视频。因此,延迟非常小。图14-7显示了视频流的高层次设计。
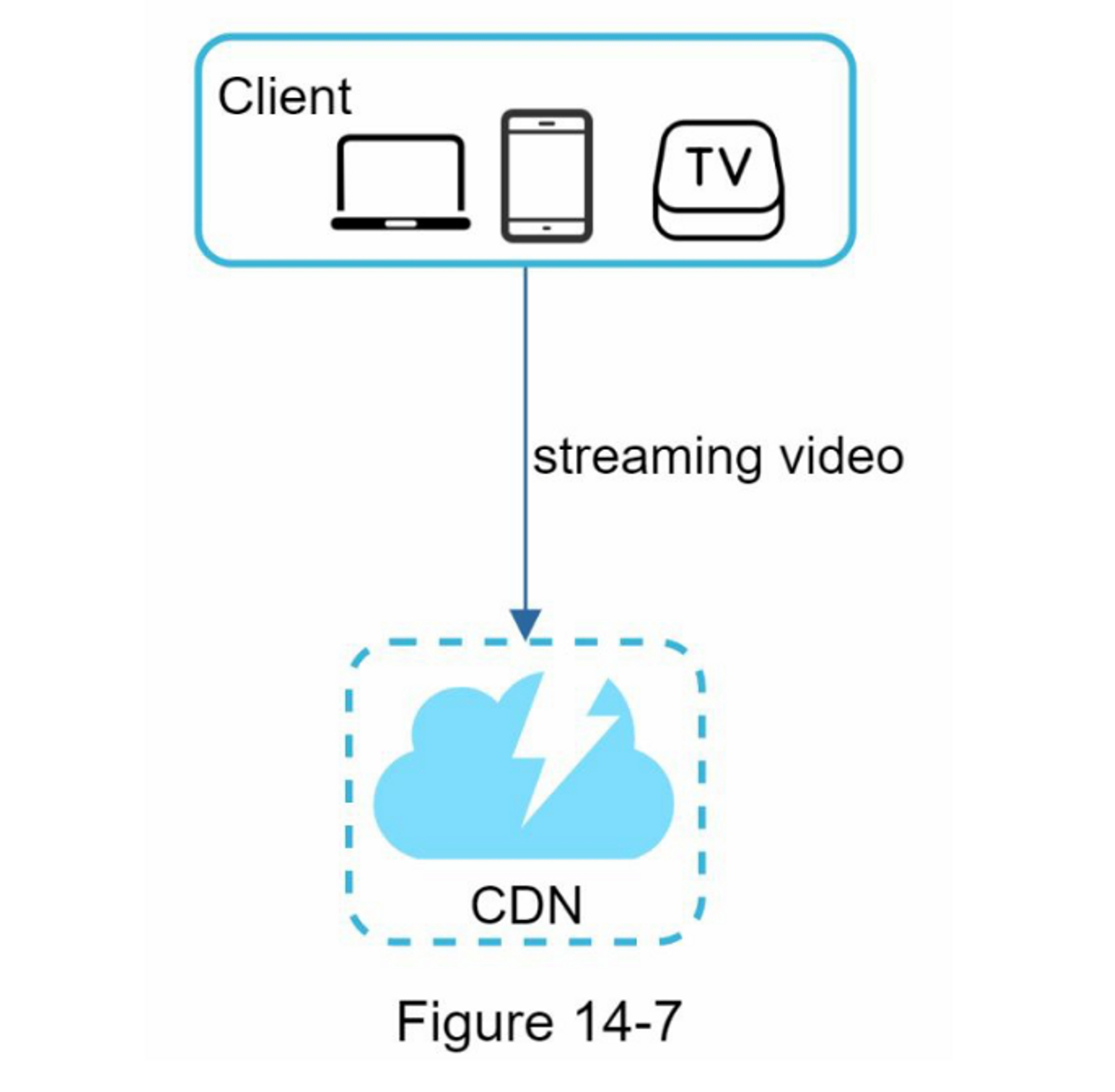
第3步:深入设计
在高层次的设计中,整个系统被分解成两个部分:视频上传流程和视频流。在本节中,我们将通过重要的优化来完善这两个流程,并引入错误处理机制。
视频转码
当你录制视频时,设备(通常是手机或相机)会给视频文件一定的格式。如果你想让视频在其他设备上顺利播放,视频必须被编码为兼容的比特率和格式。比特率是指随着时间推移,比特被处理的速度。更高的比特率通常意味着更高的视频质量。高比特率流需要更多的处理能力和快速的互联网速度。
视频转码是很重要的,原因如下:
- 原始视频会消耗大量的存储空间。一段长达一小时的高清视频以每秒60帧的速度录制,可以占用几百GB的空间。
- 许多设备和浏览器只支持某些类型的视频格式。因此,出于兼容性的考虑,将视频编码为不同的格式是很重要的。
- 为了确保用户在观看高质量视频的同时保持流畅的播放,向拥有高网络带宽的用户提供更高分辨率的视频,向拥有低带宽的用户提供低分辨率的视频是一个好主意。
- 网络条件会发生变化,特别是在移动设备上。为确保视频的连续播放,根据网络条件自动或手动切换视频质量对用户的流畅体验至关重要。
有许多类型的编码格式;然而,它们中的大多数都包含两部分:
- 容器:这就像一个篮子,包含视频文件、音频和元数据。你可以通过文件扩展名来判断容器的格式,如.avi、.mov或.mp4。
- 编码解码器:这些是压缩和解压算法,旨在减少视频尺寸,同时保留视频质量。最常用的视频编解码器是H.264、VP9和HEVC。
有向无环图(DAG)模型
转码视频的计算成本很高,而且很耗时。此外,不同的内容创建者可能有不同的视频处理要求。例如,有些内容创作者需要在他们的视频上面加水印,有些人自己提供缩略图,有些人上传高清视频,而有些人则不需要。
为了支持不同的视频处理管道并保持高度的并行性,必须增加一些抽象的层次,让客户端程序员定义执行什么任务。例如,Facebook的流媒体视频引擎使用了一个有向无环图(DAG)编程模型,它分阶段定义任务,因此它们可以顺序或平行地执行[8]。在我们的设计中,我们采用类似的DAG模型来实现灵活性和并行性。
图14-8表示一个用于视频转码的DAG。
在图14-8中,原始视频被分割成视频、音频和元数据。下面是一些可以应用于视频文件的任务。
- Inspection:确保视频有良好的质量,并且没有畸形。
- Video encodings:视频被转换以支持不同的分辨率、编解码器、比特率等。图14-9显示了一个视频编码文件的例子。
- Thumbnail:缩略图可以由用户上传或由系统自动生成。
- Watermark:视频封面,包含关于你的视频的识别信息。
视频转码架构
提议利用云服务的视频转码架构如图14-10所示。
该架构有六个主要组成部分:预处理器(preprocessor)、DAG调度器(DAG scheduler)、资源管理器(resource manager)、任务工作者(task workers,)、临时存储(temporary storage,)和作为输出的编码视频(encoded video a)。让我们仔细看看每个组件。
预处理器
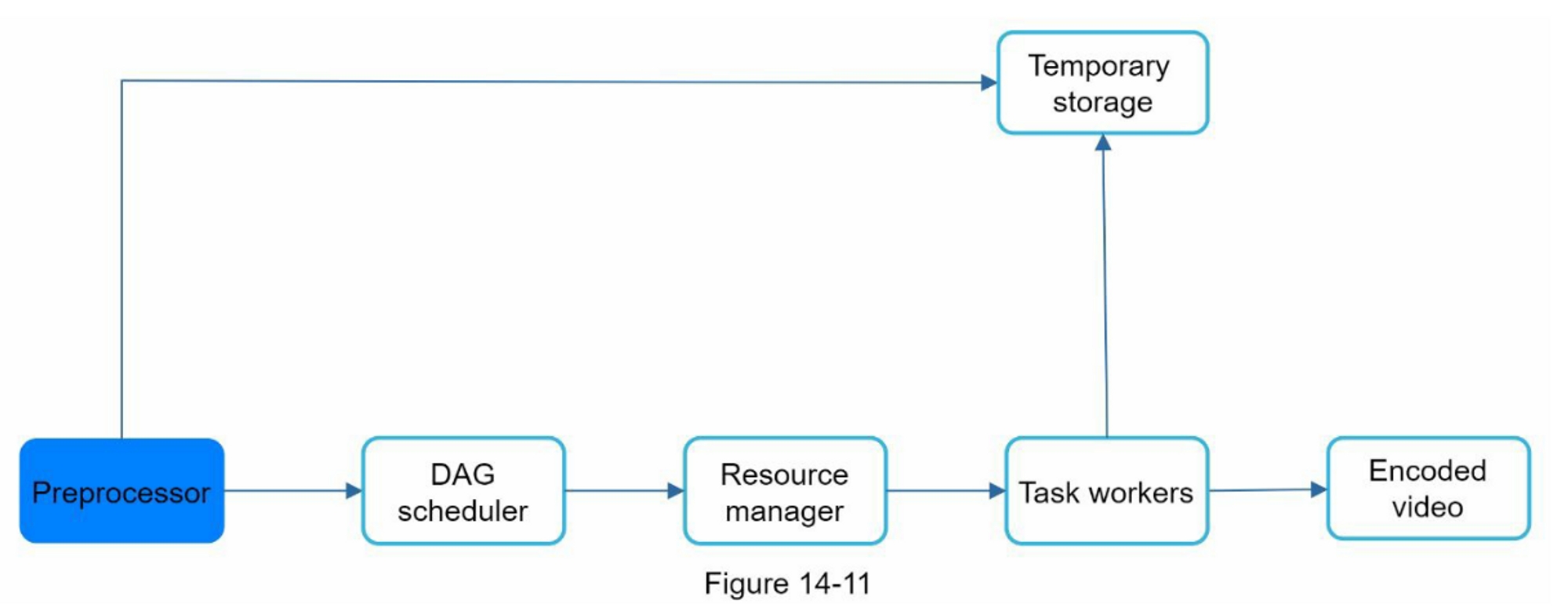
预处理器有4个职责:
-
视频分割:视频流被拆分或进一步拆分为更小的图片组 (GOP) 对齐方式。 GOP 是按特定顺序排列的一组/帧帧。 每个块都是一个独立的可玩单元,通常有几秒钟的长度。
-
一些旧的移动设备或浏览器可能不支持视频分割。 预处理器通过 GOP 对齐方式为老客户分割视频。
-
DAG 生成。 处理器根据客户端程序员编写的配置文件生成 DAG。 图 14-12 是一个简化的 DAG 表示,它有 2 个节点和 1 个边:
这个DAG表示法是由下面两个配置文件生成的(图14-13):
-
缓存数据:预处理器是分段视频的缓存。 为了获得更好的可靠性,预处理器将 GOP 和元数据存储在临时存储中。 如果视频编码失败,系统可以使用持久化数据进行重试操作。
DAG调度器
DAG调度器把DAG图分割成各阶段的任务,并把它们放在资源管理器的任务队列中。图14-15显示了DAG调度器如何工作的一个例子。
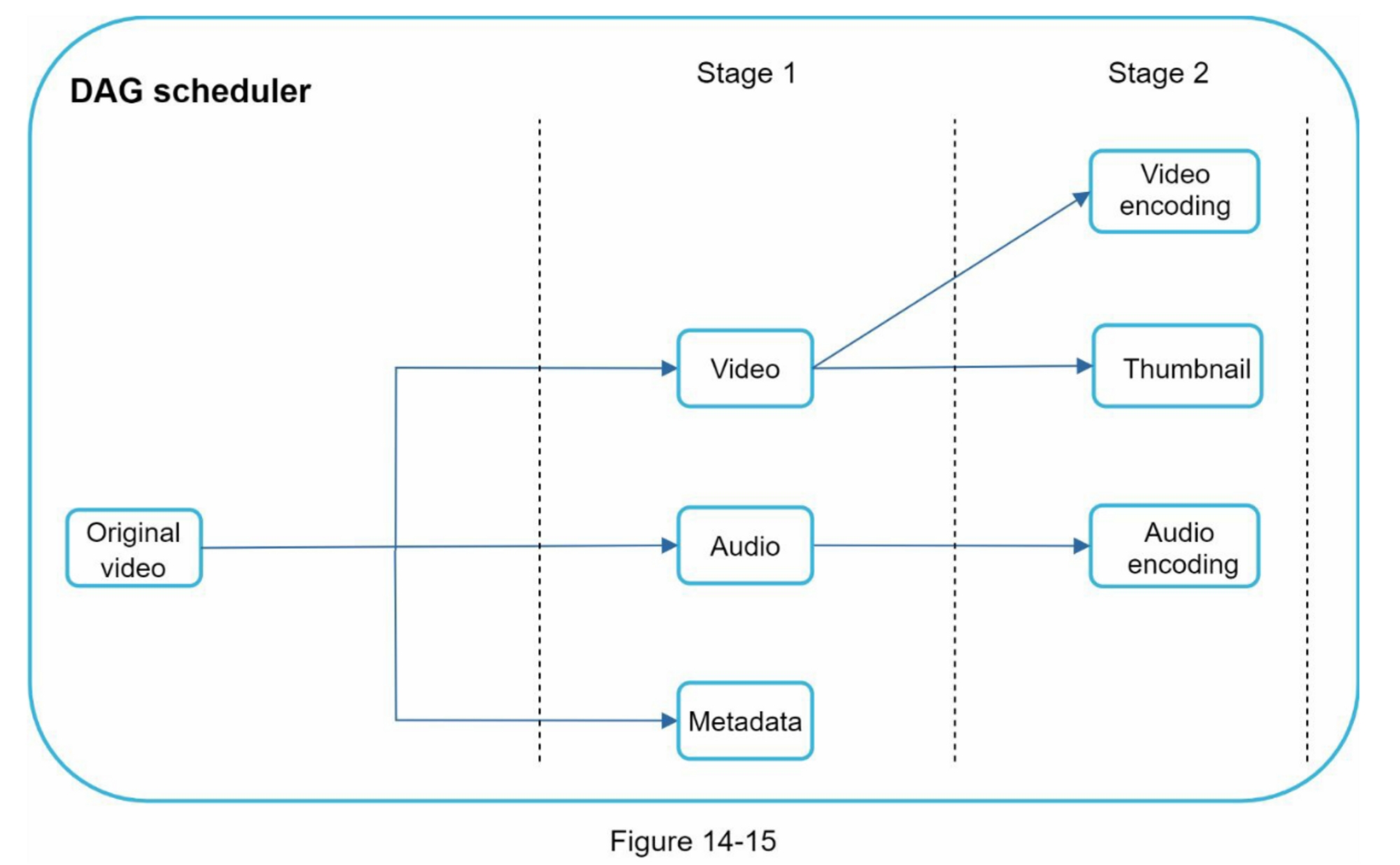
如图14-15所示,原始视频被分割成三个阶段。第1阶段:视频、音频和元数据。视频文件在第2阶段被进一步分成两个任务:视频编码和缩略图。音频文件需要进行音频编码,作为第2阶段任务的一部分。
资源管理器
资源管理器负责管理资源分配的效率。它包含3个队列和一个任务调度器,如图14-17所示。
- Task queue:是一个优先级队列,包含要执行的任务。
- Worker queue:是一个包含 Worker 利用率信息的优先级队列。
- Task scheduler:它挑选最佳任务/工作者,并指示所选的任务工作者执行工作。
资源管理器的工作原理如下:
- 任务调度器从任务队列中获得最高优先级的任务。
- 任务调度器从工作者队列中获得最佳的任务工作者来运行任务。
- 任务调度器指示所选的任务工作者运行该任务。
- 任务调度器绑定任务/工作信息并将其放入运行队列。
- 一旦工作完成,任务调度器就会将工作从运行队列中移除。
任务工作者
任务工作者运行在DAG中定义的任务。不同的任务工作者可以运行不同的任务,如图14-19所示。
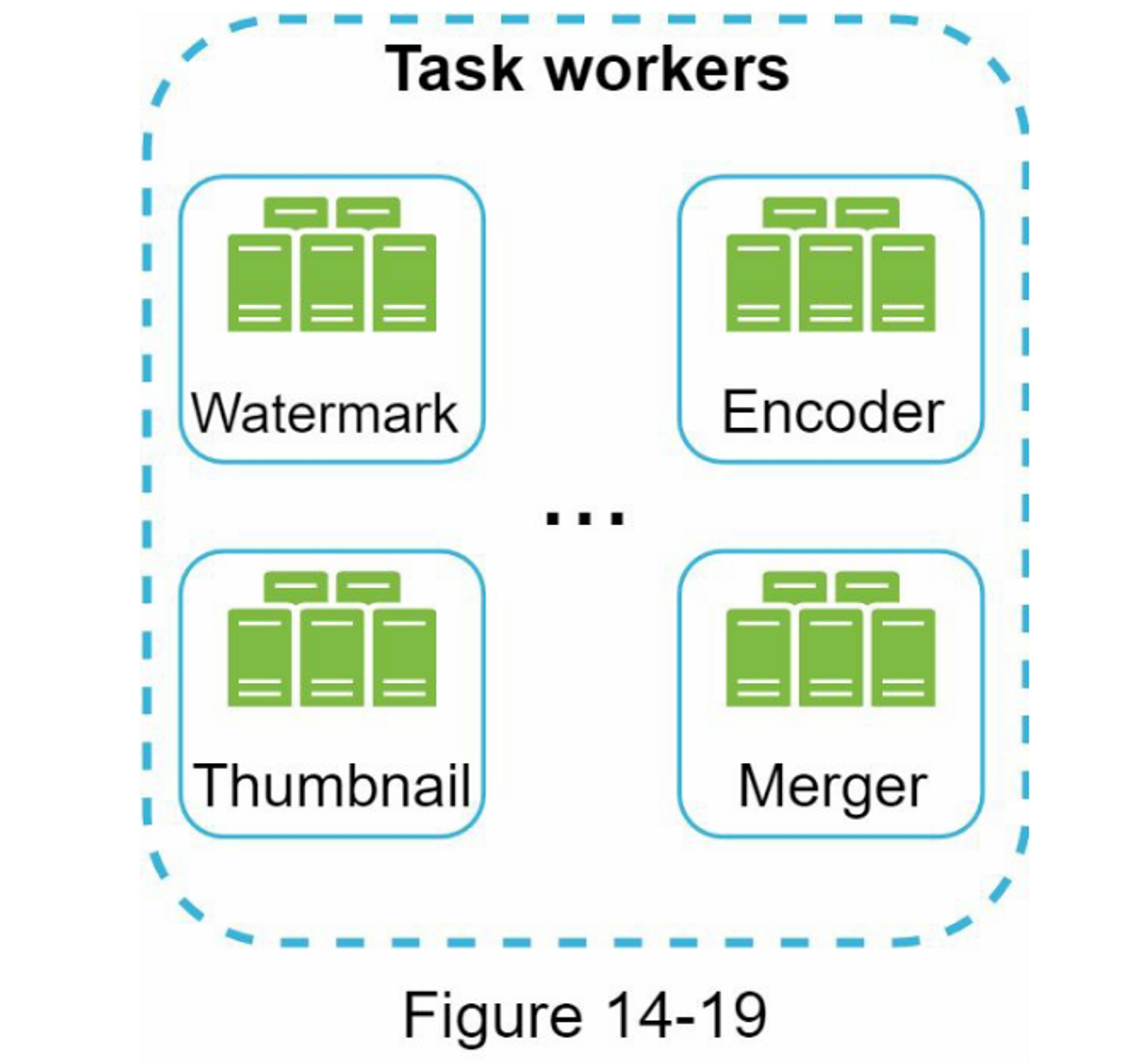
临时存储
这里使用了多种存储系统。存储系统的选择取决于数据类型、数据大小、访问频率、数据寿命等因素。例如,元数据经常被工作者访问,而且数据大小通常很小。因此,在内存中缓存元数据是一个好主意。对于视频或音频数据,我们把它们放在blob存储中。一旦相应的视频处理完成,临时存储中的数据就会被释放出来。
编码后的视频
编码后的视频是编码管道的最终输出。下面是一个输出的例子: funny_720p.mp4 。
系统优化
在这一点上,你应该对视频上传流程、视频流媒体流程和视频转码有良好的理解。接下来,我们将通过优化来完善系统,包括速度、安全和成本节约。
速度优化:并行化视频上传
将一个视频作为一个整体上传是低效的。我们可以通过GOP对齐将视频分割成小块,如图14-22所示。

这允许在前一次上传失败时快速恢复上传。按GOP分割视频文件的工作可以由客户端实现,以提高上传速度,如图14-23所示。 
速度优化:将上传中心放在靠近用户的地方
另一种提高上传速度的方法是在全球设立多个上传中心(图14-24)。美国的人可以把视频上传到北美的上传中心,而中国的人可以把视频上传到亚洲的上传中心。为了实现这一目标,我们使用CDN作为上传中心。
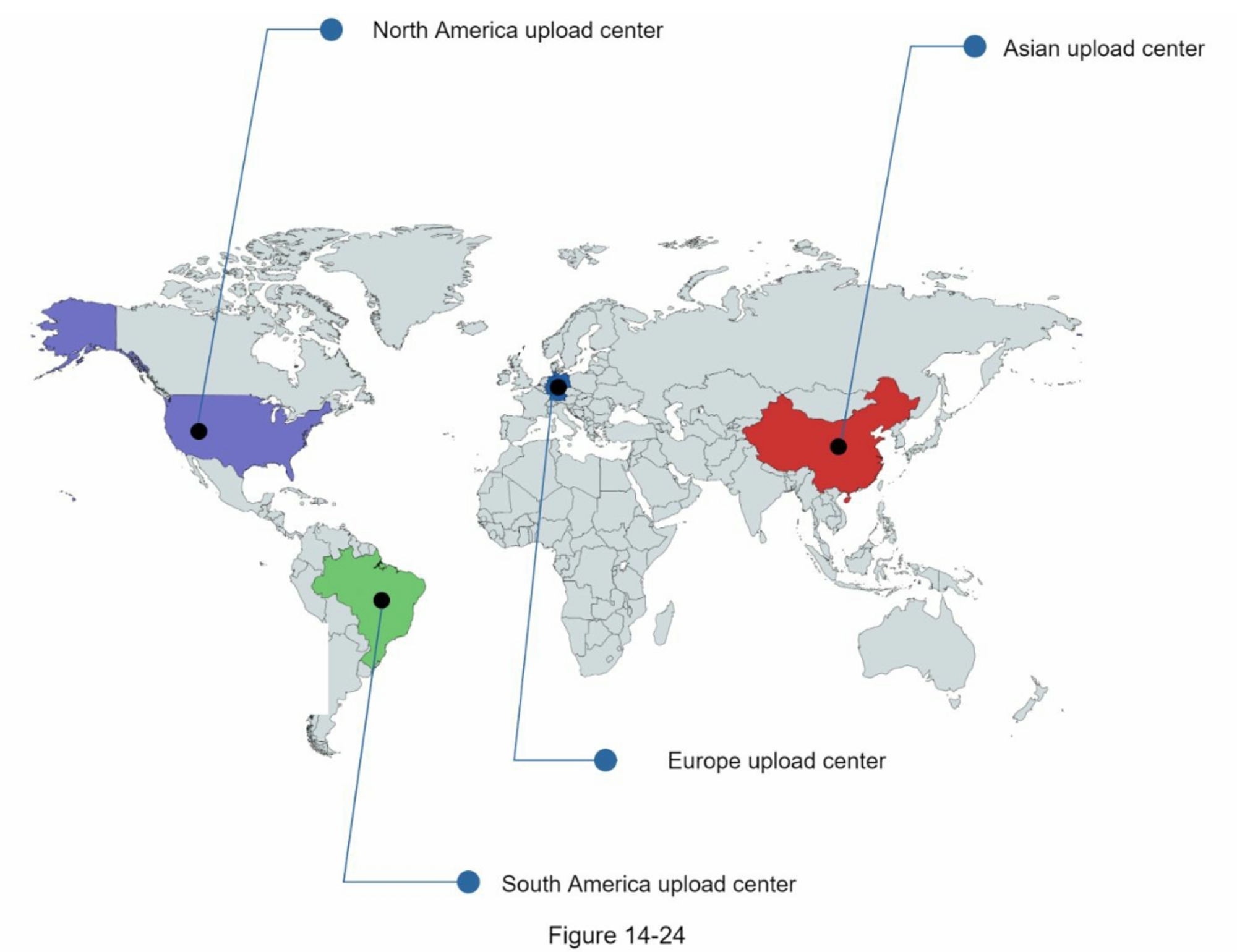
速度优化:无处不在的并行性
实现低延迟需要大量的尝试。另一个优化是构建一个低耦合的系统并实现高并行性。
我们的设计需要做一些修改以实现高并行性。让我们放大视频从原始存储到CDN的流程。该流程如图14-25所示,显示出输出取决于前一步的输入。这种依赖性使并行化变得困难。
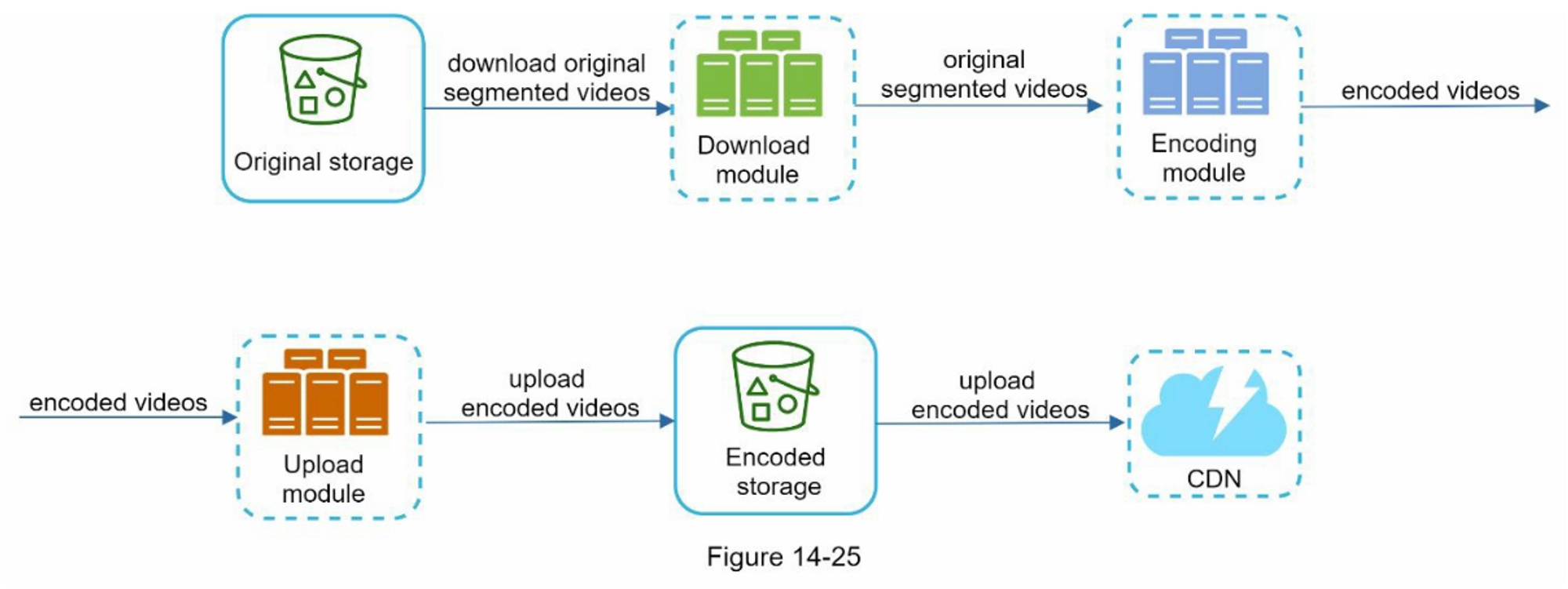
为了使系统更加低耦合,我们引入了消息队列,如图14-26所示。让我们用一个例子来解释消息队列如何使系统更加松散耦合。
- 在引入消息队列之前,编码模块必须等待下载模块的输出。
- 引入消息队列后,编码模块不需要再等待下载模块的输出。如果消息队列中存在事件,编码模块可以并行地执行这些工作。
安全优化:预签名的上传URL
安全是任何产品最重要的方面之一。为了确保只有授权用户将视频上传到正确的位置,我们引入了预签名的URL,如图14-27所示。
上传的流程更新如下:
- 客户端向API服务器发出HTTP请求,以获取预签名的URL,从而获得对URL中标识的对象的访问许可。预签名的URL一词是通过上传文件到Amazon S3使用的。其他云服务提供商可能使用不同的名称。例如,微软Azure blob存储支持同样的功能,但称之为 "Shared Access Signature"[10]。
- API服务器以预先签署的URL进行响应
- 一旦客户端收到响应,它就使用预先签署的URL上传视频。
安全优化:保护你的视频
许多内容制作者不愿意在网上发布视频,因为他们担心自己的原创视频会被盗。为了保护有版权的视频,我们可以采取以下三种安全方案之一:
- 数字版权管理(DRM)系统:三个主要的DRM系统是苹果FairPlay、谷歌Widevine和微软PlayReady。
- AES加密:你可以对视频进行加密并配置一个授权策略。加密的视频在播放时将被解密。这确保了只有授权用户才能观看加密的视频。
- 视频水印:这是在你的视频上面叠加一个图像,包含你的视频的识别信息。它可以是你的公司标志或公司名称。
成本节约优化
CDN是我们系统的一个重要组成部分。它确保了在全球范围内的快速视频传输。然而,通过粗略计算,我们知道CDN是昂贵的,特别是当数据规模很大时。我们如何才能减少成本?
以前的研究表明,YouTube视频流遵循长尾分布[11] [12]。这意味着少数热门视频被频繁访问,但其他许多视频的观众很少或没有。基于这一观察,我们进行了一些优化。
-
CDN仅面向非常受欢迎的视频服务,其他视频由我们高容量存储视频服务器进行服务。
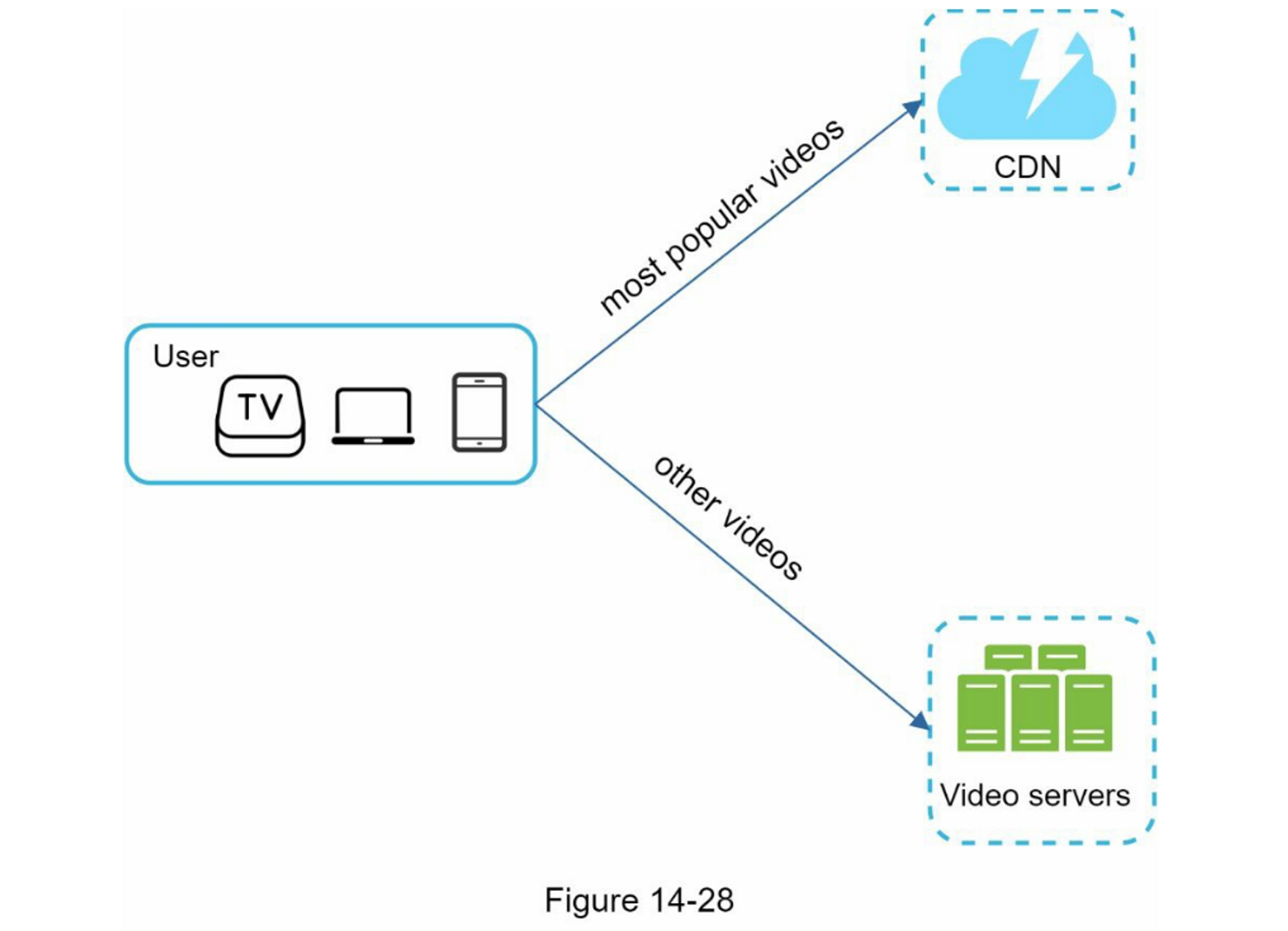
-
对于不太受欢迎的内容,我们可能不需要存储许多编码的视频版本。短视频可以按需编码。
-
有些视频只在某些地区流行。没有必要将这些视频分发到其他地区。
-
像Netflix那样建立你自己的CDN,并与互联网服务提供商(ISP)合作。建立自己的CDN是一个巨大的项目;然而,这对大型流媒体公司来说可能是有意义的。ISP可以是Comcast、AT&T、Verizon或其他互联网供应商。ISP分布在世界各地,离用户很近。通过与ISP合作,你可以改善观看体验,减少带宽费用。
所有这些优化都是基于内容流行度、用户访问模式、视频大小等。在做任何优化之前,分析历史观看模式是很重要的。这里有一些关于这个主题的有趣文章。[12] [13].
错误处理
对于一个大规模的系统,系统错误是不可避免的。为了建立一个高度容错的系统,我们必须优雅地处理错误并快速恢复。存在两种类型的错误:
- 可恢复的错误。对于可恢复的错误,如视频段转码失败,一般的想法是重试几次操作。如果任务继续失败,而且系统认为它不能恢复,它就会向客户返回一个适当的错误代码。
- 不可恢复的错误。对于不可恢复的错误,如畸形的视频格式,系统会停止与视频相关的运行任务,并向客户端返回适当的错误代码。
以下剧本涵盖了每个系统组件的典型错误:
- 上传错误:重试几次。
- 分割视频错误:如果旧版本的客户端不能通过GOP对齐来分割视频,整个视频就会被传递给服务器。分割视频的工作是在服务器端完成的。
- 转码错误:重试。
- 预处理程序错误:重新生成DAG图。
- DAG调度器错误:重新调度一个任务。
- 资源管理器队列宕机:使用副本。
- 任务工作器故障:在新的工作器上重试任务。
- API服务器故障:API服务器是无状态的,所以请求将被引导到不同的API服务器。
- 元数据缓存服务器宕机:数据被多次复制。如果一个节点发生故障,你仍然可以访问其他节点来获取数据。我们可以调出一个新的缓存服务器来取代死去的那个。
- 元数据DB服务器停机:
- Master停机了:如果主站倒下了,促进其中一个从站作为新的主站。
- 从属服务器宕机了:如果一个从属服务器宕机,你可以使用另一个从属服务器进行读取,并调出另一个数据库服务器来代替死去的那个。
第4步:总结
在这一章中,我们介绍了YouTube等视频流服务的架构设计。如果在面试结束时有多余的时间,这里有几个补充要点。
- 扩展API层:因为API服务器是无状态的,所以很容易横向扩展API层。
- 扩展数据库:你可以谈谈数据库复制和分片。
- 现场直播:它指的是一个视频如何被记录和实时播放的过程。虽然我们的系统不是专门为直播设计的,但直播和非直播有一些相似之处:都需要上传、编码和流媒体。显著的区别是:
- 实时流媒体有更高的延迟要求,所以可能需要不同的流媒体协议。
- 实时流媒体对并行性的要求较低,因为小块的数据已经被实时处理。
- 实时流媒体需要不同的错误处理集。任何花费太多时间的错误处理都是不可接受的。
- 视频下架:对侵犯版权、色情等违法行为的视频进行下架。 有些可以在上传过程中被系统发现,而另一些则可能通过用户标记发现。
恭喜你走到了这一步!现在给自己一个鼓励,干得漂亮!
参考资料
- [1] YouTube by the numbers: https://www.omnicoreagency.com/youtube-statistics/
- [2] 2019 YouTube Demographics:https://blog.hubspot.com/marketing/youtube-demographics
- [3] Cloudfront Pricing: https://aws.amazon.com/cloudfront/pricing/
- [4] Netflix on AWS: https://aws.amazon.com/solutions/case-studies/netflix/
- [5] Akamai homepage: https://www.akamai.com/
- [6] Binary large object: https://en.wikipedia.org/wiki/Binary_large_object
- [7] Here’s What You Need to Know About Streaming Protocols:
- https://www.dacast.com/blog/streaming-protocols/
- [8] SVE: Distributed Video Processing at Facebook Scale:https://www.cs.princeton.edu/~wlloyd/papers/sve-sosp17.pdf
- [9] Weibo video processing architecture (in Chinese):
- https://www.upyun.com/opentalk/399.html
- [10] Delegate access with a shared access signature:https://docs.microsoft.com/en-us/rest/api/storageservices/delegate-access-with-shared-access-signature
- [11] YouTube scalability talk by early YouTube employee: https://www.youtube.com/watch
- [12] Understanding the characteristics of internet short video sharing: A youtube-based measurement study. https://arxiv.org/pdf/0707.3670.pdf
- [13] Content Popularity for Open Connect: https://netflixtechblog.com/content-popularity-for-open-connect-b86d56f613b
第15章:设计 Google Drive
近年来,Google Drive、Dropbox、Microsoft OneDrive、Apple iCloud 等云存储服务非常流行。在本章中,你需要设计 Google Drive。
在开始设计之前,让我们花点时间了解一下 Google Drive。 Google Drive 是一种文件存储和同步服务,可帮助您在云端存储文档、照片、视频和其他文件。您可以从任何计算机、智能手机和平板电脑访问您的文件。你可以轻松地与朋友、家人和同事共享这些文件 [1]。图 15-1 和 15-2 分别显示了 Google Drive 在浏览器和移动应用程序中的样子。
第1步:了解问题并确定设计范围
设计 Google Drive 是一项大工程,因此提出问题以缩小范围很重要。
候选人:最重要的特征是什么?
面试官:上传下载文件,文件同步,通知。
候选人:这是一个移动应用程序、一个网络应用程序,还是两者兼而有之?
面试官:都是。
考生:支持的文件格式有哪些?
面试官:任何文件类型。
候选人:文件需要加密吗?
面试官:是的,存储中的文件必须加密。
候选人:文件大小有限制吗?
面试官:是的,文件必须为 10 GB 或更小。
候选人:产品有多少用户?
面试官:10M DAU
在本章中,我们重点关注以下功能:
- 添加文件。添加文件的最简单方法是将文件拖放到 Google Drive 中。
- 下载文件。
- 跨多个设备同步文件。将文件添加到一台设备后,它会自动同步到其他设备。
- 查看文件修订内容。
- 与您的朋友、家人和同事共享文件
- 当文件被编辑、删除或与您共享时发送通知。
本章未讨论的功能包括:
- 可靠性。可靠性对于存储系统来说极其重要,数据丢失是不可接受的。
- 同步速度快。如果文件同步花费太多时间,用户将变得不耐烦并放弃该产品。
- 带宽使用。如果产品占用大量不必要的网络带宽,用户会不高兴,尤其是当他们使用移动数据时。
- 可扩展性。该系统应该能够处理大量的流量。
- 高可用性。当某些服务器离线、速度变慢或出现意外网络错误时,用户应该仍然可以使用该系统。
粗略估算
- 假设该应用程序有 5000 万注册用户和 1000 万 DAU。
- 用户获得10 GB 的可用空间。
- 假设用户每天上传2 个文件。平均文件大小为 500 KB。
- 1:1 的读写比。
- 分配的总空间: $$5000 万 \times 10 GB = 500 PB$$
- 上传 API 的 QPS: $$1000 万 \times 2 次上传/24 小时/3600 秒 \approx 240$$
- 峰值 QPS : $$QPS \times 2 = 480$$
第2步:提出高层次的设计方案并获得认同
我们将使用稍微不同的方法,而不是从一开始就展示高级设计图。我们将从简单的事情开始:在单个服务器中构建所有内容。然后,逐步扩大规模以支持数百万用户。通过做这个练习,它会刷新你对书中涵盖的一些重要主题的记忆。
让我们从下面列出的单个服务器设置开始:
- 一个用于上传和下载文件的 Web 服务器。
- 一个数据库,用于跟踪元数据,如用户数据、登录信息、文件信息等。
- 一个存储系统来存储文件。我们分配了1TB的存储空间来存储文件。
我们花了几个小时设置了一个 Apache 网络服务器、一个 MySQL 数据库和一个名为 drive/ 的目录作为根目录来存储上传的文件。在 drive/ 目录下,有一个目录列表,称为名称空间。每个命名空间都包含该用户的所有上传文件。服务器上的文件名与原始文件名保持一致。通过加入命名空间和相对路径,可以唯一标识每个文件或文件夹。
图15-3显示了 /drive 目录在左边的样子和它在右边的扩展视图的一个例子。
API
API 是什么样子的?我们主要需要 3 个 API:上传文件、下载文件和获取文件修订。
-
上传文件到 Google Drive
支持两种类型的上传:
- 简单上传。当文件较小时使用此上传类型。
- 可恢复上传。当文件很大并且网络中断的可能性很高时,请使用此上传类型。
以下是可恢复上传 API 的示例:
https://api.example.com/files/upload?uploadType=resumable参数:
uploadType=resumabledata: 待上传的本地文件
可恢复上传通过以下 3 个步骤 [2] 实现:
- 发送初始请求以检索可恢复 URL。
- 上传数据并监控上传状态。
- 如果上传受到干扰,请继续上传。
-
从Google Drive下载文件
示例 API:
https://api.example.com/files/download参数:
path:下载文件路径
示例参数:
{ "path": "/recipes/soup/best_soup.txt" } -
获取文件修订
示例 API:
https://api.example.com/files/list_revisions参数:
path:要获取修订历史记录的文件的路径- 要返回的最大修订数。
示例参数:
{ "path": "/recipes/soup/best_soup.txt", "limit": 20 }所有 API 都需要用户身份验证并使用 HTTPS。安全套接字层 (SSL) 保护客户端和后端服务器之间的数据传输。
摆脱单一服务器
随着更多文件的上传,最终您会收到如图 15-4 所示的空间已满警报。

仅剩 10 MB 的存储空间!这是紧急情况,因为用户无法再上传文件。想到的第一个解决方案是将数据分片,因此将其存储在多个存储服务器上。图 15-5 显示了基于 user_id 的分片示例。
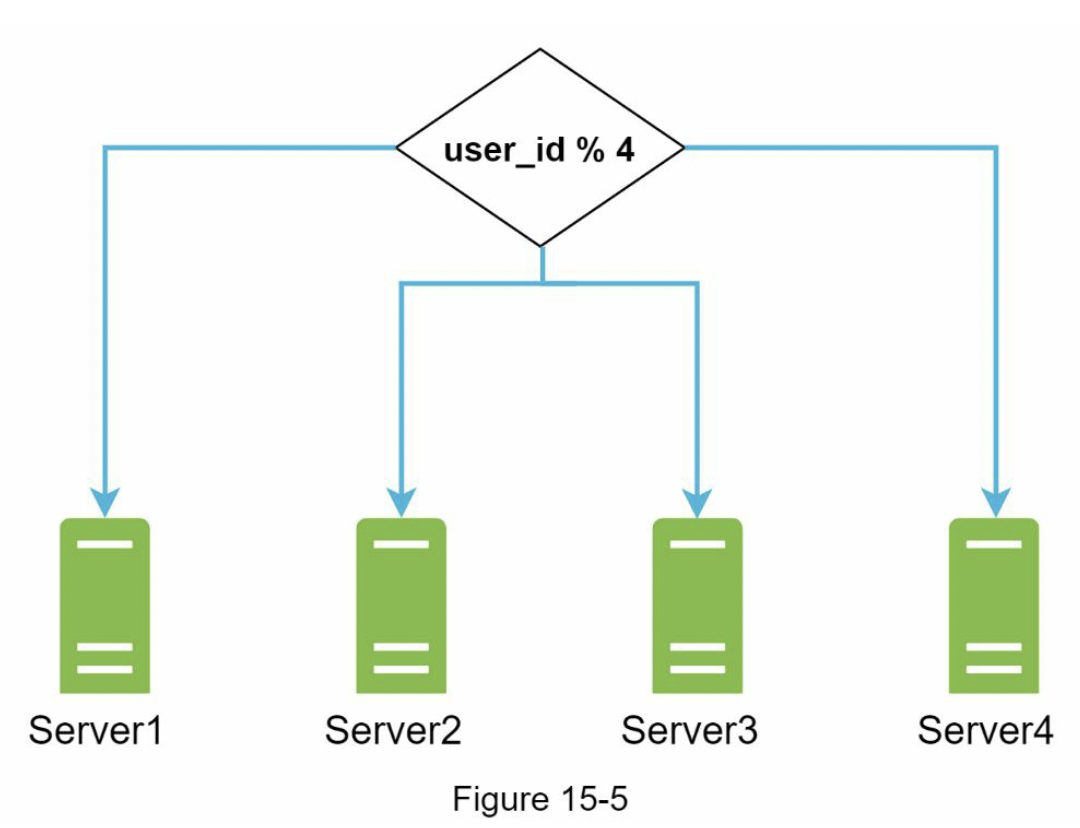
你通宵达旦地设置了数据库分片,并密切监控。一切又顺利地运行了。你已经阻止了火灾的发生,但你仍然担心在存储服务器中断的情况下可能出现的数据损失。你四处打听,你的后台大师朋友弗兰克告诉你,许多领先的公司如Netflix和Airbnb都使用Amazon S3进行存储。"亚马逊简单存储服务(Amazon S3)是一种对象存储服务,提供行业领先的可扩展性、数据可用性、安全性和性能" [3]。你决定做一些研究,看看它是否合适。
大量阅读后,您对 S3 存储系统有了很好的了解,并决定将文件存储在 S3 中。 Amazon S3 支持同区域和跨区域复制。一个地区是指亚马逊网络服务(AWS)拥有数据中心的地理区域。如图15-6所示,数据可以在同区域(左侧)和跨区域(右侧)复制。冗余文件存储在多个区域,以防止数据丢失并确保可用性。存储桶就像文件系统中的文件夹。
把文件放到S3后,你终于可以睡个好觉了,不用担心数据丢失。为了阻止类似的问题在未来发生,你决定对可以改进的地方做进一步研究。以下是你发现的几个方面:
- 负载均衡器:添加负载均衡器来分配网络流量。负载均衡器确保流量均匀分布,如果 Web 服务器出现故障,它将重新分配流量。
- Web 服务器:添加负载均衡器后,可以根据流量负载轻松添加/删除更多Web 服务器。
- 元数据数据库:将数据库移出服务器以避免单点故障。同时,设置数据复制和分片以满足可用性和可扩展性要求。
- 文件存储:Amazon S3 用于文件存储。为确保可用性和持久性,文件被复制到两个不同的地理区域。
应用上述改进后,您已成功将 Web 服务器、元数据数据库和文件存储从单个服务器中分离出来。更新后的设计如图 15-7 所示。
同步冲突
对于像 Google Drive 这样的大型存储系统,同步冲突时有发生。当两个用户同时修改同一个文件或文件夹时,就会发生冲突。我们如何解决冲突?这是我们的策略:先处理的版本获胜,后处理的版本接收冲突。图 15-8 显示了同步冲突的示例。
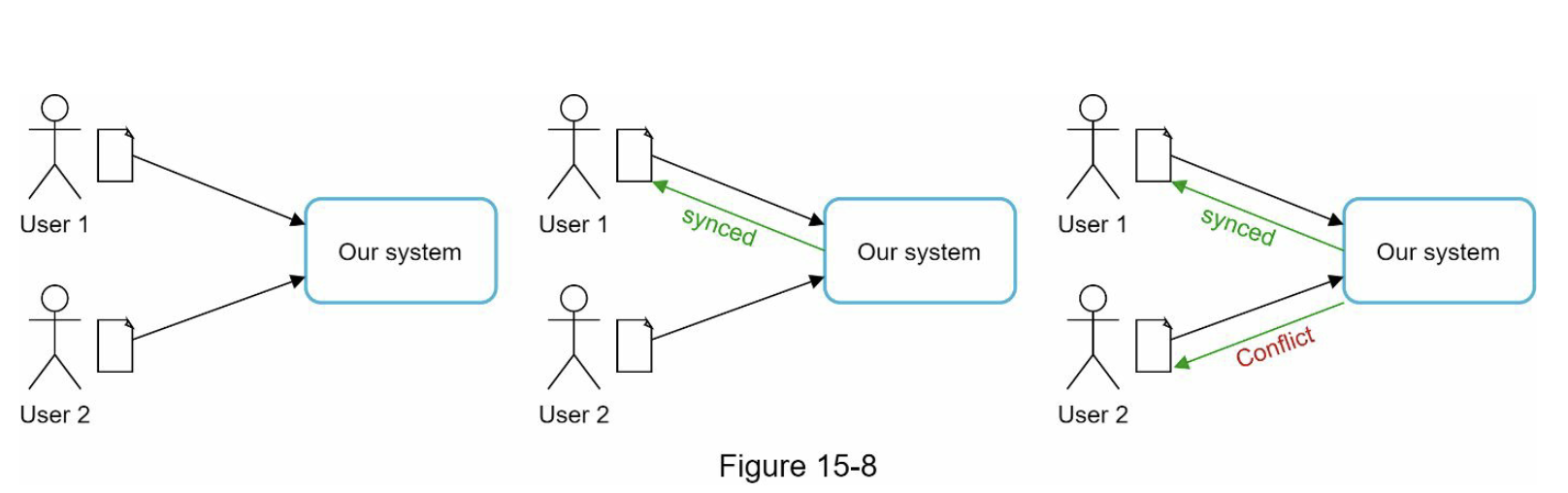
在图 15-8 中,用户 1 和用户 2 试图同时更新同一个文件,但是用户 1 的文件首先被我们的系统处理。用户 1 的更新操作通过,但用户 2 发生同步冲突。我们如何解决用户 2 的冲突?我们的系统提供同一文件的两个副本:用户 2 的本地副本和来自服务器的最新版本(图 15-9)。用户 2 可以选择合并两个文件或用另一个版本覆盖一个版本。
当多个用户同时编辑同一个文档时,保持文档同步是一项挑战。有兴趣的读者可以参考参考资料[4] [5]。
高层设计
图 15-10 说明了建议的高级设计。让我们检查系统的每个组件。
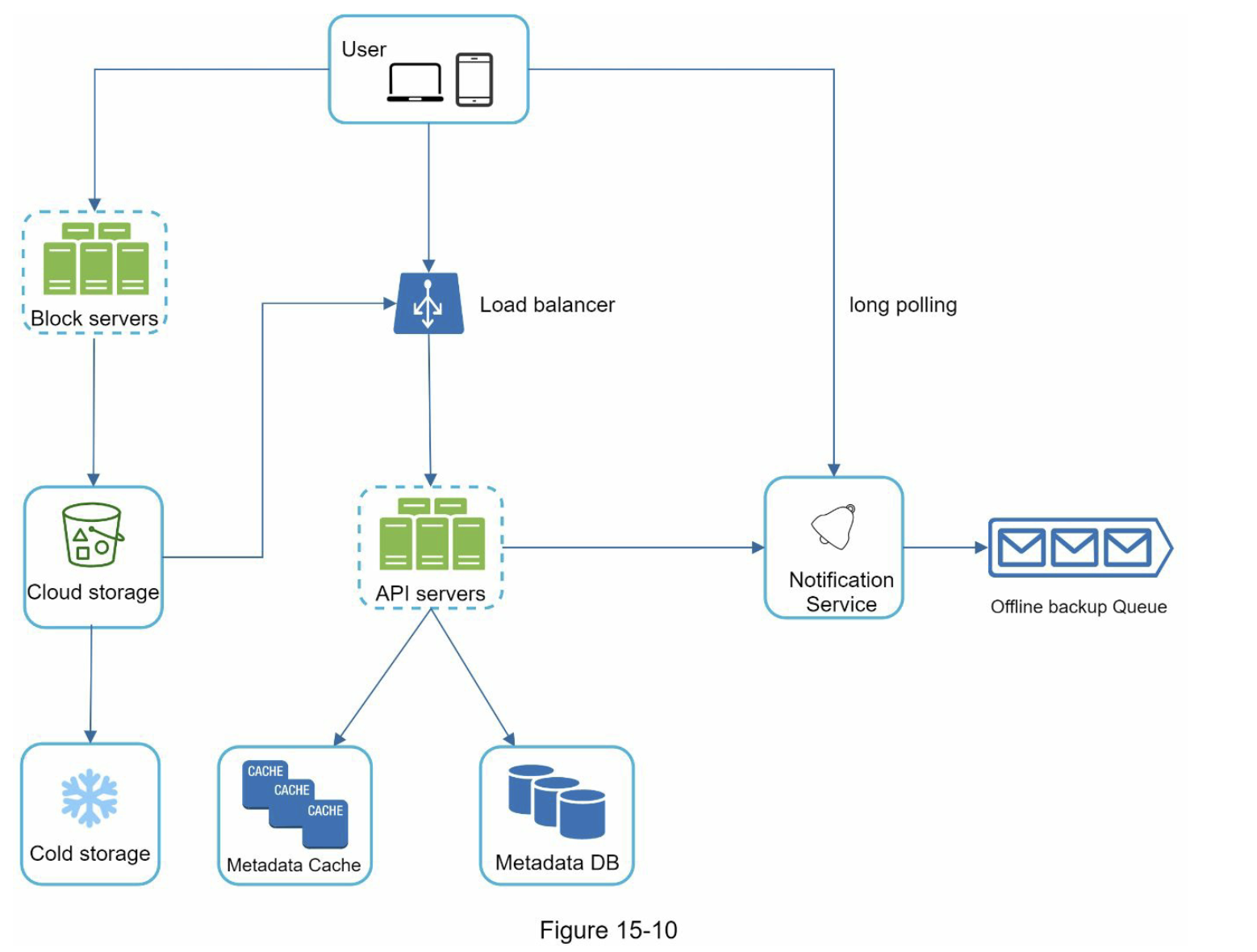
User:用户通过浏览器或移动应用程序使用该应用程序。
Block servers:块服务器将块上传到云存储。块存储,简称块级存储,是一种在基于云的环境中存储数据文件的技术。一个文件可以分成几个块,每个块都有一个唯一的哈希值,存储在我们的元数据数据库中。每个块都被视为一个独立的对象并存储在我们的存储系统 (S3) 中。为了重建文件,块以特定顺序连接。至于块大小,我们参考了Dropbox:它把一个块的最大大小设置为4MB [6]。
Cloud storage:文件被分割成更小的块并存储在云存储中。
Cold storage:冷存储是一种为存储非活动数据而设计的计算机系统,意味着文件在很长一段时间内不会被访问。
Load balancer:负载均衡器在 API 服务器之间平均分配请求。
API servers:这些服务器负责除上传流程以外的几乎所有工作。API服务器用于用户认证、管理用户资料、更新文件元数据等。
Metadata database:它存储用户、文件、块、版本等元数据。请注意,文件存储在云端,元数据数据库仅包含元数据。
Metadata cache:一些元数据被缓存以便快速检索。
Notification service:它是一个发布者/订阅者系统,允许在某些事件发生时将数据从通知服务传输到客户端。在我们的具体案例中,通知服务会在其他地方添加/编辑/删除文件时通知相关客户,以便他们可以提取最新的更改。
Offline backup queue:如果客户端离线并且无法拉取最新的文件更改,离线备份队列会存储信息,以便在客户端在线时同步更改。我们已经在高层讨论了 Google Drive 的设计。有些组件很复杂,值得仔细检查;我们将在深入讨论中详细讨论这些。
第3步:深入设计
在本节中,我们将仔细研究以下内容:块服务器、元数据数据库、上传流程、下载流程、通知服务、节省存储空间和故障处理。
块服务器
对于定期更新的大文件,在每次更新时发送整个文件会消耗大量带宽。提出了两种优化来最小化传输的网络流量:
- 增量同步。修改文件时,使用同步算法 [7] [8] 仅同步修改的块而不是整个文件。
- 压缩。对块进行压缩可以显著减少数据大小。因此,根据文件类型,使用压缩算法对块进行压缩。例如,gzip和bzip2是用来压缩文本文件的。压缩图像和视频则需要不同的压缩算法。
在我们的系统中,块服务器负责上传文件的繁重工作。块服务器通过将文件分成块、压缩每个块并加密它们来处理从客户端传递的文件。不是将整个文件上传到存储系统,而是只传输修改过的块。
图 15-11 显示了添加新文件时块服务器的工作方式。
- 一个文件被分割成更小的块。
- 每个块都使用压缩算法进行压缩。
- 为了确保安全,每个块在发送到云存储之前都经过加密。
- 块被上传到云存储。
图 15-12 说明了增量同步,这意味着只有修改过的块才会传输到云存储。突出显示的块“块 2”和“块 5”表示已更改的块。使用增量同步,只有这两个块被上传到云存储。
块服务器允许我们通过提供增量同步和压缩来节省网络流量。
高一致性要求
我们的系统默认要求强一致性。一个文件同时被不同的客户端显示不同是不可接受的。系统需要为元数据缓存和数据库层提供强一致性。
内存缓存默认采用最终一致性模型,这意味着不同的副本可能有不同的数据。要实现强一致性,我们必须确保以下几点:
- 缓存副本和主服务器中的数据是一致的。
- 在数据库写入时使缓存无效,以确保缓存和数据库保持相同的值。
在关系数据库中实现强一致性很容易,因为它维护了 ACID(原子性、一致性、隔离性、持久性)属性 [9]。但是,NoSQL 数据库默认不支持 ACID 属性。 ACID 属性必须以编程方式合并到同步逻辑中。在我们的设计中,我们选择关系数据库,因为 ACID 是原生支持的。
元数据数据库
图 15-13 显示了数据库模式设计。请注意这是一个高度简化的版本,因为它只包含最重要的表和有趣的字段。
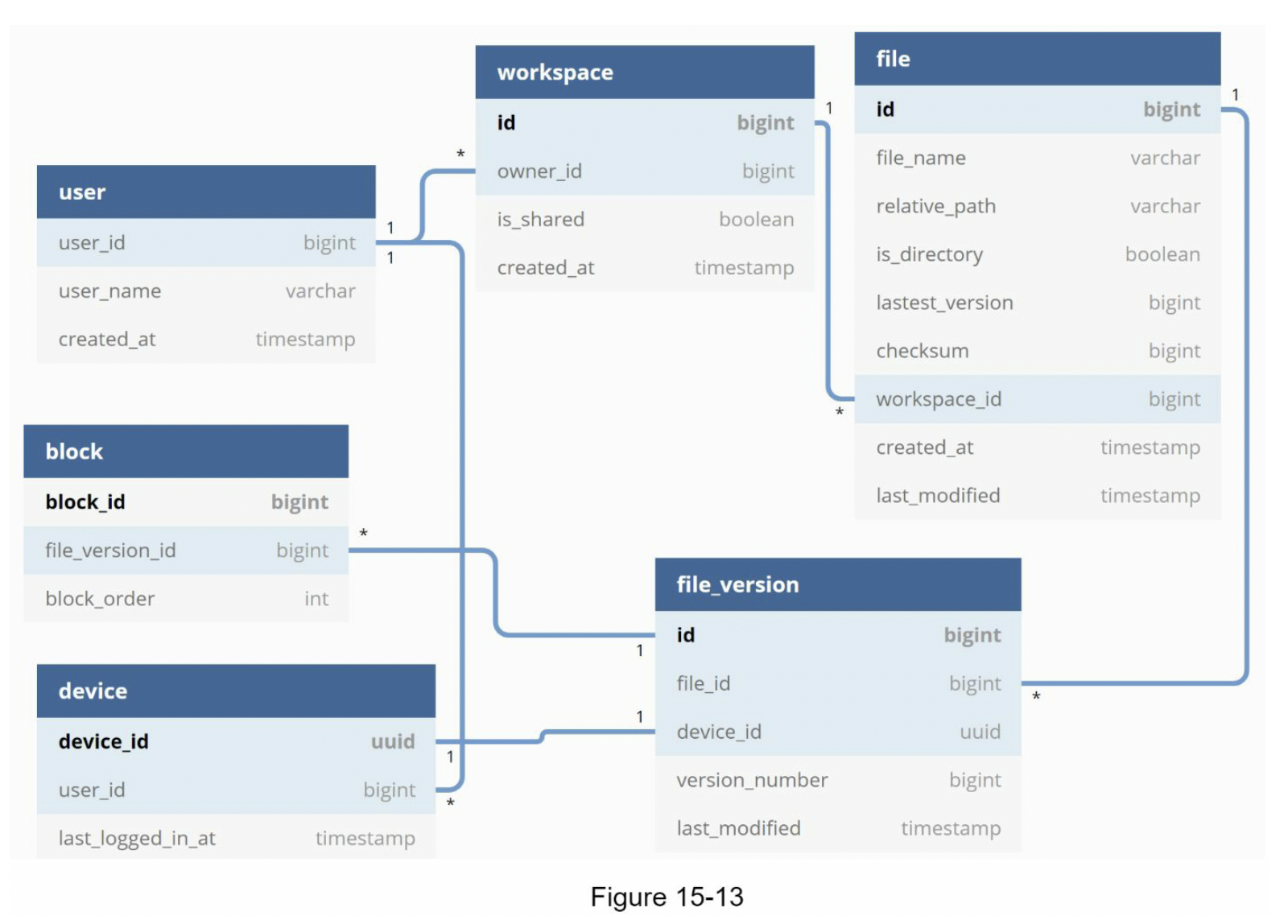
User:用户表包含有关用户的基本信息,例如用户名、电子邮件、个人资料照片等。
Device:设备表存储设备信息。 push_id 用于发送和接收移动推送通知。请注意,一个用户可以拥有多个设备。
Namespace:命名空间是用户的根目录。
File:文件表存储与最新文件相关的所有内容。
File_version:它存储文件的版本历史。现有行是只读的,以保持文件修订历史的完整性。
Block:它存储与文件块相关的所有内容。任何版本的文件都可以通过以正确的顺序连接所有块来重建。
上传流程
让我们讨论一下客户端上传文件时会发生什么。为了更好地理解流程,我们绘制了如图 15-14 所示的时序图。
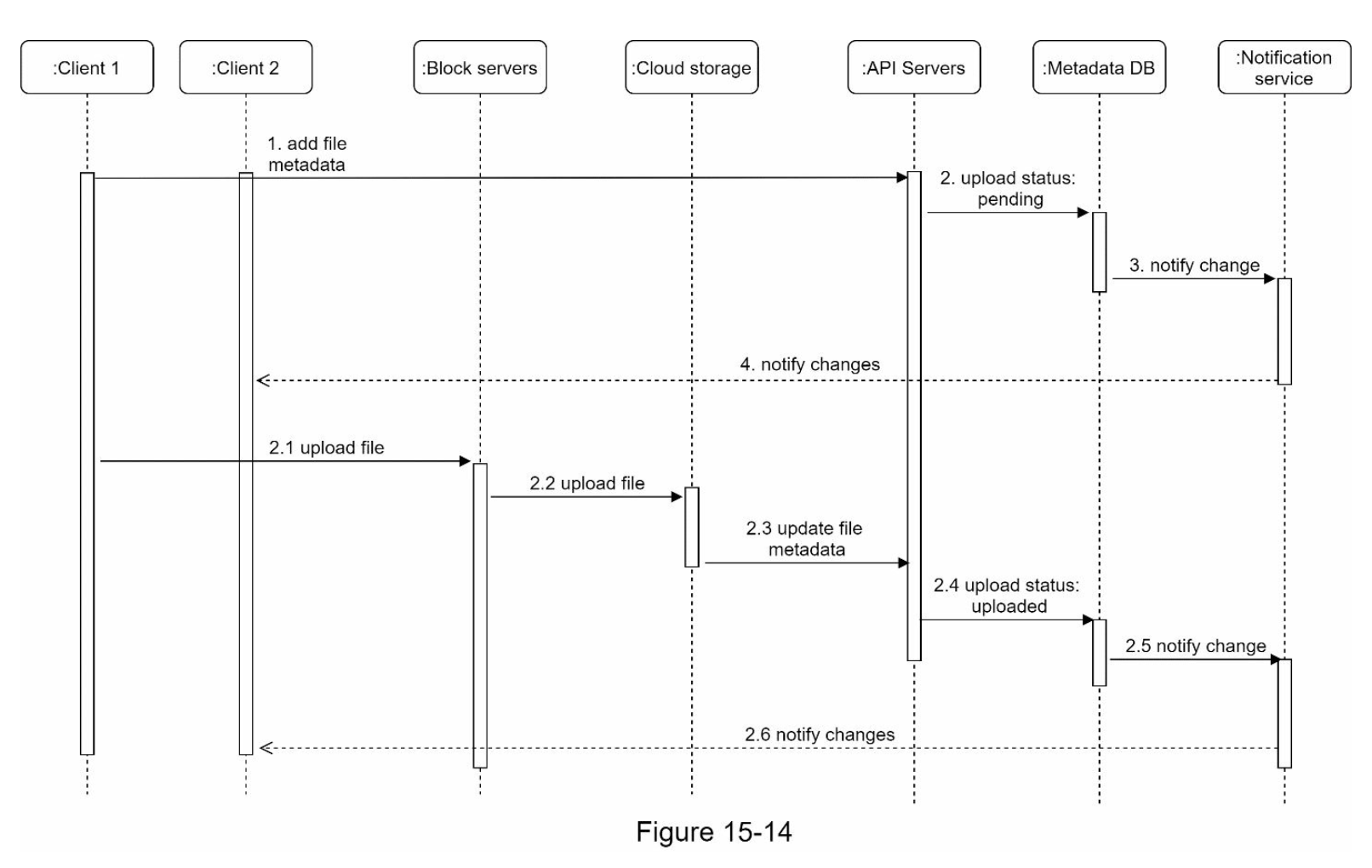
在图 15-14 中,并行发送了两个请求:添加文件元数据和将文件上传到云存储。两个请求都来自客户端 1。
- 添加文件元数据
- 客户端1发送了一个请求,要求添加新文件的元数据。
- 将新的文件元数据存储在元数据数据库中,并将文件上传状态改为
pending。 - 通知通知服务正在添加一个新的文件。
- 通知服务通知相关客户端(客户端2)有文件正在上传
- 上传文件到云存储
- 客户端 1 将文件内容上传到块服务器。
- 块服务器将文件分块成块,压缩,加密块,并将它们上传到云存储。
- 文件上传完成后,云存储触发上传完成回调。请求被发送到 API 服务器。
- 在Metadata DB 中,文件状态改为
uploaded。 - 通知通知服务文件状态更改为
uploaded。 - 通知服务通知相关客户端(客户端2)文件已完全上传。
编辑文件时,流程类似,不再赘述。
下载流程
当一个文件在其他地方被添加或编辑时,会触发下载流。客户端如何知道一个文件是由另一个客户端添加或编辑的?客户端有两种方法可以知道:
- 如果客户端 A 在线,而另一个客户端更改了文件,通知服务将通知客户端 A 某处发生了更改,因此需要拉取最新数据。
- 如果客户端A在文件被另一个客户端修改时处于离线状态,数据将被保存到缓存中。当脱机的客户端再次上线时,它就会拉出最新的变化
一旦客户端知道一个文件被改变,它首先通过API服务器请求元数据,然后下载块来构建文件。图15-15显示了详细的流程。注意,由于空间的限制,图中只显示了最重要的部分。
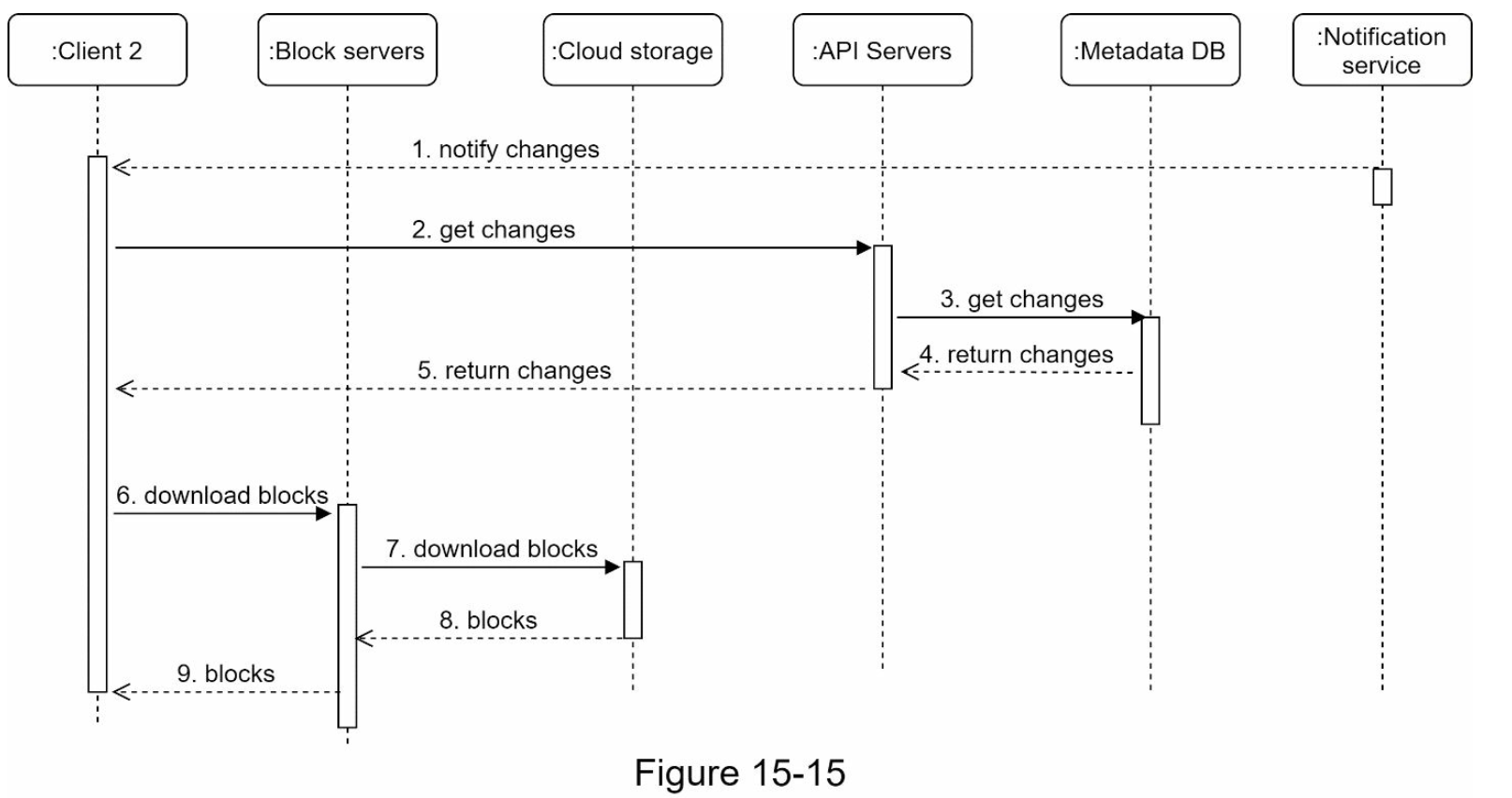
- 通知服务通知客户端某个文件在其他地方发生了更改。
- 一旦客户端 2 知道有新的更新可用,它就会发送一个获取元数据的请求。
- API 服务器调用元数据数据库来获取更改的元数据。
- 元数据返回给API服务器。
- 客户端 2 获取元数据。
- 一旦客户端收到元数据,它就会向块服务器发送请求以下载块。
- 区块服务器首先从云存储中下载区块。
- 云存储返回块给块服务器。
- 客户端2下载所有新块重建文件
通知服务
为了保持文件的一致性,本地执行的任何文件变更都需要通知其他客户端以减少冲突。通知服务就是为这个目的而构建的。在高层设计中,通知服务允许在事件发生时将数据传输到客户端。这里有几个选项:
- 长轮询。 Dropbox 使用长轮询 [10]
- WebSocket。 WebSocket 在客户端和服务器之间提供持久连接。沟通是双向的。
尽管这两种选择都很好,但出于以下两个原因,我们选择了长轮询:
- 通知服务的通信不是双向的。服务器向客户端发送有关文件更改的信息,反之亦然。
- WebSocket 适用于实时双向通信,例如聊天应用程序。对于 Google 云端硬盘,通知发送不频繁,没有突发数据。
使用长轮询,每个客户端都会建立到通知服务的长轮询连接。如果检测到对文件的更改,客户端将关闭长轮询连接。关闭连接意味着客户端必须连接到元数据服务器才能下载最新的更改。收到响应或达到连接超时后,客户端立即发送新请求以保持连接打开。
节省储存空间
为了支持文件版本历史并确保可靠性,同一文件的多个版本被存储在多个数据中心。如果频繁地备份所有文件的修订版,存储空间就会很快被填满。提出了三种技术来减少存储成本:
- 去除重复的数据块。在账户层面消除多余的块是节省空间的一个简单方法。如果两个块有相同的哈希值,那么它们就是相同的。
- 采用智能数据备份策略。可以应用两种优化策略:
- 设置限制:我们可以为要存储的版本数量设置限制。如果达到限制,最旧的版本将被新版本替换。
- 只保留有价值的版本。有些文件可能会被频繁地编辑。例如,为一个大量修改的文件保存每个编辑过的版本可能意味着该文件在短时间内被保存1000多次。为了避免不必要的复制,我们可以限制保存版本的数量。我们对最近的版本给予更多的权重。实验有助于找出保存的最佳版本数
- 将不常用的数据移动到冷存储。冷数据是数月或数年未活跃的数据。像 Amazon S3 冰川 [11] 这样的冷存储比 S3 便宜得多。
故障处理
在一个大规模的系统中可能会出现故障,我们必须采取设计策略来解决这些故障。你的面试官可能有兴趣听听你是如何处理以下系统故障的:
- 负载均衡器故障:如果负载均衡器出现故障,辅助节点将变为活动状态并接收流量。负载均衡器通常使用心跳相互监控,心跳是负载均衡器之间发送的周期性信号。如果负载均衡器在一段时间内没有发送心跳,则认为它失败了。
- 块服务器故障:如果块服务器发生故障,其他服务器将接管未完成或挂起的作业。
- 云存储故障:S3 bucket在不同地域多次复制。如果文件在一个区域不可用,可以从不同区域获取它们。
- API服务器故障:是无状态服务。如果 API 服务器发生故障,流量将通过负载均衡器重定向到其他 API 服务器。
- 元数据缓存故障:元数据缓存服务器被多次复制。如果一个节点宕机,您仍然可以访问其他节点以获取数据。我们将启动一个新的缓存服务器来替换发生故障的服务器。
- 元数据数据库故障
- Master down:如果master宕机,提升其中一个slave充当新的master,并拉起一个新的slave节点。
- Slave down:如果一个slave down了,可以用另一个slave进行读操作,带上另一台数据库服务器来代替失效的。
- 通知服务失败:每个在线用户与通知服务器保持一个长轮询连接。因此,每个通知服务器都与许多用户相连。根据 2012 年的 Dropbox 谈话 [6],每台机器打开超过 100 万个连接。如果服务器出现故障,所有长轮询连接都会丢失,因此客户端必须重新连接到不同的服务器。即使一台服务器可以保持许多打开的连接,它也无法立即重新连接所有丢失的连接。重新连接所有丢失的客户端是一个相对缓慢的过程。
- 离线备份队列故障:队列被多次复制。如果一个队列发生故障,该队列的消费者可能需要重新订阅备用队列。
第4步:总结
在本章中,我们提出了一个支持 Google Drive 的系统设计。强一致性、低网络带宽和快速同步的结合使设计变得有趣。我们的设计包含两个流程:管理文件元数据和文件同步。通知服务是系统的另一个重要组成部分。它使用长轮询来使客户端保持最新的文件更改。
像任何系统设计面试问题一样,没有完美的解决方案。每个公司都有其独特的限制,你必须设计一个系统来适应这些限制。了解你的设计和技术选择的权衡是很重要的。如果还有几分钟的时间,你可以谈谈不同的设计选择。
例如,我们可以从客户端直接向云存储上传文件,而不是通过块服务器。这种方法的优点是,它使文件的上传速度更快,因为文件只需要传输一次到云存储中。在我们的设计中,一个文件首先被传输到块服务器,然后再传输到云存储。然而,这种新方法也有一些缺点:
- 首先,同样的分块、压缩和加密逻辑必须在不同的平台(iOS、Android、Web)上实现。这是很容易出错的,需要大量的工程努力。在我们的设计中,所有这些逻辑都在一个集中的地方实现:块服务器。
- 其次,由于客户端很容易被黑客攻击或操纵,在客户端实现加密逻辑并不理想。
该系统的另一个有趣的演变是将在线/离线逻辑转移到一个单独的服务中。让我们称之为存在服务。通过将在线服务从通知服务器中移出,在线/离线功能可以很容易地被其他服务集成。
恭喜你走到了这一步!现在给自己一个鼓励,干得漂亮!
参考资料
[1] Google Drive: https://www.google.com/drive/
[2] Upload file data: https://developers.google.com/drive/api/v2/manage-uploads
[3] Amazon S3: https://aws.amazon.com/s3
[4] Differential Synchronization https://neil.fraser.name/writing/sync/
[5] Differential Synchronization youtube talk https://www.youtube.com/watch?v=S2Hp_1jqpY8
[6] How We’ve Scaled Dropbox: https://youtu.be/PE4gwstWhmc
[7] Tridgell, A., & Mackerras, P. (1996). The rsync algorithm.
[8] Librsync. (n.d.). Retrieved April 18, 2015, from https://github.com/librsync/librsync
[9] ACID: https://en.wikipedia.org/wiki/ACID
[10] Dropbox security white paper:
https://www.dropbox.com/static/business/resources/Security_Whitepaper.pdf
[11] Amazon S3 Glacier: https://aws.amazon.com/glacier/faqs/
第1章 邻近服务
在本章中,我们设计一个附近地点服务。附近地点服务用于发现附近的餐厅、酒店、剧院、博物馆等场所,是一个核心组件,为 Yelp 上查找附近最佳餐厅或 Google 地图上查找最近加油站等功能提供支持。图 1.1 展示了 Yelp [1] 上用于搜索附近餐厅的用户界面。请注意本书中使用的地图瓦片来自 Stamen Design [2],数据来自 OpenStreetMap [3]。

图 1.1: Yelp上的附近搜索
第1步 - 理解问题并确定设计范围
Yelp 支持很多功能,在面试过程中不可能设计所有功能,所以通过提问来缩小范围很重要。面试官和候选人之间的对话可能是这样的:
候选人: 用户能否指定搜索半径?如果在搜索半径内没有足够的商家,系统是否会扩大搜索范围?
面试官: 这是个很好的问题。让我们假设我们只关心指定半径内的商家。如果时间允许,我们可以讨论在半径内没有足够商家时如何扩大搜索范围。
候选人: 允许的最大半径是多少?我可以假设是20公里(12.5英里)吗?
面试官: 这是一个合理的假设。
候选人: 用户能否在UI上更改搜索半径?
面试官: 是的,我们有以下选项:0.5公里(0.31英里)、1公里(0.62英里)、2公里(1.24英里)、5公里(3.1英里)和20公里(12.42英里)。
候选人: 商家信息如何添加、删除或更新?我们需要实时反映这些操作吗?
面试官: 商家所有者可以添加、删除或更新商家。假设我们有一个预先的业务协议,新添加/更新的商家将在第二天生效。
候选人: 用户在使用应用/网站时可能在移动,所以一段时间后搜索结果可能会略有不同。我们需要不断刷新页面以保持结果最新吗?
面试官: 让我们假设用户的移动速度很慢,我们不需要持续刷新页面。
功能需求
基于这次对话,我们专注于3个关键功能:
- 基于用户位置(经纬度对)和半径返回所有商家。
- 商家所有者可以添加、删除或更新商家,但这些信息不需要实时反映。
- 客户可以查看商家的详细信息。
非功能需求
从业务需求中,我们可以推断出一系列非功能需求。你也应该与面试官确认这些需求。
- 低延迟。用户应该能够快速看到附近的商家。
- 数据隐私。位置信息是敏感数据。当我们设计基于位置的服务(LBS)时,应该始终考虑用户隐私。我们需要遵守数据隐私法律,如通用数据保护条例(GDPR)[4]和加州消费者隐私法案(CCPA)[5]等。
- 高可用性和可扩展性要求。我们应该确保系统能够处理人口密集区域高峰时段的流量激增。
粗略估算
让我们看一下一些粗略计算,以确定我们的解决方案需要应对的潜在规模和挑战。假设我们有1亿日活跃用户和2亿商家。
计算QPS 一天的秒数 = 24×60×60 = 86,400。我们可以将其四舍五入到10^5以便计算。10^5在本书中用来表示一天的秒数。
- 假设一个用户每天进行5次搜索查询。
- 搜索QPS = 1亿×5/10^5 = 5,000
第2步 - 提出高层设计并获得认可
在本节中,我们讨论以下内容:
- API设计
- 高层设计
- 查找附近商家的算法
- 数据模型
API设计
我们使用RESTful API约定来设计简化版的API。
GET /v1/search/nearby
这个端点基于特定的搜索条件返回商家。在实际应用中,搜索结果通常是分页的。分页[6]不是本章的重点,但在面试中值得提及。
请求参数:
| 字段 | 描述 | 类型 |
|---|---|---|
| latitude | 给定位置的纬度 | decimal |
| longitude | 给定位置的经度 | decimal |
| radius | 可选。默认为5000米(约3英里) | int |
表 1.1: 请求参数
{
"total": 18,
"businesses": [{business object}]
}
business对象包含渲染搜索结果页面所需的所有内容,但我们可能仍需要额外的属性(如图片、评论、星级等)来渲染商家详情页面。因此,当用户点击商家详情页面时,通常需要进行一次服务端点调用来获取商家的详细信息。
商家相关的API
下表显示了与商家相关的 API。
| API | 详情 |
|---|---|
GET /v1/businesses/:id | 返回商家的详细信息 |
POST /v1/businesses | 添加商家 |
PUT /v1/businesses/:id | 更新商家详情 |
DELETE v1/businesses/:id | 删除商家 |
表 1.2: 商家相关的API
如果你对实际的地点/商家搜索API感兴趣,可以举两个例子:Google Places API[7]和Yelp商家端点[8]。
数据模型
在本节中,我们讨论读写比率和架构设计。数据库的可扩展性将在深入探讨部分介绍。
读/写比率
读取量很高,因为以下两个功能经常使用:
- 搜索附近的商家。
- 查看商家的详细信息。
另一方面,写入量较低,因为添加、删除和编辑商家信息是不频繁的操作。
对于读取量大的系统,关系型数据库如MySQL可能是一个不错的选择。让我们仔细看看架构设计。
数据架构
关键的数据库表是商家表和地理空间(geo)索引表。
商家表
商家表包含商家的详细信息。如表1.3所示,主键是business_id。

表 1.3: 商家表
地理索引表
地理索引表用于高效处理空间操作。由于该表需要一些关于geohash的知识,我们将在第24页的"扩展数据库"部分讨论它。
高层设计
高层设计图如图1.2所示。系统包含两个部分:基于位置的服务(LBS)和商家相关服务。让我们看看系统的每个组件。
图 1.2: 高层设计
负载均衡器
负载均衡器自动在多个服务之间分配传入流量。通常,公司提供单一的DNS入口点,并根据URL路径在内部将API调用路由到适当的服务。
基于位置的服务(LBS)
LBS服务是系统的核心部分,用于在给定半径和位置范围内查找附近的商家。LBS具有以下特点:
- 这是一个读取量大且没有写请求的服务。
- QPS很高,特别是在密集区域的高峰时段。
- 这个服务是无状态的,所以很容易水平扩展。
商家服务
商家服务主要处理两类请求:
- 商家所有者创建、更新或删除商家。这些请求主要是写操作,QPS不高。
- 客户查看商家的详细信息。QPS在高峰时段很高。
数据库集群
数据库集群可以使用主从设置。在这种设置中,主数据库处理所有写操作,多个副本用于读操作。数据首先保存到主数据库,然后复制到副本。由于复制延迟,LBS读取的数据和写入主数据库的数据之间可能存在一些差异。这种不一致性通常不是问题,因为商家信息不需要实时更新。
商家服务和LBS的可扩展性
商家服务和LBS都是无状态服务,所以很容易自动添加更多服务器来应对高峰流量(如用餐时间)并在非高峰时段(如睡眠时间)移除服务器。如果系统在云上运行,我们可以设置不同的区域和可用区以进一步提高可用性[9]。我们在深入探讨中会详细讨论这一点。
获取附近商家的算法
在实际应用中,公司可能使用现有的地理空间数据库,如Redis中的Geohash[10]或带PostGIS扩展的Postgres[11]。在面试中,你不需要了解这些地理空间数据库的内部原理。最好是通过解释地理空间索引的工作原理来展示你的问题解决能力和技术知识,而不是简单地列举数据库名称。
下一步是探索获取附近商家的不同选项。我们将列出几个选项,回顾思考过程,并讨论权衡。
选项1:二维搜索
获取附近商家最直观但最简单的方法是画一个预定义半径的圆,并找出圆内的所有商家,如图1.3所示。

图 1.3: 二维搜索
这个过程可以转换为以下伪SQL查询:
Select business_id, latitude, longitude FROM business
WHERE (latitude BETWEEN {:my_lat} - radius AND {:my_lat} + radius)
AND (longitude BETWEEN {:my_long} - radius AND {:my_long} + radius)
这个查询效率不高,因为我们需要扫描整个表。
如果我们在经度和纬度列上建立索引呢?这会提高效率吗?答案是不会提高太多。问题在于我们有二维数据,而每个维度返回的数据集可能仍然很大。例如,如图1.4所示,由于经度和纬度列上的索引,我们可以快速检索数据集1和数据集2。但要获取半径内的商家,我们需要对这两个数据集执行交集操作。这不够高效,因为每个数据集都包含大量数据。
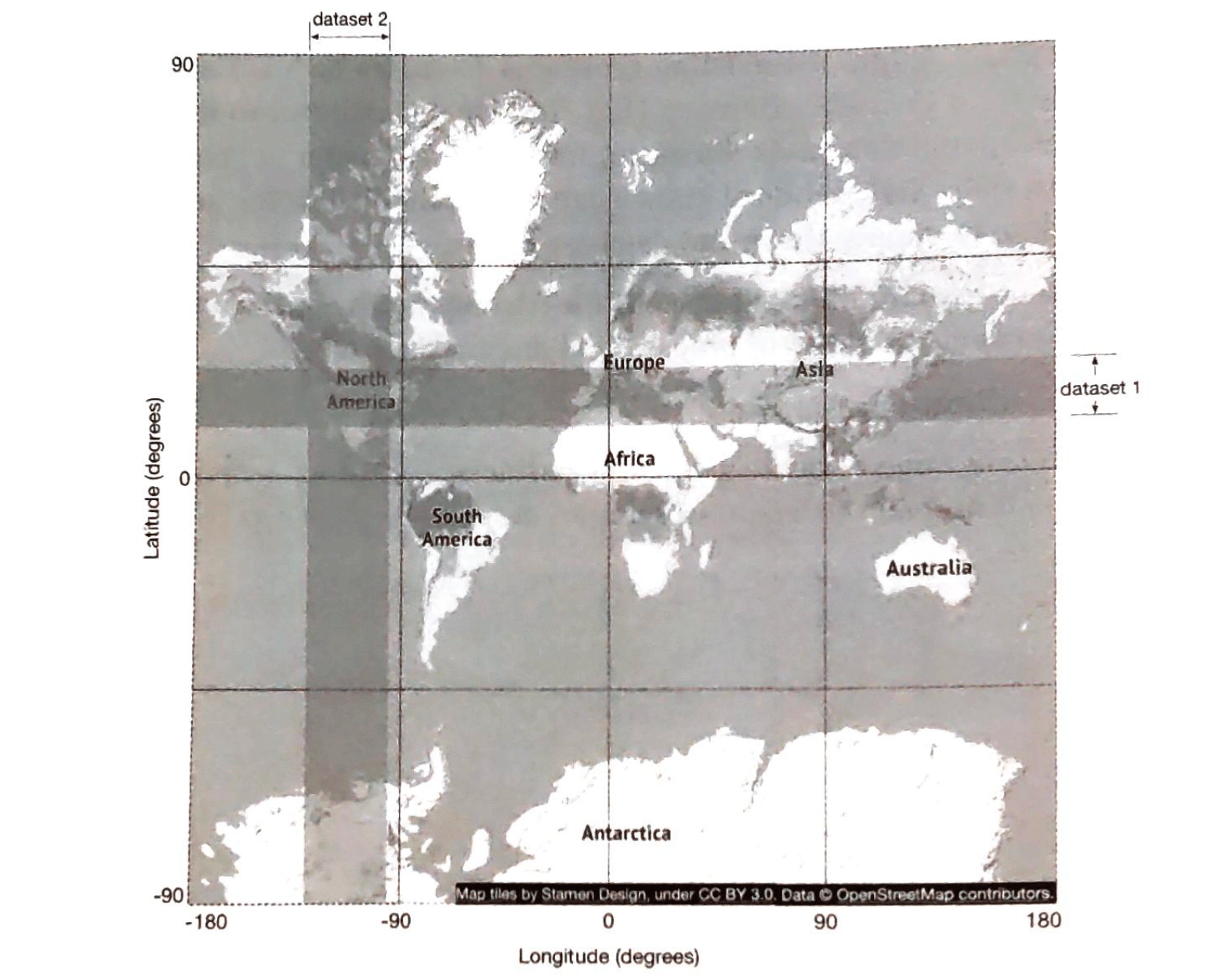
图 1.4: 两个数据集的交集
前面方法的问题在于数据库索引只能提高一个维度的搜索速度。所以自然而然的后续问题是,我们能否将二维数据映射到一维?答案是肯定的。
在深入研究答案之前,让我们看看不同类型的索引方法。
从广义上讲,有两种类型的地理空间索引方法,如图1.5所示。我们详细讨论高亮显示的算法,因为它们在业界常用。
- Hash: 均匀网格、geohash、笛卡尔层[12]等。
- Tree: 四叉树、Google S2、R树[13]等。
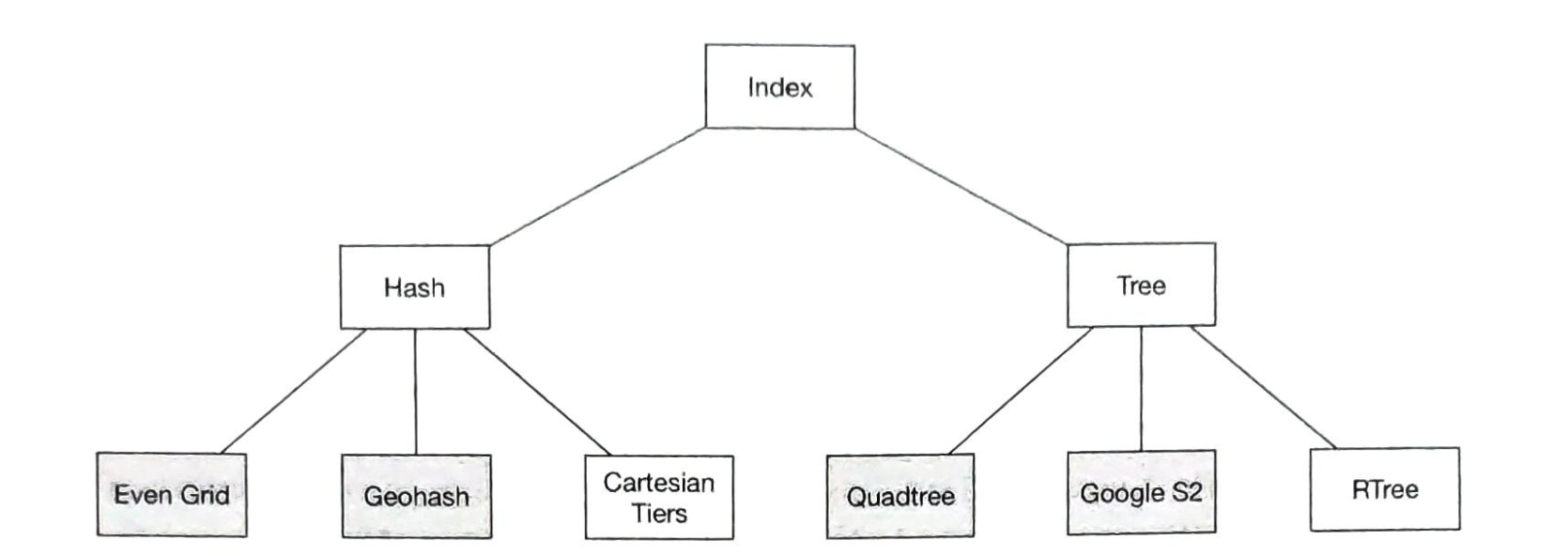
图 1.5: 不同类型的地理空间索引
尽管这些方法的底层实现不同,但高层思想是相同的,即将地图划分为更小的区域,并建立索引以便快速搜索。其中,geohash、四叉树和Google S2在实际应用中最为广泛使用。让我们逐一看看它们。
提醒
在实际面试中,你通常不需要解释索引选项的实现细节。但是,了解地理空间索引的需求、其高层工作原理以及局限性是很重要的。
选项2:均匀划分网格
一种简单的方法是将世界均匀划分为小网格(图1.6)。这样,一个网格可以包含多个商家,地图上的每个商家都属于一个网格。
图 1.6: 全球地图(来源:[14])
这种方法在某种程度上有效,但有一个主要问题:商家的分布不均匀。纽约市中心可能有很多商家,而沙漠或海洋中的其他网格可能根本没有商家。通过将世界划分为均匀网格,我们产生了非常不均匀的数据分布。理想情况下,我们希望在密集区域使用更细粒度的网格,在稀疏区域使用大网格。另一个潜在的挑战是找到固定网格的相邻网格。
选项3:Geohash
Geohash比均匀划分网格选项更好。它通过将二维经纬度数据减少为一维字母和数字字符串来工作。Geohash算法通过递归地将世界划分为越来越小的网格来工作,每增加一位就划分一次。让我们从高层次了解geohash是如何工作的。
首先,沿着本初子午线和赤道将地球分为四个象限。
图 1.7: Geohash
- 纬度范围(-90, 0]用0表示
- 纬度范围[0, 90]用1表示
- 经度范围(-180, 0]用0表示
- 经度范围[0, 180]用1表示
第二步,将每个网格分为四个更小的网格。每个网格可以通过交替使用经度位和纬度位来表示。
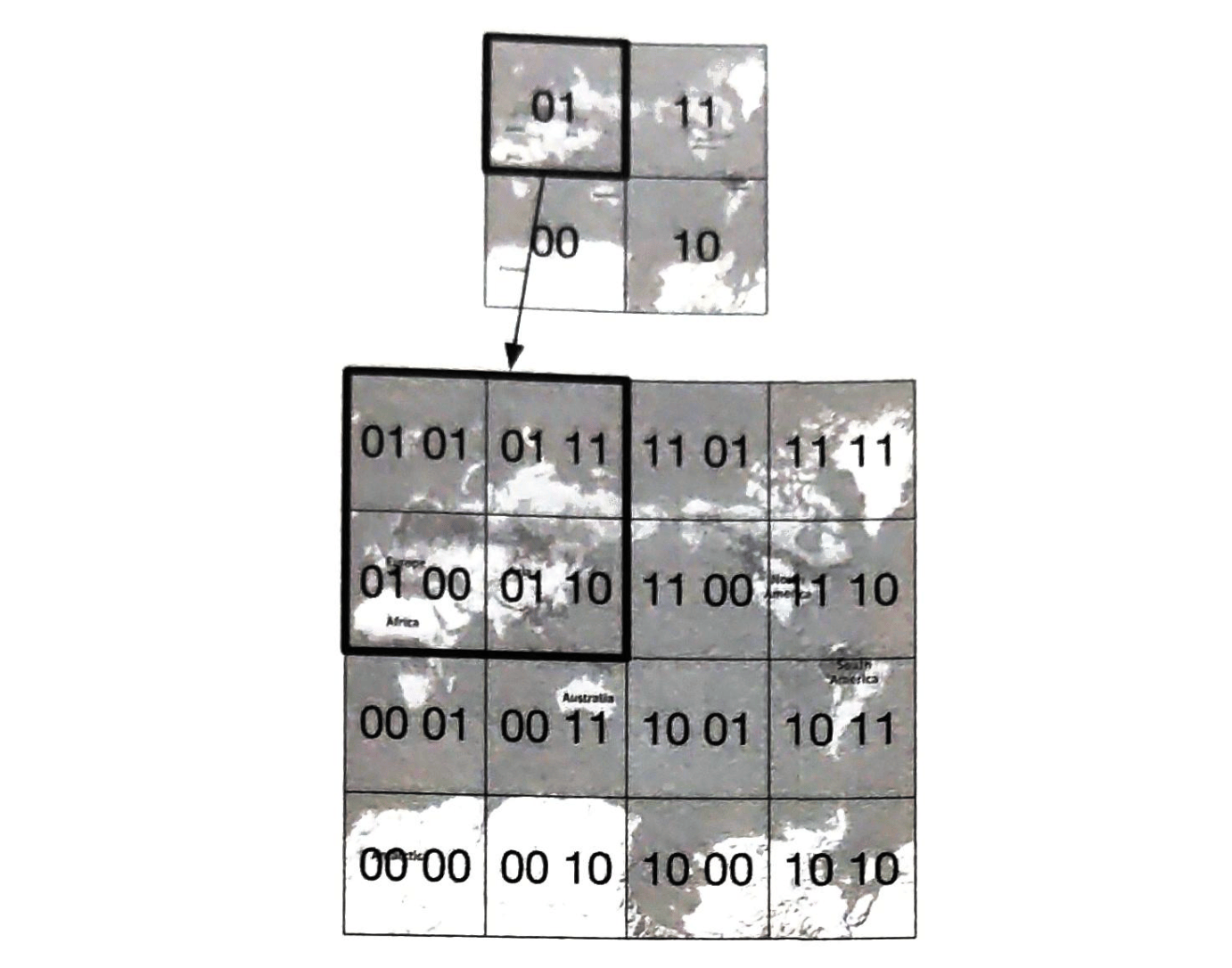 图 1.8: 划分网格
图 1.8: 划分网格
重复这个细分过程,直到网格大小达到所需的精度。Geohash通常使用base32表示[15]。让我们看两个例子。
- Google总部的geohash(长度=6):
1001 10110 01001 10000 11011 11010(二进制的base32) -> 9q9hvu(base32) - Facebook总部的geohash(长度=6):
1001 10110 01001 10001 10000 10111(二进制的base32) -> 9q9jhr(base32)
Geohash有12个精度(也称为级别),如表1.4所示。精度因子决定了网格的大小。我们只对长度在4到6之间的geohash感兴趣。这是因为当长度超过6时,网格太小,而当长度小于4时,网格太大(见表1.4)。
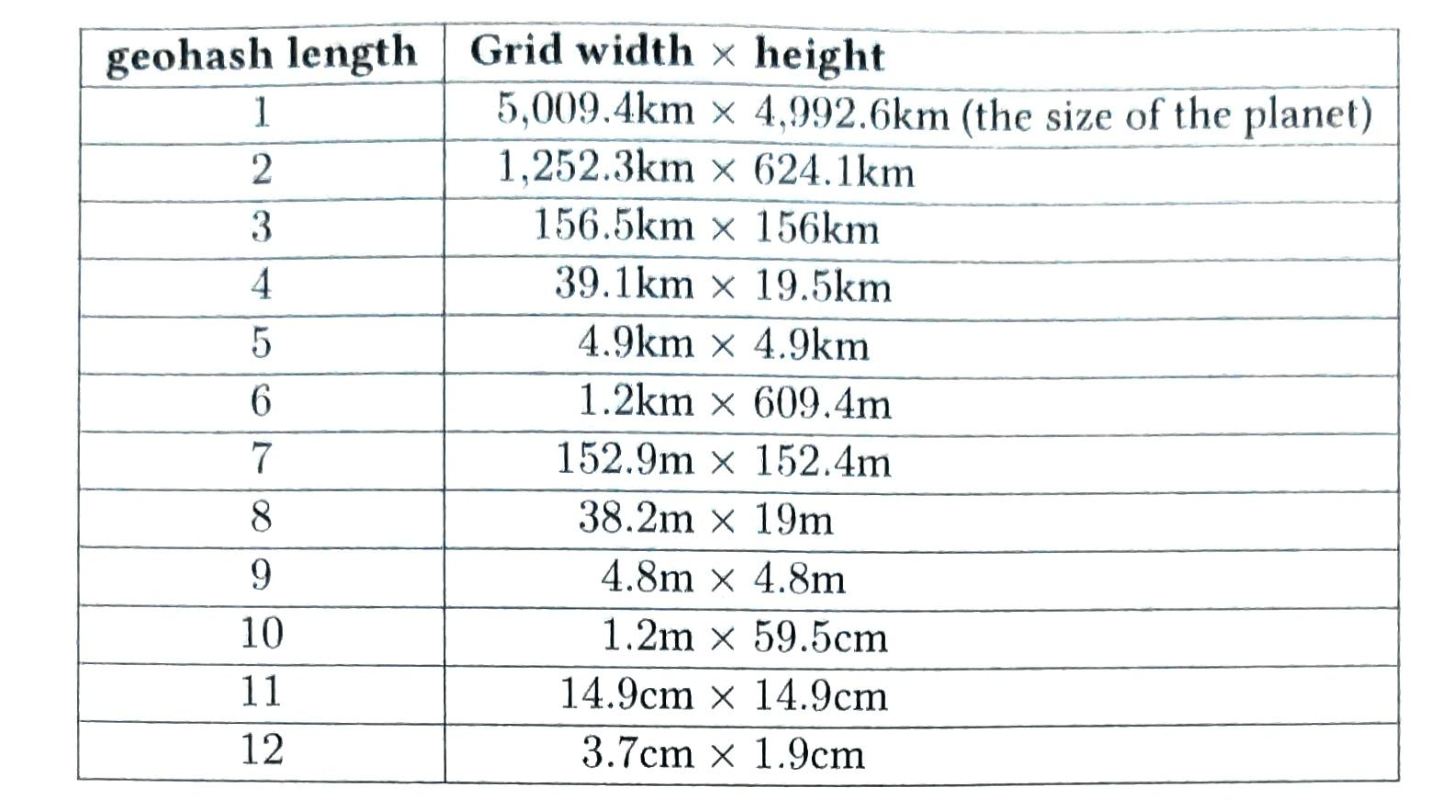
表 1.4: Geohash长度到网格大小的映射(来源:[16])
我们如何选择正确的精度?我们想要找到能覆盖用户定义半径画出的整个圆的最小geohash长度。半径和geohash长度之间的对应关系如下表所示。
表 1.5: 半径到geohash的映射
这种方法在大多数情况下都很好用,但我们应该与面试官讨论一下geohash边界处理的一些边缘情况。
边界问题
Geohash保证两个geohash之间共享的前缀越长,它们就越接近。如图1.9所示,所有网格都有一个共享前缀:9q8zn。

图 1.9: 共享前缀
边界问题1
然而,反过来并不成立:两个位置可能很接近但完全没有共享前缀。这是因为位于赤道或本初子午线两侧的两个接近位置属于世界的不同"半边"。例如,在法国,La Roche-Chalais(geohash: U08)距离Pomerol(geohash: ezzz)只有30公里,但它们的geohash完全没有共享前缀[17]。

图 1.10: 没有共享前缀
由于这个边界问题,下面这个简单的前缀SQL查询将无法获取所有附近的商家。
SELECT * FROM geohash_index WHERE geohash LIKE '9q8zn%'
边界问题2
另一个边界问题是两个位置可能有很长的共享前缀,但它们属于不同的geohash,如图1.11所示。

图 1.11: 边界问题
一个常见的解决方案是不仅获取当前网格内的所有商家,还要获取其邻居网格中的商家。邻居的geohash可以在常数时间内计算出来,更多细节可以在这里找到[17]。
商家不足
现在让我们解决额外的问题。如果当前网格和所有邻居网格中的商家加起来不够怎么办?
选项1:只返回半径内的商家。
这个选项容易实现,但缺点很明显。它不能返回足够的结果来满足用户的需求。
选项2:增加搜索半径。
我们可以删除geohash的最后一位数字,并使用新的geohash来获取附近的商家。如果商家数量不够,我们继续通过删除另一位数字来扩大范围。这样,网格大小会逐渐扩大,直到结果数量超过所需数量。图1.12显示了扩展搜索过程的概念图。
图 1.12: 扩展搜索过程
选项4:四叉树
另一个流行的解决方案是四叉树。四叉树[18]是一种数据结构,通常用于通过递归地将二维空间划分为四个象限(网格)来对其进行分区,直到网格的内容满足某些标准。
例如,标准可以是继续细分直到网格中的商家数量不超过100。这个数字是任意的,实际数字可以根据业务需求来确定。使用四叉树,我们在内存中构建一个树结构来回答查询。请注意,四叉树是一个内存数据结构,而不是数据库解决方案。它在每个LBS服务器上运行,数据结构在服务器启动时构建。
下图展示了将世界划分为四叉树的概念过程。让我们假设世界包含2亿个商家。
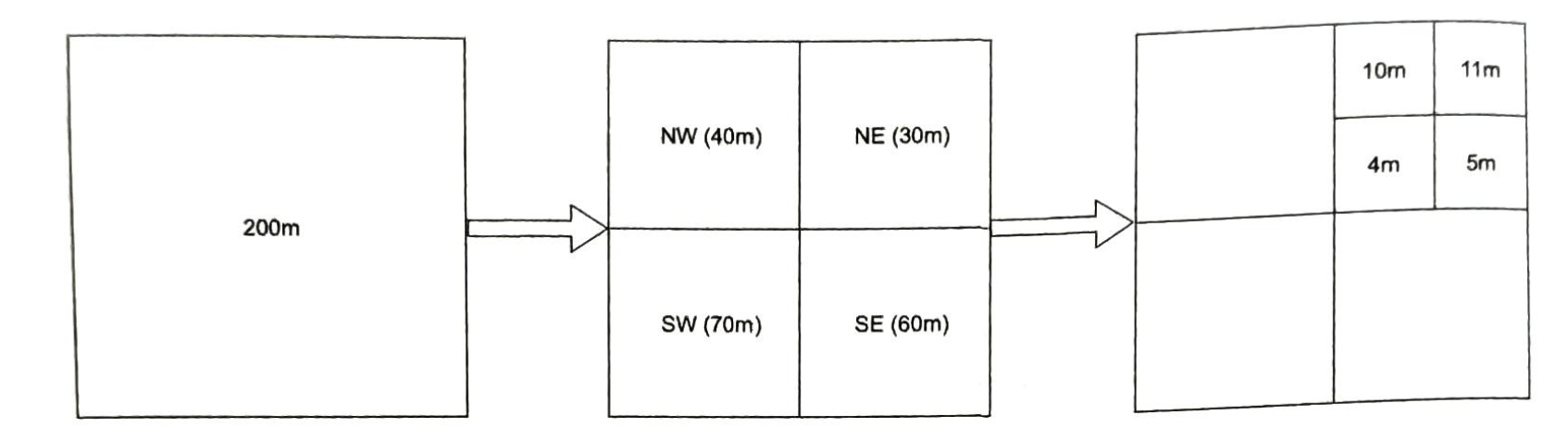
图 1.13: 四叉树
图1.14更详细地解释了四叉树的构建过程。根节点代表整个世界地图。根节点被递归地分解为4个象限,直到没有节点包含超过100个商家。
图 1.14: 构建四叉树
构建四叉树的伪代码如下所示:
public void buildQuadtree(TreeNode node) {
if (countNumberOfBusinessesInCurrentGrid(node) > 100) {
node.subdivide();
for (TreeNode child : node.getChildren()) {
buildQuadtree(child);
}
}
}
存储整个四叉树需要多少内存?
要回答这个问题,我们需要知道存储什么样的数据。
叶子节点上的数据

表 1.6: 叶子节点
内部节点上的数据

表 1.7: 内部节点
尽管树的构建过程取决于网格内的商家数量,但这个数字不需要存储在四叉树节点中,因为它可以从数据库中的记录推断出来。
现在我们知道了每个节点的数据结构,让我们看看内存使用情况。
- 每个网格最多可以存储100个商家
- 叶子节点数量 = ~2亿/100 = ~200万
- 内部节点数量 = 200万×1/3 = ~67万。如果你不知道为什么内部节点数量是叶子节点数量的三分之一,请阅读参考资料[19]
- 总内存需求 = 200万×832字节 + 67万×64字节 = ~1.71GB。即使我们添加一些构建树的开销,构建树的内存需求也相当小。
在实际面试中,我们不需要这么详细的计算。这里的关键点是四叉树索引不会占用太多内存,可以轻松地放在一台服务器上。
这是否意味着我们应该只使用一台服务器来存储四叉树索引?答案是否定的。根据读取量,单个四叉树服务器可能没有足够的CPU或网络带宽来服务所有读取请求。如果是这种情况,就有必要在多个四叉树服务器之间分散读取负载。
构建整个四叉树需要多长时间?
每个叶子节点包含大约100个商家ID。构建树的时间复杂度是 $\frac{n}{100}$ log $\frac{n}{100}$ ,其中n是商家总数。对于2亿个商家,可能需要几分钟来构建整个四叉树。
如何使用四叉树获取附近的商家?
- 在内存中构建四叉树。
- 四叉树构建完成后,从根开始搜索并遍历树,直到找到包含搜索原点的叶子节点。如果该叶子节点有100个商家,返回该节点。否则,从其邻居那里添加商家,直到返回足够的商家。
四叉树的操作考虑 如上所述,对于2亿个商家,在服务器启动时构建四叉树可能需要几分钟。考虑这么长的服务器启动时间的操作影响很重要。在四叉树构建期间,服务器无法处理流量。因此,我们应该逐步地将新版本的服务器发布到服务器的一小部分子集。这避免了使服务器集群的大部分离线并导致服务中断。蓝/绿部署[20]也可以使用,但整个新服务器集群同时从数据库服务获取2亿个商家可能会给系统带来很大压力。这是可以做到的,但可能会使设计变得复杂,你应该在面试中提到这一点。
另一个操作考虑是随着时间的推移,商家被添加和删除时如何更新四叉树。最简单的方法是在整个集群中逐步重建四叉树,每次只重建一小部分服务器。但这意味着一些服务器在短时间内会返回过时的数据。然而,根据需求,这通常是一个可以接受的折折中方案。这可以通过设置业务协议来进一步缓解,即新添加/更新的商家将在第二天生效。这意味着我们可以使用夜间作业来更新缓存。这种方法的一个潜在问题是大量的键会在同一时间失效,导致缓存服务器负载过重。
也可以在商家添加和删除时动态更新四叉树。这当然会使设计变得更复杂,特别是如果四叉树数据结构可能被多个线程访问。这将需要一些锁定机制,这可能会大大复杂化四叉树的实现。
四叉树的实际例子
Yext[21]提供了一张图片(图1.15),显示了在丹佛附近构建的四叉树[21]。我们希望在密集区域使用更小、更细粒度的网格,在稀疏区域使用更大的网格。
图 1.15: 四叉树的实际例子
选项5:Google S2
Google S2几何库[22]是该领域的另一个重要参与者。与四叉树类似,它是一个内存解决方案。它基于希尔伯特曲线(一种空间填充曲线)[23]将球体映射到1D索引。希尔伯特曲线有一个非常重要的特性:在希尔伯特曲线上彼此接近的两个点在1D空间中也是接近的(图1.16)。在1D空间上的搜索比在2D空间上的搜索效率要高得多。感兴趣的读者可以使用在线工具[24]来体验希尔伯特曲线。
图 1.16: 希尔伯特曲线(来源:[24])
S2是一个复杂的库,在面试中你不需要解释其内部原理。但是因为它在Google、Tinder等公司广泛使用,我们将简要介绍它的优势。
-
S2非常适合地理围栏,因为它可以用不同级别覆盖任意区域(图1.17)。根据维基百科,"地理围栏是真实地理区域的虚拟边界。地理围栏可以动态生成-例如以点位置为中心的半径,或者地理围栏可以是预定义的边界集合(如学校区域或邻里边界)"[25]。 地理围栏允许我们定义围绕感兴趣区域的边界,并向离开区域的用户发送通知。这可以提供比仅返回附近商家更丰富的功能。
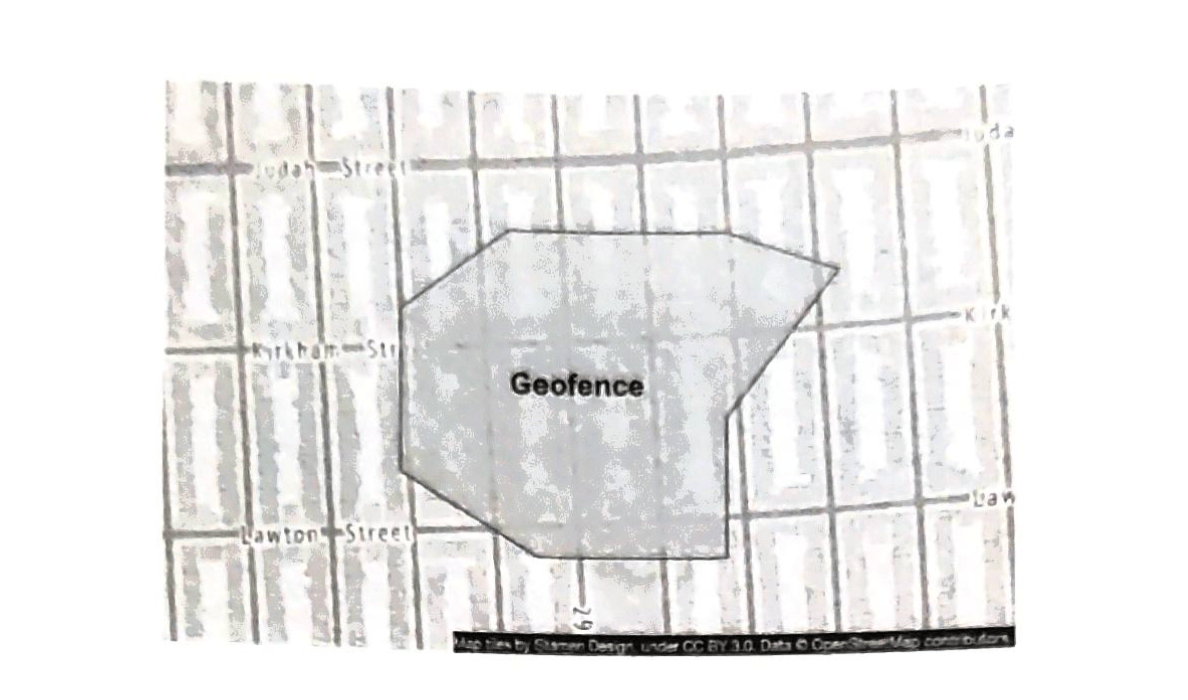
图 1.17: 地理围栏 -
S2的另一个优势是其区域覆盖算法[26]。与geohash中的固定级别(精度)不同,在S2中我们可以指定最小级别、最大级别和最大单元格数。由于单元格大小是灵活的,S2返回的结果更加精细。如果你想了解更多,可以看看S2工具[26]。
建议
为了高效地查找附近的商家,我们讨论了几个选项:geohash、四叉树和S2。如表1.8所示,不同的公司或技术采用不同的选项。

表 1.8: 不同类型的地理索引
在面试中,我们建议选择geohash或四叉树,因为S2太复杂,在面试中很难清楚地解释。
Geohash vs 四叉树 在结束本节之前,让我们快速比较一下geohash和四叉树。
Geohash
- 使用和实现都很简单。不需要构建树。
- 支持返回指定半径内的商家。
- 当geohash的精度(级别)固定时,网格大小也是固定的。它不能根据人口密度动态调整网格大小。需要更复杂的逻辑来支持这一点。
- 更新索引很容易。例如,要从索引中删除一个商家,我们只需要从具有相同geohash和business_id的对应行中删除它。见图1.18的具体示例。
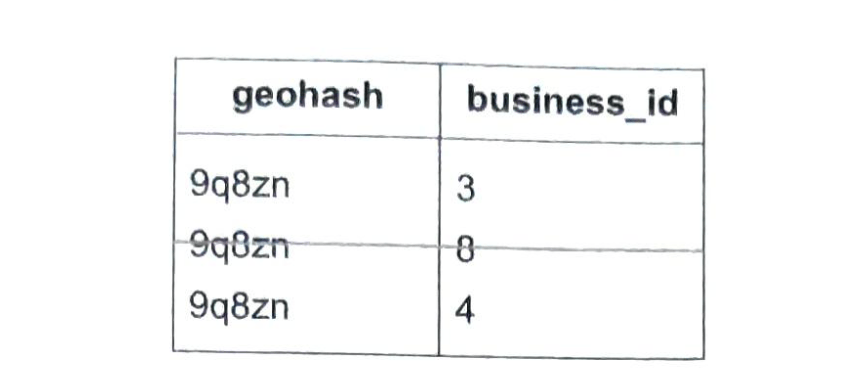
图 1.18: 删除商家
四叉树
- 由于需要构建树,实现稍微复杂一些。
- 支持获取k个最近的商家。有时我们只想返回k个最近的商家,不关心商家是否在指定半径内。例如,当你在旅行时汽车油量不足,你只想找到最近的加油站。这些加油站可能离你不近,但应用程序需要返回最近的k个结果。对于这类查询,四叉树是一个很好的选择,因为它的细分过程是基于数量的,它可以自动调整查询范围直到返回k个结果。
- 它可以根据人口密度动态调整网格大小(见图1.15中的丹佛示例)。
- 更新索引比geohash更复杂。四叉树是一个树结构。如果要删除一个商家,我们需要从根节点遍历到叶子节点来删除该商家。例如,如果我们想删除ID=2的商家,我们必须从根节点一直遍历到叶子节点,如图1.19所示。更新索引的时间复杂度是O(log n),但如果数据结构被多线程程序访问,实现会变得复杂,因为需要锁定。此外,重新平衡树也可能很复杂。例如,当叶子节点没有空间容纳新添加的商家时,就需要重新平衡。一个可能的解决方案是过度分配范围。
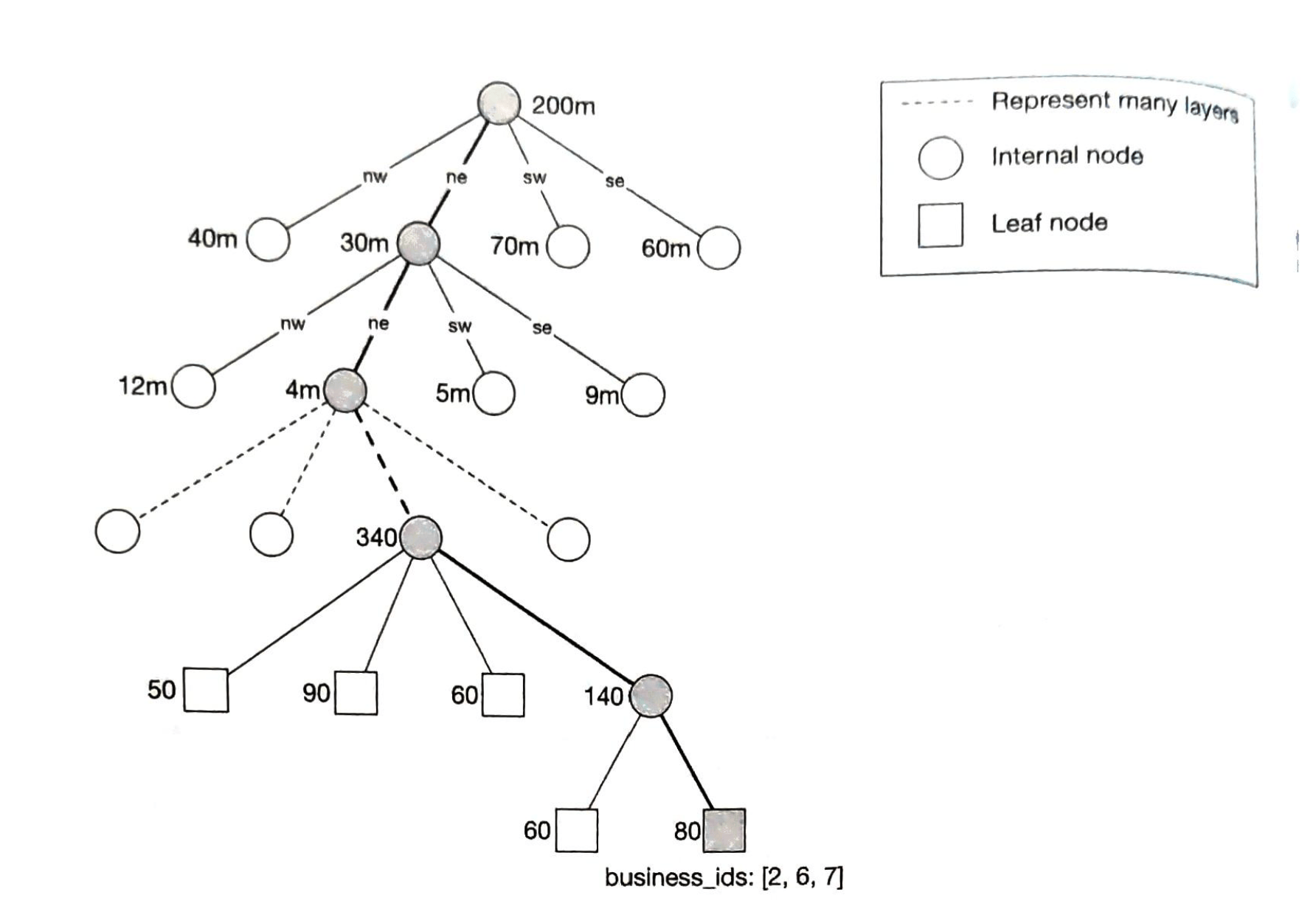
图 1.19: 更新四叉树
第3步 - 深入设计
到目前为止,你应该对整个系统有了很好的了解。现在让我们深入研究几个领域:
- 扩展数据库
- 缓存
- 区域和可用区
- 按时间或商家类型过滤结果
- 最终架构图
扩展数据库
我们将讨论如何扩展两个最重要的表:商家表和地理空间索引表。
商家表
商家表的数据可能无法全部放在一台服务器上,所以它是分片的好候选。最简单的方法是按business_id分片。这种分片方案确保负载在所有分片之间均匀分布,并且在运维上很容易维护。
地理空间索引表
Geohash和四叉树都被广泛使用。由于geohash的简单性,我们用它作为示例。有两种方式来构建表。
选项1:对于每个geohash键,在单行中有一个business_id的JSON数组。这意味着一个geohash内的所有business_id都存储在一行中。

表 1.9: list_of_business_ids是一个JSON数组
选项2:如果同一个geohash中有多个商家,将有多行,每个商家一行。这意味着一个geohash内的不同business_id存储在不同的行中。

表 1.10: business_id是单个ID
以下是选项2的一些示例行。
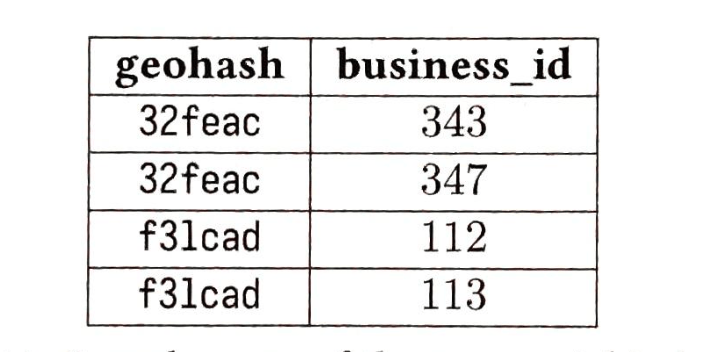
表 1.11: 地理空间索引表的示例行
建议:我们推荐选项2,原因如下: 对于选项1,要更新一个商家,我们需要获取business_id数组并扫描整个数组来找到要更新的商家。插入新商家时,我们必须扫描整个数组以确保没有重复。我们还需要锁定该行以防止并发更新。有很多边缘情况需要处理。 对于选项2,如果我们有两列组成的复合键(geohash, business_id),添加和删除商家就非常简单。不需要锁定任何内容。
扩展地理空间索引
关于扩展地理空间索引的一个常见错误是在考虑表的实际数据大小之前就急于采用分片方案。在我们的案例中,地理空间索引表的完整数据集并不大(四叉树索引只需要1.71G内存,geohash索引的存储需求类似)。整个地理空间索引可以轻松地放入现代数据库服务器的工作集中。然而,根据读取量,单个数据库服务器可能没有足够的CPU或网络带宽来处理所有读取请求。如果是这种情况,就有必要在多个数据库服务器之间分散读取负载。
有两种通用方法来分散关系数据库服务器的负载。我们可以添加读副本,或者对数据库进行分片。
许多工程师喜欢在面试中谈论分片。然而,对于geohash表来说,这可能不是一个好选择,因为分片很复杂。例如,分片逻辑必须添加到应用层。有时,分片是唯一的选择。但在这种情况下,所有内容都可以放入数据库服务器的工作集中,所以没有强有力的技术理由在多个服务器之间分片数据。
在这种情况下,更好的方法是使用一系列读副本来帮助处理读取负载。这种方法在开发和维护上要简单得多。因此,建议通过副本来扩展地理空间索引表。
缓存
在引入缓存层之前,我们必须问自己,我们真的需要缓存层吗?
缓存是否有明显的优势并不明显:
- 工作负载是读取密集型的,数据集相对较小。数据可以放入任何现代数据库服务器的工作集中。因此,查询不受I/O限制,它们的运行速度应该几乎和内存缓存一样快。
- 如果读取性能成为瓶颈,我们可以添加数据库读副本来提高读取吞吐量。
在与面试官讨论缓存时要谨慎,因为它需要仔细的基准测试和成本分析。如果你发现缓存确实符合业务需求,那么你可以继续讨论缓存策略。
缓存键
最直接的缓存键选择是用户的位置坐标(纬度和经度)。然而,这种选择有几个问题:
- 手机返回的位置坐标并不准确,因为它们只是最佳估计[32]。即使你不移动,每次在手机上获取坐标时结果可能也略有不同。
- 用户可以从一个位置移动到另一个位置,导致位置坐标略有变化。对于大多数应用来说,这种变化并不重要。
因此,位置坐标不是一个好的缓存键。理想情况下,位置的小变化应该仍然映射到相同的缓存键。前面提到的geohash/四叉树解决方案很好地处理了这个问题,因为一个网格内的所有商家都映射到相同的geohash。
要缓存的数据类型
如表1.12所示,有两种类型的数据可以缓存以提高系统的整体性能:

表 1.12: 缓存中的键值对
网格中的商家ID列表
由于商家数据相对稳定,我们预先计算给定geohash的商家ID列表并将其存储在Redis等键值存储中。让我们看一个启用缓存获取附近商家的具体示例。
-
获取给定geohash的商家ID列表。 SELECT business_id FROM geohash_index WHERE geohash LIKE '{geohash}%'
-
如果缓存未命中,将结果存储在Redis缓存中。
public List<String> getNearbyBusinessIds(String geohash) {
String cacheKey = hash(geohash);
List<String> listOfBusinessIds = Redis.get(cacheKey);
if (listOfBusinessIds == null) {
listOfBusinessIds = Run the select SQL query above;
Cache.set(cacheKey, listOfBusinessIds, "1d");
}
return listOfBusinessIds;
}
当添加、编辑或删除新商家时,数据库会更新并使缓存失效。由于这些操作的数量相对较小,并且geohash方法不需要锁定机制,更新操作很容易处理。
根据需求,用户可以在客户端选择以下4个半径:500m、1km、2km和5km。这些半径分别映射到长度为4、5、5和6的geohash。为了快速获取不同半径的附近商家,我们在Redis中缓存所有三个精度(geohash_4、geohash_5和geohash_6)的数据。
如前所述,我们有2亿个商家,每个商家在给定精度下属于1个网格。因此所需的总内存是:
- Redis值的存储:8字节×2亿×3个精度 = ~5GB
- Redis键的存储:可以忽略不计
- 所需总内存:~5GB
从内存使用的角度来看,我们可以使用一台现代Redis服务器,但为了确保高可用性并减少跨大洲的延迟,我们在全球部署Redis集群。考虑到估计的数据大小,我们可以在全球部署相同的缓存数据副本。我们在最终架构图(图1.21)中将这个Redis缓存称为"Geohash"。
渲染客户端页面所需的商家数据 这种类型的数据缓存非常直接。键是business_id,值是包含商家名称、地址、图片URL等的商家对象。我们在最终架构图(图1.21)中将这个Redis缓存称为"Business info"。
区域和可用区
我们将基于位置的服务部署到多个区域和可用区,如图1.20所示。这有几个优点:
- 使用户在物理上"更接近"系统。美国西部的用户连接到该区域的数据中心,欧洲的用户连接到欧洲的数据中心。
- 让我们能够根据人口灵活地均匀分散流量。日本和韩国等一些地区人口密度高。将它们放在单独的区域,或者甚至在多个可用区部署基于位置的服务来分散负载可能是明智的。
- 隐私法律。某些国家可能要求用户数据在本地使用和存储。在这种情况下,我们可以在该国设置一个区域,并使用DNS路由将该国的所有请求限制在该区域内。
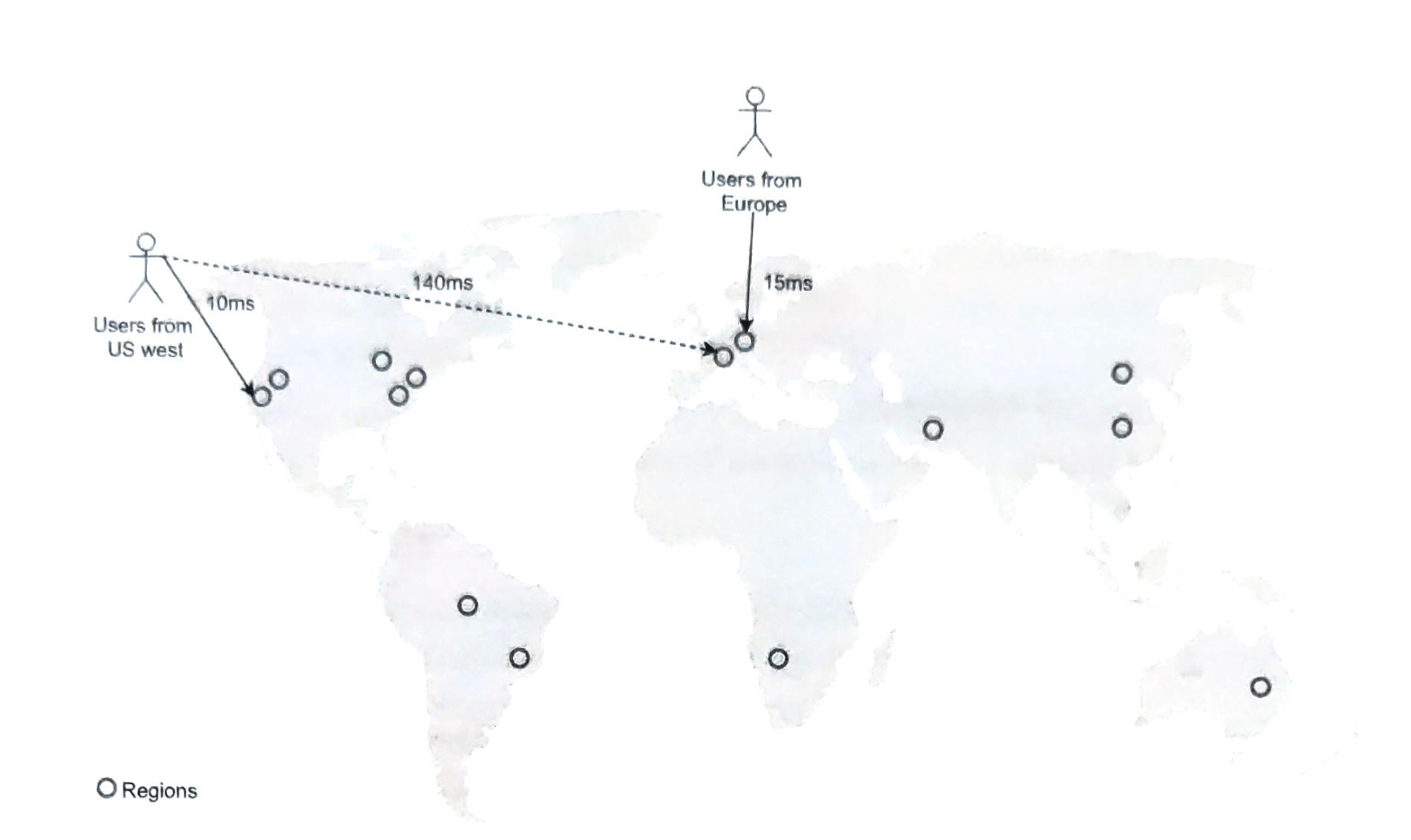
图 1.20: 将LBS部署"更接近"用户
后续问题:按时间或商家类型过滤结果
面试官可能会问一个后续问题:如何返回现在营业的商家,或者只返回餐厅类型的商家?
候选人:当世界用geohash或四叉树划分为小网格时,搜索结果返回的商家数量相对较少。因此,先返回商家ID,然后填充商家对象,并根据营业时间或商家类型进行过滤是可以接受的。这个解决方案假设营业时间和商家类型存储在商家表中。
最终设计图
把所有内容放在一起,我们得到以下设计图。
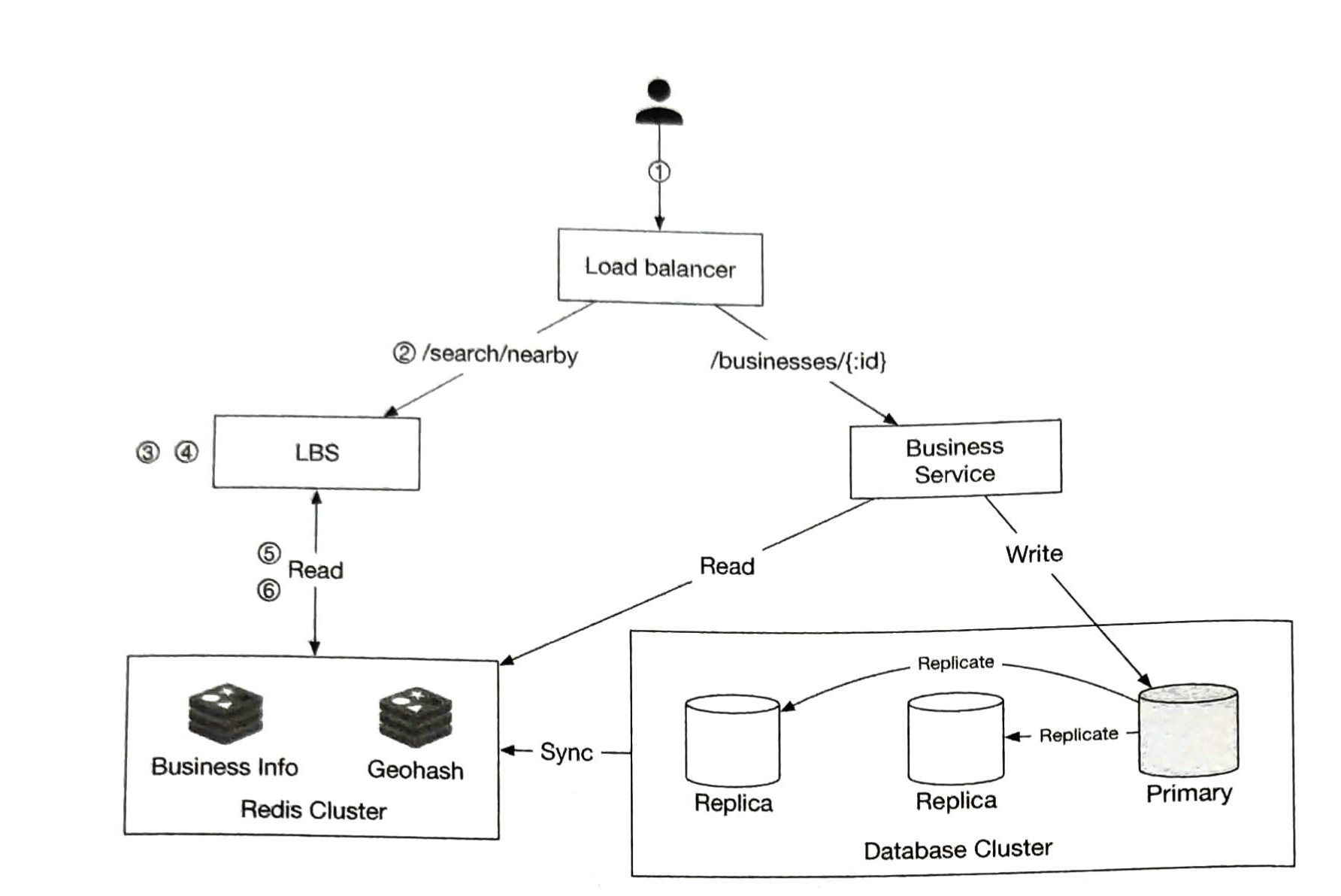
图 1.21: 设计图
获取附近商家
- 你在Yelp上尝试查找500米范围内的餐厅。客户端将用户位置(纬度=37.776720,经度=-122.416730)和半径(500m)发送到负载均衡器。
- 负载均衡器将请求转发到LBS。
- 基于用户位置和半径信息,LBS找到匹配搜索的geohash长度。通过查看表1.5,500m对应geohash长度=6。
- LBS计算相邻的geohash并将它们添加到列表中。结果看起来像这样: list_of_geohashes = [my_geohash, neighbor1_geohash, neighbor2_geohash, ..., neighbor8_geohash]。
- 对于list_of_geohashes中的每个geohash,LBS调用"Geohash" Redis服务器来获取相应的商家ID。获取每个geohash的商家ID的调用可以并行进行以减少延迟。
- 基于返回的商家ID列表,LBS从"Business info" Redis服务器获取完整的商家信息,然后计算用户和商家之间的距离,对它们进行排序,并将结果返回给客户端。
查看、更新、添加或删除商家
所有与商家相关的API都与LBS分开。要查看商家的详细信息,商家服务首先检查数据是否存储在"Business info" Redis缓存中。如果是,将返回缓存的数据给客户端。如果不是,从数据库集群获取数据并存储在Redis缓存中,允许后续请求直接从缓存获取结果。
由于我们有一个预先的业务协议,新添加/更新的商家将在第二天生效,缓存的商家数据由夜间作业更新。
第4步 - 总结
在本章中,我们介绍了附近地点服务的设计。该系统是一个典型的利用地理空间索引的LBS。我们讨论了几个索引选项:
- 二维搜索
- 均匀划分网格
- Geohash
- 四叉树
- Google S2
Geohash、四叉树和S2被不同的科技公司广泛使用。我们选择geohash作为示例来展示地理空间索引是如何工作的。
在深入探讨中,我们讨论了为什么缓存在减少延迟方面是有效的,应该缓存什么以及如何使用缓存快速检索附近的商家。我们还讨论了如何通过复制和分片来扩展数据库。
然后我们研究了在不同区域和可用区部署LBS,以提高可用性,使用户在物理上更接近服务器,并更好地遵守当地隐私法律。
恭喜你走到这里!现在给自己一个鼓励。干得好!
章节总结
参考资料
[1] Yelp. https://www.yelp.com/
[2] Map tiles by Stamen Design. http://maps.stamen.com/
[3] OpenStreetMap. https://www.openstreetmap.org
[4] GDPR. https://en.wikipedia.org/wiki/General_Data_Protection_Regulation
[5] CCPA. https://en.wikipedia.org/wiki/California_Consumer_Privacy_Act
[6] REST API中的分页. https://developer.atlassian.com/server/confluence/ pagination-in-the-rest-api/
[7] Google places API. https://developers.google.com/maps/documentation/places/web-service/search
[8] Yelp商家端点. https://www.yelp.com/developers/documentation/v3/business_search
[9] 区域和可用区. https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/using-regions-availability-zones.html
[10] Redis GEOHASH. https://redis.io/commands/GEOHASH
[11] POSTGIS. https://postgis.net/
[12] 笛卡尔层. http://www.nsshutdown.com/projects/lucene/whitepaper/locallucene_v2.html
[13] R-tree. https://en.wikipedia.org/wiki/R-tree
[14] 地理坐标参考系统中的全球地图. https://bit.ly/3DsjAwg
[15] Base32. https://en.wikipedia.org/wiki/Base32
[16] Geohash网格聚合. https://bit.ly/3kK146
[17] Geohash. https://www.movable-type.co.uk/scripts/geohash.html
[18] 四叉树. https://en.wikipedia.org/wiki/Quadtree
[19] 四叉树有多少叶子. https://stackoverflow.com/questions/35976444/how-many-leaves-has-a-quadtree
[20] 蓝绿部署. https://martinfowler.com/bliki/BlueGreenDeployment.html
[21] 使用四叉树改进位置缓存. https://engblog.yext.com/post/geolocation-caching
[22] S2. https://s2geometry.io/
[23] 希尔伯特曲线. https://en.wikipedia.org/wiki/Hilbert_curve
[24] 希尔伯特映射. http://bit-player.org/extras/hilbert/hilbert-mapping.html
[25] 地理围栏. https://en.wikipedia.org/wiki/Geo-fence
[26] 区域覆盖. https://s2.sidewalklabs.com/regioncoverer/
[27] Bing地图. https://bit.ly/30ytSfG
[28] MongoDB. https://docs.mongodb.com/manual/tutorial/build-a-2d-index/
[29] 地理空间索引:支持Lyft的每秒1000万QPS的Redis架构. https://www.youtube.com/watch?v=cSFWIF96Sds&t=2155s
[30] 地理形状类型. https://www.elastic.co/guide/en/elasticsearch/reference/1.6/mapping-geo-shape-type.html
[31] 地理分片推荐第1部分:分片方法. https://medium.com/tinder-engineering/geosharded-recommendations-part-1-sharding-approach-d5d540ec77a
[32] 获取最后已知位置. https://developer.android.com/training/location/retrieve-current#Challenges
第2章 附近的好友
在本章中,我们将为一个移动应用的新功能"附近的好友"设计一个可扩展的后端系统。对于选择加入并授予位置访问权限的用户,移动客户端会显示地理位置上靠近的好友列表。如果你想看一个真实的例子,可以参考这篇关于Facebook应用类似功能的文章[1]。
图2.1: Facebook的附近好友功能
如果你读过第1章"邻近服务",你可能会想知道为什么我们需要单独一章来设计"附近的好友",因为它看起来与邻近服务很相似。但如果仔细思考,你会发现有重大区别。在邻近服务中,商家的地址是静态的,因为它们的位置不会改变,而在"附近的好友"中,数据更加动态,因为用户的位置经常变化。
第1步 - 理解问题并确定设计范围
任何达到Facebook规模的后端系统都十分复杂。在开始设计之前,我们需要问一些澄清性问题来缩小范围。
候选人:多近的距离才算是"附近"?
面试官:5英里。这个数字应该是可配置的。
候选人:我可以假设距离是按用户之间的直线距离计算吗?在现实生活中,用户之间可能会有河流等障碍物,导致实际行程距离更长。
面试官:是的,这是一个合理的假设。
候选人:这个应用有多少用户?我可以假设有10亿用户,其中10%使用附近好友功能吗?
面试官:是的,这是一个合理的假设。
候选人:我们需要存储位置历史记录吗?
面试官:是的,位置历史记录对机器学习等不同用途很有价值。
候选人:如果一个好友超过10分钟没有活动,这个好友是否会从附近好友列表中消失?或者我们应该显示最后已知的位置?
面试官:我们可以假设不活跃的好友将不再显示。
候选人:我们需要担心GDPR或CPA等隐私和数据法律吗?
面试官:好问题。为了简单起见,现在暂时不用考虑这个问题。
功能需求
- 用户应该能够在移动应用上查看附近的好友。每个好友条目都会显示与用户的距离以及该距离信息的最后更新时间。
- 附近好友列表应该每隔几秒钟更新一次。
非功能需求
- 低延迟。及时接收好友的位置更新很重要。
- 可靠性。系统整体需要可靠,但偶尔的数据点丢失是可以接受的。
- 最终一致性。位置数据存储不需要强一致性。在不同副本中接收位置数据有几秒钟的延迟是可以接受的。
粗略估算
让我们做一个粗略估算来确定我们的解决方案需要解决的潜在规模和挑战。以下是一些约束和假设:
- 附近的好友定义为位置在5英里半径范围内的好友。
- 位置刷新间隔为30秒。这是因为人类步行速度较慢(平均每小时3~4英里)。30秒内行走的距离对"附近的好友"功能影响不大。
- 平均每天有1亿用户使用"附近的好友"功能。
- 假设并发用户数是DAU(日活跃用户)的10%,所以并发用户数是1000万。
- 平均每个用户有400个好友。假设所有好友都使用"附近的好友"功能。
- 应用每页显示20个附近的好友,并可以根据请求加载更多附近的好友。
| QPS计算 |
|---|
| - 1亿DAU - 并发用户数:10% × 1亿 = 1000万 - 用户每30秒报告一次位置 - 位置更新OPS = 1000万 / 30 = ~334,000 |
在其他章节中,我们通常在高层设计之前讨论API设计和数据模型。然而,对于这个问题,客户端和服务器之间的通信协议可能不是一个简单的HTTP协议,因为我们需要将位置数据推送给所有好友。在不了解高层设计的情况下,很难知道API是什么样的。因此,我们先讨论高层设计。
高层设计
从高层次来看,这个问题需要一个高效的消息传递设计。从概念上讲,用户希望收到每个在附近的活跃好友的位置更新。理论上,这可以完全采用点对点的方式,即用户可以与附近的每个活跃好友保持持久连接(图2.2)。
图2.2: 点对点
对于连接可能不稳定且电量预算有限的移动设备来说,这种解决方案并不实用,但这个想法为总体设计方向提供了一些启发。 一个更实用的设计是有一个共享的后端,如图2.3所示:
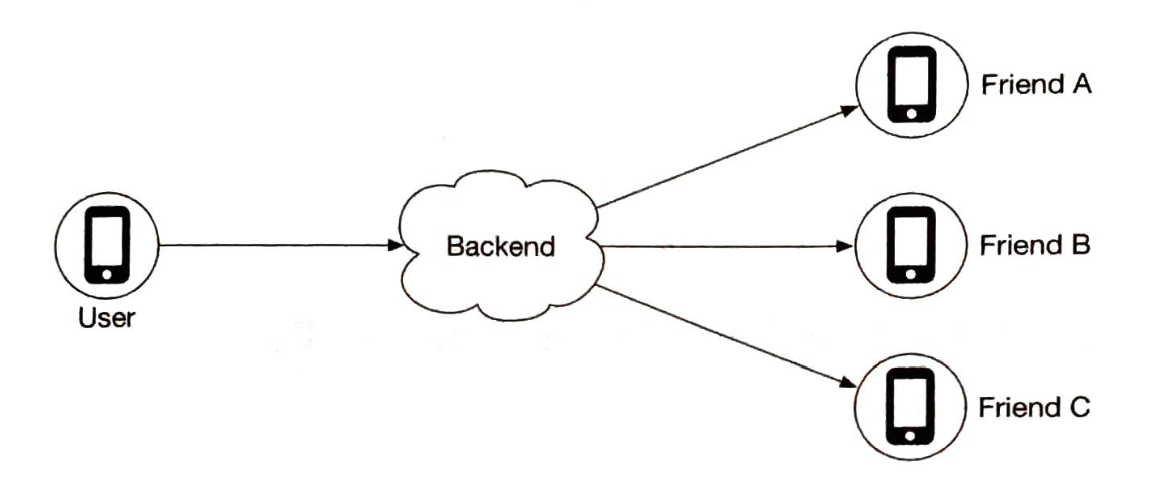
图2.3: 共享后端
图2.3中后端的职责是什么?
- 接收所有活跃用户的位置更新。
- 对于每个位置更新,找到应该接收它的所有活跃好友,并将其转发到这些用户的设备。
- 如果两个用户之间的距离超过某个阈值,则不将其转发给接收者的设备。
这听起来很简单。问题是什么?好吧,要大规模实现这一点并不容易。我们有1000万活跃用户。每个用户每30秒更新一次位置信息,每秒有334K次更新。如果平均每个用户有400个好友,并且我们进一步假设大约10%的好友在线且在附近,那么后端每秒需要转发334K × 400 × 10% = 1400万次位置更新。这是大量需要转发的更新。
建议的设计
我们首先为较小规模的后端提出一个高层设计。之后在深入探讨部分,我们将优化设计以实现扩展。 图2.4显示了应该满足功能需求的基本设计。让我们逐一介绍设计中的每个组件。
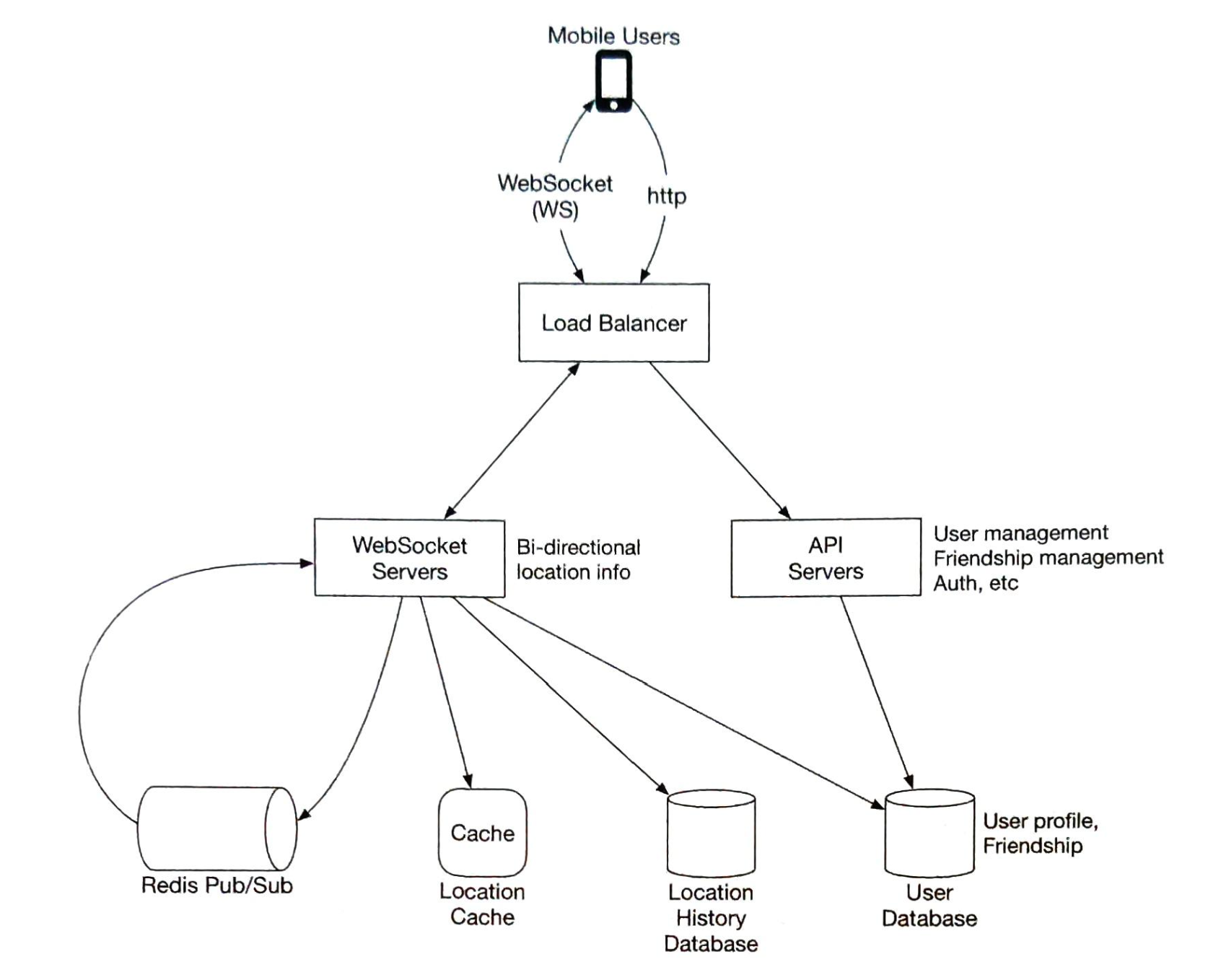
图2.4: 高层设计
负载均衡器
负载均衡器位于RESTful API服务器和有状态的双向WebSocket服务器前面。它将流量分配到这些服务器上以均匀分散负载。
RESTful API服务器
这是一个无状态HTTP服务器集群,处理典型的请求/响应流量。API请求流程如图2.5所示。这个API层处理添加/删除好友、更新用户资料等辅助任务。这些都很常见,我们不会详细讨论。
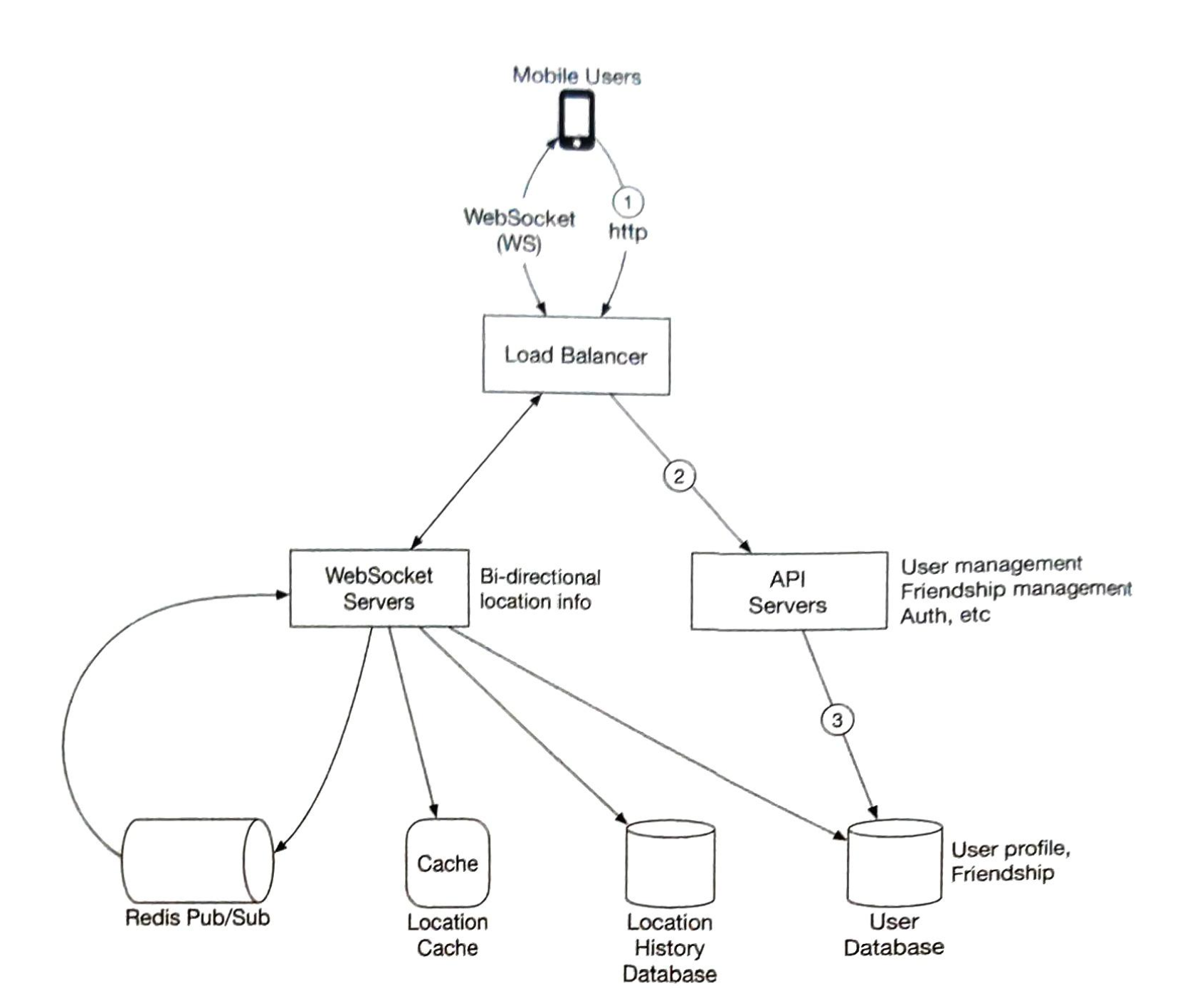
图2.5: RESTful API请求流程
WebSocket服务器
这是一个有状态服务器集群,处理好友位置的近实时更新。每个客户端与这些服务器中的一个维护一个持久的WebSocket连接。当有一个位置更新来自搜索半径内的好友时,更新会通过这个连接发送给客户端。
WebSocket服务器的另一个主要职责是处理"附近的好友"功能的客户端初始化。它为移动客户端提供所有在线的附近好友的位置信息。我们稍后会详细讨论这是如何完成的。 注意:本章中"WebSocket连接"和"WebSocket连接处理程序"是可以互换的。
Redis位置缓存
Redis用于存储每个活跃用户的最新位置数据。缓存中的每个条目都设置了生存时间(TTL,Time To Live)。当TTL过期时,用户不再活跃,位置数据会从缓存中清除。每次更新都会刷新TTL。其他支持TTL的KV存储也可以使用。
用户数据库
用户数据库存储用户数据和用户好友关系数据。可以使用关系数据库或NoSQL数据库。
位置历史数据库
该数据库存储用户的历史位置数据。它与"附近的好友"功能没有直接关系。
Redis Pub/Sub服务器
Redis Pub/Sub[2]是一个非常轻量级的消息总线。Redis Pub/Sub中的频道创建成本很低。一个具有GB内存的现代Redis服务器可以容纳数百万个频道(也称为主题)。图2.6显示了Redis Pub/Sub的工作原理。
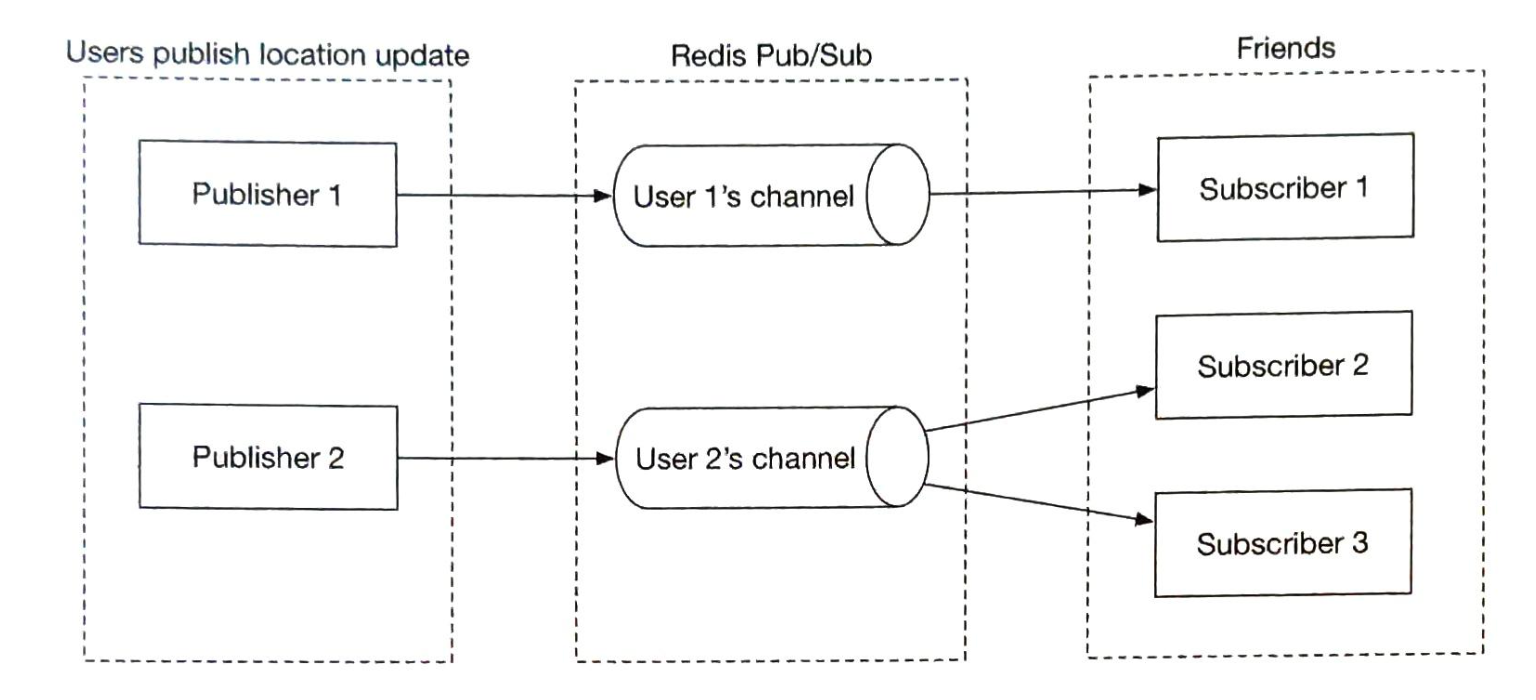
图2.6: Redis Pub/Sub
在这个设计中,通过WebSocket服务器接收的位置更新会发布到Redis Pub/Sub服务器中用户自己的频道。每个活跃好友的专用WebSocket连接处理程序都会订阅该频道。当有位置更新时,WebSocket处理程序函数会被调用,并且对于每个活跃好友,该函数会重新计算距离。如果新距离在搜索半径内,新的位置和时间戳会通过WebSocket连接发送给好友的客户端。其他具有轻量级频道的消息总线也可以使用。
现在我们已经了解了每个组件的功能,让我们从系统的角度来看看当用户的位置发生变化时会发生什么。
周期性位置更新
移动客户端通过持久的WebSocket连接发送周期性的位置更新。流程如图2.7所示。
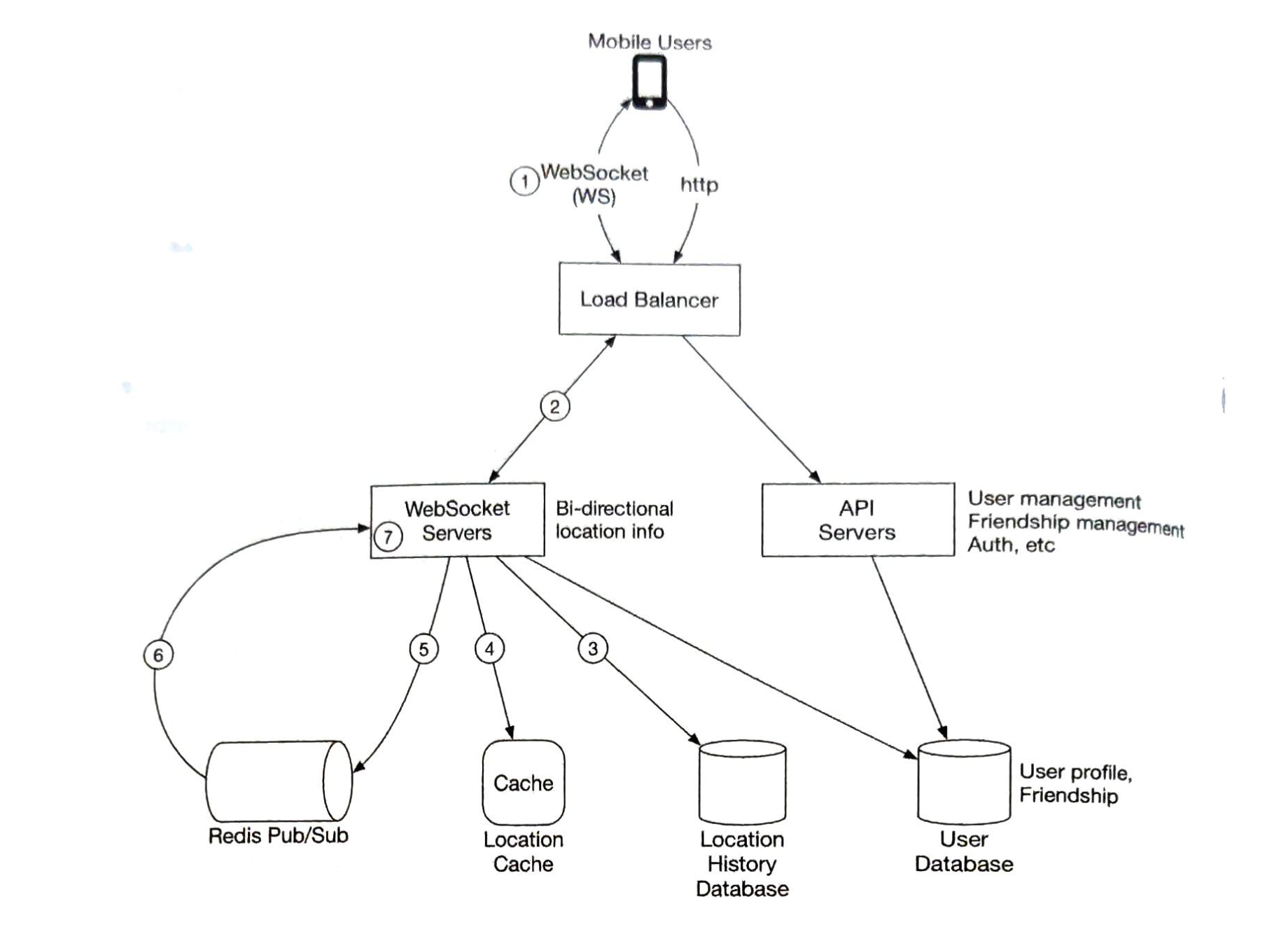
图2.7: 周期性位置更新
- 移动客户端向负载均衡器发送位置更新。
- 负载均衡器将位置更新转发到该客户端在WebSocket服务器上的持久连接。
- WebSocket服务器将位置数据保存到位置历史数据库。
- WebSocket服务器在位置缓存中更新新位置。更新会刷新TTL。WebSocket服务器还将新位置保存在用户的WebSocket连接处理程序的变量中,用于后续的距离计算。
- WebSocket服务器将新位置发布到Redis Pub/Sub服务器中用户的频道。步骤3到5可以并行执行。
- 当Redis Pub/Sub在某个频道收到位置更新时,它会将更新广播给所有订阅者(WebSocket连接处理程序)。在这种情况下,订阅者是发送更新的用户的所有在线好友。对于每个订阅者(即用户的每个好友),其WebSocket连接处理程序都会收到用户位置更新。
- 在收到消息时,WebSocket服务器(连接处理程序所在的服务器)计算发送新位置的用户(位置数据在消息中)与订阅者(位置数据存储在订阅者的WebSocket连接处理程序的变量中)之间的距离。
- 这一步没有在图中画出。如果距离没有超过搜索半径,新的位置和最后更新时间戳会通过WebSocket连接发送给订阅者的客户端。否则,更新会被丢弃。
由于理解这个流程非常重要,让我们用一个具体的例子再次检查它,如图2.8所示。在开始之前,让我们做一些假设。
- 用户1的好友:用户2、用户3和用户4
- 用户5的好友:用户4和用户6
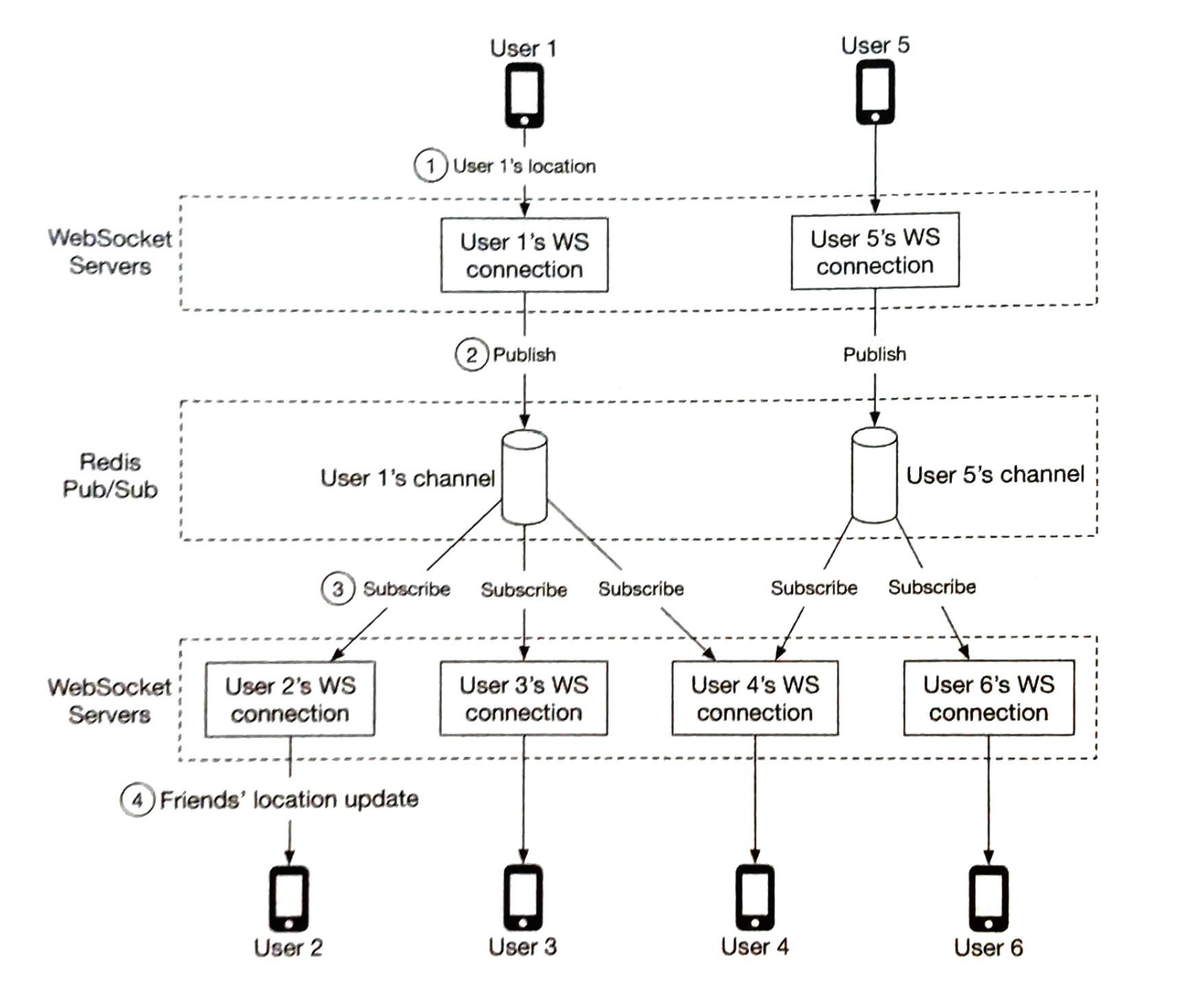
图2.8: 向好友发送位置更新
- 当用户1的位置发生变化时,他们的位置更新被发送到持有用户1连接的WebSocket服务器。
- 位置被发布到Redis Pub/Sub服务器中用户1的频道。
- Redis Pub/Sub服务器将位置更新广播给所有订阅者。在这种情况下,订阅者是WebSocket连接处理程序(用户1的好友)。
- 如果发送位置的用户(用户1)与订阅者(用户2)之间的距离没有超过搜索半径,新位置会被发送到客户端(用户2)。
这个计算对频道的每个订阅者都会重复进行。由于平均每个用户有10个好友,并且我们假设10%的好友在线且在附近,因此每个用户的位置更新大约需要转发40次位置更新。
API设计
现在我们已经创建了一个高层设计,让我们列出需要的API。
WebSocket:用户通过WebSocket协议发送和接收位置更新。至少需要以下API。
-
周期性位置更新 请求:客户端发送纬度、经度和时间戳 响应:无
-
客户端接收位置更新 发送的数据:好友位置数据和时间戳
-
WebSocket初始化 请求:客户端发送纬度、经度和时间戳 响应:客户端接收好友位置数据
-
订阅新好友 请求:WebSocket服务器发送好友ID 响应:好友的最新纬度、经度和时间戳
-
取消订阅好友 请求:WebSocket服务器发送好友ID 响应:无
HTTP请求:API服务器处理添加/删除好友、更新用户资料等任务。这些都很常见,我们不会在这里详细讨论。
数据模型
另一个需要讨论的重要元素是数据模型。我们已经在高层设计中讨论了用户数据库,所以让我们专注于位置缓存和位置历史数据库。
位置缓存
位置缓存存储所有已启用附近好友功能的活跃用户的最新位置。我们使用Redis作为这个缓存。缓存的键/值如表2.1所示。
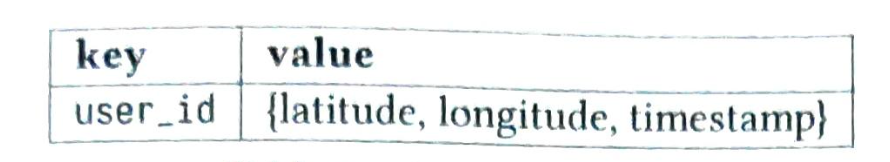 表2.1:位置缓存
表2.1:位置缓存
为什么不使用数据库来存储位置数据? "附近的好友"功能只关心用户的当前位置。因此,我们只需要存储每个用户的一个位置。Redis是一个很好的选择,因为它提供超快的读写操作。它支持TTL,我们用它来自动清除不再活跃的用户。当前位置不需要持久存储。如果Redis实例宕机,我们可以用一个空的新实例替换它,让缓存随着新的位置更新流入而填充。活跃用户可能会在缓存预热时错过一两个更新周期的好友位置更新。这是一个可以接受的权衡。在深入探讨部分,我们将讨论当缓存被替换时如何减少对用户的影响。
位置历史数据库
位置历史数据库存储用户的历史位置数据,模式如下:
| user_id | latitude | longitude | timestamp |
|---|
我们需要一个能够很好地处理大量写入工作负载并且可以水平扩展的数据库。Cassandra是一个很好的候选。我们也可以使用关系数据库。然而,使用关系数据库时,历史数据将无法适应单个实例,所以我们需要对数据进行分片。最基本的方法是按用户ID分片。这种分片方案确保负载在所有分片之间均匀分布,并且在操作上很容易维护。
第3步 - 深入设计
我们在上一节创建的高层设计在大多数情况下都能工作,但在我们的规模下可能会出现问题。在本节中,我们将一起发现随着规模增加而出现的瓶颈,并在此过程中研究消除这些瓶颈的解决方案。
每个组件的扩展性如何?
API服务器
扩展RESTful API层的方法是众所周知的。这些是无状态服务器,有很多方法可以根据CPU使用率、负载或I/O自动扩展集群。我们不会在这里详细讨论。
WebSocket服务器
对于WebSocket集群,根据使用情况自动扩展并不难。然而,WebSocket服务器是有状态的,所以在移除现有节点时需要小心。在可以移除节点之前,应该允许所有现有连接耗尽。为了实现这一点,我们可以在负载均衡器上将节点标记为"正在耗尽",这样就不会有新的WebSocket连接路由到正在耗尽的服务器。一旦所有现有连接都关闭(或经过合理的长时间等待),就可以移除服务器。 在WebSocket服务器上发布应用软件的新版本需要同样的谨慎。 值得注意的是,有状态服务器的有效自动扩展是一个好的负载均衡器的工作。大多数云负载均衡器都能很好地处理这项工作。
客户端初始化
移动客户端在启动时与其中一个WebSocket服务器实例建立持久的WebSocket连接。每个连接都是长期运行的。大多数现代语言都能够以合理的小内存占用维护许多长期运行的连接。
当WebSocket连接初始化时,客户端发送用户的初始位置,服务器在WebSocket连接处理程序中执行以下任务:
- 更新位置缓存中用户的位置。
- 将位置保存在连接处理程序的变量中,用于后续计算。
- 从用户数据库加载所有用户的好友。
- 向位置缓存发出批量请求,获取所有好友的位置。注意,因为我们在位置缓存中的每个条目上设置了与不活跃超时期间匹配的TTL,如果一个好友不活跃,他们的位置将不会在位置缓存中。
- 对于缓存返回的每个位置,服务器计算用户与该位置的好友之间的距离。如果距离在搜索半径内,好友的资料、位置和最后更新时间戳通过WebSocket连接返回给客户端。
- 对于每个好友,服务器订阅Redis Pub/Sub服务器中好友的频道。我们稍后会解释我们对Redis Pub/Sub的使用。由于创建新频道的成本很低,用户订阅所有活跃和不活跃好友的频道。不活跃的好友会在Redis Pub/Sub服务器上占用少量内存,但在他们上线之前不会消耗任何CPU或I/O(因为他们不发布更新)。
- 将用户的当前位置发送到Redis Pub/Sub服务器中用户的频道。
用户数据库
用户数据库包含两个不同的数据集:用户资料(用户ID、用户名、资料URL等)和好友关系。这些数据集在我们的设计规模下可能无法适应单个关系数据库实例。好消息是,数据可以通过基于用户ID的分片实现水平扩展。关系数据库分片是一种非常常见的技术。 作为旁注,在我们设计的规模下,用户和好友关系数据集很可能由专门的团队管理,并通过内部API提供。在这种情况下,WebSocket服务器将使用内部API而不是直接查询数据库来获取用户和好友相关的数据。无论是通过API访问还是直接数据库查询,在功能或性能方面都没有太大区别。
位置缓存
我们选择Redis来缓存所有活跃用户的最新位置。如前所述,我们还在每个键上设置TTL。TTL在每次位置更新时都会更新。这限制了最大内存使用量。在峰值时有1000万活跃用户,每个位置占用不超过100字节,一个具有多GB内存的现代Redis服务器应该能够轻松容纳所有用户的位置信息。
然而,有1000万活跃用户大约每30秒更新一次,Redis服务器将需要处理每秒334K次更新。这个数字可能有点太高,即使对于现代的高端服务器来说也是如此。幸运的是,这个缓存数据很容易分片。每个用户的位置数据是独立的,我们可以通过基于用户ID对位置数据进行分片,将负载均匀地分散到几个Redis服务器上。
为了提高可用性,我们可以将每个分片上的位置数据复制到一个备用节点。如果主节点宕机,可以快速提升备用节点以最小化停机时间。
Redis Pub/Sub服务器
Pub/Sub服务器用作路由层,将消息(位置更新)从一个用户定向到所有在线好友。如前所述,我们选择Redis Pub/Sub是因为创建新频道的成本很低。当有人订阅时就会创建新频道。如果消息发布到没有订阅者的频道,消息会被丢弃,对服务器的负载很小。当创建频道时,Redis使用少量内存来维护一个哈希表和一个链表[3]来跟踪订阅者。如果用户离线时频道没有更新,在创建频道后不会使用CPU周期。我们在设计中以以下方式利用这些特性:
- 我们为每个使用"附近的好友"功能的用户分配一个唯一的频道。用户在应用初始化时会订阅每个好友的频道,无论好友是否在线。这简化了设计,因为后端不需要处理在好友变为活跃时订阅好友的频道,或在好友变为不活跃时处理取消订阅。
- 这种权衡是设计会使用更多内存。正如我们稍后会看到的,内存使用不太可能成为瓶颈。在这种情况下,用更高的内存使用换取更简单的架构是值得的。
我们需要多少Redis Pub/Sub服务器?让我们计算一下内存和CPU使用情况。
内存使用 假设为每个使用附近好友功能的用户分配一个频道,我们需要1亿个频道(10亿 × 10%)。假设平均每个用户有10个活跃好友使用这个功能(这包括附近或不附近的好友),并且在内部哈希表和链表中跟踪每个订阅者需要约20字节的指针,那么需要约200GB(1亿 × 20字节 × 10个好友 / 10^9 = 20GB)来保存所有频道。对于一个具有100GB内存的现代服务器,我们需要约2个Redis Pub/Sub服务器来保存所有频道。
CPU使用 如前所计算,Pub/Sub服务器每秒向订阅者推送约1400万次更新。虽然没有实际基准测试很难准确估计现代Redis服务器每秒可以推送多少消息,但可以安全地假设单个Redis服务器无法处理这种负载。让我们选择一个保守的数字,假设具有千兆网络的现代服务器每秒可以处理约100,000次订阅者推送。考虑到我们的位置更新消息很小,这个数字可能过于保守。使用这个保守估计,我们需要将负载分配到1400万 / 100,000 = 140个Redis服务器上。同样,这个数字可能过于保守,实际需要的服务器数量可能要少得多。
从计算中,我们得出结论:
- Redis Pub/Sub服务器的瓶颈是CPU使用率,而不是内存使用率
- 为了支持我们的规模,我们需要一个分布式Redis Pub/Sub集群
分布式Redis Pub/Sub服务器集群
我们如何将频道分配到数百个Redis服务器上?好消息是频道之间是独立的。这使得基于发布者的用户ID进行分片来将频道分散到多个Pub/Sub服务器变得相对容易。但从实际操作的角度来看,有数百个Pub/Sub服务器,我们应该更详细地讨论如何做到这一点,因为服务器不可避免地会时不时地宕机。
在这里,我们引入一个服务发现组件到我们的设计中。有许多可用的服务发现包,其中etcd[4]和ZooKeeper[5]是最受欢迎的。我们对服务发现组件的需求很基本。我们需要这两个功能:
- 能够在服务发现组件中保存服务器列表,并提供简单的UI或API来更新它。从根本上说,服务发现是一个用于保存配置数据的小型键值存储。使用图2.9作为例子,哈希环的键和值可能如下所示:
Key: /config/pub_sub_ring
Value: ["p_1", "p_2", "p_3", "p_4"]
- 客户端(在这种情况下是WebSocket服务器)能够订阅"Value"(Redis Pub/Sub服务器)的任何更新。
在第1点提到的"Key"下,我们在服务发现组件中存储所有活跃Redis Pub/Sub服务器的哈希环(关于哈希环的详细信息,请参见《系统设计面试》第1卷中的一致性哈希章节或[6])。Redis Pub/Sub服务器的发布者和订阅者使用哈希环来确定每个频道要与哪个Pub/Sub服务器通信。例如,在图2.9中,频道2位于Redis Pub/Sub服务器1中。
 图2.9:一致性哈希
图2.9:一致性哈希
图2.10显示了当WebSocket服务器向用户的频道发布位置更新时会发生什么。
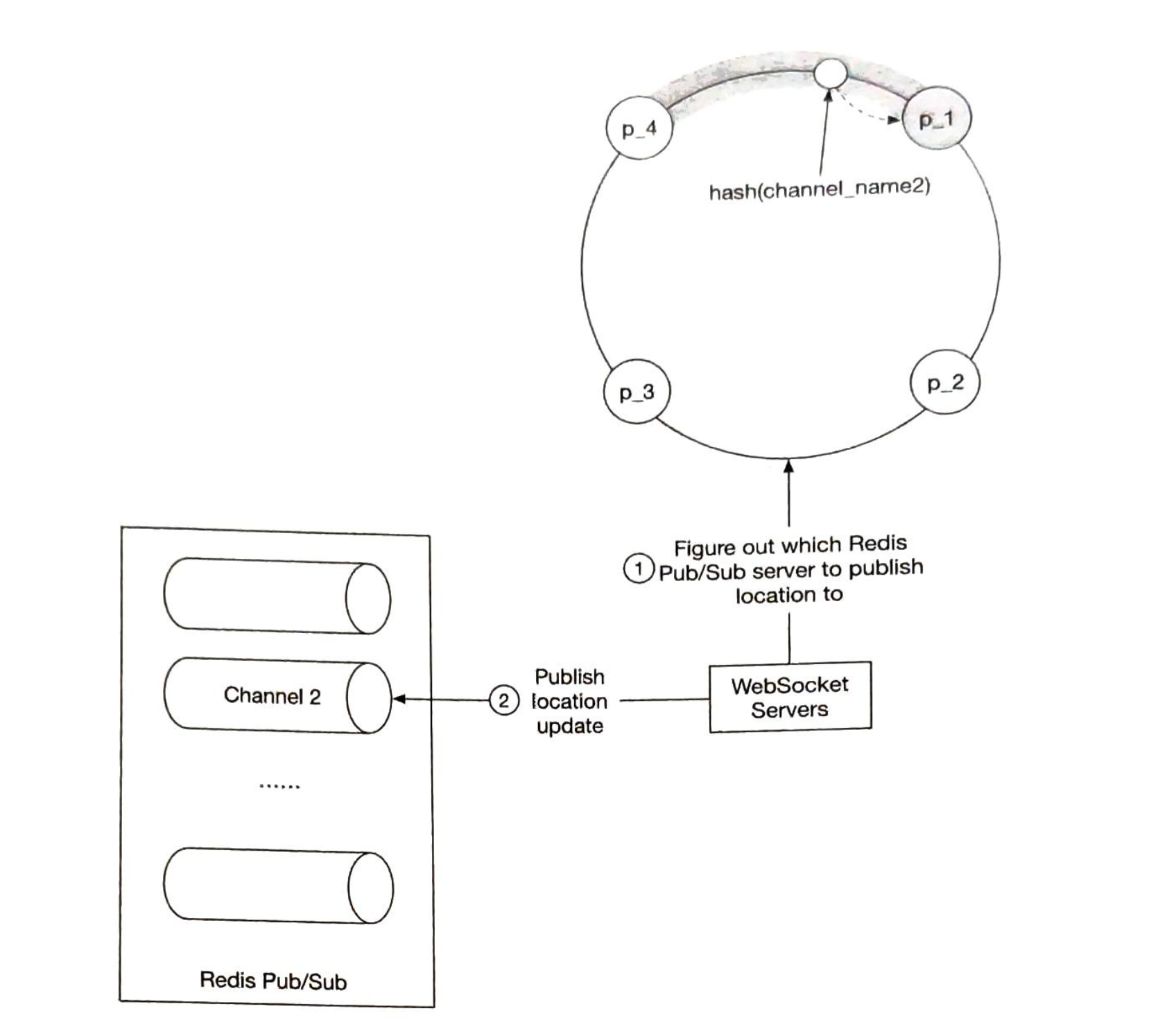 图2.10:确定正确的Redis Pub/Sub服务器
图2.10:确定正确的Redis Pub/Sub服务器
- WebSocket服务器查询哈希环以确定要写入的Redis Pub/Sub服务器。真实数据存储在服务发现中,但为了效率,每个WebSocket服务器可以缓存哈希环的副本。WebSocket服务器订阅哈希环的任何更新以保持其本地内存副本最新。
- WebSocket服务器将位置更新发布到该Redis Pub/Sub服务器上的用户频道。
订阅频道以获取位置更新使用相同的机制。
Redis Pub/Sub服务器的扩展考虑
我们应该如何扩展Redis Pub/Sub服务器集群?我们是否应该根据流量模式每天进行扩缩容?这对无状态服务器来说是一种很常见的做法,因为风险低且可以节省成本。要回答这些问题,让我们检查Redis Pub/Sub服务器集群的一些特性。
-
Pub/Sub频道上发送的消息不会在内存或磁盘中持久化。它们被发送给频道的所有订阅者后立即删除。如果没有订阅者,消息就会被丢弃。从这个意义上说,通过Pub/Sub频道的数据是无状态的。
-
然而,Pub/Sub服务器确实存储了频道的状态。具体来说,每个频道的订阅者列表是Pub/Sub服务器跟踪的关键状态。如果一个频道被移动(当频道的Pub/Sub服务器被替换时可能发生这种情况,或者当在哈希环上添加新服务器或删除旧服务器时),那么被移动频道的每个订阅者都必须知道这一点,这样他们就可以从旧服务器取消订阅该频道,并在新服务器上重新订阅替换频道。从这个意义上说,Pub/Sub服务器是有状态的,必须协调与服务器所有订阅者的操作以最小化服务中断。
出于这些原因,我们应该将Redis Pub/Sub集群更多地视为有状态集群,类似于我们处理存储集群的方式。对于有状态集群,扩缩容有一些运营开销和风险,所以应该谨慎规划。通常会对集群进行过度配置,以确保它能够处理日常峰值流量,并留有一些舒适的余地,以避免不必要的集群调整。
当我们不可避免地需要扩展时,要注意这些潜在问题:
- 当我们调整集群大小时,哈希环上的许多频道将被移动到不同的服务器。当服务发现组件通知所有WebSocket服务器哈希环更新时,将会产生大量的重新订阅请求。
- 在这些大规模重新订阅事件期间,客户端可能会错过一些位置更新。虽然对我们的设计来说偶尔的丢失是可以接受的,但我们应该尽量减少这种情况的发生。
- 由于可能的中断,应该在一天中使用量最低的时候进行调整。
实际上如何进行调整?这很简单。按照以下步骤:
- 确定新的环大小,如果是扩容,则配置足够的新服务器
- 用新内容更新哈希环的键
- 监控你的仪表板。WebSocket集群的CPU使用率应该会出现一些峰值
使用上面图2.9中的哈希环,如果我们要添加2个新节点,比如说p_5和p_6,哈希环将这样更新:
旧:["p_1", "p_2", "p_3", "p_4"]
新:["p_1", "p_2", "p_3", "p_4", "p_5", "p_6"]
Redis Pub/Sub服务器的运维考虑
替换现有Redis Pub/Sub服务器的运营风险要低得多。它不会导致大量频道被移动。只需要处理被替换服务器上的频道。这很好,因为服务器不可避免地会宕机并需要定期替换。
当Pub/Sub服务器发生宕机时,监控软件应当及时通知值班运维人员。本章不涉及监控软件如何监控Pub/Sub服务器的健康状况的具体细节。值班运维人员在服务发现中更新哈希环键,用新的备用节点替换死掉的节点。WebSocket服务器会收到更新通知,每个服务器然后通知其连接处理程序在新的Pub/Sub服务器上重新订阅频道。每个WebSocket处理程序保存它已订阅的所有频道的列表,在收到服务器的通知后,它会检查每个频道与哈希环的对应关系,以确定是否需要在新服务器上重新订阅频道。
使用上面图2.9中的哈希环,如果p_1宕机,我们用p1_new替换它,哈希环将这样更新:
旧:["p_1", "p_2", "p_3", "p_4"]
新:["p1_new", "p_2", "p_3", "p_4"]
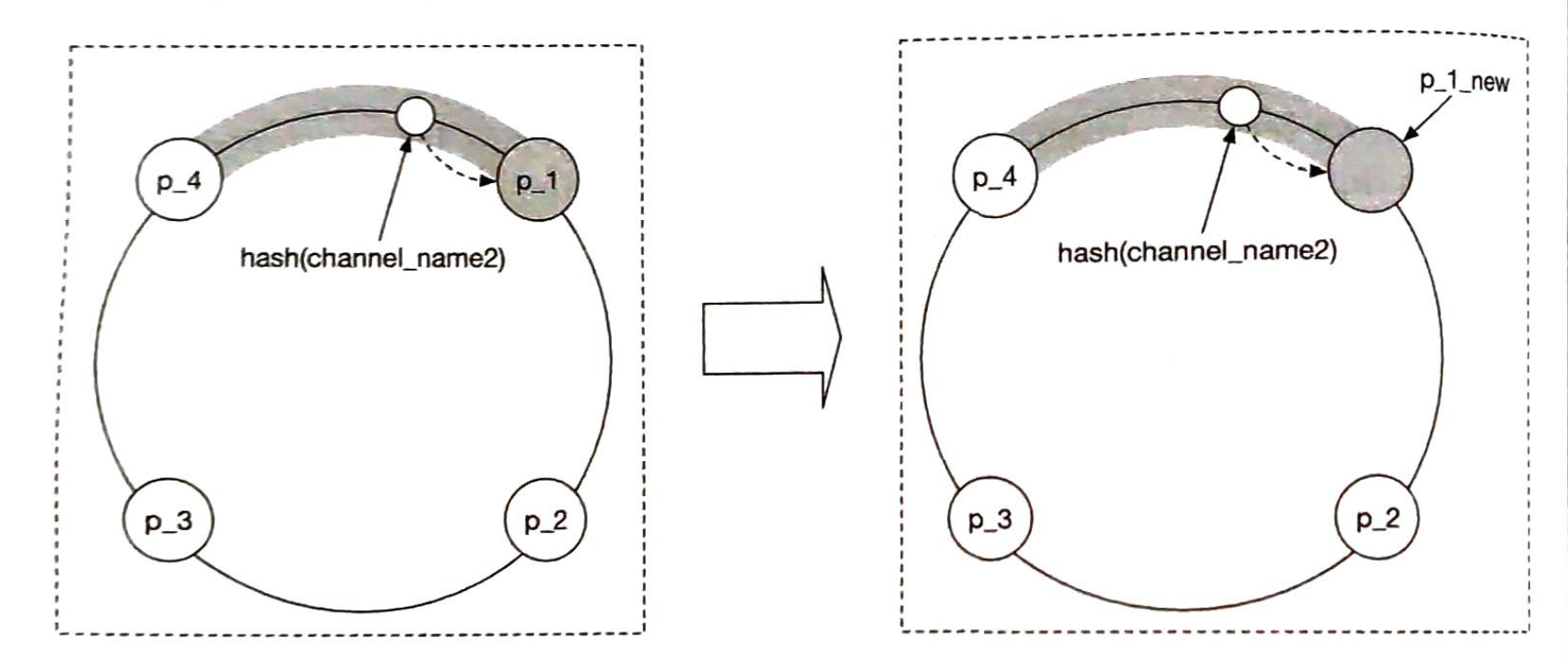 图2.11:替换Pub/Sub服务器
图2.11:替换Pub/Sub服务器
添加/删除好友
当用户添加或删除好友时客户端应该做什么?当添加新好友时,需要通知客户端的WebSocket连接处理程序,这样它就可以订阅新好友的Pub/Sub频道。
由于"附近的好友"功能是更大应用生态系统的一部分,我们可以假设"附近的好友"功能可以在移动客户端上注册一个回调,在添加新好友时触发。回调被调用时,会向WebSocket服务器发送消息以订阅新好友的Pub/Sub频道。如果新好友处于活跃状态,WebSocket服务器还会返回一条包含新好友最新位置和时间戳的消息。
同样,当删除好友时,客户端可以在应用程序中注册一个回调。回调会向WebSocket服务器发送消息以取消订阅该好友的Pub/Sub频道。
这个订阅/取消订阅回调也可以在好友选择加入或退出位置更新时使用。
拥有很多好友的用户
值得讨论的是,拥有很多好友的用户是否会在我们的设计中造成性能热点。我们在这里假设好友数量有硬性上限。(例如,Facebook有5000个好友的上限)。好友关系是双向的,这与粉丝模式不同 - 在粉丝模式中,名人可能拥有数百万的粉丝。
在有数千个好友的场景中,Pub/Sub订阅者会分散在集群中的许多WebSocket服务器上。更新负载会分散在它们之间,不太可能造成任何热点。
用户会在其频道所在的Pub/Sub服务器上产生稍多的负载。由于有超过100个Pub/Sub服务器,这些"大户"用户会分散在Pub/Sub服务器之间,增加的负载不应该使任何单个服务器过载。
附近的随机人
你可以把这一节称为额外加分,因为它不在最初的功能需求中。如果面试官想要更新设计以显示选择共享位置的随机人怎么办?
一种利用我们设计的方法是按地理哈希添加一个Pub/Sub频道池。(有关地理哈希的详细信息,请参见第1章"邻近服务")。如图2.12所示,一个区域被分为四个地理哈希网格,为每个网格创建一个频道。
 图2.12:Redis Pub/Sub频道
图2.12:Redis Pub/Sub频道
网格内的任何人都订阅相同的频道。让我们以图2.13中的网格9q8znd为例。
 图2.13:向附近的随机人发布位置更新
图2.13:向附近的随机人发布位置更新
- 这里,当用户2更新他们的位置时,WebSocket连接处理程序计算用户的地理哈希ID,并将位置发送到该地理哈希的频道。
- 附近订阅该频道的任何人(不包括发送者)都会收到位置更新消息。
为了处理靠近地理哈希网格边界的人,每个客户端可以订阅用户所在的地理哈希和周围八个地理哈希网格。图2.14显示了所有9个高亮显示的地理哈希网格的示例。
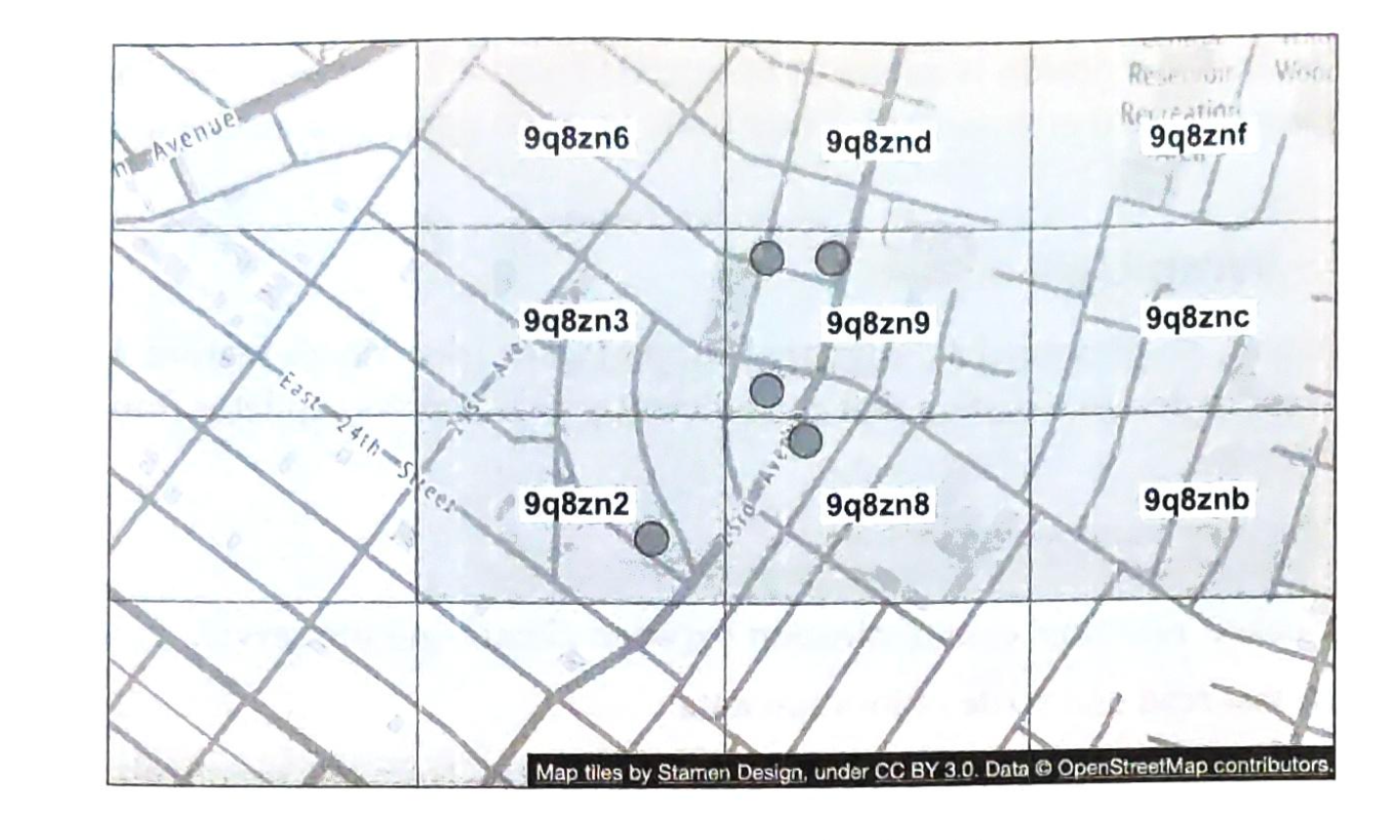 图2.14:九个地理哈希网格
图2.14:九个地理哈希网格
Redis Pub/Sub的替代方案
作为路由层,是否有Redis Pub/Sub的好替代方案?答案是肯定的。Erlang[7]对这个特定问题来说是一个很好的解决方案。我们认为Erlang是比上面提出的Redis Pub/Sub更好的解决方案。然而,Erlang相当小众,招聘优秀的Erlang程序员很难。但如果你的团队有Erlang专业知识,这是一个很好的选择。
那么,为什么选择Erlang?Erlang是一种通用编程语言和运行时环境,专为高度分布式和并发应用程序而构建。当我们在这里说Erlang时,我们特指Erlang生态系统本身。这包括语言组件(Erlang或Elixir[8])和运行时环境及库(称为BEAM[9]的Erlang虚拟机和称为OTP[10]的Erlang运行时库)。
Erlang的强大之处在于其轻量级进程。Erlang进程是在BEAM VM上运行的实体。它比Linux进程要便宜几个数量级。一个最小的Erlang进程占用约300字节,我们可以在单个现代服务器上运行数百万个这样的进程。如果Erlang进程中没有工作要做,它就只是坐在那里,根本不使用任何CPU周期。换句话说,在我们的设计中将1000万活跃用户中的每一个都建模为单个Erlang进程是非常便宜的。
Erlang也很容易在多个Erlang服务器之间分布。运营开销很低,有很好的工具支持安全地调试实时生产问题。部署工具也很强大。
我们如何在设计中使用Erlang?我们会用Erlang实现WebSocket服务,并用分布式Erlang应用程序替换整个Redis Pub/Sub集群。在这个应用程序中,每个用户都被建模为一个Erlang进程。当客户端更新用户的位置时,用户进程会从WebSocket服务器接收更新。用户进程还订阅用户好友的Erlang进程的更新。订阅在Erlang/OTP中是原生的,很容易构建。这形成了一个连接网络,可以高效地将位置更新从一个用户路由到多个好友。
第4步 - 总结
在本章中,我们提出了一个支持附近好友功能的设计。从概念上讲,我们想要设计一个系统,可以高效地将位置更新从一个用户传递给他们的好友。
一些核心组件包括:
- WebSocket:客户端和服务器之间的实时通信
- Redis:位置数据的快速读写
- Redis Pub/Sub:路由层,将位置更新从一个用户定向到所有在线好友
我们首先在较低规模下提出了一个高层设计,然后讨论了随着规模增加而出现的挑战。我们探讨了如何扩展以下内容:
- RESTful API服务器
- WebSocket服务器
- 数据层
- Redis Pub/Sub服务器
- Redis Pub/Sub的替代方案
最后,我们讨论了当用户有很多好友时的潜在瓶颈,并为"附近的随机人"功能提出了一个设计。
恭喜你走到这一步!现在给自己一个鼓励。干得好!
参考资料
[1] Facebook推出"附近的好友"。https://techcrunch.com/2014/04/17/facebook-nearby-friends/
[2] Redis Pub/Sub。https://redis.io/topics/pubsub
[3] Redis Pub/Sub内部原理。https://making.pusher.com/redis-pubsub-under-the-hood/
[4] etcd。https://etcd.io/
[5] ZooKeeper。https://zookeeper.apache.org/
[6] 一致性哈希。https://www.toptal.com/big-data/consistent-hashing
[7] Erlang。https://www.erlang.org/
[8] Elixir。https://elixir-lang.org/
[9] BEAM简介。https://www.erlang.org/blog/a-brief-beam-primer/
[10] OTP。https://www.erlang.org/doc/design_principles/des_princ.html
3 谷歌地图
在本章中,我们设计一个简化版的谷歌地图。在我们进行系统设计之前,让我们先了解一下谷歌地图。谷歌于 2005 年启动了谷歌地图项目,并开发了一个 Web 地图服务。它提供了许多服务,例如卫星图像、街道地图、实时交通状况和路线规划 [1]。
谷歌地图帮助用户找到方向并导航到他们的目的地。截至 2021 年 3 月,谷歌地图拥有 10 亿日活跃用户,覆盖全球 99% 的区域,以及 2500 万次关于准确和实时位置信息的每日更新 [2]。鉴于谷歌地图的巨大复杂性,重要的是确定我们版本支持的功能。
步骤 1 - 理解问题并确定设计范围
面试官和候选人之间的互动可能如下所示:
候选人: 我们期望有多少日活跃用户?
面试官: 10 亿 DAU。
候选人: 我们应该关注哪些功能?方向、导航和预计到达时间 (ETA)?
面试官: 我很高兴你问了这个问题并考虑了这些。我们不需要设计所有这些。
候选人: 我们的系统是否需要考虑交通状况?
面试官: 是的,交通状况对于准确的 ETA 估算非常重要。
候选人: 关于不同的出行方式,如驾车、步行、公交等怎么样?
面试官: 我们应该能够支持不同的出行方式。
候选人: 我们应该支持多站点路线吗?
面试官: 允许用户定义多个站点是好的,但让我们暂时不关注它。
候选人: 关于商家地点和照片怎么样?我们期望有多少照片?
面试官: 我很高兴你问了这个问题并考虑了这些。我们不需要设计这些。
在本章的其余部分,我们专注于三个关键特性。我们需要支持的主要设备是移动电话。
- 用户位置更新。
- 导航服务,包括 ETA 服务。
- 地图渲染。
非功能需求和约束
- 准确性: 不应给用户错误的指示。
- 流畅导航: 在客户端,用户应该体验到非常流畅的地图渲染。
- 数据和电池使用: 客户端应尽可能少地使用数据和电池。这对于移动设备非常重要。
- 通用可用性和可扩展性要求。
在深入探讨设计之前,我们将简要介绍一些基本概念和术语,这些术语在设计谷歌地图时很有用。
地图 101
定位系统
世界是一个绕其轴线旋转的球体。最顶部是北极,最底部是南极。
[图 3.1:纬度和经度(来源:[3])]
- 纬度 (Latitude): 表示我们有多靠北或靠南
- 经度 (Longitude): 表示我们有多靠东或靠西
从 3D 到 2D
将点从 3D 球体转换到 2D 平面的过程称为"地图投影"。 有不同的地图投影方式,每种方式都有其自身的优缺点。几乎所有方式都会扭曲实际的几何形状。下面我们可以看到一些例子。

[图 3.2:地图投影(来源:维基百科 [4] [5] [6] [7])]
- 墨卡托投影 (Mercator projection)
- 皮尔斯梅花投影 (Peirce quincuncial projection)
- 割圆锥投影 (Gall-Peters projection)
- 温克尔投影 (Winkel tripel projection)
谷歌地图选择了墨卡托投影的一种修改版本,称为 Web 墨卡托。有关定位系统和投影的更多详细信息,请参阅 [3]。
地理编码 (Geocoding)
地理编码是将地址转换为地理坐标的过程。例如,"1600 Amphitheatre Parkway, Mountain View, CA"被地理编码为纬度/经度对(纬度 37.423021,经度 -122.083739)。 另一方面,从纬度/经度对到实际人类可读地址的转换称为反向地理编码。
地理编码的一种方法是插值 [8]。此方法利用来自不同来源(例如地理信息系统 (GIS))的数据,其中街道网络被映射到地理坐标空间。
地理哈希 (Geohashing)
地理哈希是一种将地理区域编码为短字符串字母和数字的编码系统。其核心是,它将地球描述为一个扁平化的表面,并递归地将网格划分为子网格,直到每个网格达到某个大小阈值。我们用 0 到 3 的数字串来表示网格,这些数字串是递归创建的。
假设初始平面尺寸为 20,000km x 10,000km。在第一次划分后,我们将得到 4 个尺寸为 10,000km x 5,000km 的网格。我们用 00, 01, 10 和 11 来表示它们,如图 3.3 所示。我们进一步将每个网格划分为 4 个网格,并使用相同的命名策略。每个子网格现在的尺寸是 5,000km x 2,500km。我们递归地划分网格,直到每个网格达到某个大小阈值。

[图 3.3:Geohashing]
级别 0: 01, 11, 00, 10
级别 1: 0101, 0111, ... , 1010
级别 2: 010101, 010111, ... , 101010
...
地图瓦片来自 Stamen Design, 在 CC BY 3.0 许可下。数据来自 OpenStreetMap 贡献者。
Geohashing 有许多用途。在我们的设计中,我们使用 geohashing 进行地图瓦片化。有关 geohashing 及其好处的更多细节,请参阅 [9]。
地图渲染
我们不会详细介绍地图渲染,但值得一提的是基础。地图渲染的一个基本概念是瓦片化。与其一次性渲染整个地图(这对于大图像来说可能是个问题),不如将世界分解成更小的瓦片。客户端只下载用户所在区域的相关瓦片,并将它们像马赛克一样拼接起来进行显示。
有不同的地图缩放级别对应的不同瓦片集。客户端根据地图视口的缩放级别选择适当的瓦片集。这提供了合适的地图细节级别,而不会消耗过多的带宽。为了说明这一点,假设当客户端完全缩小以显示整个世界时,我们不需要下载数千个高缩放级别的瓦片。所有细节都将浪费掉。相反,客户端将下载最低缩放级别的一个瓦片,该瓦片用单个 256 x 256 像素图像表示整个世界。
用于导航算法的道路数据处理
大多数路由算法是 Dijkstra 或 A* 寻路算法的变种。精确算法选择是一个复杂的话题,我们本章不会深入探讨。重要的是要注意,所有这些算法都在图数据结构上运行,其中交叉点是节点,道路是图的边。图 3.4 显示了一个示例:
[图 3.4:地图作为图]
地图瓦片来自 Stamen Design, 在 CC BY 3.0 许可下。数据来自 OpenStreetMap 贡献者。
寻路性能对图的大小极其敏感。将整个世界的道路网络表示为单个图会消耗太多内存,并且对于任何这些算法来说都太大而无法有效运行。我们需要将图分解成可管理的单元以适应我们的设计规模。
一种方法是将世界分解成称为路由瓦片 (routing tiles) 的小网格。我们通过采用 geohashing 等平铺技术来实现这一点。我们将世界划分为小网格。对于每个网格,我们提取网格内的道路(交叉点)和网格内的地理区域所覆盖的边(道路)组成的图数据结构。我们将这些称为路由瓦片。每个路由瓦片都持有对其连接的所有其他瓦片的引用。这样,路由算法可以将它们拼接在一起,形成一个更大的路由图,代表这些互连的路由瓦片。
通过将道路网络分解成路由瓦片,这些路由瓦片可以按需加载,路由算法可以显著减少内存消耗,并通过仅在需要时加载一小组路由瓦片来提高寻路性能,并且仅在需要时加载额外的瓦片。
[图 3.5:路由瓦片]
路由瓦片 1 | 路由瓦片 2 | 路由瓦片 3
地图瓦片来自 Stamen Design, 在 CC BY 3.0 许可下。数据来自 OpenStreetMap 贡献者。
提醒 在图 3.5 中,我们称这些网格为路由瓦片。路由瓦片类似于地图瓦片,因为两者都是覆盖某些地理区域的网格。地图瓦片是 PNG 图像,而路由瓦片是覆盖瓦片区域的道路数据的二进制文件。
分层路由瓦片 (Hierarchical routing tiles)
高效的导航路由还需要在正确的细节级别上拥有道路数据。例如,对于跨国路由,在最低细节级别运行路由算法会很慢。图被拼接在一起形成这些详细的街道级路由瓦片。它会产生一个可能太大且消耗过多内存的详细路由图。
通常有三组具有不同细节级别的路由瓦片。在最详细的级别,路由瓦片很小,只包含当地道路。在下一个级别,瓦片更大,包含连接区域的主要干道。在最低细节级别,瓦片覆盖大片区域,包含连接城市和州的主要高速公路。在每个级别,瓦片都可以边缘连接以形成在不同缩放级别运行的路由图。例如,对于高速公路入口,从本地街道 A 到高速公路 F,在小瓦片中会有一个从节点(街道 A)到大瓦片中节点(高速公路 F)的引用。参见图 3.6 的不同尺寸路由瓦片示例。
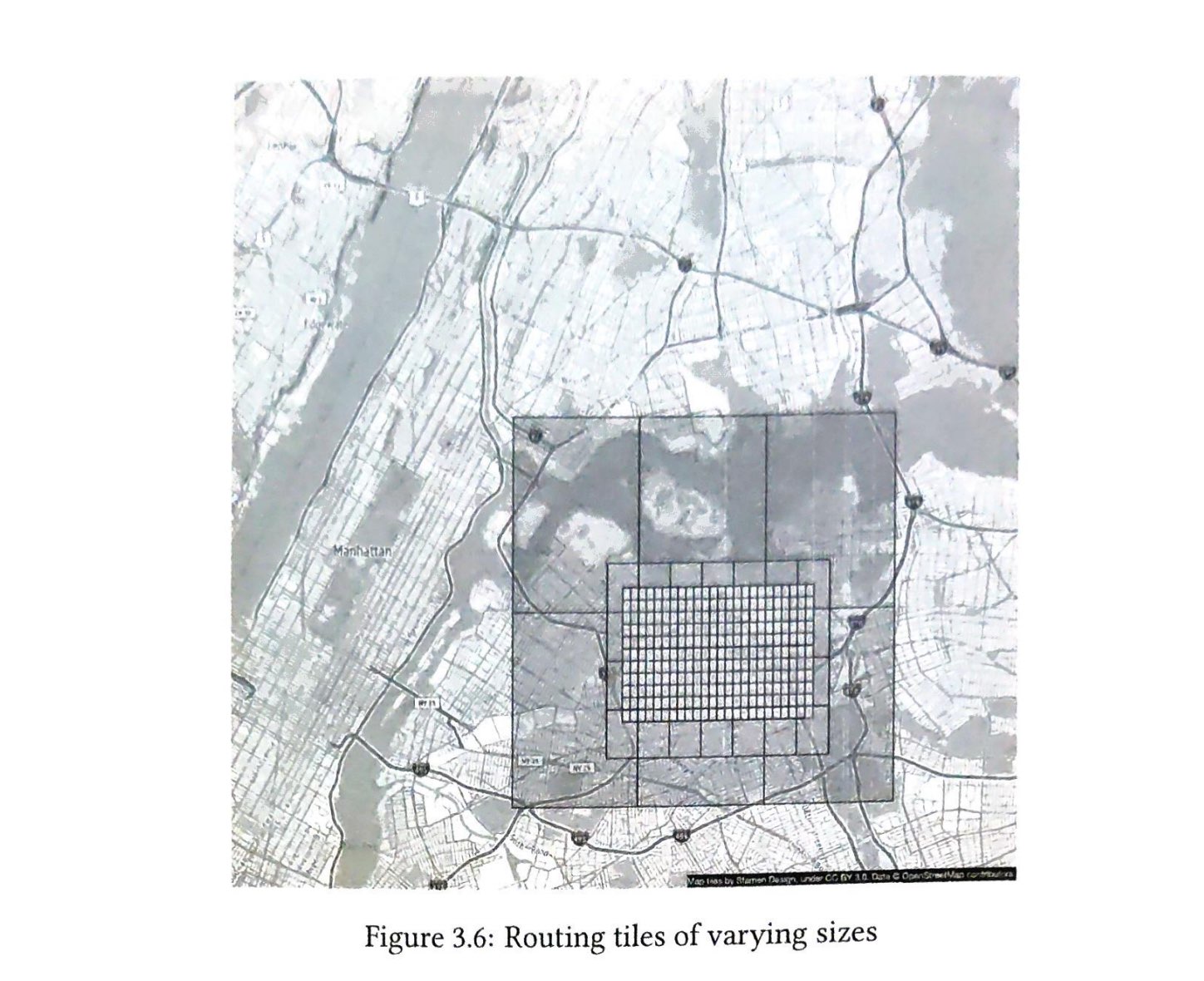
[图 3.6:不同尺寸的路由瓦片]
粗略估算
现在我们理解了基础知识,让我们做一个粗略的估算。由于设计的重点是移动设备,数据使用和电池消耗是两个重要的考虑因素。
在我们深入估算之前,这里有一些英制/公制转换供参考。
- 1 英尺 = 0.3048 米
- 1 公里 (km) = 0.6214 英里
- 1 公里 = 1,000 米
存储使用
我们需要存储三种类型的数据。
- 世界地图: 详细计算如下所示。
- 元数据: 鉴于每个地图瓦片的数据可以忽略不计,我们可以在计算中跳过元数据。
- 道路信息: 面试官告诉我们有 TB 级的原始道路数据来自外部来源。我们将这些数据集转换为路由瓦片,这些瓦片的大小也可能是 TB 级。
世界地图
我们在第 60 页的"地图 101"部分讨论了地图瓦片的概念。有许多地图瓦片集,每个对应一个缩放级别。为了了解整个地图瓦片图像集合所需的存储量,估算最高缩放级别下最大瓦片集的大小会很有信息量。首先,假设有 21 个缩放级别,最高缩放级别是 21。在那里,大约有 4.3 万亿个瓦片(表 3.1)。让我们假设每个瓦片是一个 256 x 256 像素的压缩 PNG 图像,图像大小约为 100KB。最高缩放级别的整个集合将需要大约 4.4 万亿 x 100KB = 440PB。
在表 3.1 中,我们展示了每个缩放级别的瓦片数量的进展。
| 缩放级别 (Zoom) | 瓦片数量 (Number of Tiles) |
|---|---|
| 0 | 1 |
| 1 | 4 |
| 2 | 16 |
| 3 | 64 |
| 4 | 256 |
| 5 | 1 024 |
| 6 | 4 096 |
| 7 | 16 384 |
| 8 | 65 536 |
| 9 | 262 144 |
| 10 | 1 048 576 |
| 11 | 4 194 304 |
| 12 | 16 777 216 |
| 13 | 67 108 864 |
| 14 | 268 435 456 |
| 15 | 1 073 741 824 |
| 16 | 4 294 967 296 |
| 17 | 17 179 869 184 |
| 18 | 68 719 476 736 |
| 19 | 274 877 906 944 |
| 20 | 1 099 511 627 776 |
| 21 | 4 398 046 511 104 |
| 表 3.1:缩放级别 |
然而,请记住,大约 90% 的地球表面是自然的,大部分是无人居住的区域,如海洋、沙漠、湖泊和山脉。由于这些区域作为图像高度可压缩,我们可以保守地将存储估计减少 80 ~ 90%。这将使存储大小减少到 44 到 88PB。我们选择一个中间值 50PB。
接下来,让我们估计每个后续较低缩放级别会占用多少存储空间。在每个较低缩放级别,南北方向和东西方向的瓦片数量都减半。这导致瓦片总数减少 4 倍,这使得缩放级别的存储大小也减少 4 倍。通过每个较低缩放级别,总大小的数学公式为:50 + 50/4 + 50/16 + ... ≈ 67PB。这只是一个粗略的估计。知道我们需要大致 100PB 来存储所有不同缩放级别的地图瓦片就足够了。
服务器吞吐量
为了估算服务器吞吐量,让我们回顾一下我们需要支持的请求类型。主要有两种类型的请求。第一种是导航请求。这些是由客户端发送以启动导航会话的。第二种是位置更新请求。这些是客户端在导航会话期间四处移动时发送的。位置数据被下游服务以多种不同方式使用。例如,位置数据用于实时交通数据。我们将在设计深入探讨部分介绍位置数据的使用案例。
现在我们可以分析导航请求的服务器吞吐量。假设我们有 10 亿 DAU,每个用户平均每周使用导航总共 35 分钟,或者说每周 50 亿分钟。
一种简单的方法是每秒发送 GPS 坐标,这将导致每秒 3000 亿次请求(50 亿分钟 x 60)或每秒 300 万 QPS (3000 亿请求 / 10^5 秒 = 300 万)。然而,客户端可能不需要每秒发送 GPS 更新。我们可以批量处理客户端上的位置更新,并以较低的频率(例如,每 15 秒或 30 秒)发送它们,以减少写入 QPS。实际频率可能取决于用户移动速度等因素。如果他们被困在交通中,客户端可以降低 GPS 更新速度。在我们的设计中,假设 GPS 更新被批量处理,并每 15 秒发送一次。使用此假设,QPS 降低到 200,000 (3 百万 / 15)。
假设峰值 QPS 是平均值的五倍。位置更新的峰值 QPS = 200,000 x 5 = 1 百万。
步骤 2 - 提出高层设计并获得认可
现在我们对谷歌地图有了更多的了解,我们准备提出一个高层设计(图 3.7)。
高层设计
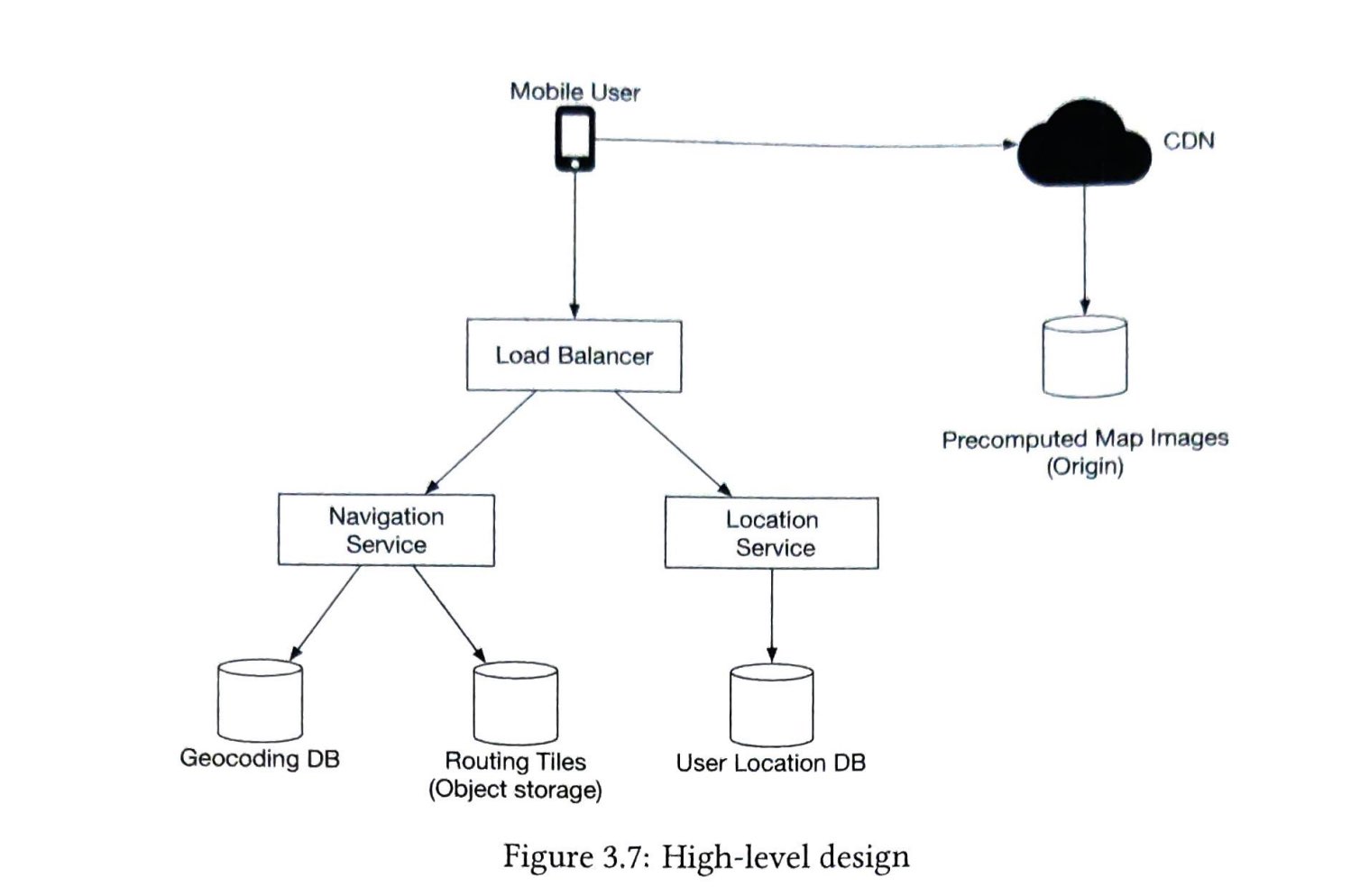
[图 3.7:高层设计]
移动用户 -> CDN (预计算地图图像 (源站))
移动用户 -> 负载均衡器
负载均衡器 -> 导航服务 -> 地理编码数据库 (Geocoding DB)
负载均衡器 -> 导航服务 -> 路由瓦片 (对象存储)
负载均衡器 -> 位置服务 -> 用户位置数据库 (User Location DB)
高层设计支持三个特性。让我们逐一看看。
- 位置服务
- 导航服务
- 地图渲染
位置服务
位置服务负责记录用户的位置更新。架构如图 3.8 所示。
[图 3.8:位置服务]
移动用户 -> 负载均衡器 -> 位置服务 -> 用户位置数据库
基本设计要求客户端每隔 t 秒发送位置更新,其中 t 是一个可配置的间隔。周期性更新有几个好处。首先,我们可以利用位置数据流来随着时间的推移改进我们的系统。我们可以使用这些数据来监控实时交通、检测新的或封闭的道路,以及分析用户行为以实现个性化,例如。其次,我们可以利用位置数据在必要时近乎实时地为用户提供更准确的 ETA 并重新规划路线。
但是我们真的需要立即将每个位置更新发送到服务器吗?答案可能是否定的。位置历史可以在客户端缓冲,并以较低的频率批量发送到服务器。例如,如图 3.9 所示,位置更新每秒记录一次,但仅作为每 15 秒一批次的一部分发送到服务器。这显著减少了发送到所有客户端的总更新流量。
[图 3.9:批量请求]
(时间轴显示每 15 秒发送一个包含多个位置记录的批次)
批次 3 (loc 45, ...) --- 15s --- 批次 2 (loc 32, loc 31, loc 30, ..., loc 17, loc 16) --- 15s --- 批次 1 (loc 15, ..., loc 2, loc 1)
对于像谷歌地图这样的系统,即使位置更新是批量的,写入量仍然很高。我们需要一个针对高写入量和高可扩展性进行优化的数据库,例如 Cassandra。我们可能还需要将位置数据记录到一个流处理引擎,如 Kafka,用于进一步处理。我们将在深入探讨部分讨论这一点。
什么通信协议可能是一个好的选择?带有 keep-alive 选项 [10] 的 HTTP 在这里可能是个不错的选择,因为它非常高效。HTTP 请求可能看起来像这样:
POST /v1/locations
参数
locs: JSON 编码的 (纬度, 经度, 时间戳) 元组数组。
导航服务
此组件负责找到从点 A 到点 B 的合理快速路径。我们可以容忍一点延迟。计算出的路线不必是最快的,但准确性至关重要。
如图 3.7(译者注:原文此处为 3.8,根据上下文应为高层设计图 3.7) 所示,用户通过负载均衡器向导航服务发送 HTTP 请求。该请求包括起点和终点作为参数。API 可能看起来像这样:
GET /v1/nav?origin=1355+market+street,SF&destination=Disneyland
导航请求的结果可能如下所示:
{
"distance": { "text": "0.2 mi", "value": 259 },
"duration": { "text": "1 min", "value": 83 },
"end_location": { "lat": 37.4038943, "lng": -121.9410454 },
"html_instructions": "Head <b>northeast</b> on <b>Brandon St</b> toward <b>Alum Rock Ave</b><div style=\"font-size:0.9em\">Restricted usage road</div>",
"polyline": { "points": "_fhcFjbngVuAWsDsCal"},
"start_location": { "lat": 37.4027166, "lng": -121.9435889 },
"geocoded_waypoints": [ {
"geocoder_status": "OK",
"partial_match": true,
"place_id": "ChIJmt1fawWR02aVVVX2Ykg",
"types": [ "locality", "political" ]
}, {
"geocoder_status": "OK",
"partial_match": true,
"place_id": "ChIJa3ApQG6tXawRLYeiBMUi7bM",
"types": [ "locality", "political" ]
} ],
"travel_mode": "DRIVING"
}
请参考 [11] 了解更多关于谷歌地图官方 API 的细节。
到目前为止,我们还没有考虑实时交通和路线变化。这些问题由自适应 ETA 服务解决,该服务将在深入探讨部分进行讨论。
地图渲染
正如我们在粗略估算中讨论的那样,整个地图瓦片集合在各种缩放级别下大约有数百 PB。将整个数据集保存在服务器上供客户端根据客户端视口的当前位置和缩放级别按需获取是不切实际的。
客户端应该何时从服务器获取新的地图瓦片?以下是一些场景:
- 用户正在缩放和平移地图视口以探索他们的周围环境。
- 在导航过程中,用户移出当前地图瓦片进入邻近瓦片。
我们正在处理大量数据。让我们看看如何有效地为客户端提供地图瓦片。
选项 1
服务器根据客户端位置和客户端视口的缩放级别动态构建地图瓦片。考虑到位置和缩放级别组合的数量是无限的,动态生成地图瓦片有几个严重的缺点:
- 它给服务器集群带来了巨大的负载,需要动态生成每个地图瓦片。
- 由于地图瓦片是动态生成的,因此很难利用缓存。
选项 2
另一个选项是为每个缩放级别预先生成一组静态地图瓦片。地图瓦片是静态的,每个瓦片使用诸如 geohashing 之类的细分方案覆盖固定的矩形网格。每个瓦片因此由其 geohash 表示。换句话说,有一个唯一的 geohash 与每个网格相关联。当客户端需要地图瓦片时,它首先确定基于其缩放级别要使用的地图瓦片集合。然后它通过将其位置转换为适当缩放级别的 geohash 来计算地图瓦片 URL。 这些静态的、预先生成的图像由 CDN 提供,如图 3.10 所示。
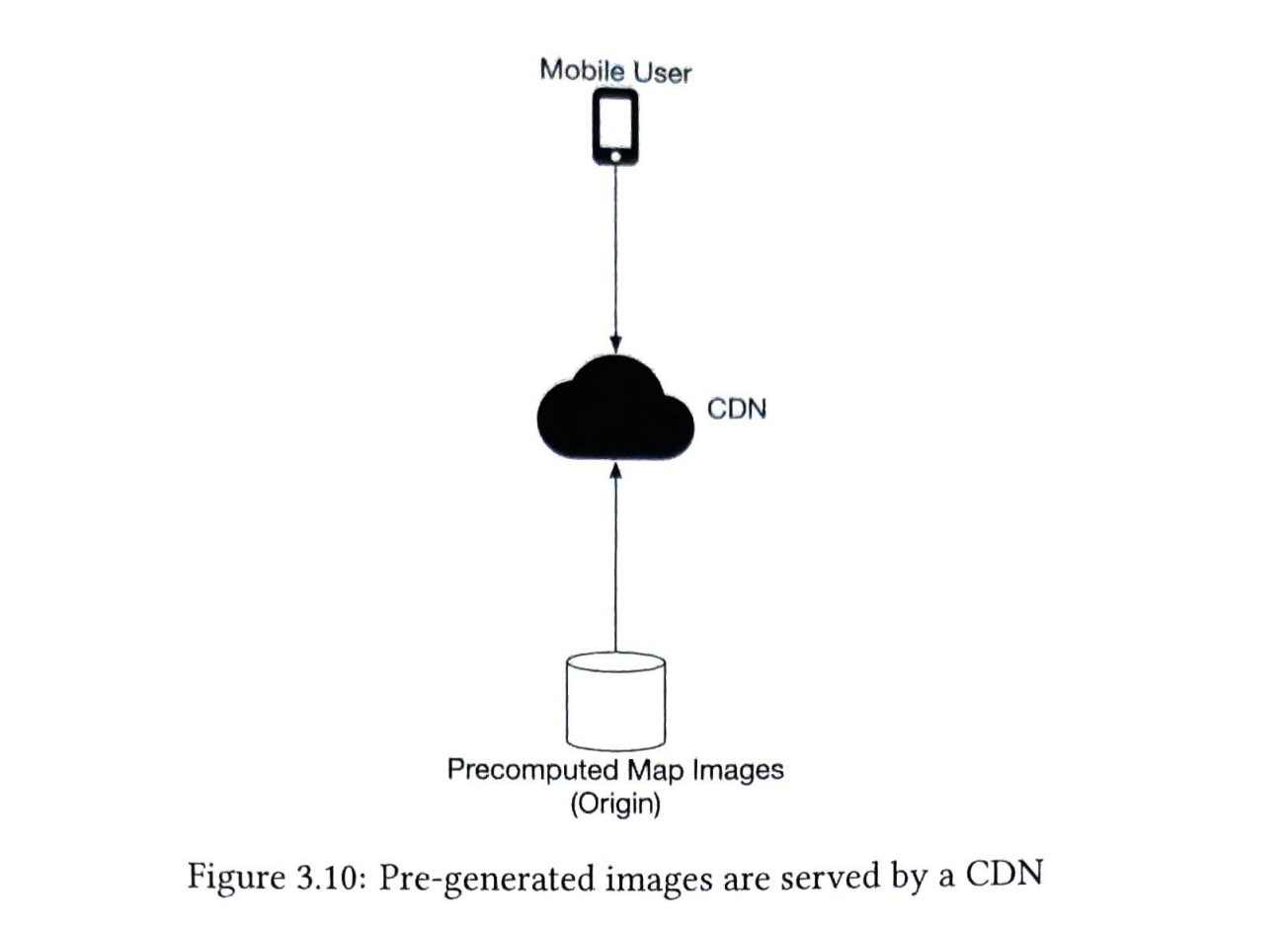
[图 3.10:预生成图像由 CDN 提供]
移动用户 -> CDN -> 预计算地图图像 (源站)
在上图中,移动用户发出 HTTP 请求以从 CDN 获取瓦片。如果 CDN 尚未提供该特定瓦片,它会从源服务器获取副本,在本地缓存,然后返回给用户。对于后续请求,即使这些请求来自不同的用户,CDN 也会返回缓存的副本,而无需联系源服务器。
这种方法更具可扩展性和性能,因为地图瓦片是从最近的存在点 (POP) 提供的,如图 3.11 所示。地图瓦片的静态特性使其高度可缓存。
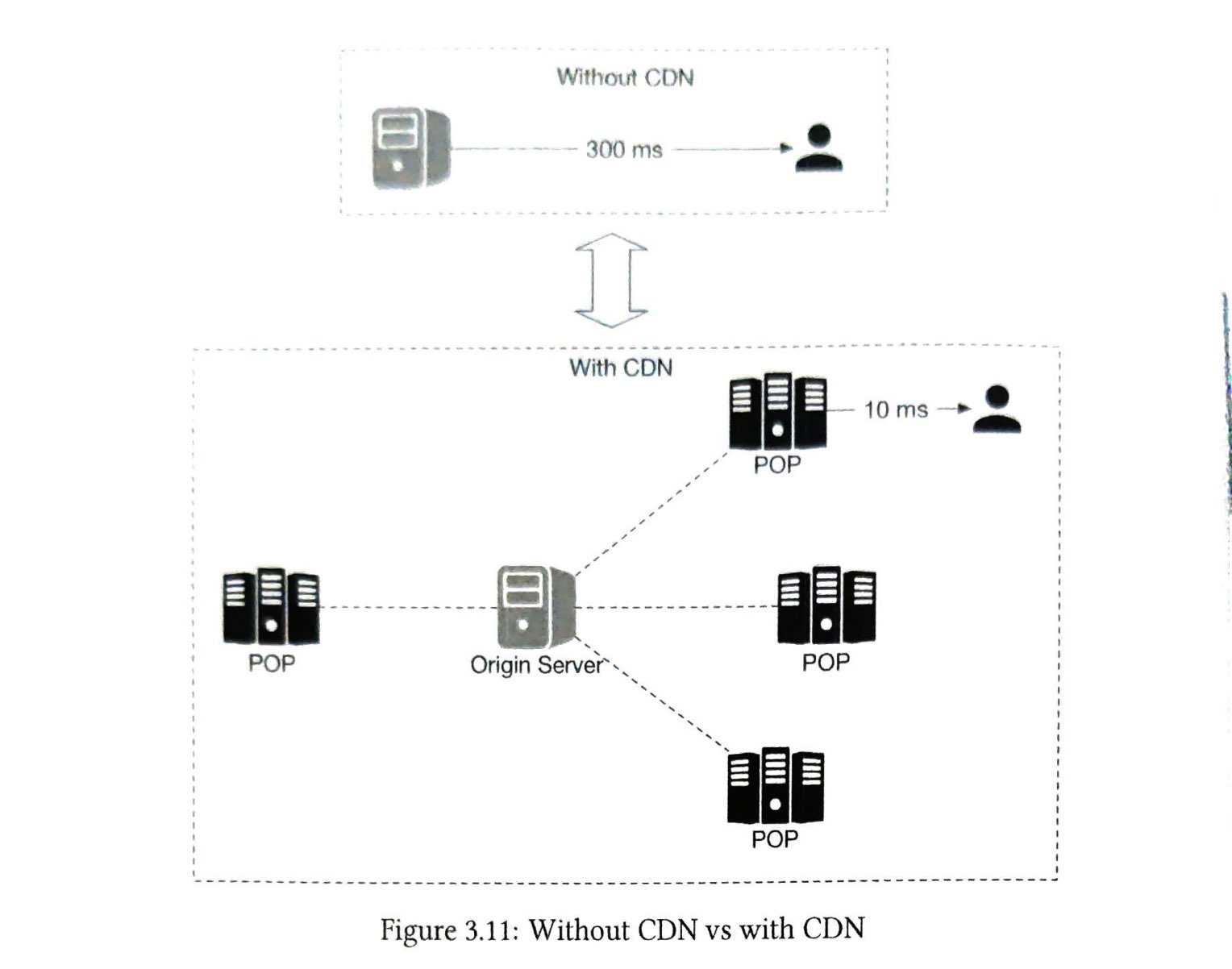
[图 3.11:有 CDN vs 无 CDN]
无 CDN:服务器 <-- 300 ms --> 用户
有 CDN:
用户 <-- 10 ms --> POP
POP <-- ... --> POP
POP <-- ... --> 源服务器
POP <-- ... --> POP
保持移动数据使用量低很重要。让我们计算客户端在典型导航会话期间需要加载的数据量。请注意,以下计算未考虑客户端缓存。由于用户每天可能会走相似的路线,因此数据使用量可能比使用客户端缓存要低得多。
数据使用
假设用户以 30km/h 的速度移动,并且在某个缩放级别,每个图像覆盖一个 200m x 200m 的区块(一个区块由 256 像素表示,平均图像大小为 100KB)。对于 1km x 1km 的区域,我们需要 25 个图像或 2.5MB (25 x 100KB) 的数据。因此,如果速度是 30km/h,我们需要每小时 75MB (30 x 2.5MB) 或每分钟 1.25MB 的数据。
接下来,我们估算 CDN 数据使用量。以我们的规模,成本是一个重要的考虑因素。
通过 CDN 的流量
如前所述,我们每天提供 50 亿分钟的导航。这转化为每天 50 亿 x 1.25MB = 6.25 PB 的地图数据。因此,我们每秒需要提供 62,500MB (6.25 PB / 10^5 秒) 的数据。这些地图图像将从世界各地的 POP 提供。假设有 200 个 POP。每个 POP 只需要每秒提供几百 MB (62,500 / 200)。
在地图渲染设计中,还有一个最终细节我们只简要触及过。客户端如何知道使用哪些 URL 从 CDN 获取地图瓦片?请记住,在使用我们讨论的选项 2 时,地图瓦片是静态的,并基于固定的网格集预先生成,每个集合代表一个离散的缩放级别。
由于网格基于 geohash,并且每个网格有一个唯一的 geohash,因此客户端计算 geohash(对于地图瓦片)非常高效。此计算可以在客户端完成,我们可以从 CDN 获取静态图像瓦片。例如,谷歌总部图像瓦片的 URL 可能看起来像这样:https://cdn.map-provider.com/tiles/9q9hvu.png
请参阅第 10 页的第一章邻近服务,了解有关 geohash 编码的更详细讨论。
在客户端计算 geohash 应该工作良好。然而,请记住,此算法被硬编码在所有客户端的所有不同平台上。将更改发布到移动应用程序是一个耗时且有风险的过程。我们必须确保该方法有效。如果我们计划长期使用此编码来收集地图瓦片,并且不太可能更改它。如果我们需要切换到另一种编码方法,风险很低。
另一个值得考虑的选择。与其使用硬编码的客户端算法将纬度/经度对和缩放级别转换为瓦片 URL,不如引入一个服务作为中介,其工作是构建基于相同输入的瓦片 URL。这是一个非常简单的服务。增加的操作灵活性可能值得付出这个代价。这种非常有趣的权衡讨论可以与面试官进行。另一种地图渲染流程如图 3.12 所示。
当用户移动到新位置或新的缩放级别时,地图瓦片服务确定需要哪些瓦片,并转换该信息为一组要检索的瓦片 URL。
[图 3.12:地图渲染]
移动用户 --(1) 获取瓦片 URL --> 负载均衡器 --(2) 转发请求 --> 地图瓦片服务 --(3) 构建瓦片 URL --> 负载均衡器 -> 移动用户 --(4) 下载瓦片 --> CDN
- 移动用户调用地图瓦片服务以获取瓦片 URL。请求被发送到负载均衡器。
- 负载均衡器将请求转发给地图瓦片服务。
- 地图瓦片服务将客户端的位置和缩放级别作为输入,并返回 9 个 URL,包括要渲染的瓦片和八个周围的瓦片。
- 移动客户端从 CDN 下载瓦片。
我们将在设计深入探讨部分更详细地介绍预计算的地图瓦片。
步骤 3 - 设计深入探讨
在本节中,我们将讨论数据模型。然后我们将更详细地讨论位置服务、导航服务和地图渲染。
数据模型
我们正在处理四种类型的数据:路由瓦片、用户位置数据、地理编码数据和世界的预计算地图。
路由瓦片
如前所述,初始道路数据集来自不同的来源和权威机构。它包含 TB 级的原始数据。数据集会随着用户使用应用程序不断从用户那里收集的位置数据而不断改进。
此数据集包含大量道路和关联的元数据,例如名称、县、经度、纬度。此数据未组织为图形数据结构,并且不适用于大多数路由算法。我们运行一个周期性的离线处理管道,称为路由瓦片处理服务,将此数据集转换为我们引入的路由瓦片。该服务定期运行以捕获对道路数据的最新更改。
路由瓦片处理服务的输出是路由瓦片。有三组具有不同分辨率的瓦片,如第 60 页的"地图 101"部分所述。每个瓦片包含一个表示瓦片覆盖区域内的交叉口和道路的图节点和边的列表。它还包含对其连接的所有其他瓦片的引用。这些瓦片共同构成了一个互连的道路网络,路由算法可以增量地使用这些道路。
路由瓦片处理服务存储这些瓦片的位置在哪里?大多数图数据都表示为邻接表 [12] 或邻接列表 [13] 在内存中。为了保持瓦片尽可能小以减少存储和网络传输,我们只存储节点和边作为行在数据库中,并认为它需要某种方式来序列化邻接列表到二进制文件中。我们可以使用高性能软件包装,如 Protocol Buffers,将这些瓦片序列化为对象存储。这提供了一种通过其 geohash/ing 对在对象存储中查找瓦片的快速机制。
我们稍后讨论最短路径服务如何使用这些路由瓦片。
用户位置数据
用户位置数据很有价值。我们使用它来更新我们的路由数据和路由瓦片。我们还使用它来构建实时和历史交通数据。我们还使用它通过多个数据流处理服务来更新地图数据。
对于用户位置数据,我们需要一个能够很好地处理写入密集型工作负载并且可以水平扩展的数据库。Cassandra 可能是一个不错的选择。
以下是单个行可能的样子:
| user_id | timestamp | user_mode | driving_mode | location |
|---|---|---|---|---|
| 101 | 1635740977 | active | driving | (20.0, 30.5) |
| 表 3.2:位置表 |
地理编码数据
此数据库存储地点及其对应的纬度/经度对。我们可以使用键值数据库,例如 Redis,用于快速读取,因为我们有频繁的读取和不频繁的写入。我们使用它将起点或终点转换为路由规划器之前的纬度/经度对。
世界地图的预计算图像
当设备请求地图的特定区域时,我们需要获取附近的道路并计算代表该区域以及所有道路和相关细节的图像。这些计算将是繁重和多余的,因此预先计算它们并将图像缓存起来可能会有所帮助。我们在不同的缩放级别预先计算图像,并将它们存储在像 Amazon S3 这样的云存储中,该存储由 CDN 支持。这是一个示例图像:

[图 3.13:预计算瓦片]
地图瓦片来自 Stamen Design, 在 CC BY 3.0 许可下。数据来自 OpenStreetMap 贡献者。
服务
现在我们已经讨论了数据模型,让我们仔细看看一些最重要的服务:位置服务、地图渲染服务和导航服务。
位置服务
在高层设计中,我们讨论了位置服务的工作原理。在本节中,我们将重点关注该服务的数据库设计以及如何使用用户位置数据。
在图 3.14 中,键值存储用于存储用户位置数据。让我们仔细看看。
[图 3.14:用户位置数据库]
移动用户 -> 负载均衡器 -> 位置服务 -> 用户位置数据库
鉴于我们每秒有 100 万次位置更新,我们需要一个支持快速写入的数据库。NoSQL 键值数据库或面向列的数据库将是一个不错的选择。此外,用户的位置是不断变化的,并尽快变得陈旧。因此,我们优先考虑可用性而不是一致性。CAP 定理 [13] 指出我们可以在一致性、可用性和分区容错性这三个属性中选择两个。考虑到我们的约束,我们将选择可用性和分区容错性。一个具有强可用性保证的数据库是一个不错的选择,比如 Cassandra。它可以处理我们的规模并具有强大的可用性保证。
键是 (user_id, timestamp) 的组合,值是纬度/经度对。在此设置中,user_id 是分区键,timestamp 是聚类键。使用 user_id 作为分区键的优势在于,它可以快速读取特定用户的最新位置。给定用户的所有数据都存储在同一个分区键中,按 timestamp 排序。通过这种安排,检索特定用户在时间范围内的位置数据非常高效。
下面是表格可能的样子:
| key (user_id) | timestamp | lat | long | user_mode | navigation_mode |
|---|---|---|---|---|---|
| 51 | 132053000 | 21.9 | 89.8 | active | driving |
| 表 3.3:位置数据 |
我们如何使用用户位置数据?
用户位置数据至关重要。它支持许多用例。我们使用这些数据来检测新的和封闭的道路。我们使用它作为改进地图随时间推移准确性的输入之一。它还用于实时交通数据。
为了支持这些用例,除了将当前用户位置写入我们的数据库,我们将此信息记录到一个消息队列中,例如 Kafka。Kafka 是一个统一的、低延迟、高吞吐量的数据流平台,专为实时数据馈送而设计。图 3.15 显示了改进后的设计中使用 Kafka 的情况。
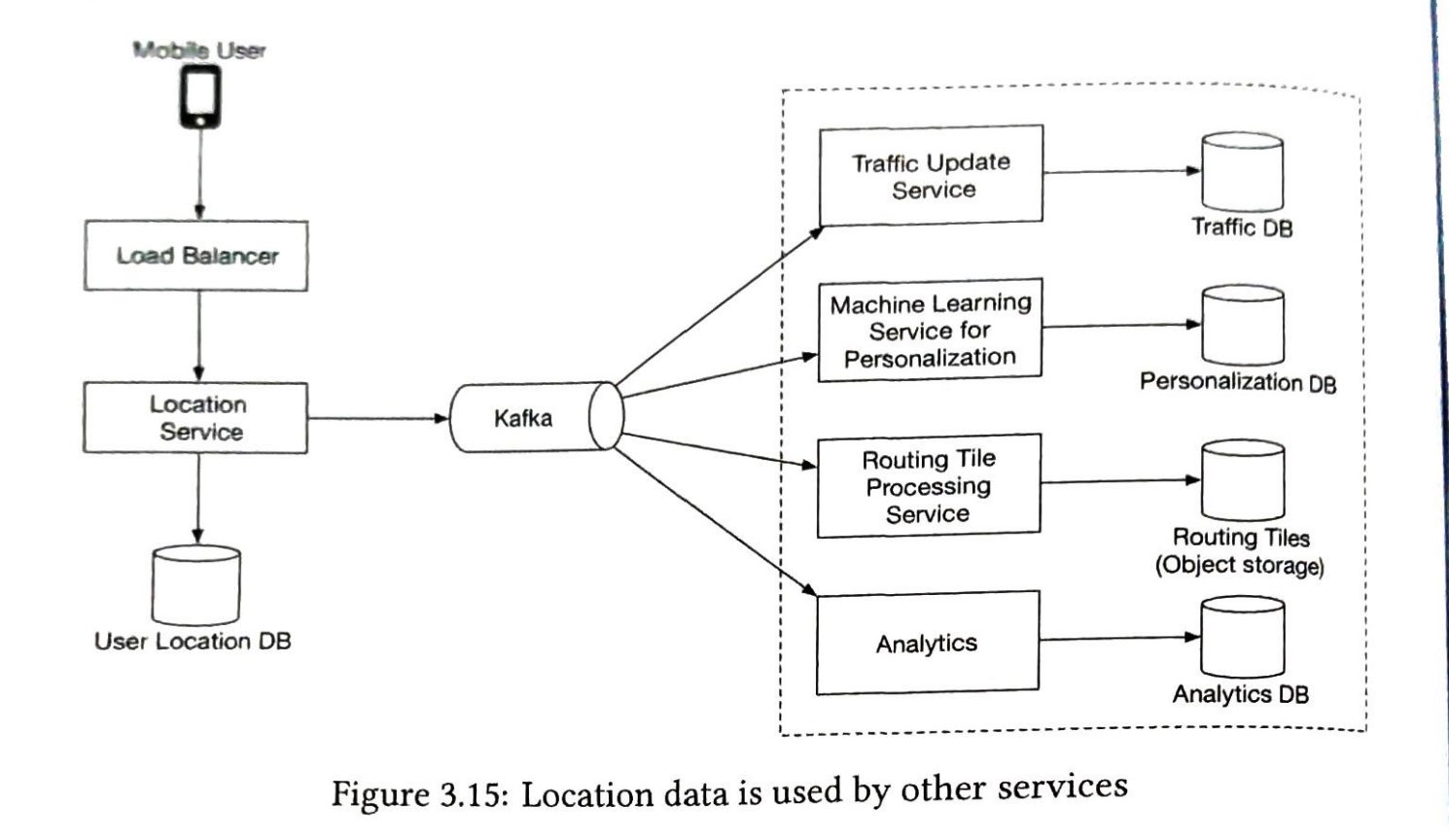
[图 3.15:位置数据被其他服务使用]
移动用户 -> 负载均衡器 -> 位置服务 -> 用户位置数据库
位置服务 -> Kafka
Kafka -> 交通更新服务 -> 交通数据库
Kafka -> 机器学习服务 & 个性化 -> 个性化数据库
Kafka -> 路由瓦片处理服务 -> 路由瓦片 (对象存储)
Kafka -> 分析 -> 分析数据库
其他服务消费来自 Kafka 的位置数据流用于各种用例。例如,实时交通服务消化流并更新实时交通数据库。路由瓦片处理服务利用流通过检测新的或封闭的道路以及更新受影响的路由瓦片来改进地图。其他服务也可以接入流用于不同目的。
渲染地图
在本节中,我们将深入探讨预计算地图瓦片和地图渲染优化。这些主要受到谷歌设计 [3] 工作的启发。
预计算瓦片
如前所述,有不同的预计算地图瓦片集,在不同的缩放级别提供适当的地图细节级别,基于客户端的视口大小和缩放级别。谷歌地图使用 21 个缩放级别(表 3.1)。我们也会这样做。
级别 0 是最缩小的级别。整个地图由单个 256 x 256 像素的瓦片表示。
随着每次缩放级别的增加,地图瓦片的数量在南北方向和东西方向上都翻倍。如图 3.16 所示,在缩放级别 1,有 2 x 2 = 4 个瓦片,总分辨率为 512 x 512 像素。在缩放级别 2,有 4 x 4 = 16 个瓦片,总分辨率为 1024 x 1024 像素。随着每次增加,整个瓦片集的像素数量增加 4 倍与上一级别相比。增加的像素数给用户提供了更高层次的细节。这允许客户端在最佳粒度级别渲染地图,而无需下载过多的瓦片到客户端的视口和缩放级别。
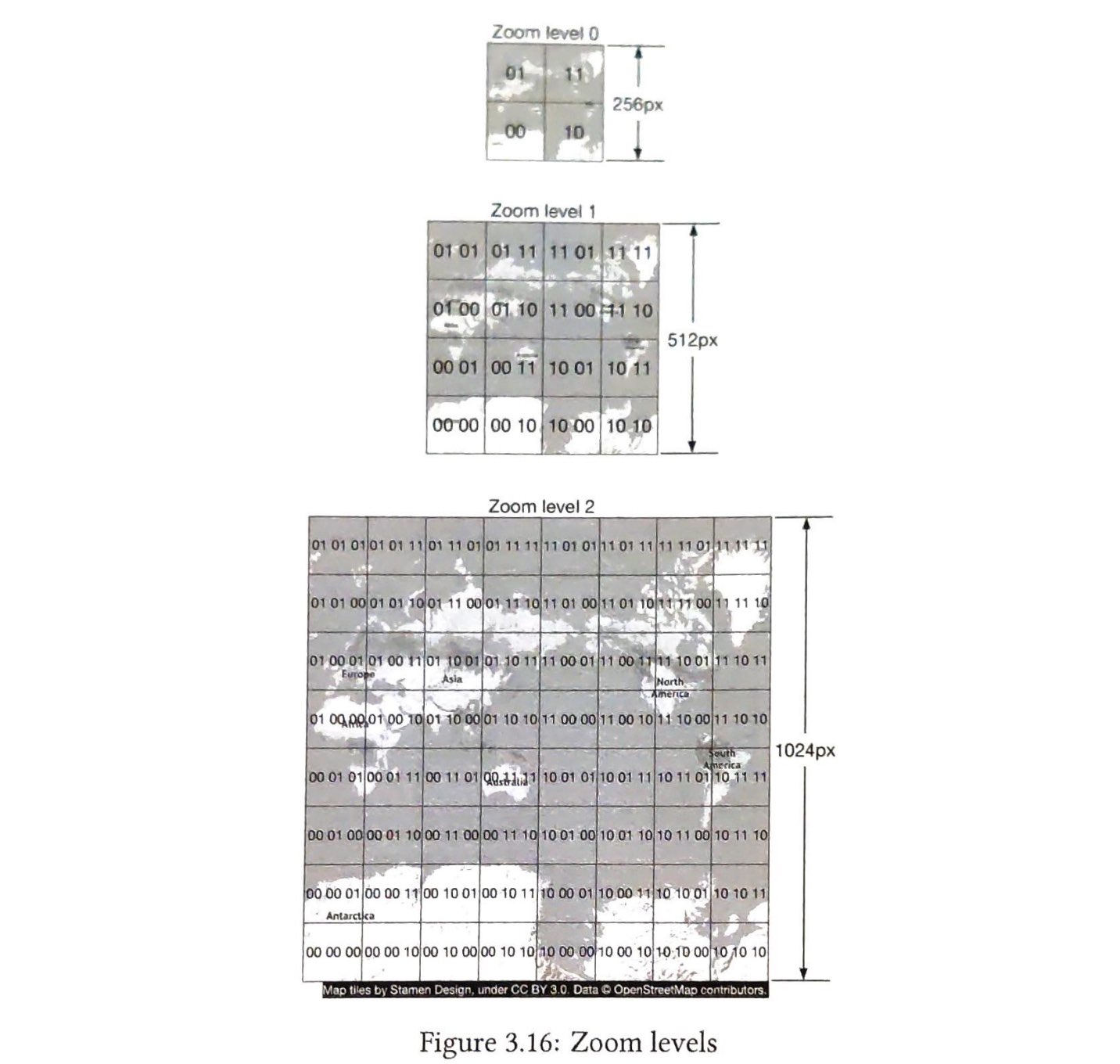
[图 3.16:缩放级别]
缩放级别 0 (256px)
01 11
00 10
缩放级别 1 (512px)
0101 0111 1101 1111
0100 0110 1100 1110
0001 0011 1001 1011
0000 0010 1000 1010
缩放级别 2 (1024px)
(更细分的网格)
地图瓦片来自 Stamen Design, 在 CC BY 3.0 许可下。数据来自 OpenStreetMap 贡献者。
优化:使用矢量
随着 WebGL 的开发和实现,一个潜在的改进是将设计从发送图像(栅格瓦片)更改为发送矢量信息(路径和多边形)。客户端从矢量信息中绘制路径和多边形。
矢量瓦片的一个明显优势是矢量数据压缩效果比图像好得多。带宽节省是可观的。
一个不那么明显的优势是矢量瓦片提供了更好的缩放体验。使用栅格图像,客户端从一个缩放级别缩放到另一个级别时,一切都会变得模糊,直到新的瓦片被加载。
导航服务 (续)
让我们回到导航服务。图 3.17 显示了导航服务及其依赖项。

[图 3.17:导航服务]
导航服务 -> 地理编码服务
导航服务 -> 路线规划器服务
路线规划器服务 -> 最短路径服务
路线规划器服务 -> ETA 服务
路线规划器服务 -> 排名器服务
最短路径服务 -> 过滤器服务
最短路径服务 -> 路由瓦片
ETA 服务 -> 交通数据库
ETA 服务 -> 自适应 ETA 和重新路由
自适应 ETA 和重新路由 -> 活跃用户数据库
地理编码服务
该服务将人类可读的地址转换为地理坐标(纬度/经度对)。对于反向操作,它将地理坐标转换为地址。
路线规划器服务
这是导航服务的核心组件。它与多个下游服务交互以找到最佳路线。
最短路径服务
最短路径服务接收起点和终点的纬度/经度对,并返回考虑交通或当前状况的前 k 条最短路径。此计算依赖于道路的结构。在这里,缓存路线可能是有益的,因为图很少改变。
最短路径服务运行 A* 寻路算法的变种,该算法在对象存储中的路由瓦片上运行。以下是概述:
- 算法接收起点和终点的纬度/经度对。纬度/经度对被转换为 geohash,然后用于加载路线的起点和终点。
- 算法从起点路由瓦片开始,遍历图数据结构,并从对象存储(或其本地缓存,如果已加载)水合额外的相邻瓦片,因为它扩展了搜索区域。它连接来自一个级别的瓦片以覆盖相同区域的另一个级别的瓦片。这是算法可以"进入"更大的瓦片,只包含高速公路的方式,例如。算法继续进行,直到找到终点,需要通过水合更多相邻瓦片(或不同分辨率的瓦片)来扩展,直到找到一组最佳路线。
图 3.18(基于 [14])给出了图遍历中使用的瓦片的概念性概述。
[图 3.18:图遍历]
地图瓦片来自 Stamen Design, 在 CC BY 3.0 许可下。数据来自 OpenStreetMap 贡献者。
ETA 服务
路线规划器收到可能的最近路径列表后,它会为每个可能的路径调用 ETA 服务以获取时间估计。为此,ETA 服务使用机器学习来根据当前和历史交通数据预测 ETA。
预测未来 10 或 20 分钟交通状况的挑战需要在一个单独的算法层面得到解决,本讨论不涉及。如果你感兴趣,请参考 [15] 和 [16]。
排名器服务 (Ranker service)
最后,在路线规划器获得 ETA 预测后,它将此信息传递给排名器以应用用户定义的过滤器。一些示例过滤器包括避开收费公路或避开高速公路。然后,排名器服务将路线从最快到最慢进行排名,并返回导航服务的前 k 个结果。
更新器服务 (Updater services)
这些服务接入 Kafka 位置更新流并异步更新一些重要的数据库以保持它们最新。交通数据库和路由瓦片就是一些例子。
路由瓦片处理服务负责将带有新发现的道路和道路封闭的道路数据集转换为持续更新的路由瓦片集。这有助于最短路径服务更加准确。
交通更新服务提取来自活跃用户的流位置更新的交通状况。此洞察被输入到实时交通数据库中。这使得 ETA 服务能够提供更准确的估计。
改进:自适应 ETA 和重新路由
当前设计不支持自适应 ETA 和重新路由。为了解决这个问题,服务器需要跟踪活跃导航用户并根据 ETA 变化更新他们。无论何时交通状况发生变化,我们都需要回答几个重要问题:
- 我们如何跟踪活跃导航用户?
- 我们如何存储数据,以便我们可以有效地根据交通变化定位受影响的用户,例如在特定路由瓦片上的交通拥堵?
让我们从一个简单的解决方案开始。在图 3.19 中,user_1 的导航路线由路由瓦片 r_1, r_2, r_3, ..., r_7 表示。
[图 3.19:导航路线]
r_1 (起点) -> r_2 -> r_3 -> r_4 -> r_5 -> r_6 -> r_7 (目的地)
数据库存储活跃导航用户和路线信息,可能看起来像这样:
user_1: r_1, r_2, r_3, ..., r_k
user_2: r_4, r_6, r_9, ..., r_n
user_3: r_2, r_8, r_9, ..., r_m
...
user_n: r_2, r_10, r_21, ..., r_l
假设路由瓦片 2 (r_2) 发生交通事件。要找出哪些用户受到影响,我们可以扫描每一行并检查路由瓦片 2 是否在我们的路由瓦片列表中(参见下面的示例):
user_1: r_1, **r_2**, r_3, ..., r_k
user_2: r_4, r_6, r_9, ..., r_n
user_3: **r_2**, r_8, r_9, ..., r_m
...
user_n: **r_2**, r_10, r_21, ..., r_l
假设表中有 n 行,导航的平均长度是 m。找到所有受交通变化影响的用户的时间复杂度是 O(n x m)。
我们能让这个过程更快吗?让我们探索一种不同的方法。对于每个活跃导航用户,我们保留当前路由瓦片、下一个分辨率级别的路由瓦片(包含它),并递归地直到文件中的最高分辨率级别(图 3.20)。通过这样做,我们可以快速过滤出许多用户。数据库表的行可能看起来像这样:
user_1, r_1, super(r_1), super(super(r_1)), ...
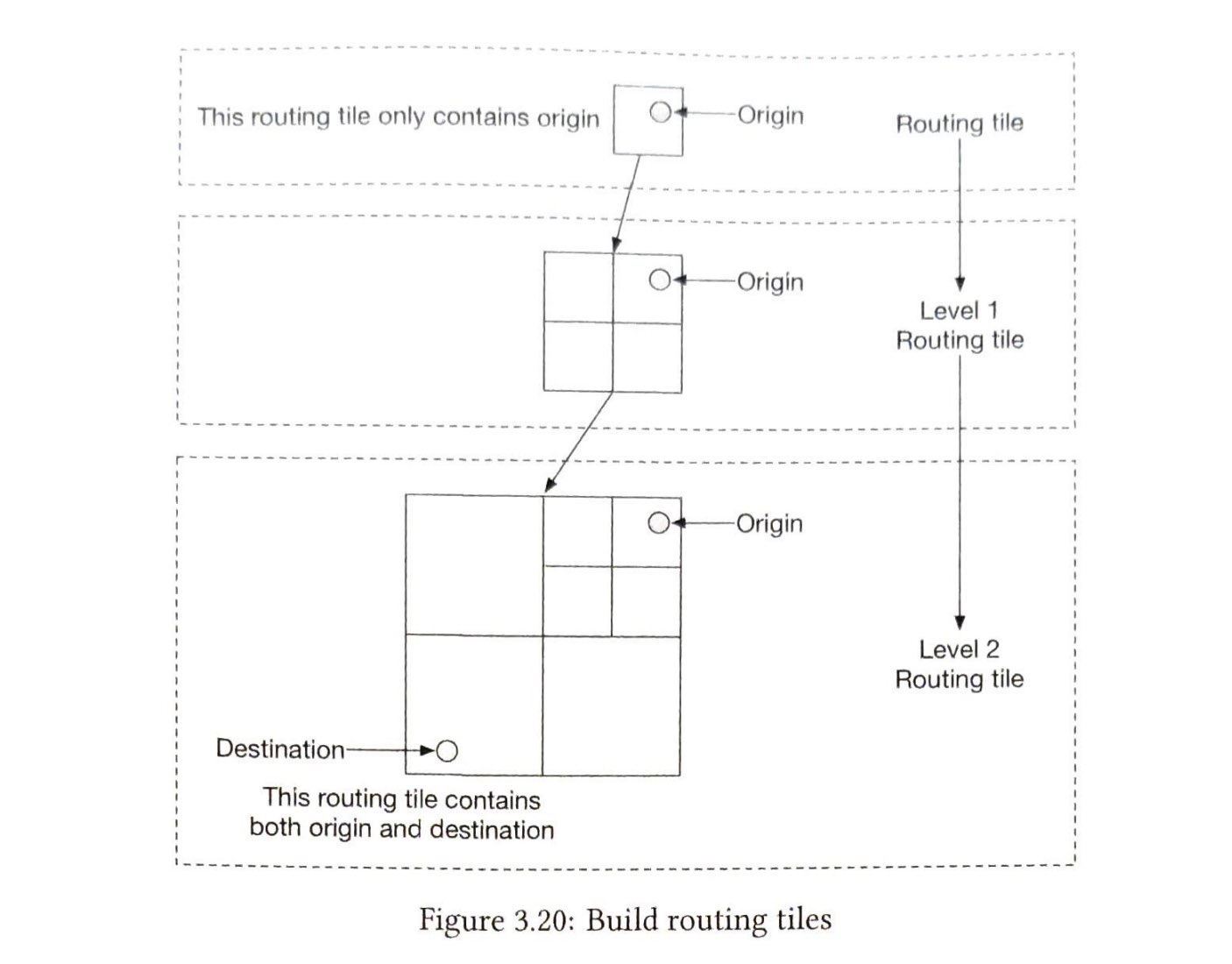
[图 3.20:构建路由瓦片]
此路由瓦片仅包含起点 (Origin) -> O (Level 2 Routing tile)
此路由瓦片包含起点和终点 (Origin & Destination) -> O (Level 1 Routing tile)
目的地 (Destination) -> O (Routing tile)
要找出用户是否受到交通变化的影响,我们只需要检查数据库中一行的最后一个路由瓦片是否包含该路由瓦片。如果不是,则用户不受影响。如果是,则用户受到影响。通过这样做,我们可以快速过滤掉许多用户。
这种方法没有具体说明当交通畅通时会发生什么。例如,如果路由瓦片 2 清除并且用户可以回到旧路线,用户如何知道重新路由可用?一个想法是跟踪所有可能的备用路线,并定期重新计算 ETA,以便在有新路线可用时通知用户。
交付协议 (Delivery protocols)
在导航过程中,路线状况可能会发生变化,服务器需要一种可靠的方式将数据推送到移动客户端。对于从服务器到客户端的交付协议,我们的选择包括移动推送通知、长轮询、WebSocket 和服务器发送事件 (SSE)。
- 移动推送通知不是一个好的选择,因为有效载荷大小非常有限(iOS 为 4,096 字节),并且它不支持 Web 应用程序。
- WebSocket 通常被认为比长轮询更好,因为它在服务器上的占用空间非常小。
- 由于我们已经排除了移动推送通知和长轮询,因此选择主要在 WebSocket 和 SSE 之间。即使两者都可以工作,我们还是倾向于 WebSocket,因为它支持双向通信和功能,例如最后一英里交付可能需要双向实时通信。
有关 ETA 和重新路由的更多详细信息,请参考 [15]。
现在我们已经设计好了所有部分。请看图 3.21 中的更新设计。
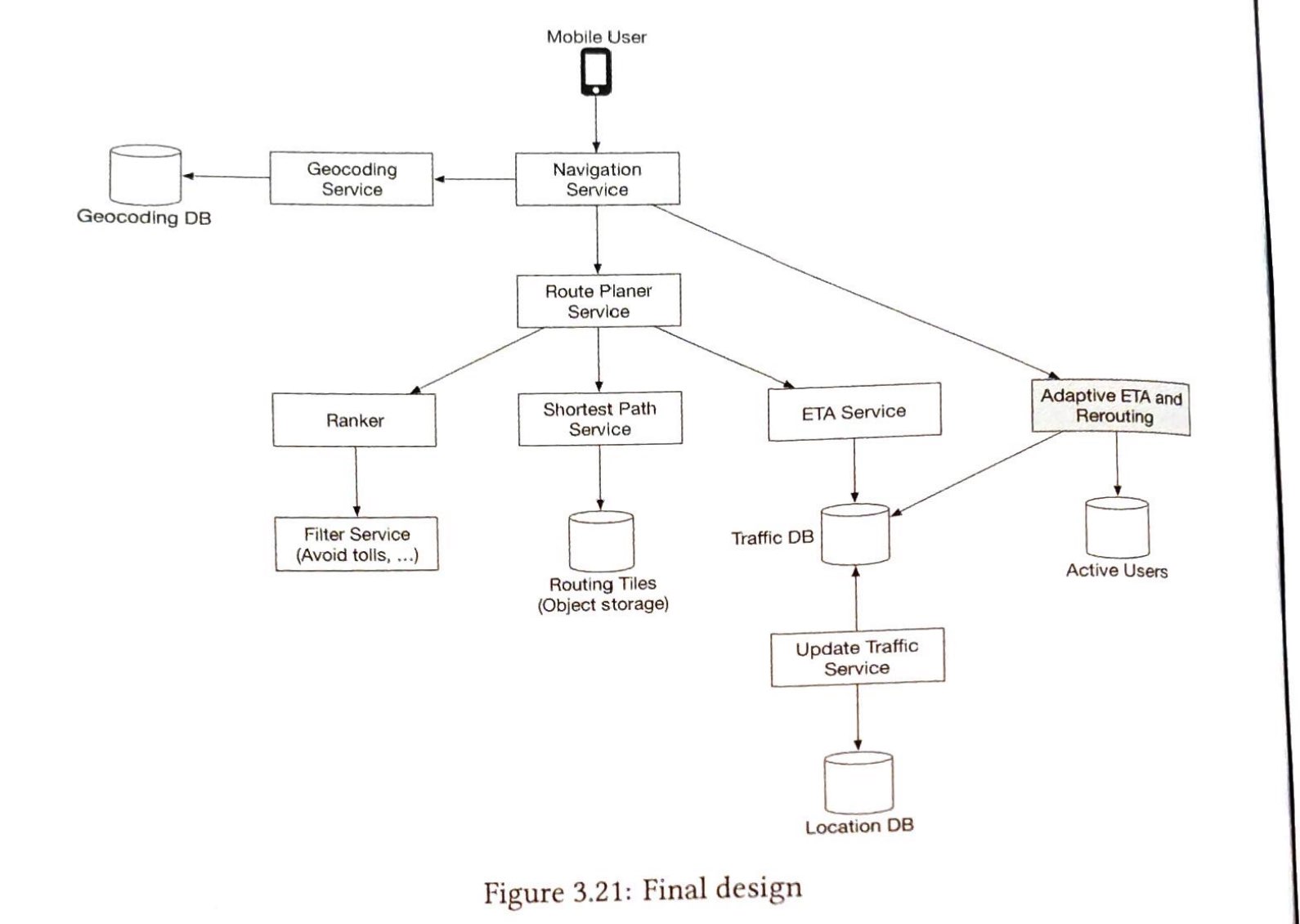
[图 3.21:最终设计]
移动用户 -> 负载均衡器
负载均衡器 -> 地理编码服务 -> 地理编码数据库
负载均衡器 -> 导航服务
导航服务 -> 路线规划器服务
路线规划器服务 -> 最短路径服务 -> 路由瓦片 (对象存储)
路线规划器服务 -> ETA 服务 -> 交通数据库
路线规划器服务 -> 排名器
最短路径服务 -> 过滤器服务 (避开收费站, ...)
ETA 服务 -> 自适应 ETA 和重新路由 -> 活跃用户数据库
自适应 ETA 和重新路由 -> 更新交通服务 -> 位置数据库
步骤 4 - 总结
在本章中,我们设计了一个简化的谷歌地图,具有关键功能,例如位置更新、ETA、路线规划和地图渲染。如果你有兴趣扩展系统,一个潜在的改进是为企业客户提供多站点导航功能。例如,对于给定的目的地集,我们需要找到访问所有这些目的地的最佳顺序,并提供导航,基于实时交通状况。这对于像 DoorDash、Uber、Lyft 等送货服务会很有帮助。
恭喜你走到这一步!现在给自己一个鼓励。干得好!
章节总结
- 谷歌地图 (Google Maps)
- 步骤 1 (step 1)
- 功能需求 (functional req)
- 用户位置更新 (user location update)
- 导航服务 (navigation service)
- 地图渲染 (map rendering)
- 非功能需求 (non-functional req)
- 高精度 (highly accurate)
- 流畅导航 (smooth navigation)
- 数据使用 (data usage)
- 估算 (estimation)
- 存储 (storage)
- 服务器流量 (server traffic)
- 功能需求 (functional req)
- 步骤 2 (step 2)
- 地图 101 (map 101)
- 定位系统 (positioning system)
- 从 3D 到 2D (going from 3d to 2d)
- 地理编码 (geocoding)
- 地理哈希 (geohashing)
- 路由瓦片 (routing tiles)
- 高层设计 (high-level design)
- 位置服务 (location service)
- 导航服务 (navigation service)
- 地图渲染 (map rendering)
- 地图 101 (map 101)
- 步骤 3 (step 3)
- 数据 (data)
- 路由瓦片 (routing tiles)
- 用户位置 (user location)
- 地点 (places)
- 预计算图像 (precomputed images)
- 服务 (services)
- 位置服务 (location service) -> 如何使用位置数据 (how location data is used)
- 渲染地图 (rendering map)
- 预计算瓦片 (precomputed tiles)
- 使用矢量 (use vectors)
- 导航服务 (navigation service)
- 地理编码 (geocoding)
- 路线规划器 (route planner)
- 最短路径 (shortest-path)
- ETA 服务 (ETA service)
- 自适应 ETA 和重新路由 (adaptive ETA and rerouting)
- 数据 (data)
- 步骤 4 (step 4) -> 总结 (wrap up)
- 步骤 1 (step 1)
参考资料
- 谷歌地图。 https://developers.google.com/maps?hl=en_US.
- 谷歌地图平台。 https://cloud.google.com/maps-platform/.
- 原型化更流畅的地图。 https://medium.com/google-design/google-maps-cb0326d165f5.
- 墨卡托投影。 https://en.wikipedia.org/wiki/Mercator_projection.
- 皮尔斯梅花投影。 https://en.wikipedia.org/wiki/Peirce_quincuncial_projection.
- 割圆锥投影。 https://en.wikipedia.org/wiki/Gall–Peters_projection.
- 温克尔投影。 https://en.wikipedia.org/wiki/Winkel_tripel_projection.
- 地址地理编码。 https://en.wikipedia.org/wiki/Address_geocoding.
- Geohashing. https://kousiknath.medium.com/system-design-design-a-geo-spatial-index-for-real-time-location-search-10968fe62b9c.
- HTTP keep-alive. https://en.wikipedia.org/wiki/HTTP_persistent_connection.
- Directions API. https://developers.google.com/maps/documentation/directions/start?hl=en_US.
- 邻接表。 https://en.wikipedia.org/wiki/Adjacency_list.
- CAP 定理。 https://en.wikipedia.org/wiki/CAP_theorem.
- 路由瓦片。 https://valhalla.readthedocs.io/en/latest/mjolnir/why_tiles/.
- 使用 GNN 的 ETA。 https://deepmind.com/blog/article/traffic-prediction-with-advanced-graph-neural-networks.
- 谷歌地图 101:AI 如何帮助预测交通和确定路线。 https://blog.google/products/maps/google-maps-101-how-ai-helps-predict-traffic-and-determine-routes/.
第04章:分布式消息队列
第05章:指标监控与告警系统
第06章:广告点击事件聚合
第07章:酒店预订系统
第08章:分布式邮件服务
第09章:类S3对象存储
第10章 实时游戏排行榜
在本章中,我们将讨论,如何为一款联网手机游戏设计排行榜。
什么是排行榜?排行榜在游戏和其他领域很常见,用于显示谁在特定的赛季或比赛对局中领先。用户在完成任务或挑战后会被分配分数,分数最高的用户就会在排行榜上名列前茅。图 10.1 示例,展示了一款手机游戏的排行榜。排行榜显示领先竞争对手的排名,同时也显示用户在排行榜上的位置。
译者注:赛季在原文中是 particular tournament,通常翻译为特定赛事或锦标赛,在游戏场景中,翻译为赛季更加贴切国内读者的习惯。之后的 particular tournament 均译为赛季。
 图 10.1: 排行榜
图 10.1: 排行榜
第1步 - 理解问题并确定设计范围
排行榜可以非常简单,但有许多不同的事项会增加复杂性。我们应该明确要求。
候选人:排行榜的分数是如何计算的?
面试官:用户赢得一场对局就能得到一分。我们可以采用一个简单的积分系统,每个用户都有一个与之相关的分数。用户每赢得一场对局,我们就应该在他们的总分上加上一分。
候选人:排行榜是否包括所有选手?
面试官:是的。
候选人:排行榜有时间段吗?
面试官:每个月都会有一次新的赛季拉开帷幕,并开始新的排行榜。
候选人:是否可以认为,我们只关心前 10 名用户?
面试官:我们希望显示排行榜上前10名用户以及特定用户的位置。如果时间允许,我们还将讨论如何返回比特定用户高 4 位和低 4 位的用户。
候选人:一次赛季有多少用户?
面试官:日活跃用户 (DAU) 平均500万,月活跃用户 (MAU) 平均 2500 万。
候选人:一次赛季平均要进行多少场对局?
面试官:每位玩家平均每天要打 10 次对局。
候选人:如果两名选手得分相同,如何确定名次?
面试官:在这种情况下,他们的排名是一样的。如果时间允许,我们可以讨论一下如何打破平局。
候选人:排行榜必须是实时的吗?
面试官:是的,我们希望呈现实时结果,或者尽可能接近实时结果。不能展示批量的历史结果。
现在,我们已经收集了所有需求,让我们列出功能需求。
功能需求
-
在排行榜上显示前 10 名玩家。
-
显示用户的具体排名。
-
显示比指定用户排名高四位和低四位的玩家。
除了明确功能性需求外,了解非功能性需求也很重要。
非功能性需求
-
实时更新分数。
-
得分更新会实时反映在排行榜上。
-
常见的可扩展性、可用性和可靠性要求。
粗略估算
让我们进行一些简单的计算,以确定我们的解决方案需要应对的潜在规模和挑战。
在 500 万 DAU 的情况下,如果游戏的玩家在 24 小时内分布均匀,那么平均每秒将有 50 个用户 $({5,000,000 DAU \over 10^6 seconds}\approx 50)$ 。但是,我们知道用户数量很可能不是均匀分布的,在晚上可能会出现高峰,因为不同时区的许多人都有时间玩游戏。为了考虑到这一点,我们可以假设峰值负载是平均值的 5 倍。因此,我们希望允许每秒 250 个用户的峰值负载。
用户获得积分的 QPS:如果一个用户平均每天玩 10 场游戏对局,则用户获得积分的 QPS 为: $50\times10\approx 500$。峰值QP 是平均值的 5 倍: $500\times5=2500$。
获取排行榜前 10 名的 QPS:假设用户每天打开一次游戏,而排行榜前 10 名仅在用户首次打开游戏时加载。其 QPS 约为 50。
第2步 - 提出高层设计并获得认可
在本节中,我们将讨论应用程序的接口设计、高层设计和数据模型。
API设计
在高层次上,我们需要以下三个API接口:
POST /v1/scores
当用户赢得游戏时,更新用户在排行榜上的位置。请求参数如下。这应该是一个内部 API,只能由游戏服务器调用。客户端不能直接更新排行榜得分。
| 字段 | 描述 |
|---|---|
| user_id | 赢得游戏的用户 |
| points | 用户赢得游戏所获得的积分 |
表 10.1: 请求参数
响应:
| 字段 | 描述 |
|---|---|
| 200 OK | 成功更新用户分数 |
| 400 Bad Request | 更新用户分数失败 |
表 10.2: 响应
GET /v1/scores
获取排行榜前 10 的用户
响应示例:
{
"data":[
{
"user_id": "user_id1",
"user_name": "alice",
"rank": 1,
"score": 976
},
{
"user_id": "user_id2",
"user_name": "bob",
"rank": 2,
"score": 965
}
],
"total": 10
}
GET /v1/scores/{:user_id}
获取指定用户排名。
| 字段 | 描述 |
|---|---|
| user_id | 我们要获取其排名的用户的ID |
表 10.3: 请求参数
响应示例:
{
"user_info": {
"user_id": "user5",
"score": 940,
"rank": 6,
}
}
高层设计
高层设计图,如图 10.2 所示。本设计中有两个服务。游戏服务,允许用户玩游戏;排行榜服务,创建并展示排行榜。
 图 10.2: 高层设计图
图 10.2: 高层设计图
-
玩家赢得游戏,客户端向游戏服务发送一个请求。
-
游戏服务确保胜利有效后,调用排行榜服务更新分数。
-
排行榜服务更新用户数据库中的分数。
-
玩家直接调用排行榜服务来获取排行榜数据,包括:
(a) 前10排行榜。
(b) 该玩家在排行榜的名次。
在确定这个设计方案之前,我们考虑了一些替代方案,但最终决定放弃。回顾并比较不同的方案,可能会有所帮助。
客户端是否直接和排行榜服务通信?
 图 10.3: 由谁设置排行榜分数
图 10.3: 由谁设置排行榜分数
在另一种设计中,分数由客户端设定。这种方案并不安全,因为它会受到中间人攻击[1],玩家可以通过代理随意更改分数。因此,我们需要在服务器端设置分数。
请注意,对于服务器授权的游戏(如在线扑克),客户端可能不需要明确调用游戏服务器来设置分数。游戏服务器会处理所有的游戏逻辑,它知道游戏何时结束,可以在没有客户端干预的情况下设置分数。
我们是否需要在游戏服务和排行榜服务之间建立消息队列?
这个问题的答案在很大程度上取决于游戏分数的使用方式。如果数据被用于其他地方或支持多种功能,那么如图 10.4 所示,将数据放在 Kafka 中可能会更有意义。这样,排行榜服务、分析服务、推送通知服务等多个消费者就可以使用相同的数据。当游戏是一款回合制或多人游戏时,我们需要通知其他玩家分数的更新情况,消息队列尤其重要。根据与面试官的对话,这并不是一个明确的需求,因此我们在设计中没有使用消息队列。
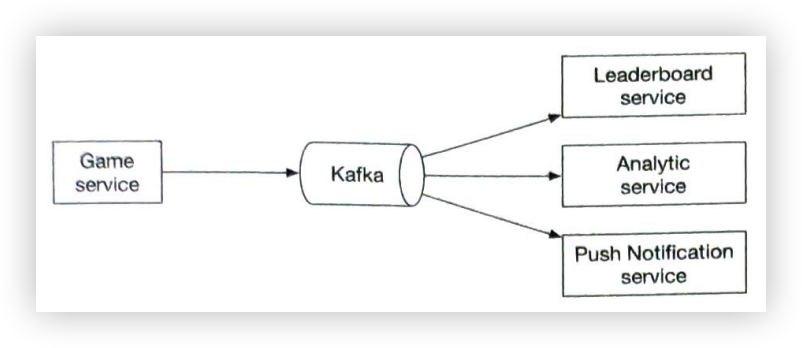 图 10.4: 游戏分数被多种服务使用
图 10.4: 游戏分数被多种服务使用
数据模型
系统的关键组件之一是排行榜存储。我们将讨论三种可能的解决方案:关系数据库、Redis 和 NoSQL(NoSQL解决方案将在本文的深入设计部分进行解释)。
关系数据库解决方案
译者注:关系数据库,英语原文 Realational database solution,也可以翻译为关系型数据库。
首先,让我们退一步,从最简单的解决方案开始。如果规模并不重要,我们只有几个用户,应该如何设计?
我们很可能会选择使用关系型数据库系统 (RDS) 来提供一个简单的排行榜解决方案。每个月的排行榜都可以用一个包含用户 ID 和分数列的数据库表来表示。当用户赢得一场比赛时,如果是新用户,则奖励 1 分,如果是老用户,则增加 1 分。为了确定用户在排行榜上的排名,我们将对表中的得分,从高到低进行排序。详情如下。
 图 10.5: 排行榜表
图 10.5: 排行榜表
实际上,排行榜表还包含其他信息,如 game_id、时间戳等。不过,如何查询和更新排行榜的基本逻辑是一样的。为简单起见,我们假设排行榜表中只存储了当前月份的排行榜数据。
用户赢得积分
 图 10.6: 用户赢得积分
图 10.6: 用户赢得积分
假设每次分数更新都以 1 为增量。如果用户在当月的排行榜中还没有条目,则第一次插入的内容:
INSERT INTO leaderboard (user_id, score) VALUES (‘mary1934’, 1);
对用户分数的更新:
UPDATE leaderboard set score=score + 1 where user_id='mary1934';
查询用户在排行榜上的排名
 图 10.7: 查询用户在排行榜上的排名
图 10.7: 查询用户在排行榜上的排名
要获取用户排名,我们将通过分数对排行榜表排序:
SELECT (@rownum := @rownum + 1) AS rank, user_id, score
FROM leaderboard
ORDER BY score DESC;
SQL查询的结果如下:
| rank | user_id | score |
|---|---|---|
| 1 | happy_tomato | 987 |
| 2 | mallow | 902 |
| 3 | smith | 870 |
| 4 | mary1934 | 850 |
表 10.4: 按分数排序的结果
当数据集较小时,这种解决方案还能奏效,但当数据行数达到数百万行时,查询速度就会变得非常慢。让我们来看看原因何在。
要确定用户的排名,我们需要将每个玩家,排序到排行榜上的正确位置,这样我们才能确定正确的排名。请记住,也可能有重复的分数,因此排名不仅仅是用户在列表中的位置。
当我们需要处理大量持续变化的信息时,SQL 数据库的性能并不理想。尝试对数百万行进行排序操作将需要 10 秒钟的时间,这对于所需的实时方法来说是不可接受的。由于数据是不断变化的,因此考虑使用缓存也是不可行的。
关系数据库在设计上,无法处理这种实时的高负载查询。如果以批量操作的方式进行,则可以使用 RDS,但这不符合为用户返回实时排名的需求。
我们可以做的一项优化是添加索引,并使用 LIMIT 语句限制要扫描的页面数。如下:
SELECT (@rownum := @rownum + 1) AS rank, user_id, score
FROM leaderboard
ORDER BY score DESC
LIMIT 10
然而,这种方法并不能很好地扩展。首先,查找用户排名的性能不高,因为它基本上需要通过表扫描来确定排名。其次,这种方法没有提供直接的解决方案,来确定不在排行榜顶端的用户的排名。
Redis 解决方案
我们希望找到一种解决方案,即使在数百万用户的情况下也能提供可预测的性能,并允许我们轻松访问常用的排行榜操作,而无需依赖复杂的数据库查询。
Redis 为我们的问题提供了一个潜在的解决方案。Redis 是一种支持键值对的内存数据存储。由于它在内存中工作,因此可以实现快速读写。Redis 有一种称为 sorted sets 的数据类型,非常适合解决排行榜系统设计问题。
什么是 sorted sets?
sorted sets 是一种类似于集合的数据类型。它的每个成员都与一个分数相关联。集合的成员必须是唯一的,但分数可以重复。分数用于按升序排列 sorted sets。
我们的排行榜用例完美地映射了 sorted sets。在底层,sorted sets 由两种数据结构实现:hashtab 哈希表和 skip list 跳表 [2]。哈希表将用户映射到分数,跳过列表将分数映射到用户。在 sorted sets 中,用户按分数排序。如图 10.8 所示,理解 sorted sets 的一个好方法是把它想象成一个带有分数和成员列的表格。该表按分数降序排序。
 图 10.8: 二月份的排行榜通过 sorted sets 表示
图 10.8: 二月份的排行榜通过 sorted sets 表示
在本章中,我们不会详述 sorted sets 的全部实现细节,但会介绍一些高层设计思路。
skip list 调表是一种可实现快速搜索的列表结构。它由基本排序链表和多级索引组成。让我们来看一个例子。在图 10.9 中,列表是一个已排序的单链表。插入、移除和查询操作的时间复杂度为 $O(n)$。
怎样才能让这些操作变得更快?其中一个办法就是像二分查找算法那样,快速找到中间节点。为了达到这个目的,我们增加了一个跳过其他节点的一级索引,然后又增加了一个跳过一级索引的其他节点的二级索引。我们会不断引入更多级索引,每一级索引都会跳过上一级索引中的每一个节点。当节点间的距离为 $({n \over 2}-1)$(其中为 n 为节点总数)时,我们将停止这种添加。如图 10.9 所示,当我们使用多级索引时,搜索数字 45 的速度会快很多。
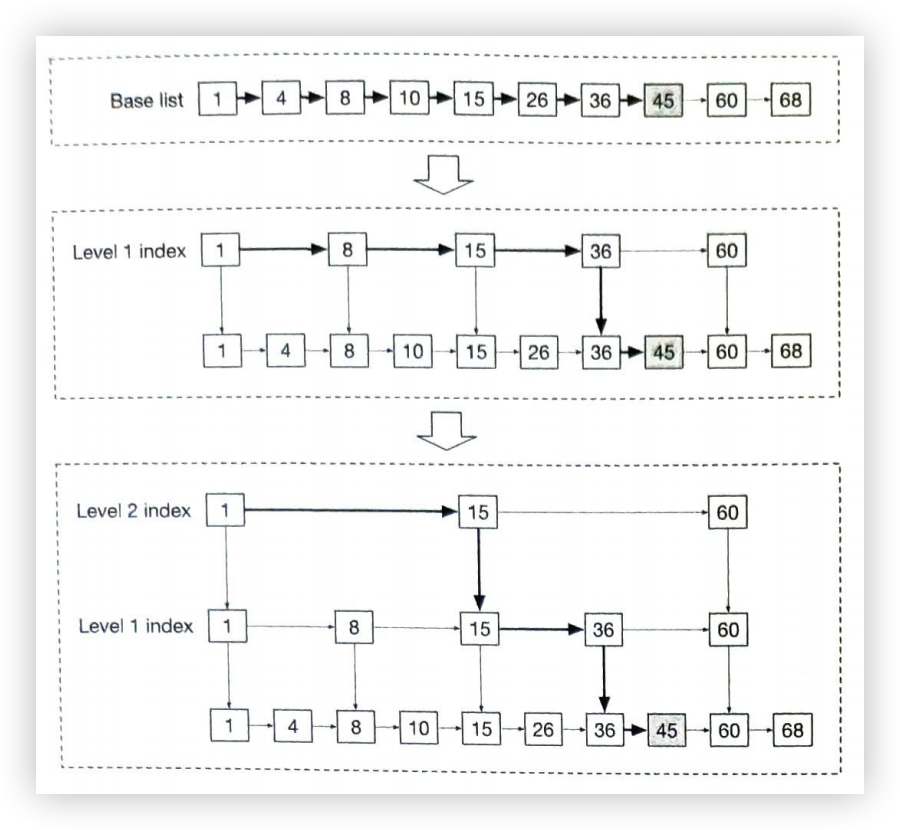 图 10.9: 跳表
图 10.9: 跳表
当数据集较小时,使用跳表对速度的提升并不明显。图 10.10 显示了一个有 5 层索引的表示例。在基本链表中,需要遍历 62 个节点才能到达正确的节点。而在跳表中,只需遍历 11 个节点 [3]。
 图 10.10: 带有 5 级索引的跳表
图 10.10: 带有 5 级索引的跳表
与关系数据库相比,sorted sets 的性能更高,因为在插入或更新时,每个元素都会自动按照正确的顺序定位,而且在 sorted sets 中进行添加或查找操作的复杂度是 $O\big(log(n)\big)$。
相比之下,要计算关系数据库中特定用户的排名,我们需要运行嵌套查询:
SELECT *,(SELECT COUNT(*) FROM leaderboard lb2
WHERE lb2.score >= lb1.score) RANK
FROM leaderboard lb1
WHERE lb1.user_id = {:user_id};
Redis sorted sets 实现
既然我们已经知道 sorted sets 的速度很快,那加下来,我们来看看通过 Redis 建立排行榜的具体操作 [4] [5] [6] [7]:
-
ZADD:如果用户尚不存在,则将其插入数据集。否则,更新该用户的分数。执行需要 $O\big(log(n)\big)$。
-
ZINCRBY:按指定的增量,递增用户的分数。如果用户不存在于集合中,则假定分数从 0 开始。执行需要 $O\big(log(n)\big)$ 的时间。
-
ZRANGE/ZREVRANGE:获取按分数排序的用户范围。我们可以指定顺序(range 与 revrange)、条目数和起始位置。这需要 $O\big(log(n)+m\big)$ 来执行,其中 m 是要获取的条目的数量(在我们的情况下通常较少),n 是 sorted sets 中条目的数量。
-
ZRANK/ZREVRANK:以对数的时间复杂度按升序/降序获取任何用户的位置。
sorted set 的工作流
- 用户得分
 图 10.11: 用户得分
图 10.11: 用户得分
我们每个月都会创建一个新的排行榜 sorted sets ,之前的 sorted sets 会被移至历史数据存储区。当用户赢得一场比赛时,他们会得到 1 分;因此我们会调用 ZINCRBY 将该用户在当月排行榜中的得分增加 1,或者将该用户添加到排行榜中(如果他们还没有在排行榜中的话)。ZINCRBY 的语法是:
ZINCRBY <key> <increment> <user>
下面的命令会在用户 mary1934 赢得比赛后为其增加一个积分。
ZINCRBY leaderboard_feb_2021 1 ‘mary1934’
- 用户获取全球排行榜前 10 名
 图 10.12: 用户获取全球排行榜前 10 名
图 10.12: 用户获取全球排行榜前 10 名
我们将调用 ZREVRANGE 以从高到低的顺序获取成员,因为我们想要最高分,并通过 WITHSCORES 属性确保同时返回每个用户的总分以及得分最高的用户集合。下面的命令将获取 2021 年 2 月排行榜上的前 10 名玩家。
ZREVRANGE leaderboard_feb_2021 0 9 WITHSCORES
返回的列表如下:
[(user2, score2),(user1, score1),(user5, score5)...]
- 用户希望获取自己在排行榜上的位置
 图 10.13: 获取用户在排行榜上的位置
图 10.13: 获取用户在排行榜上的位置
要获取用户在排行榜中的位置,我们将调用 ZREVRANK 来获取用户在排行榜中的排名。我们再次调用 rev 版本的命令,因为我们想把分数从高到低排序。
ZREVRANK leaderboard_feb_2021 'mary1934'
- 获取用户在排行榜中的相对位置,示例如图 10.14 所示。
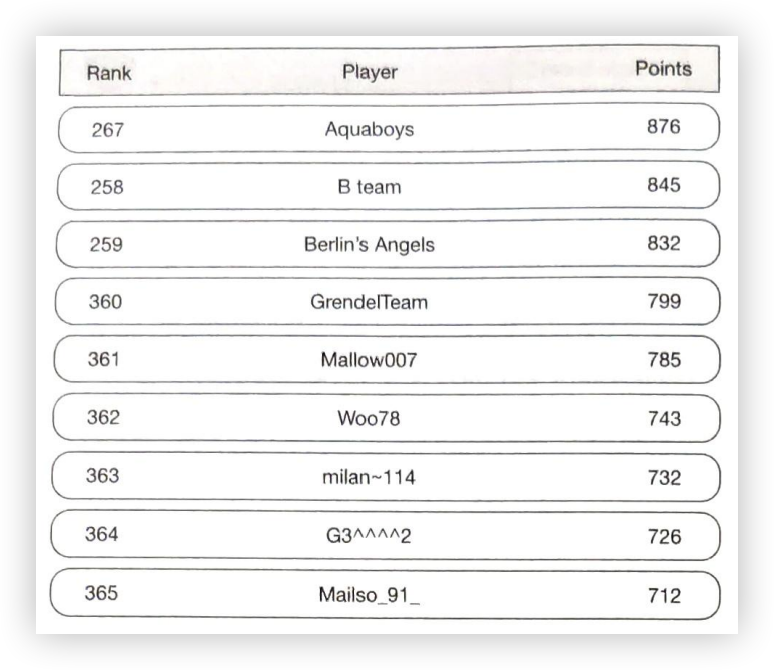 图 10.14: 获取排名前后的 4 个用户
图 10.14: 获取排名前后的 4 个用户
虽然这不是一个明确的要求,但我们可以利用 ZREVRANGE 和所需上下用户的人数,轻松获取用户的相对位置。例如,如果用户 Mallow007 的排名是 361,而我们想获取在其上下的 4 名用户,我们可以运行以下命令。
ZREVRANGE leaderboard_feb_2821 357 365
存储要求
我们至少需要存储用户 ID 和得分。最坏的情况是,所有 2500 万月活跃用户都至少赢过一场游戏,而且他们都在当月的排行榜上有记录。假设用户 ID 是 24 个字符的字符串,得分是 16 位整数(或 2 个字节),则每个排行榜条目需要 26 个字节的存储空间。假设最坏的情况是每个 MAU 有一个排行榜条目,那么我们将需要 26 个字节 x 25 百万字节 = 650 百万字节或约 650 MB 用于 Redis 缓存中的排行榜存储。即使我们将内存使用量增加一倍,以考虑到跳表和 sorted sets 的开销,一台现代 Redis 服务器也足以存储这些数据。
另一个需要考虑的相关因素是 CPU 和 I/O 使用率。我们通过回溯估算得出的峰值 QPS 为 2500 次更新。这完全在单个 Redis 服务器的性能范围之内。
Redis 缓存的一个问题是持久性,因为 Redis 节点可能会出现故障。幸运的是,Redis 确实支持持久性,但从磁盘重启大型 Redis 实例的速度很慢。通常情况下,Redis 会配置一个读取副本,当主实例发生故障时,读取副本会被升级,并附加一个新的读取副本。
此外,我们还需要在 MySQL 等关系数据库中建立两个支持表(用户表和点表)。用户表将存储用户 ID 和用户显示名(在实际应用中,这将包含更多数据)。积分表将包含用户 ID、得分和赢得比赛的时间戳。这可用于其他游戏功能,如游戏历史,也可用于在基础设施发生故障时重新创建 Redis 排行榜。
作为一个小的性能优化,为用户详细信息创建一个额外的缓存可能是有意义的,因为前 10 名玩家的检索频率最高。这并不会产生大量数据。
深入设计
既然我们已经讨论了高层设计,下面就让我们深入探讨一下:
- 是否使用云提供商
- 服务管理
- 使用 AWS 等云服务
- Redis 扩展
- 备选方案:NoSQL
- 其他考虑因素
是否使用云服务
根据现有的基础设施,我们通常有两种部署解决方案的选择。让我们分别来看一看。
服务管理
在这种方法中,我们将每月创建一个排行榜 sorted sets ,以存储该期间的排行榜数据。sorted sets 存储用户和分数信息。用户的其他详细信息(如姓名和个人资料图片)则存储在 MySQL 数据库中。在获取排行榜时,除了排行榜数据外,API 服务器还会查询数据库,以获取相应的用户名和个人资料图像,并显示在排行榜上。如果长期这样做效率太低,我们可以缓存前 10 名玩家的用户详细信息。设计如图 10.15 所示。
 图 10.15: 服务管理
图 10.15: 服务管理
使用云服务
第二种方法是利用云基础设施。在本节中,我们假定我们现有的基础设施是建立在 AWS 上的,因此在云上建立排行榜是自然而然的事情。我们将在本设计中使用两项主要的 AWS 技术:亚马逊 API 网关和 AWS Lambda 函数 [8]。亚马逊 API 网关提供了一种定义 RESTful API 的 HTTP 端点并将其连接到任何后端服务的方法。我们用它来连接 AWS lambda 函数。表 10.5 显示了有源 API 和 Lambda 函数之间的映射。
| APIs | Lambda 函数 |
|---|---|
| GET /v1/scores | LeaderboardFetchTop10 |
| GET /v1/scores/{:user_id} | LeaderboardFetchPlayerRank |
| POST /v1/scores | LeaderboardUpdateScore |
表 10.5: Lambda 函数
AWS Lambda 是最流行的无服务器计算平台之一。它允许我们运行代码,而无需自己配置或管理服务器。它只在需要时运行,并会根据流量自动扩展。无服务器是云服务领域最热门的话题之一,所有主要的云服务提供商都支持它。例如,Google Cloud 拥有 Google Cloud Functions [9],Microsoft 将其产品命名为 Microsoft Azure Functions [10]。
从高层来看,我们的游戏会调用亚马逊 API 网关,然后再调用相应的 lambda 函数。我们将使用 AWS Lambda 函数在存储层(Redis 和 MySQL)上调用相应的命令,将结果返回给 API Gateway,然后再返回给应用程序。
我们可以利用 Lambda 函数来执行所需的查询,而无需启动服务器实例。AWS 支持可从 Lambda 函数调用的 Redis 客户端。这还允许根据 DAU 增长的需要进行自动扩展。用户得分和检索排行榜的设计图如下所示:
示例1:得分
 图 10.16: 得分
图 10.16: 得分
示例2:检索排行榜
 图 10.17: 检索排行榜
图 10.17: 检索排行榜
Lambdas 非常出色,因为它是一种无服务器方法,基础设施会根据需要自动扩展功能。这意味着我们无需管理扩展、环境设置和维护。因此,如果我们从头开始构建游戏,我们建议使用无服务器方法。
Redis 扩展
在 DAU 为 500 万的情况下,从存储和 QPS 的角度来看,我们只需使用一个 Redis 缓存即可。但是,假设我们有 5 亿 DAU,这是我们原始规模的 100 倍。现在,在最坏的情况下,我们的排行榜规模会增加到 65 GB(650MB x 100),而 QPS 则会增加到每秒 250,00(2,500 x 100)次查询。这就需要采用分片解决方案。
译者注:这种计算方法,只是从存储的角度,实际业务中,我们还需要考虑 Redis 的热 Key 和 大 Key 问题喔。
数据分片
我们考虑用以下两种方式之一进行分片:固定分片或散列分片。
固定分片 了解固定分区的一种方法是查看排行榜上积分的总体范围。假设一个月内赢得的分数从 1 到 1000 不等,我们按范围对数据进行分割。例如,我们可以有 10 个分区,每个分区有 100 个分数范围(例如,1 ~ 100,101 ~ 200,201 ~ 300,...),如图 10.18 所示。
 图 10.18: 固定分片
图 10.18: 固定分片
为此,我们要确保排行榜上的分数分布均匀。否则,我们就需要调整每个分区的分数范围,以确保分数分布相对均匀。在这种方法中,我们自己在应用程序代码中对数据进行分片。
在插入或更新用户分数时,我们需要知道用户所在的分区。我们可以从 MySQL 数据库中计算出用户当前的得分。这种方法可行,但性能更好的方法是创建二级缓存来存储用户 ID 到分数的映射。当用户提高分数并在分片之间移动时,我们需要小心。在这种情况下,我们需要将用户从当前分片移除,并将其转移到新的分片。
要获取排行榜中的前 10 名选手,我们需要从得分最高的分片(sorted sets)中获取前 10 名选手。在图 10.18 中,得分[901, 1000]的最后一个分片包含了前 10 名选手。
要获取用户的排名,我们需要计算用户在当前分片内的排名(本地排名),以及所有分配内分数较高的玩家总数。请注意,可以通过运行 info keyspace 命令 $O(1)$ 的获取分区内玩家的总数 [11]。
哈希分片
第二种方法是使用 Redis 集群,如果分数非常集中或成块,这种方法就比较理想。Redis 集群提供了一种在多个 Redis 节点间自动分片的方法。它使用的不是一致散列,而是另一种形式的分片,即每个键都是散列槽的一部分。哈希槽有 16384 个 [12],我们可以通过 CRC16(key) %16384 [13] 来计算给定密钥的哈希槽。这样我们就可以用图 10.19 的方法,我们有 3 个节点,其中:
- 第一个节点包含哈希槽 [0,5500]。
- 第二个节点包含哈希槽 [5501, 11000]。
- 第三个节点包含哈希槽 [11001, 16383]。
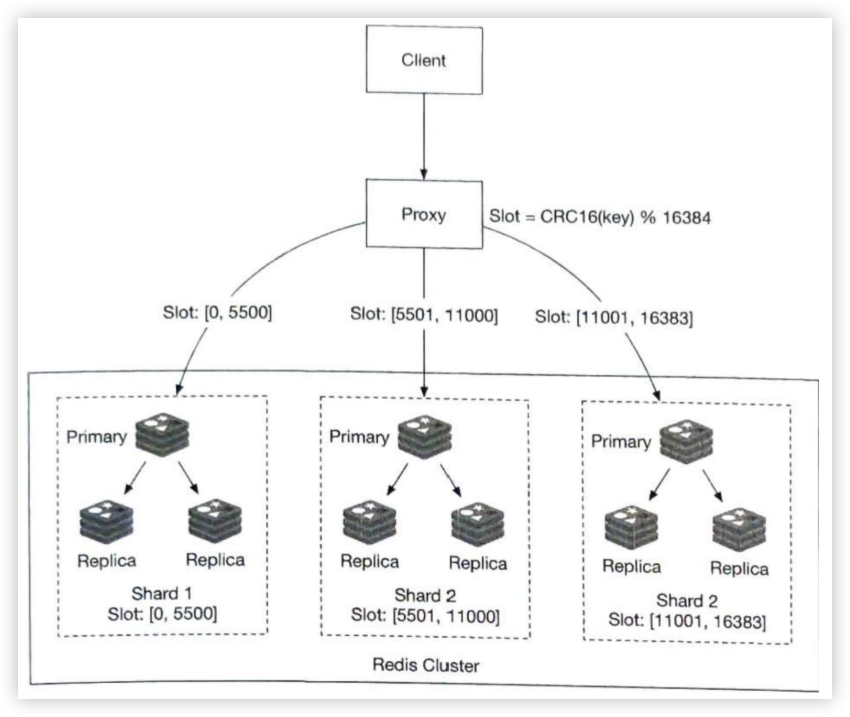 图 10.19: 哈希分片
图 10.19: 哈希分片
更新只需改变用户在相应分块中的得分(由 CRC16(key) %16384 决定)。检索排行榜上的前 10 名玩家则更为复杂。我们需要收集每个分区的前 10 名玩家,并让应用程序对数据进行排序。具体示例如图 10.20 所示。这些查询可以并行处理,以减少延迟。
 图 10.20: 分散收集
图 10.20: 分散收集
这种方法有一些局限性:
- 当我们需要在排行榜上返回顶部 k 个结果(其中 k 是一个非常大的数字)时,延迟会很高,因为每个分片都会返回大量条目并需要进行排序。
- 如果有很多分片,延迟就会很高,因为查询必须等待最慢的分片。
- 这种方法的另一个问题是,它没有为确定特定用户的排名提供直接的解决方案。
因此,我们倾向于第一种方案:固定分片。
确定 Redis 节点的大小
在确定 Redis 节点的大小时,需要考虑多个方面 [14]。写入量大的应用程序需要更多可用内存,因为我们需要能够容纳所有写入,以便在发生故障时创建快照。为安全起见,应为写入量大的应用程序分配两倍的内存。
备选方案:NoSQL
一种替代解决方案是考虑使用 NoSQL 数据库。我们应该选择什么样的 NoSQL 数据库呢?理想情况下,我们希望选择具备以下特性的 NoSQL 数据库:
- 为写操作进行了优化。
- 能够在分区内根据得分高效地排序项目。
NoSQL 数据库,如 Amazon 的 DynamoDB [16]、Cassandra 或 MongoDB 都是不错的选择。在本章中,我们以 DynamoDB 为例。DynamoDB 是一种完全托管的 NoSQL 数据库,提供可靠的性能和卓越的可扩展性。为了高效地访问除主键以外的其他属性,我们可以在 DynamoDB 中使用全局二级索引 [17]。全局二级索引包含从父表选择的属性,但它们以不同的主键方式组织起来。我们来看一个例子。
更新后的系统架构如图 10.21 所示。Redis 和 MySQL 被 DynamoDB 替代。
 图 10.21: DynamoDB 解决方案
图 10.21: DynamoDB 解决方案
假设我们为国际象棋游戏设计排行榜,我们的初始表如图 10.22 所示。这是排行榜视图和用户表的非规范化视图,包含渲染排行榜所需的所有数据。
 图 10.22: 排行榜和用户表的非规范化视图
图 10.22: 排行榜和用户表的非规范化视图
此表结构可用,但无法很好地扩展。随着添加更多行,我们必须扫描整个表以找到最高分项。
译者注:原文 PDF 为扫描版,有部分内容不全,我联系了文章上下文进行补全。
为了避免线性扫描,我们需要添加索引。我们的第一种尝试是使用 year-month 作为分区键,并使用 score 作为排序键,如图 10.23 所示。
 图 10.23: 分区键和排序键
图 10.23: 分区键和排序键
在高负载下,这种设计会遇到问题。DynamoDB 使用一致性哈希(consistent hashing)将数据分布到多个节点中。每个数据项基于其分区键被映射到对应的节点。
在上述表设计(图 10.23)中,所有最近月份的数据都会集中在同一个分区,从而形成“热点分区”(hot partition)。我们该如何解决这个问题?
一种方法是将数据拆分为多个分区,并在分区键后附加一个分区编号(例如 user_id % n,其中 n 为分区数)。这种模式被称为写分片(write sharding)。它会增加读写操作的复杂性,因此需要慎重考虑。
需要回答的关键问题是,我们应该使用多少个分区?这取决于写入量或 DAU(每日活跃用户数量)。重要的是要确保负载可以均匀分布在多个分区上,从而减少读操作的复杂度。
由于同一月份的数据会分布在多个分区中,要读取给定月份的数据,必须查询所有分区的结果,这增加了读操作的复杂性。
更新后的分区键设计像这样:game_name#{year-month}#p{partition_number}。这代表了更新后的表结构。
 图 10.24: 更新分区键
图 10.24: 更新分区键
全局二级索引使用 game_name#{year-month}#p{partition_number} 作为分区键,使用 score 作为排序键。最终我们得到的是 n 个分区,每个分区内部都是排序好的(局部排序)。假设我们有 3 个分区,那么为了获取前 10 名排行榜,我们会使用之前提到的"scatter-gather"方法。我们会在每个分区中获取前 10 个结果(这是"scatter"部分),然后让应用程序对所有分区的结果进行排序(这是"gather"部分)。如图 10.25 所示。
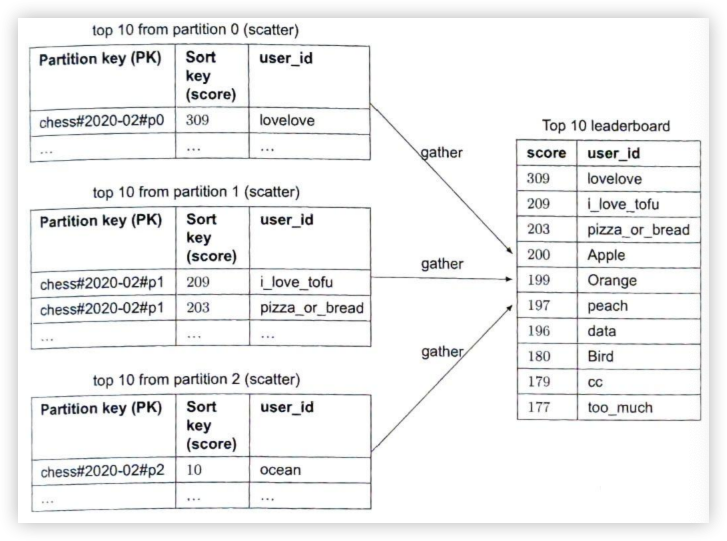 图 10.25: Scatter-gather
图 10.25: Scatter-gather
我们如何决定分区数量?这需要仔细的基准测试。更多的分区会减少每个分区的负载,但也增加了复杂性,因为我们需要跨更多分区进行 scatter 操作来构建最终的排行榜。通过基准测试,我们可以更清楚地看到这种权衡。
然而,类似于之前提到的 Redis 分区方案,这种方法并不能直接得到用户的准确排名。但是,我们可以获得用户位置的百分位数,这在实际应用中可能已经足够好了。在现实中,告诉玩家他们在前 10-20% 可能比显示具体排名(如1,200,001)更好。因此,如果规模大到需要分片,我们可以假设所有分片的分数分布大致相同。如果这个假设成立,我们可以用一个定时任务来分析每个分片的分数分布,并缓存结果。
结果会是这样的: 第 10 百分位 = 分数 < 100 第 20 百分位 = 分数 < 500 ... 第 90 百分位 = 分数 < 6500
然后我们可以快速返回用户的相对排名(比如第 90 百分位)。
第4步 - 总结
在本章中,我们创建了一个支持百万 DAU 的实时游戏排行榜解决方案。我们探讨了使用 MySQL 数据库的直接方案,但因为它无法扩展到百万用户而放弃了这种方法。然后我们使用 Redis 有序集合设计了排行榜。我们还通过在不同 Redis 缓存之间使用分片来将解决方案扩展到 5 亿 DAU。我们还提出了一个替代的 NoSQL 解决方案。
如果在面试最后还有额外时间,你可以讨论以下几个话题:
更快的检索和打破相同排名
Redis 哈希表提供了字符串字段和值之间的映射。我们可以利用哈希实现两个用例:
- 存储用户 ID 到用户对象的映射,以便在排行榜上显示。这比从数据库获取用户对象更快。
- 在两个玩家分数相同的情况下,我们可以基于谁先获得该分数来对用户进行排名。当我们增加用户分数时,我们还可以存储用户ID 到最近获胜游戏时间戳的映射。在平局情况下,较早的时间戳排名更高。
系统故障恢复
Redis 集群可能会遇到大规模故障。基于上述设计,我们可以创建一个脚本,利用 MySQL 数据库中记录的每次用户获胜时的时间戳。我们可以遍历每个用户的所有记录,并为每个用户的每条记录调用一次 ZINCRBY 命令。这样,在发生大规模故障时,我们可以在离线状态下重建排行榜。
恭喜你能坚持到这里!给自己一个赞,干得漂亮!
章节总结
参考资料
[1] Man-in-the-middle attack. https://en.wikipedia.org/wiki/Man-in-the-middle_attack.
[2] Redis Sorted Set source code. https://github.com/redis/redis/blob/unstable/src/t_zset.c.
[3] Geekbang. https://static001.geekbang.org/resource/image/46/a9/46d283cd82c987153b3fe0c76dfba8a9.jpg.
[4] Building real-time Leaderboard with Redis. https://medium.com/@sandeep4.verma/building-real-time-leaderboard-with-redis-82c98aa47b9f.
[5] Build a real-time gaming leaderboard with Amazon ElastiCache for Redis. https://aws.amazon.com/blogs/database/building-a-real-time-gaming-leaderboard-with-amazon-elasticache-for-redis.
[6] How we created a real-time Leaderboard for a million Users. https://levelup.gitconnected.com/how-we-created-a-real-time-leaderboard-for-a-million-users-555aaa3cef7b.
[7] Leaderboards. https://redislabs.com/solutions/use-cases/leaderboards/.
[8] Lambda. https://aws.amazon.com/lambda/.
[9] Google Cloud Functions. https://cloud.google.com/functions.
[10] Azure Functions. https://azure.microsoft.com/en-us/services/functions/.
[11] Info command. https://redis.io/commands/INFO.
[12] Why redis cluster only have 16384 slots. https://stackoverflow.com/questions/3620532/why-redis-cluster-only-have-16384-slots.
[13] Cyclic redundancy check. https://en.wikipedia.org/wiki/Cyclic_redundancy_check.
[14] Choosing your node size. https://docs.aws.amazon.com/AmazonElastiCache/latest/red-ug/nodes-select-size.html.
[15] How fast is Redis? https://redis.io/topics/benchmarks.
[16] Using Global Secondary Indexes in DynamoDB. https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/GSI.html.
[17] Leaderboard & Write Sharding. https://www.dynamodbguide.com/leaderboard-write-sharding/.
第11章:支付系统
数字钱包
支付平台通常为客户提供数字钱包服务,这样他们可以将钱存入钱包并在以后使用。例如,你可以从银行卡向数字钱包充值,当你在线购买产品时,可以选择使用钱包中的钱进行支付。

花钱并不是数字钱包提供的唯一功能。对于像 PayPal 这样的支付平台,我们可以直接将钱转移到同一支付平台上其他人的钱包中。与银行间转账相比,数字钱包之间的直接转账速度更快,最重要的是,通常不会收取额外费用。
假设我们被要求设计一个支持跨钱包余额转账操作的数字钱包应用程序的后端。在面试开始时,我们会通过澄清问题来确定需求。
第一步 - 理解问题并确定设计范围
候选人: 我们是否只需要关注两个数字钱包之间的余额转账操作?是否需要考虑其他功能?
面试官: 我们只关注余额转账操作。
候选人: 系统需要支持每秒多少笔交易(TPS)?
面试官: 假设需要支持 1,000,000 TPS。
候选人: 数字钱包对正确性有严格要求。我们可以假设事务性保证 [1] 足够吗?
面试官: 听起来不错。
候选人: 我们需要证明正确性吗?
面试官: 这是个好问题。正确性通常只能在交易完成后验证。一种验证方法是将我们的内部记录与银行的对账单进行比较。对账的局限性在于它只能显示差异,无法说明差异是如何产生的。因此,我们希望设计一个具有可重现性的系统,这意味着我们始终可以通过从最开始重放数据来重建历史余额。
候选人: 我们可以假设可用性要求为 99.99% 吗?
面试官: 听起来不错。
候选人: 是否需要考虑外汇?
面试官: 不需要,这超出了范围。
总结
总结一下,我们的数字钱包需要支持以下内容:
- 支持两个数字钱包之间的余额转账操作。
- 支持 1,000,000 TPS。
- 可靠性至少为 99.99%。
- 支持事务。
- 支持可重现性。
粗略估算
当我们谈论 TPS 时,意味着将使用事务性数据库。如今,运行在典型数据中心节点上的关系型数据库可以支持每秒几千笔事务。例如,参考文献 [2] 包含一些流行的事务性数据库服务器的性能基准。假设一个数据库节点可以支持 1,000 TPS。为了达到 100 万 TPS,我们需要 1,000 个数据库节点。
然而,这个计算略有偏差。每笔转账命令需要两个操作:从一个账户扣款和向另一个账户存款。为了支持每秒 100 万笔转账,系统实际上需要处理高达 200 万 TPS,这意味着我们需要 2,000 个节点。
| 单节点 TPS | 节点数量 |
|---|---|
| 100 | 20,000 |
| 1,000 | 2,000 |
| 10,000 | 200 |
表 12.1: 单节点 TPS 与节点数量的映射
第二步 - 提出高层设计并获得认可
在本节中,我们将讨论以下内容:
- API 设计
- 三种高层设计
- 简单的内存解决方案
- 基于数据库的分布式事务解决方案
- 具有可重现性的事件溯源解决方案
API 设计
我们将使用 RESTful API 规范。对于这次面试,我们只需要支持一个 API:
| API | 详情 |
|---|---|
| POST /v1/wallet/balance_transfer | 将余额从一个钱包转移到另一个钱包 |
请求参数如下:
| 字段 | 描述 | 类型 |
|---|---|---|
| from_account | 扣款账户 | string |
| to_account | 收款账户 | string |
| amount | 金额 | string |
| currency | 货币类型 | string (ISO 4217[3]) |
| transaction_id | 用于去重的 ID | uuid |
示例响应体:
{
"Status": "success",
"Transaction_id": "81589980-2664-11ec-9621-0242ac130002"
}
值得一提的是,“amount”字段的数据类型是“string”,而不是“double”。我们在第 11 章支付系统中解释了原因([第 320 页](./CHAPTER 11:Payment System.md#APIs-for-payment-service))。
在实践中,许多人仍然选择浮点数或双精度数表示,因为它几乎被所有编程语言和数据库支持。只要我们了解精度丢失的潜在风险,这是一个合适的选择。
内存分片解决方案
钱包应用程序为每个用户账户维护一个账户余额。表示这种 <用户, 余额> 关系的一个良好数据结构是映射(map),也称为哈希表(hash table)或键值存储(key-value store)。
对于内存存储,一个流行的选择是 Redis。一个 Redis 节点不足以处理 100 万 TPS。我们需要建立一个 Redis 节点集群,并将用户账户均匀分布在其中。这个过程称为分区或分片。
为了将键值数据分布在 n 个分区中,我们可以计算键的哈希值并将其除以 n。余数就是分区的目标。以下伪代码展示了分片过程:
String accountID = "A";
Int partitionNumber = 7;
Int myPartition = accountID.hashCode() % partitionNumber;
分区数量和所有 Redis 节点的地址可以存储在一个集中的地方。我们可以使用 ZooKeeper [4] 作为高可用性配置存储解决方案。
该解决方案的最后一个组件是处理转账命令的服务。我们称之为钱包服务,它有几个关键职责。
- 接收转账命令
- 验证转账命令
- 如果命令有效,它会更新参与转账的两个用户的账户余额。在集群中,账户余额可能位于不同的 Redis 节点中
钱包服务是无状态的。它很容易水平扩展。图 12.3 展示了内存解决方案。
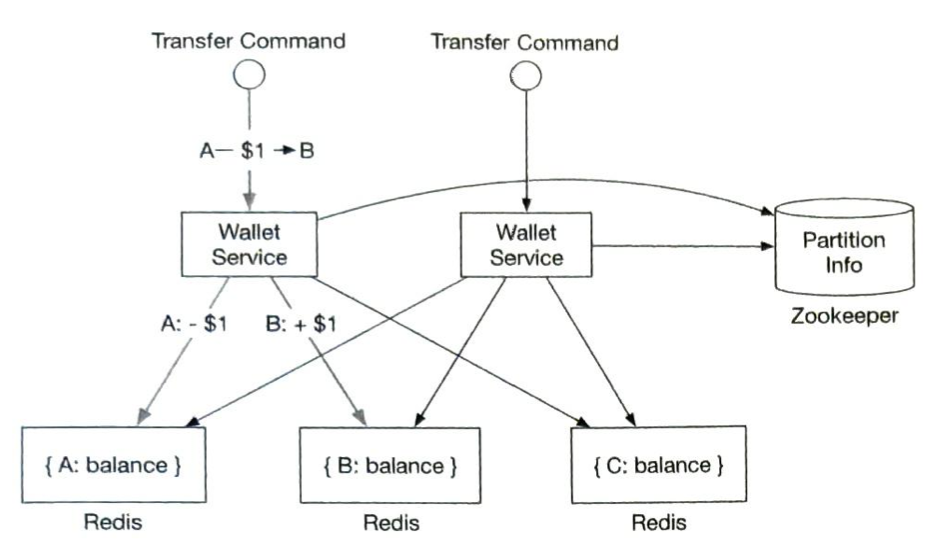
在这个例子中,我们有 3 个 Redis 节点。有三个客户端 A、B 和 C。他们的账户余额均匀分布在这三个 Redis 节点中。这个例子中有两个钱包服务节点处理余额转账请求。当其中一个钱包服务节点收到将 1 美元从客户端 A 转移到客户端 B 的转账命令时,它会向两个 Redis 节点发出两个命令。对于包含客户端 A 账户的 Redis 节点,钱包服务从账户中扣除 1 美元。对于客户端 B,钱包服务向账户中添加 1 美元。
候选人: 在这个设计中,账户余额分布在多个 Redis 节点中。ZooKeeper 用于维护分片信息。无状态的钱包服务使用分片信息定位客户端的 Redis 节点并相应地更新账户余额。
面试官: 这个设计可行,但它不符合我们的正确性要求。钱包服务为每笔转账更新两个 Redis 节点。无法保证两个更新都会成功。例如,如果钱包服务节点在第一次更新完成后但在第二次更新完成之前崩溃,将导致转账不完整。这两个更新需要在一个原子事务中完成。
分布式事务
数据库分片
我们如何使对两个不同存储节点的更新具有原子性?第一步是将每个 Redis 节点替换为事务型关系数据库节点。图 12.4 展示了这种架构。这次,客户端 A、B 和 C 被分区到 3 个关系数据库中,而不是 3 个 Redis 节点中。
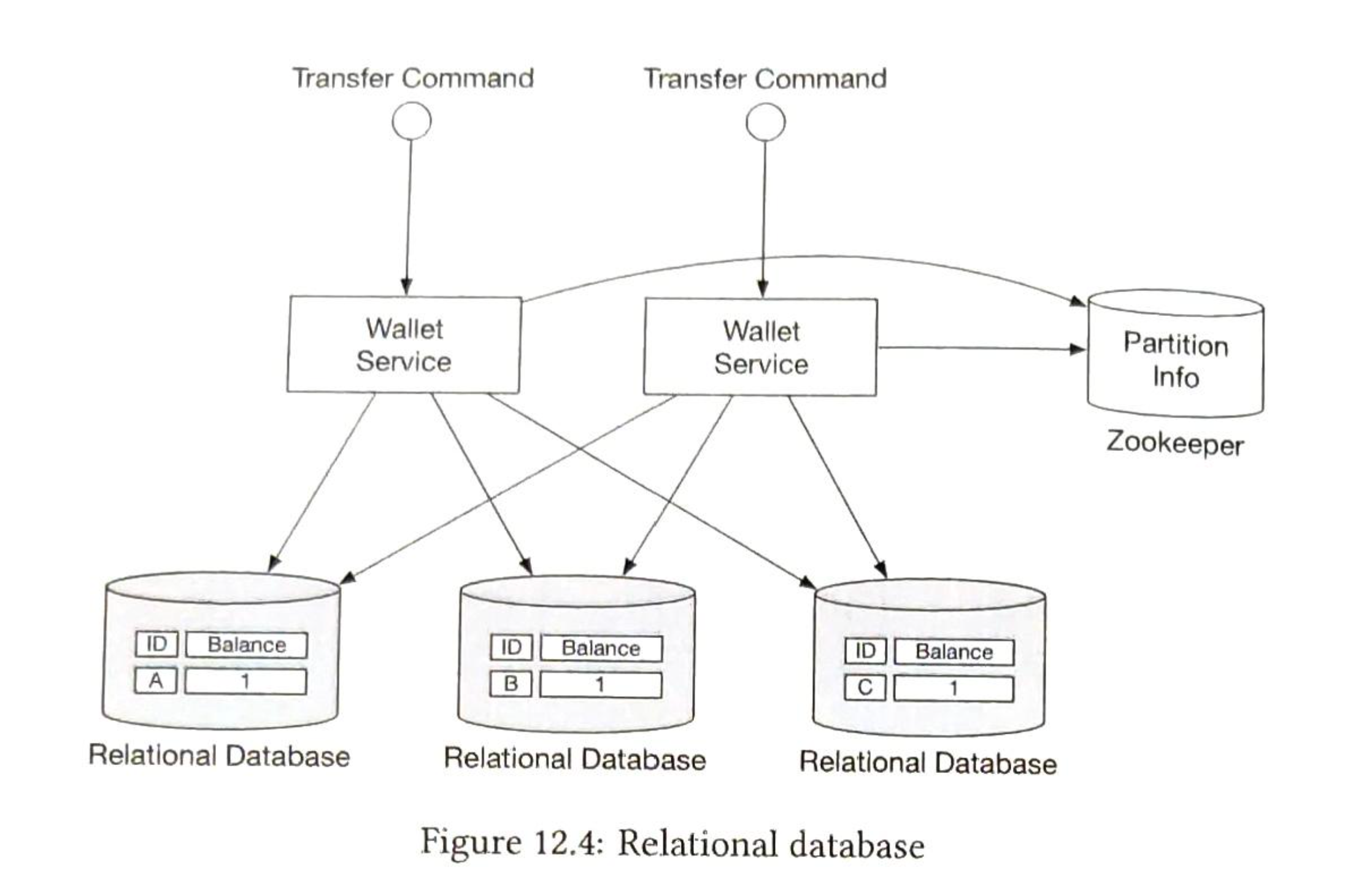
使用事务性数据库只能解决部分问题。正如上一节提到的,一个转账命令很可能需要更新两个不同数据库中的两个账户。无法保证两个更新操作会同时处理。如果钱包服务在更新第一个账户余额后立即重启,我们如何确保第二个账户也会被更新?
分布式事务:两阶段提交
在分布式系统中,一个事务可能涉及多个节点上的多个进程。为了使事务具有原子性,分布式事务可能是答案。有两种实现分布式事务的方式:低级别解决方案和高级别解决方案。我们将分别探讨它们。
低级别解决方案依赖于数据库本身。最常用的算法称为两阶段提交(2PC)。顾名思义,它有两个阶段,如图 12.5 所示。
![Figure 12.5: 两阶段提交(来源 [5])](Volume2/../images/v2/chapter12/Figure_12.5.png)
- 协调者(在我们的例子中是钱包服务)像往常一样在多个数据库上执行读写操作。如图 12.5 所示,数据库 A 和 C 都被锁定。
- 当应用程序准备提交事务时,协调者会要求所有数据库准备事务。
- 在第二阶段,协调者收集所有数据库的回复并执行以下操作: (a) 如果所有数据库都回复“是”,协调者会要求所有数据库提交它们收到的事务。 (b) 如果有任何一个数据库回复“否”,协调者会要求所有数据库中止事务。
这是一个低级别解决方案,因为准备步骤需要对数据库事务进行特殊修改。例如,有一个 X/Open XA [6] 标准,用于协调异构数据库以实现 2PC。2PC 的最大问题是性能不佳,因为在等待其他节点的消息时,锁可能会被长时间持有。2PC 的另一个问题是协调者可能成为单点故障,如图 12.6 所示。
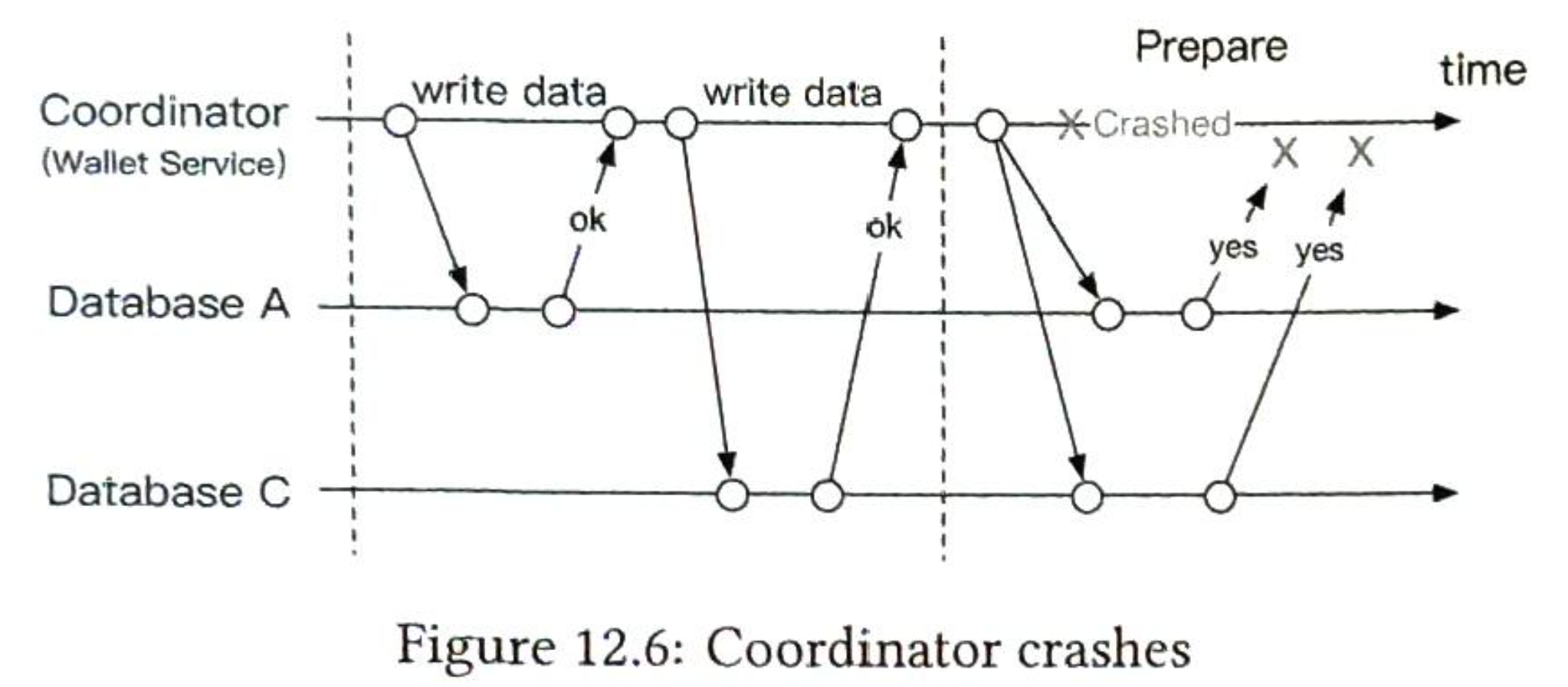
分布式事务:尝试-确认/取消(TC/C)
TC/C 是一种补偿性事务 [7],分为两个步骤:
- 在第一阶段,协调者要求所有数据库为事务预留资源。
- 在第二阶段,协调者收集所有数据库的回复: (a) 如果所有数据库都回复“是”,协调者要求所有数据库确认操作,即尝试-确认过程。 (b) 如果有任何一个数据库回复“否”,协调者要求所有数据库取消操作,即尝试-取消过程。
需要注意的是,2PC 的两个阶段被包装在同一个事务中,而在 TC/C 中,每个阶段都是一个独立的事务。
TC/C 示例
通过一个实际例子更容易解释 TC/C 的工作原理。假设我们想从账户 A 转账 1 美元到账户 C。表 12.2 总结了 TC/C 在每个阶段的执行情况。
| 阶段 | 操作 | 账户 A 的余额变化 | 账户 C 的余额变化 |
|---|---|---|---|
| 1 | 尝试 | -$1 | 无操作 |
| 2 | 确认 | 无操作 | +$1 |
| 取消 | +$1 | 无操作 |
表 12.2: TC/C 示例
假设钱包服务是 TC/C 的协调者。在分布式事务开始时,账户 A 的余额为 1 美元,账户 C 的余额为 0 美元。
第一阶段:尝试
在尝试阶段,钱包服务(作为协调者)向两个数据库发送两个事务命令:
- 对于包含账户 A 的数据库,协调者启动一个本地事务,将账户 A 的余额减少 1 美元。
- 对于包含账户 C 的数据库,协调者发送一个无操作(NOP)命令。数据库对 NOP 命令不执行任何操作,并始终向协调者回复成功消息。
尝试阶段如图 12.7 所示。粗线表示事务持有的锁。
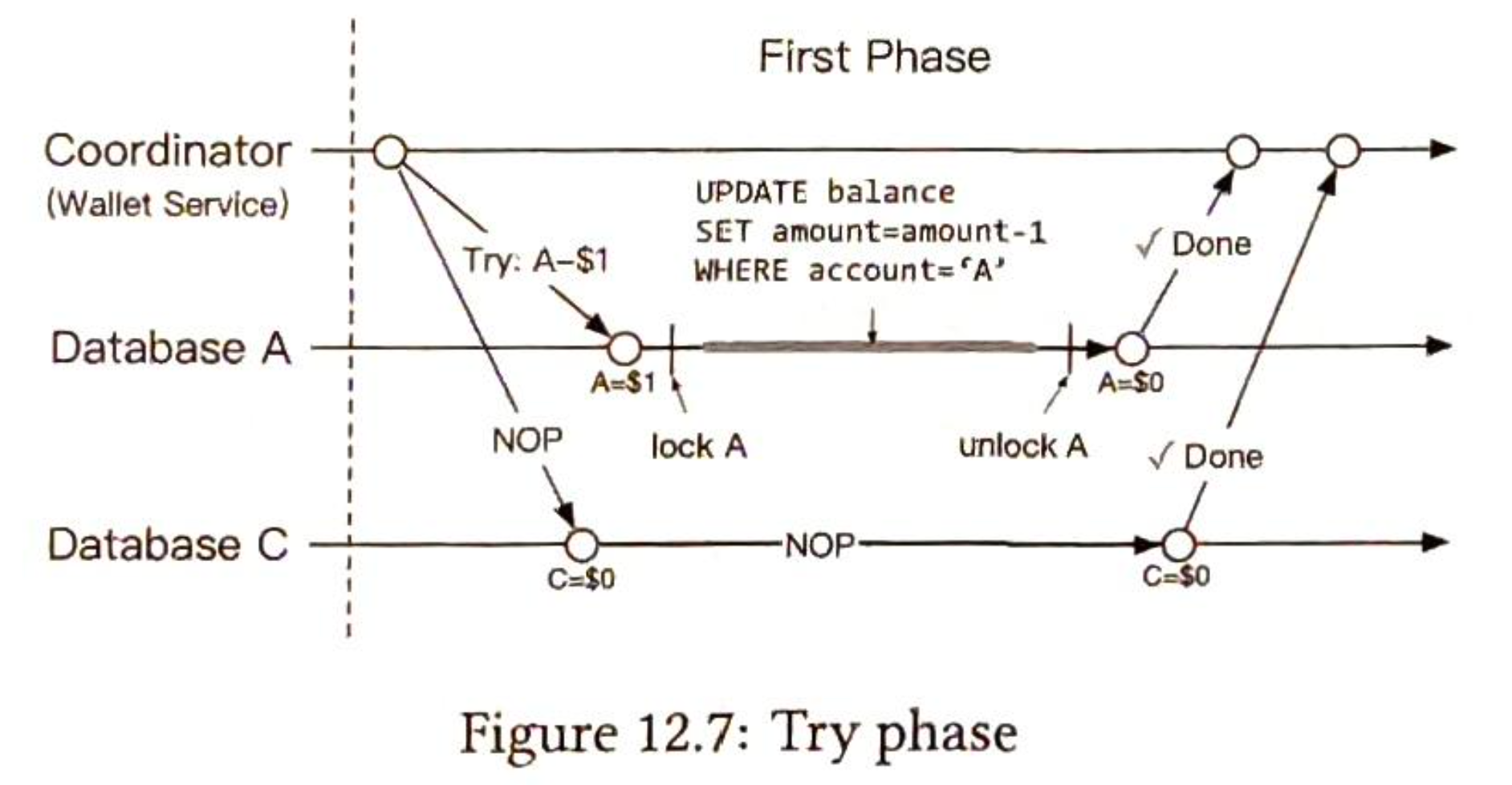
第二阶段:确认
如果两个数据库都回复“是”,钱包服务进入确认阶段。 账户 A 的余额已在第一阶段更新,钱包服务无需在此阶段更改其余额。然而,账户 C 在第一阶段尚未收到来自账户 A 的 1 美元。在确认阶段,钱包服务需要将 1 美元添加到账户 C 的余额中。
确认过程如图 12.8 所示。
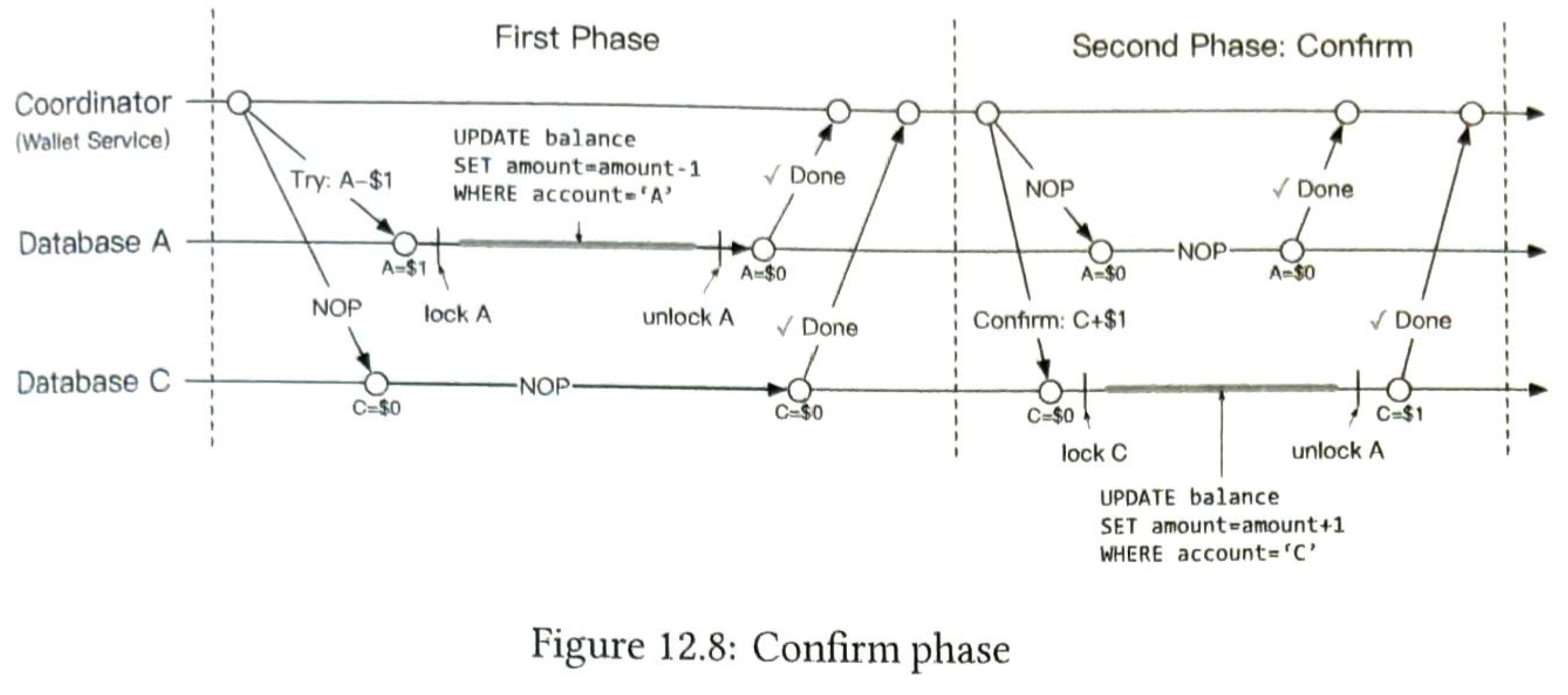
第二阶段:取消
如果尝试阶段失败怎么办?在上面的例子中,我们假设账户 C 的 NOP 操作始终成功,但在实践中它可能会失败。例如,账户 C 可能是一个非法账户,监管机构禁止资金流入或流出该账户。在这种情况下,分布式事务必须取消,我们需要清理。
由于账户 A 的余额已在尝试阶段的事务中更新,钱包服务无法取消已完成的事务。它所能做的是启动另一个事务,以撤销尝试阶段事务的效果,即将 1 美元加回账户 A。
由于账户 C 在尝试阶段未被更新,钱包服务只需向账户 C 的数据库发送一个 NOP 操作。
取消过程如图 12.9 所示。
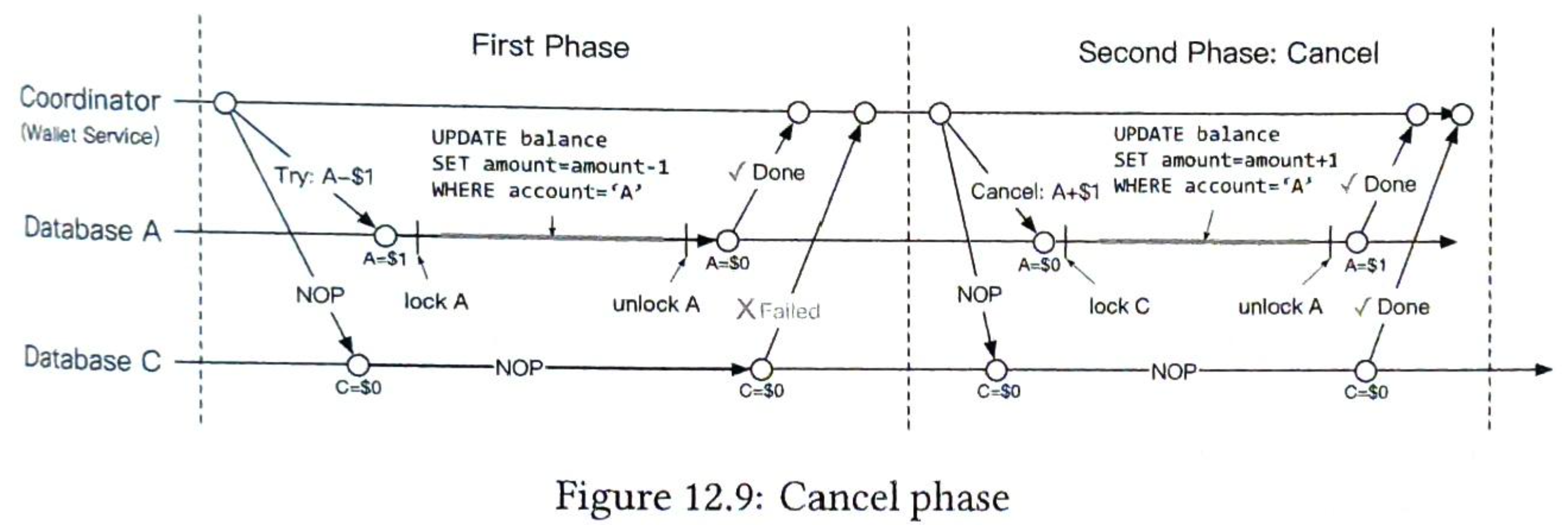
2PC 与 TC/C 的比较
表 12.3 显示 2PC 和 TC/C 有许多相似之处,但也存在差异。在 2PC 中,当第二阶段开始时,所有本地事务都未完成(仍被锁定),而在 TC/C 中,所有本地事务都已完成(解锁)。换句话说,2PC 的第二阶段是关于完成未完成的事务(如中止或提交),而在 TC/C 中,第二阶段是关于在发生错误时使用反向操作来抵消之前的事务结果。下表总结了它们的差异。
| 第一阶段 | 第二阶段:成功 | 第二阶段:失败 | |
|---|---|---|---|
| 2PC | 本地事务未完成 | 提交所有本地事务 | 取消所有本地事务 |
| TC/C | 所有本地事务已完成 | 执行新的本地事务 | 撤销已提交事务的副作用 |
表 12.3: 2PC 与 TC/C 的比较
TC/C 也被称为补偿性分布式事务。它是一种高级解决方案,因为补偿(也称为“撤销”)是在业务逻辑中实现的。这种方法的优点是它与数据库无关。只要数据库支持事务,TC/C 就可以工作。缺点是必须在应用层的业务逻辑中管理分布式事务的细节并处理其复杂性。
阶段状态表
我们还没有回答之前提出的问题:如果钱包服务在 TC/C 中间重启怎么办?当它重启时,所有之前的操作历史可能会丢失,系统可能不知道如何恢复。
解决方案很简单。我们可以将 TC/C 的进度作为阶段状态存储在事务性数据库中。阶段状态至少包括以下信息:
- 分布式事务的 ID 和内容。
- 每个数据库的尝试阶段状态。状态可能是“未发送”、“已发送”和“已收到回复”。
- 第二阶段名称。可能是“确认”或“取消”。可以使用尝试阶段的结果计算。
- 第二阶段的状态。
- 一个乱序标志(稍后在“乱序执行”部分解释)。
阶段状态表应该放在哪里?通常,我们将阶段状态存储在包含扣款钱包账户的数据库中。更新后的架构图如图 12.10 所示。
不平衡状态
不知你是否注意到,在尝试阶段结束时,1 美元消失了(图 12.11)? 假设一切顺利,在尝试阶段结束时,1 美元从账户 A 中扣除,这比 TC/C 开始时少了。这违反了会计的基本原则,即交易后总和应保持不变。
好消息是,TC/C 仍然保持了事务性保证。TC/C 由多个独立的本地事务组成。由于 TC/C 是由应用程序驱动的,应用程序本身能够看到这些本地事务之间的中间结果。另一方面,数据库事务或 2PC 版本的分布式事务由数据库维护,对高级应用程序是不可见的。
在分布式事务执行期间,总会出现数据不一致的情况。这些不一致可能对我们来说是透明的,因为数据库等低级系统已经修复了这些不一致。如果没有,我们必须自己处理(例如 TC/C)。
不平衡状态如图 12.11 所示。
有效操作顺序
尝试阶段有三种选择:
| 尝试阶段选择 | 账户 A | 账户 C |
|---|---|---|
| 选择 1 | -$1 | 无操作 |
| 选择 2 | NOP | +$1 |
| 选择 3 | -$1 | +$1 |
表 12.4: 尝试阶段选择
这三种选择看起来都合理,但有些是无效的。
对于选择 2,如果账户 C 的尝试阶段成功,但账户 A 的尝试阶段失败(NOP),钱包服务需要进入取消阶段。有可能其他人会介入并将 1 美元从账户 C 中移走。当钱包服务尝试从账户 C 中扣除 1 美元时,发现没有剩余资金,这违反了分布式事务的事务性保证。
对于选择 3,如果 1 美元从账户 A 中扣除并同时添加到账户 C 中,会引入很多复杂性。例如,1 美元被添加到账户 C,但未能从账户 A 中扣除。在这种情况下,我们该怎么办?
因此,选择 2 和选择 3 是有缺陷的选择,只有选择 1 是有效的。
乱序执行
TC/C 的一个副作用是乱序执行。通过一个例子更容易解释。
我们重用上面的例子,从账户 A 转账 1 美元到账户 C。如图 12.12 所示,在尝试阶段,对账户 A 的操作失败,并向钱包服务返回失败,钱包服务随后进入取消阶段,并向账户 A 和账户 C 发送取消操作。
假设处理账户 C 的数据库有一些网络问题,它在收到尝试指令之前收到了取消指令。在这种情况下,没有需要取消的内容。
乱序执行如图 12.12 所示。
为了处理乱序操作,允许每个节点在没有收到尝试指令的情况下取消 TC/C,通过以下更新增强现有逻辑:
- 乱序取消操作在数据库中留下一个标志,表示它已经看到了取消操作,但尚未看到尝试操作。
- 尝试操作被增强,始终检查是否存在乱序标志,如果存在则返回失败。
这就是为什么我们在“阶段状态表”部分向阶段状态表添加了乱序标志。
分布式事务:Saga
线性顺序执行
另一种流行的分布式事务解决方案称为 Saga [8]。Saga 是微服务架构中的事实标准。Saga 的理念很简单:
- 所有操作按顺序排列。每个操作都是其自身数据库上的独立事务。
- 操作从第一个到最后一个依次执行。当一个操作完成后,触发下一个操作。
- 当某个操作失败时,整个过程从当前操作开始,按相反顺序回滚到第一个操作,使用补偿事务。因此,如果一个分布式事务有 n 个操作,我们需要准备 2n 个操作:n 个操作用于正常情况,另外 n 个操作用于回滚期间的补偿事务。
通过一个例子更容易理解这一点。图 12.13 展示了从账户 A 转账 1 美元到账户 C 的 Saga 工作流程。顶部水平线显示正常执行顺序。两条垂直线显示系统在遇到错误时应执行的操作。当遇到错误时,转账操作会回滚,客户端会收到错误消息。正如我们在第 352 页的“有效操作顺序”部分提到的,我们必须将扣款操作放在加款操作之前。
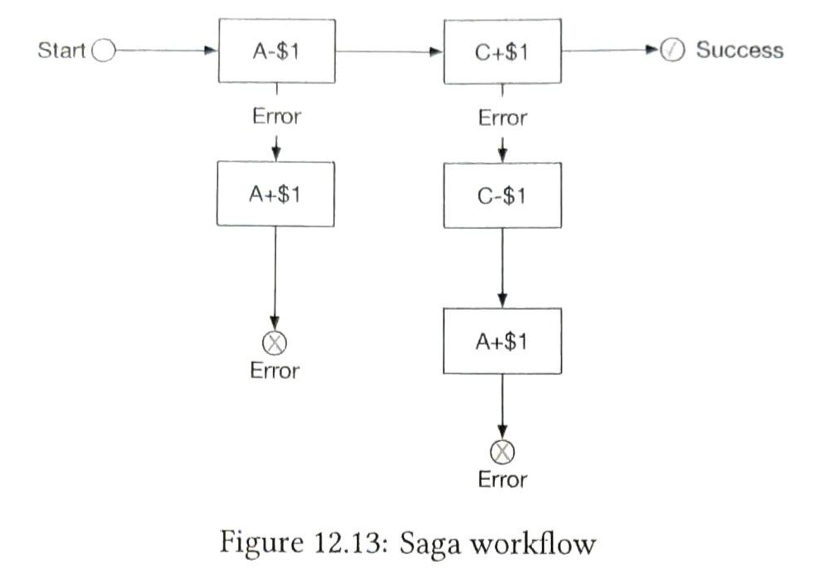
我们如何协调这些操作?有两种方法:
- 编排(Choreography)。在微服务架构中,所有参与 Saga 分布式事务的服务通过订阅其他服务的事件来完成自己的工作。因此,这是一种完全去中心化的协调方式。
- 编排(Orchestration)。一个单一的协调者指示所有服务按正确顺序完成工作。
选择哪种协调模型取决于业务需求和目标。编排解决方案的挑战在于服务以完全异步的方式通信,因此每个服务必须维护一个内部状态机,以便在其他服务发出事件时知道该做什么。当有许多服务时,管理起来可能会变得困难。编排解决方案很好地处理了复杂性,因此它通常是数字钱包系统中的首选解决方案。
TC/C 与 Saga 的比较
TC/C 和 Saga 都是应用级别的分布式事务。表 12.5 总结了它们的相似之处和差异。
| TC/C | Saga | |
|---|---|---|
| 补偿操作 | 在取消阶段 | 在回滚阶段 |
| 中央协调 | 是 | 是(编排模式) |
| 操作执行顺序 | 任意 | 线性 |
| 并行执行可能性 | 是 | 否(线性执行) |
| 能否看到部分不一致状态 | 是 | 是 |
| 应用或数据库逻辑 | 应用 | 应用 |
表 12.5: TC/C 与 Saga 的比较
在实践中我们应该使用哪种?答案取决于延迟要求。如表 12.5 所示,Saga 中的操作必须按线性顺序执行,但在 TC/C 中可以并行执行。因此,决策取决于以下几个因素:
- 如果没有延迟要求,或者服务非常少(例如我们的转账示例),我们可以选择其中任何一种。如果我们想顺应微服务架构的趋势,选择 Saga。
- 如果系统对延迟敏感并且包含许多服务/操作,TC/C 可能是更好的选择。
候选人: 为了使余额转账具有事务性,我们用关系数据库替换 Redis,并使用 TC/C 或 Saga 来实现分布式事务。
面试官: 干得好!分布式事务解决方案有效,但在某些情况下可能效果不佳。例如,用户可能在应用级别输入错误的操作。在这种情况下,我们指定的金额可能是错误的。我们需要一种方法来追溯问题的根本原因并审计所有账户操作。我们如何做到这一点?
事件溯源(Event Sourcing)
背景
在现实生活中,数字钱包提供商可能会被审计。这些外部审计员可能会提出一些具有挑战性的问题,例如:
- 我们是否知道任何时间点的账户余额?
- 我们如何知道历史和当前账户余额是正确的?
- 我们如何证明在代码更改后系统逻辑是正确的?
一种系统回答这些问题的设计理念是事件溯源,这是一种在领域驱动设计(DDD)[9] 中开发的技术。
定义
事件溯源中有四个重要术语:
- 命令(Command)
- 事件(Event)
- 状态(State)
- 状态机(State Machine)
命令
命令是来自外部世界的预期操作。例如,如果我们想从客户端 A 转账 1 美元到客户端 C,这个转账请求就是一个命令。
在事件溯源中,一切都有顺序非常重要。因此,命令通常被放入一个 FIFO(先进先出)队列中。
事件
命令是一种意图,而不是事实,因为某些命令可能无效且无法执行。例如,如果转账后账户余额变为负数,转账操作将失败。
在执行任何操作之前,必须验证命令。一旦命令通过验证,它就是有效的并且必须执行。执行的结果称为事件。
命令和事件之间有两个主要区别:
- 事件必须被执行,因为它们代表已验证的事实。在实践中,我们通常使用过去时态来描述事件。如果命令是“从 A 转账 1 美元到 C”,则相应的事件是“从 A 转账 1 美元到 C”。
- 命令可能包含随机性或 I/O,但事件必须是确定性的。事件代表历史事实。
事件生成过程有两个重要属性:
- 一个命令可能生成任意数量的事件。它可能生成零个或多个事件。
- 事件生成可能包含随机性,这意味着不能保证一个命令总是生成相同的事件。事件生成可能包含外部 I/O 或随机数。我们将在本章末尾更详细地重新讨论这一属性。
事件的顺序必须遵循命令的顺序。因此,事件也存储在 FIFO 队列中。
状态
状态是在应用事件时将更改的内容。在钱包系统中,状态是账户名称或 ID,值是账户余额。状态可以看作是一个键值存储,其中键是主键,值是表行。
状态机
状态机驱动事件溯源过程。它有两个主要功能:
- 验证命令并生成事件。
- 应用事件以更新状态。
事件溯源要求状态机的行为是确定性的。因此,状态机本身不应包含任何随机性。例如,它不应使用 I/O 从外部读取任何随机内容,或使用任何随机数。当它将事件应用于状态时,它应始终生成相同的结果。
图 12.14 展示了事件溯源架构的静态视图。状态机负责将命令转换为事件并应用事件。由于状态机有两个主要功能,我们通常绘制两个状态机,一个用于验证命令,另一个用于应用事件。
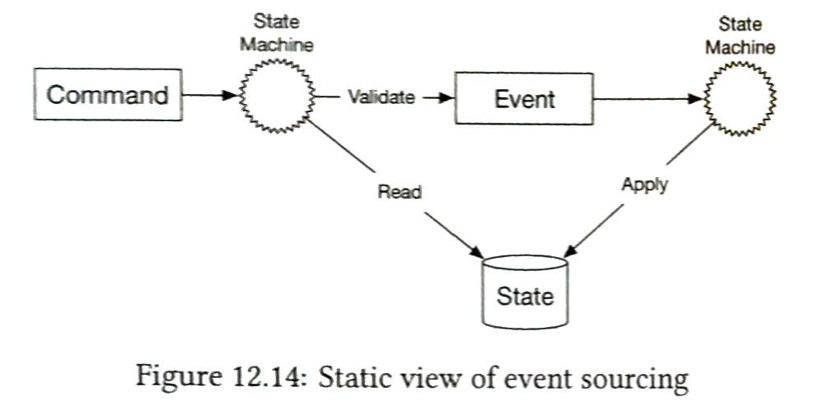
如果我们添加时间维度,图 12.15 展示了事件溯源的动态视图。系统不断接收命令并逐个处理它们。
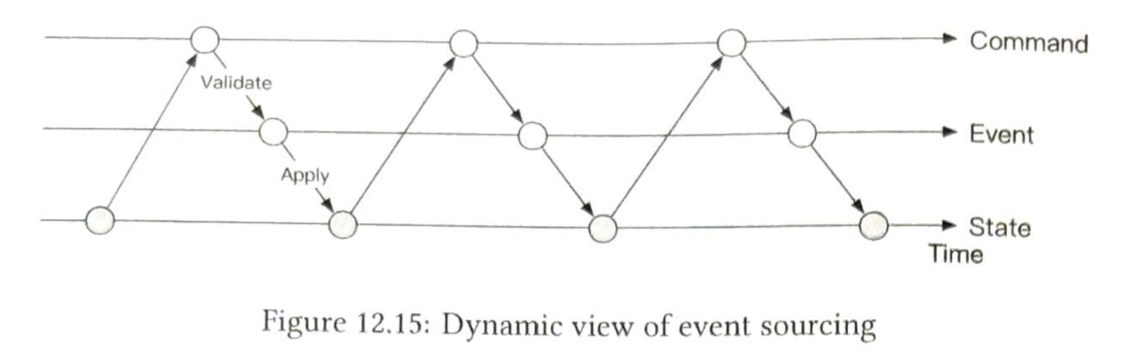
钱包服务示例
对于钱包服务,命令是余额转账请求。这些命令被放入 FIFO 队列中。命令队列的一个流行选择是 Kafka [10]。命令队列如图 12.16 所示。
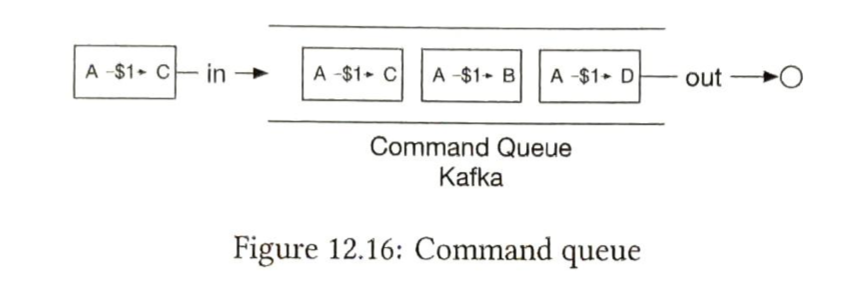
假设状态(账户余额)存储在关系数据库中。状态机按 FIFO 顺序逐个检查每个命令。对于每个命令,它检查账户是否有足够的余额。如果有,状态机为每个账户生成一个事件。例如,如果命令是“A→$1→C”,状态机生成两个事件:“A:-$1”和“C:+$1”。
图 12.17 展示了状态机如何工作的 5 个步骤:
- 从命令队列中读取命令。
- 从数据库中读取余额状态。
- 验证命令。如果有效,为每个账户生成两个事件。
- 读取下一个事件。
- 通过更新数据库中的余额来应用事件。
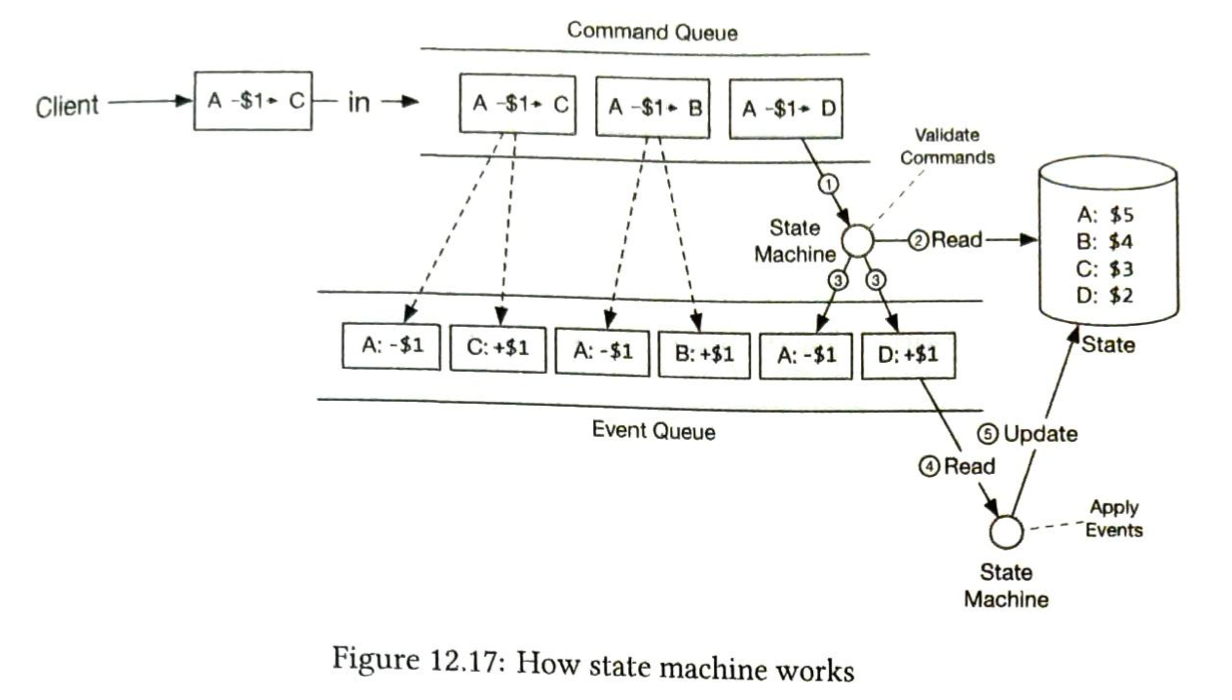
可重现性
事件溯源相对于其他架构的最大优势是可重现性。
在前面提到的分布式事务解决方案中,钱包服务将更新后的账户余额(状态)保存到数据库中。很难知道账户余额为何发生变化。同时,历史余额信息在更新操作期间丢失。在事件溯源设计中,所有更改首先作为不可变的历史记录保存。数据库仅用作任何给定时间点余额的更新视图。
我们始终可以通过从最开始重放事件来重建历史余额状态。由于事件列表是不可变的,并且状态机逻辑是确定性的,因此可以保证每次重放生成的历史状态是相同的。
图 12.18 展示了如何通过重放事件来重现钱包服务的状态。
可重现性帮助我们回答本节开头审计员提出的难题。我们在此重复这些问题:
- 我们是否知道任何时间点的账户余额?
- 我们如何知道历史和当前账户余额是正确的?
- 我们如何证明在代码更改后系统逻辑是正确的?
对于第一个问题,我们可以通过从开始重放事件到我们想知道账户余额的时间点来回答。
对于第二个问题,我们可以通过从事件列表中重新计算账户余额来验证其正确性。
对于第三个问题,我们可以针对事件运行不同版本的代码,并验证它们的结果是否相同。
由于审计能力,事件溯源通常被选为钱包服务的事实解决方案。
命令查询责任分离(CQRS)
到目前为止,我们已经设计了钱包服务以高效地将资金从一个账户转移到另一个账户。然而,客户端仍然不知道账户余额是多少。需要有一种方法来发布状态(余额信息),以便事件溯源框架外部的客户端可以知道状态是什么。
直观地说,我们可以创建数据库(历史状态)的只读副本并与外部世界共享。事件溯源以一种略有不同的方式回答这个问题:与其发布状态(余额信息),不如发布所有事件。这种理念称为 CQRS [11]。
在 CQRS 中,有一个状态机负责状态的写入部分,但有多个只读状态机负责生成状态的视图。这些视图可用于查询。
这些只读状态机可以从事件队列中派生出不同的状态表示。例如,客户端可能想知道他们的余额,一个只读状态机可以将状态保存在数据库中以服务余额查询。另一个状态机可以为特定时间段构建状态,以帮助调查可能的重复扣款等问题。状态信息是一个审计跟踪,可以帮助对账财务记录。
只读状态机在一定程度上滞后,但最终会赶上。架构设计是最终一致的。
图 12.19 展示了一个经典的 CQRS 架构。
候选人: 在这个设计中,我们使用事件溯源架构使整个系统可重现。所有有效的业务记录都保存在不可变的事件队列中,可用于正确性验证。
面试官: 这很棒。但你提出的事件溯源架构一次只处理一个事件,并且需要与多个外部系统通信。我们能让它更快吗?
第三步 - 深入探讨设计
在这一部分,我们将深入探讨实现高性能、可靠性和可扩展性的技术。
高性能事件溯源
在之前的例子中,我们使用 Kafka 作为命令和事件存储,使用数据库作为状态存储。现在让我们探讨一些优化方法。
基于文件的命令和事件列表
第一个优化是将命令和事件保存到本地磁盘,而不是像 Kafka 这样的远程存储。这样可以避免网络传输时间。事件列表使用仅追加的数据结构。追加是一种顺序写入操作,通常非常快。即使对于机械硬盘,它也表现良好,因为操作系统对顺序读写进行了高度优化。根据这篇文章 [12],在某些情况下,顺序磁盘访问可能比随机内存访问更快。 第二个优化是将最近的命令和事件缓存在内存中。正如我们之前解释的那样,我们在命令和事件持久化后立即处理它们。我们可以将它们缓存在内存中,以节省从本地磁盘加载的时间。
我们将探讨一些实现细节。一种称为 mmap [13] 的技术非常适合实现上述优化。Mmap 可以同时写入本地磁盘并将最近的内容缓存在内存中。它将磁盘文件映射为内存中的数组。操作系统将文件的某些部分缓存在内存中,以加速读写操作。对于仅追加的文件操作,几乎可以保证所有数据都保存在内存中,这非常快。 图 12.20 展示了基于文件的命令和事件存储。
基于文件的状态
在之前的设计中,状态(余额信息)存储在关系数据库中。在生产环境中,数据库通常运行在独立服务器中,只能通过网络访问。类似于我们对命令和事件的优化,状态信息也可以保存到本地磁盘。
更具体地说,我们可以使用 SQLite [14],它是一个基于文件的本地关系数据库,或者使用 RocksDB [15],它是一个基于文件的本地键值存储。
选择 RocksDB 是因为它使用日志结构合并树(LSM),该结构针对写操作进行了优化。为了提高读取性能,最近的数据会被缓存。
图 12.21 展示了基于文件的命令、事件和状态解决方案。
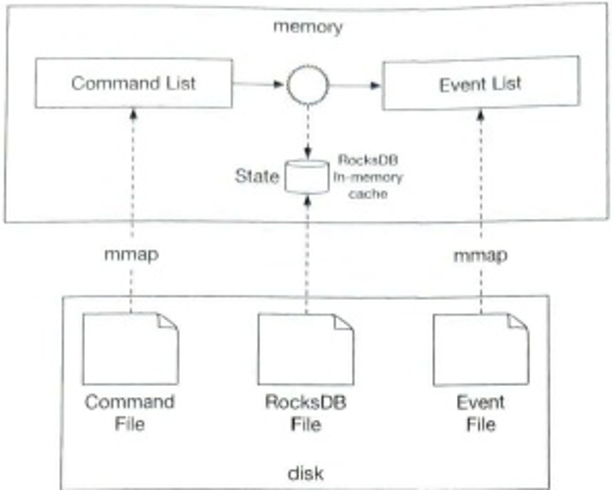
快照
一旦所有内容都基于文件,我们考虑如何加速可重现性过程。当我们第一次介绍可重现性时,状态机每次都必须从头开始处理事件。我们可以优化的方法是定期停止状态机并将当前状态保存到文件中。这称为快照。 快照是历史状态的不可变视图。一旦保存了快照,状态机就不必再从头开始了。它可以从快照中读取数据,验证上次停止的位置,并从那里恢复处理。 对于钱包服务等金融应用,财务团队通常要求在 00:00 拍摄快照,以便他们可以验证当天发生的所有交易。当我们第一次介绍事件溯源的 CQRS 时,解决方案是设置一个只读状态机,从头开始读取,直到达到指定时间。使用快照后,只读状态机只需加载包含数据的快照。 快照是一个巨大的二进制文件,常见的解决方案是将其保存在对象存储解决方案中,例如 HDFS [16]。 图 12.22 展示了基于文件的事件溯源架构。当所有内容都基于文件时,系统可以充分利用计算机硬件的最大 I/O 吞吐量。
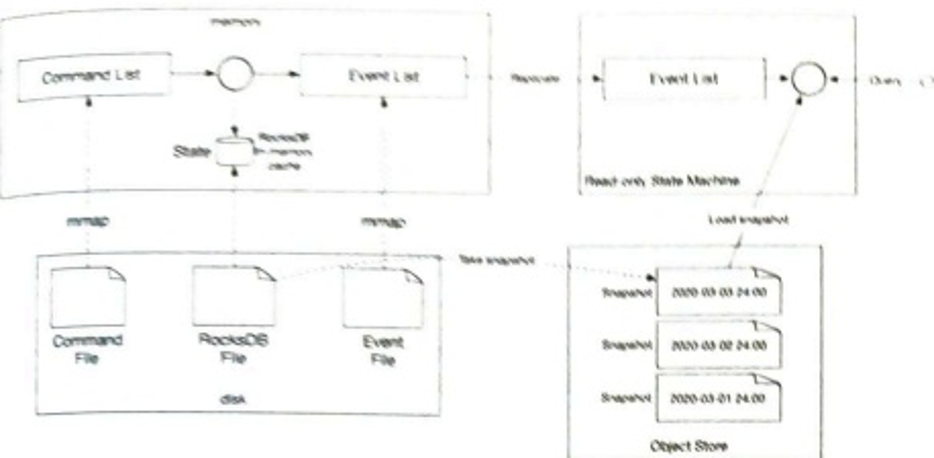
Candidate: 我们可以重构事件溯源的设计,使命令列表、事件列表、状态和快照都保存在文件中。事件溯源架构以线性方式处理事件列表,这与硬盘和操作系统缓存的设计非常契合。 Interviewer: 本地基于文件的解决方案的性能优于需要从远程 Kafka 和数据库访问数据的系统。然而,还有一个问题:由于数据保存在本地磁盘上,服务器现在是有状态的,并成为单点故障。我们如何提高系统的可靠性?
可靠的高性能事件溯源
在解释解决方案之前,让我们先分析系统中需要可靠性保证的部分。
可靠性分析
从概念上讲,节点所做的一切都围绕两个概念:数据和计算。只要数据是持久的,就可以通过在另一个节点上运行相同的代码来恢复计算结果。这意味着我们只需要担心数据的可靠性,因为如果数据丢失,它将永远丢失。系统的可靠性主要取决于数据的可靠性。 我们的系统中有四种类型的数据:
- 基于文件的命令
- 基于文件的事件
- 基于文件的状态
- 状态快照
我们来仔细看看如何确保每种类型数据的可靠性。 状态和快照总是可以通过重放事件列表来重新生成。为了提高可靠性。
现在我们来检查命令。表面上看,事件是从命令生成的。我们可能认为为命令提供强可靠性保证就足够了。乍一看这似乎是正确的,但它忽略了一些重要的东西。事件生成不一定是确定性的,它可能包含随机因素,例如随机数、外部 I/O 等。因此,命令不能保证事件的可重现性。
现在是时候仔细看看事件了。事件代表引入状态(账户余额)变化的历史事实。事件是不可变的,可以用来重建状态。 通过这个分析,我们得出结论:事件数据是唯一需要高可靠性保证的数据。我们将在下一节中解释如何实现这一点。
共识
为了提供高可靠性,我们需要在多个节点之间复制事件列表。在复制过程中,我们必须保证以下属性:
- 无数据丢失。
- 日志文件中的数据相对顺序在节点之间保持一致。
为了实现这些保证,基于共识的复制是一个很好的选择。共识算法确保多个节点就事件列表的内容达成一致。让我们以 Raft [17] 共识算法为例。
Raft 算法保证只要超过半数的节点在线,它们上的仅追加列表就具有相同的数据。例如,如果我们有 5 个节点并使用 Raft 算法同步它们的数据,只要至少 3 个(超过 1/2)节点在线,如图 12.23 所示,系统仍然可以正常工作:

在 Raft 算法中,一个节点可以扮演三种不同的角色:
- 领导者(Leader)
- 候选者(Candidate)
- 跟随者(Follower)
我们可以在 Raft 论文中找到 Raft 算法的实现。我们在这里只涵盖高层次的概念,不深入细节。在 Raft 中,最多有一个节点是集群的领导者,其余节点是跟随者。领导者负责接收外部命令并在集群中的节点之间可靠地复制数据。
使用 Raft 算法,只要大多数节点在线,系统就是可靠的。例如,如果有 3 个节点,系统可以容忍 1 个节点的故障;如果有 5 个节点,系统可以容忍 2 个节点的故障。
可靠解决方案
通过复制,我们的基于文件的事件溯源架构中不会有单点故障。让我们看看实现细节。图 12.24 展示了具有可靠性保证的事件溯源架构。
在图 12.24 中,我们设置了 3 个事件溯源节点。这些节点使用 Raft 算法可靠地同步事件列表。
领导者从外部用户接收传入的命令请求,将它们转换为事件,并将事件追加到本地事件列表中。Raft 算法将新添加的事件复制到跟随者。
所有节点(包括跟随者)处理事件列表并更新状态。Raft 算法确保领导者和跟随者具有相同的事件列表,而事件溯源保证只要事件列表相同,所有状态都相同。
一个可靠的系统需要优雅地处理故障,因此让我们探讨如何处理节点崩溃。
如果领导者崩溃,Raft 算法会自动从剩余的健康节点中选择一个新的领导者。这个新选举的领导者负责接受外部用户的命令。保证当节点宕机时,集群整体仍能提供服务。
当领导者崩溃时,崩溃可能发生在命令列表转换为事件之前。在这种情况下,客户端会通过超时或收到错误响应注意到问题。客户端需要将相同的命令重新发送给新选举的领导者。
相比之下,跟随者崩溃的处理要简单得多。如果跟随者崩溃,发送给它的请求将失败。Raft 通过无限重试来处理故障,直到崩溃的节点重新启动或被新节点替换。
候选人: 在这个设计中,我们使用 Raft 共识算法在多个节点之间复制事件列表。领导者接收命令并将事件复制到其他节点。
分布式事件溯源
在上一节中,我们解释了如何实现可靠的高性能事件溯源架构。它解决了可靠性问题,但有两个限制:
- 当数字钱包更新时,我们希望立即收到更新结果。但在 CQRS 设计中,请求/响应流程可能很慢。这是因为客户端不知道数字钱包何时更新,客户端可能需要依赖定期轮询。
- 单个 Raft 组的容量有限。在某个规模下,我们需要对数据进行分片并实现分布式事务。
让我们看看如何解决这两个问题。
拉取与推送
在拉取模型中,外部用户定期从只读状态机轮询执行状态。这种模型不是实时的,如果轮询频率设置过高,可能会使钱包服务过载。图 12.25 展示了拉取模型。
通过在外部用户和事件溯源节点之间添加反向代理 [18],可以改进简单的拉取模型。在这种设计中,外部用户发送命令,反向代理定期轮询执行状态。这种设计简化了客户端逻辑,但通信仍然不是实时的。
图 12.26 展示了添加反向代理的拉取模型。
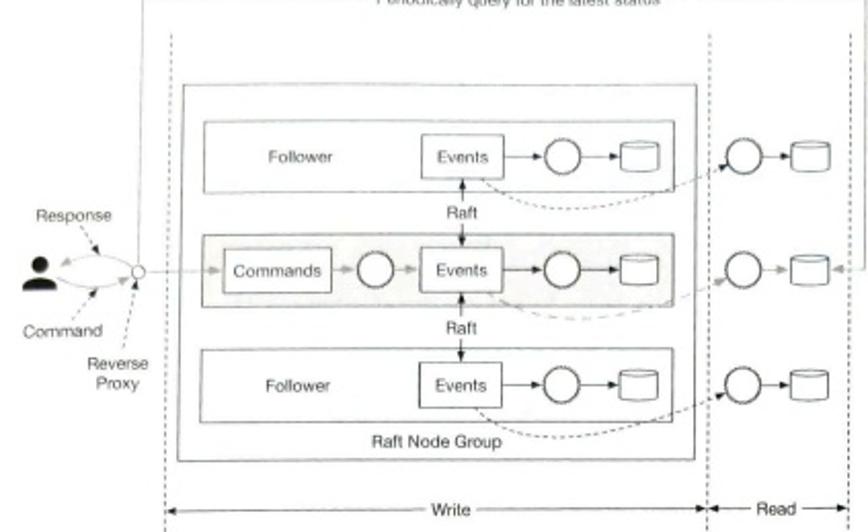
一旦我们有了反向代理,我们可以通过修改只读状态机来加快响应速度。正如我们之前提到的,只读状态机可以有自己的行为。例如,一种行为可以是只读状态机在收到事件后立即将执行状态推回反向代理。这将给用户一种实时响应的感觉。
图 12.27 展示了基于推送的模型。
分布式事务
我们可以重用分布式事务解决方案,TC/C 或 Saga。假设我们通过将键的哈希值除以 2 来对数据进行分区。
图 12.28 展示了更新后的设计。
让我们看看在最终的分布式事件溯源架构中,转账操作是如何工作的。为了更容易理解,我们使用 Saga 分布式事务模型,并且只解释没有回滚的成功路径。
转账操作包含 2 个分布式操作:A:-$1 和 C:+$1。Saga 协调者协调执行,如图 12.29 所示:
- 用户 A 向 Saga 协调者发送一个分布式事务。它包含两个操作:A:-$1 和 C:+$1。
- Saga 协调者在阶段状态表中创建一条记录以跟踪事务的状态。
- Saga 协调者检查操作顺序并确定需要先处理 A:-$1。协调者将 A:-$1 作为命令发送到包含账户 A 信息的分区 1。
- 分区 1 的 Raft 领导者接收 A:-$1 命令并将其存储在命令列表中。然后验证命令。如果有效,则将其转换为事件。Raft 共识算法用于在不同节点之间同步数据。事件(从 A 的账户余额中扣除 1 美元)在同步完成后执行。
- 事件同步后,分区 1 的事件溯源框架使用 CQRS 将数据同步到读取路径。读取路径重建状态和执行状态。
- 分区 1 的读取路径将状态推回事件溯源框架的调用者,即 Saga 协调者。
- Saga 协调者从分区 1 接收到成功状态。
- Saga 协调者在阶段状态表中创建一条记录,指示分区 1 中的操作成功。
- 由于第一个操作成功,Saga 协调者执行第二个操作,即 C:+$1。协调者将 C:+$1 作为命令发送到包含账户 C 信息的分区 2。
- 分区 2 的 Raft 领导者接收 C:+$1 命令并将其保存到命令列表中。如果有效,则将其转换为事件。Raft 共识算法用于在不同节点之间同步数据。事件(向 C 的账户添加 1 美元)在同步完成后执行。
- 事件同步后,分区 2 的事件溯源框架使用 CQRS 将数据同步到读取路径。读取路径重建状态和执行状态。
- 分区 2 的读取路径将状态推回事件溯源框架的调用者,即 Saga 协调者。
- Saga 协调者从分区 2 接收到成功状态。
- Saga 协调者在阶段状态表中创建一条记录,指示分区 2 中的操作成功。
- 此时,所有操作都成功,分布式事务完成。Saga 协调者向其调用者返回结果。
第四步 - 总结
在本章中,我们设计了一个能够每秒处理超过 100 万条支付命令的钱包服务。经过粗略估算,我们得出结论:需要数千个节点来支持这样的负载。
在第一个设计中,提出了使用 Redis 等内存键值存储的解决方案。这个设计的问题是数据不具备持久性。
在第二个设计中,内存缓存被事务性数据库取代。为了支持多个节点,提出了不同的分布式事务协议,如 2PC、TC/C 和 Saga。基于事务的解决方案的主要问题是无法轻松进行数据审计。
接下来,我们引入了事件溯源。我们首先使用外部数据库和队列实现了事件溯源,但性能不佳。通过将命令、事件和状态存储在本地节点中,我们提高了性能。
单节点意味着单点故障。为了提高系统的可靠性,我们使用 Raft 共识算法将事件列表复制到多个节点上。
我们做的最后一个增强是采用事件溯源的 CQRS 特性。我们为外部用户提供了一个异步的读取路径。TC/C 或 Saga 协议用于协调多个节点组之间的命令执行。
恭喜你坚持到这里!现在给自己一个鼓励吧。干得好!
章节索引
参考资料
Reference Material
[1] Transactional guarantees. https://docs.oracle.com/cd/E1727501/html/programmer_reference/rep_trans.html
[2] TPC-E Top Price/Performance Results. http://tpc.org/tpce/results/tpce_priceperf_results5.asp?resulttype=all
[3] ISO 4217 CURRENCY CODES. https://en.wikipedia.org/wiki/ISO4217
[4] Apache ZooKeeper. https://zookeeper.apache.org/
[5] Martin Kleppmann. Designing Data-Intensive Applications. O'Reilly Media, 2017
[6] X/Open XA. https://en.wikipedia.org/wiki/X/Open_XA
[7] Compensating transaction. https://en.wikipedia.org/wiki/Compensating_transaction
[8] SAGAS, Hector Garcia-Molina. https://www.cs.cornell.edu/andru/cs711/2002fa/reading/sagas.pdf
[9] Eric Evans. Domain-Driven Design: Tackling Complexity in the Heart of Software. Addison-Wesley Professional, 2003
[10] Apache Kafka. https://kafka.apache.org/
[11] CQRS. https://martinfowler.com/bliki/CQRS.html
[12] Comparing Random and Sequential Access in Disk and Memory. https://deliveryimages.acm.org/10.1145/1570000/1563874/jacobs3.jpg
[13] mmap. https://man7.org/linux/man-pages/man2/mmap.2.html
[14] SQLite. https://www.sqlite.org/index.html
[15] RocksDB. https://rocksdb.org/
[16] Apache Hadoop. https://hadoop.apache.org/
[17] Raft. https://raft.github.io/
[18] Reverse proxy. https://en.wikipedia.org/wiki/Reverseproxy